weidl x DeepRec:热门微博推荐框架性能提升实战
微博推荐团队:陈雨、韩楠、蔡小娟、高家华
1.项目背景
热门微博是新浪微博的重要功能之一,包含热门流、热点流、频道流、小视频后推荐、视频社区等场景。
 标推荐首页 发现页推荐 沉浸视频题
标推荐首页 发现页推荐 沉浸视频题
weidl机器学习框架为热门微博在线学习提供模型训练和推理服务,推荐全链路中在线推理服务的性能一直是weidl框架优化迭代的重要目标。在线学习系统依托于weidl框架。其服务的吞吐量、平均响应时间、承接上游QPS、机器资源占用等指标相互制衡,其中weidl框架推理计算的性能至关重要,与推荐服务全链路的整体性能指标及成本密切相关。探索引擎中计算图运行时算子计算加速的各种特性及优化支持成为本项目主要方向。
DeepRec是阿里巴巴集团提供的针对搜索、推荐、广告场景模型的训练/预测引擎,在分布式、图优化、算子、Runtime等方面对稀疏模型进行了深度性能优化,同时提供了稀疏场景下丰富的Embedding相关功能。

本文主要介绍热门微博推荐的整体架构与DeepRec对热门推荐框架性能上的提升,并详细剖析的weidl平台中使用的DeepRec的重要优化点。
2.热门微博推荐系统与weidl在线学习平台
2.1 热门微博推荐系统整体架构
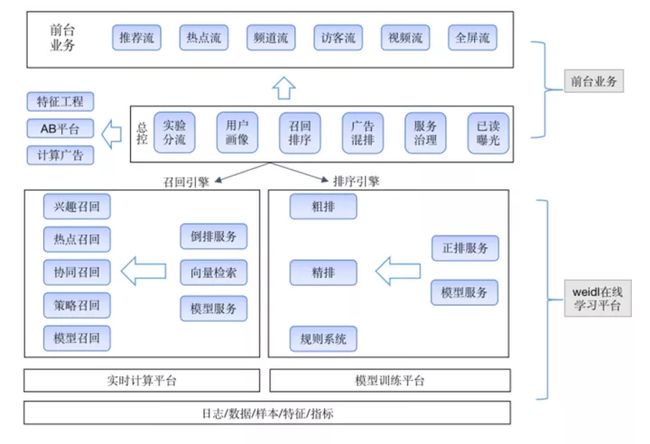
热门微博推荐系统可分为前台业务与weidl在线学习平台两个部分。前台业务为各个业务的接口,负责将推荐结果返回给业务方。在线学习平台集成了样本拼接、模型训练、参数服务器、模型服务等多个模块,为热门推荐的多个业务实现了完整的推荐流程,可快速为新业务搭建一套推荐系统。
2.2 weidl在线学习平台
在线学习平台是整个系统最核心的部分,主要负责召回、粗排、精排等模块。热门推荐系统为全链路大规模深度模型的在线学习系统,其中召回模块有兴趣召回、热点召回、策略召回、模型召回等多路召回,分别从千万级物料库中召回部分候选集,通过每路配额配置,将万级物料送入粗排模块。粗排阶段通过物料特征离线生成、用户特征实时拉取的方式,实现高性能的打分服务,通过粗排排序后,将千级候选集送入精排阶段。精排阶段模型最为复杂,物料与用户特征实时拉取,多场景多目标融合,最终通过规则系统的重排,选出一次曝光的博文,推荐给用户。
在线学习平台底层推理计算部分采用bridge模式,支持多个backend,包括DeepRec、TensorFlow、Torch、TensorRT等,同时支持基于CPU与GPU的模型训练与在线推理。
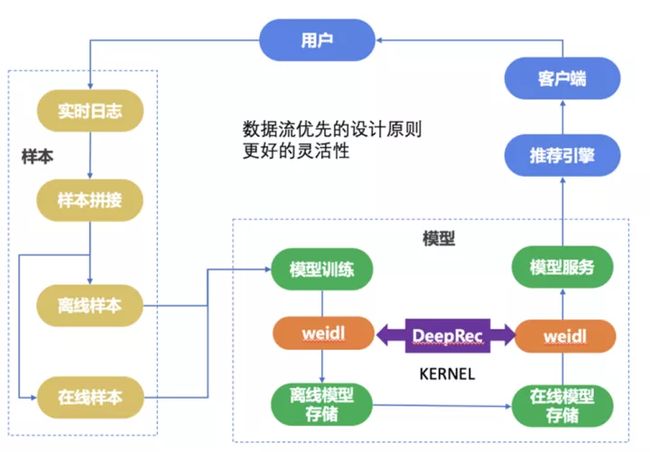 标题weidl在线学习平台
标题weidl在线学习平台
热门微博推荐系统从2018年开始,经过几年的升级,在实时性和规模上都有了本质的提升。
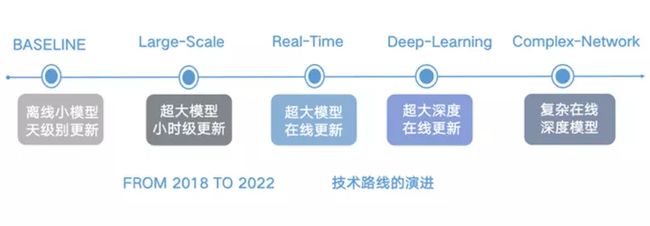
2.2.1 实时性
实时性包括模型学习到用户行为的速度,模型参数的更新应用到线上模型服务的速度。推荐系统的更新速度越快,越能够反应用户最近的用户习惯,越能够给用户进行越有时效性的推荐;模型更容易发现最新流行的数据pattern,越能够让模型反应找到最新的流行趋势。工程上主要通过以下几个方面,实现推荐系统的实时性。
a. 样本拼接作为模型训练的起点,一条完整的样本拼接完成的速度决定了模型学习用户行为速度的上限,目前热门推荐样本拼接窗口为30分钟,即用户在客户端的互动行为在30分钟内必会生成一条样本,送入kafka队列。
b. 模型训练读取样本流kafka,保证kafka无积压,所以该条样本会在毫秒级被模型学到,并通过rpc调用,更新到训练的参数服务器,并将新的模型参数推入kafka队列。
c. 参数同步服务从模型更新的kafka队列中读取数据,将模型最新的参数通过rpc调用,发送给在线服务所用的参数服务器中,此时从用户行为到模型更新完成。
d. 模型在线推理服务直连参数服务器,实时拉取模型最新参数进行打分。除去样本拼接所需的30分钟窗口,其余流程在1分钟内完成。

2.2.2 大规模深度复杂模型
热门推荐业务从最初的FM模型,到现在召回阶段以双塔为主,粗排阶段以cold dnn为主,精排阶段以多场景、多目标的复杂深度模型为主,模型在特征数量、目标个数、模型结构复杂度上都发生了质的变化,给业务带来了很大的收益。
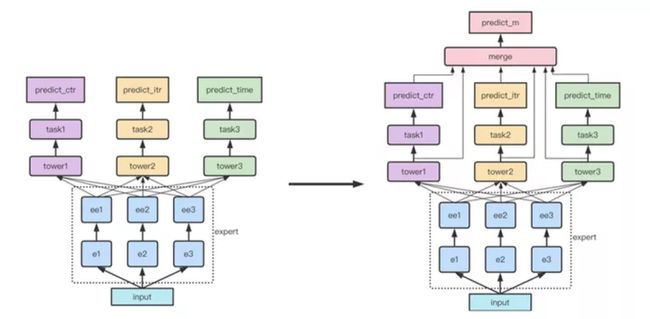 精排模型从snr模型迭代到mm模型 标题
精排模型从snr模型迭代到mm模型 标题
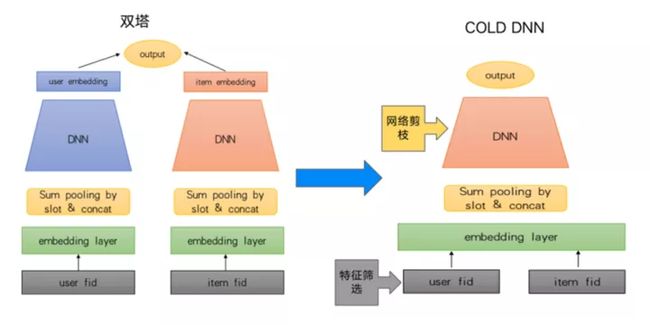 标题粗排双塔模型迭代到cold dnn模型
标题粗排双塔模型迭代到cold dnn模型
模型复杂度的提升给工程架构带来了不小的压力,一个multitask模型比一个单目标的dnn模型在算力上是成倍的增加。为了复杂模型的落地,热门微博推荐团队探索了多种开源框架,包括TensorRT, XDL,TFRA等,通过测试与源码分析,这些框架都在原生Tensorflow基础上做了不同方向的优化,但性能始终无法满足要求。同时,我们也通过指令集优化、改进TensorFlow内存管理、算子融合等方式,优化weidl kernel部分性能。
在不断的优化与开源框架的尝试中,发现DeepRec框架在性能、易用性、与weidl的兼容性上都全面胜出,最终,热门推荐框架引擎采用DeepRec引擎,提升了训练与在线推理的新能,同时也给业务带来了效果上的提升。
3.DeepRec及相关模块优化点剖析
3.1 OneDNN库加速算子运算
DeepRec集成了最新版本的开源的跨平台深度学习性能加速库oneDNN(oneAPI Deep Neural Network Library),英特尔相关团队进一步优化将oneDNN 原有的线程池统一成DeepRec的Eigen线程池,减少了线程池切换开销,避免了不同线程池之间竞争而导致的性能下降问题。oneDNN针对主流算子实现了性能优化,包括MatMul、BiasAdd、LeakyReLU等在稀疏场景中的常见算子。针对热门微博的线上模型,性能提升明显。
在DeepRec中英特尔CESG团队针对搜索广告推荐模型中存在着大量稀疏算子如Select、DynamicStitch、Transpose、Tile、SparseSegmentMean、Unique、SparseSegmentSum、SparseFillEmptyRows等一系列稀疏算子进行了深度的优化,下面介绍2个常用稀疏算子的优化方法。
3.1.1 Select算子优化
Select算子实现原理是依据条件来做元素的选择,此时可采用向量化指令的mask load方式,如图所示,以减少原先由if条件带来大量判断所导致的时间开销,然后再通过批量选择提升数据读写效率,最终线上测试表明,性能提升显著。

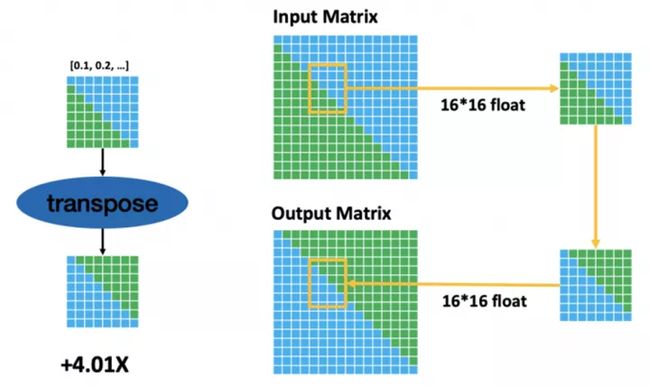
3.1.2 Transpose算子优化
同样,可以使用向量化的unpack和shuffle指令对transpose算子进行优化,即通过小Block的方式对矩阵进行转置,最终经线上测试表明,性能提升同样十分显著。
3.2 关键路径优先的调度引擎
DeepRec通过对执行引擎以及底层线程池的重新设计,达到在不同的场景下,包括trianing和inference,能做到更佳执行性能。保证不同线程之间的均衡性,尽量减少线程之间的steal,避免加锁等问题。
Executor的设计需要考虑对内存的访问及其并行实现之间的联系,进行多层次任务调度,减少缓存缺失和远程内存访问,充分发挥多核、多节点CPU的并行特性,提升系统的运行性能。在线程池层面,设计Cost-aware线程池,结合内存感知以及算子类型等信息,进行针对性优化;在计算图层面,对张量内存的位置进行调度,有利于线程池的调度;在算子生成层面,进行有利于线程池任务调度的算子任务划分。
DeepRec提供的基于关键路径优化的执行引擎,通过动态采集Session Run情况,统计与计算多组指标,并构建CostModel,计算出一个较优的调度策略。该功能中包含了基于关键路径的调度策略,根据CostModel patching执行细碎算子的调度策略以及线程池Cost-aware调度策略等。
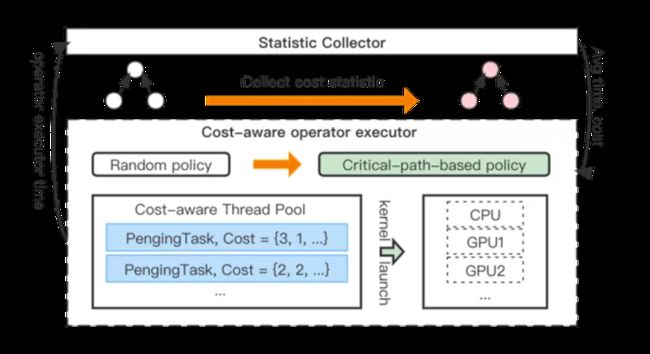
在graph执行过程中,Collector会监测所有算子执行以及线程池情况,包括算子执行时间,线程池pending任务饱和度,以及算子的前后依赖关系。这些参数会通过CostModel来计算更佳的调度策略。对于一张graph来说,存在一条或者多条关键路径,即从输入到输出经过的延时最长的逻辑路径。graph执行总的时间一定是大于等于关键路径时间。为了让整个graph执行更快,并发更佳高效 ,在graph执行时应当优先执行关键路径上的节点。
在稀疏模型图中,可能会存在大量细碎算子,会带来大量调度开销。有些可以通过算子融合来做优化,算子融合一般通过graph pattern匹配或者手动指定子图来确定需要融合的对象,难以覆盖全部算子。故而在executor层面,通过trace运行时数据来动态进行批量调度执行,这样可以减少非必要的细碎算子调度开销。
在线程调度层面,目前的线程池调度策略比较简单,如果当前执行线程是inter线程,优先将task调度到当前线程执行,若不是,则调度到一个random线程上。线程的balance完全由steal机制来保证。在我们的观察中,发现inter线程之间存在大量的steal,这会导致很多锁以及重复的线程调度等开销。CostModel executor通过采集运行时数据,来确定更佳的线程来执行任务,减少大量的steal行为。
在复杂模型上,使用DeepRec的CostModel调度,能够生成更佳的调度策略,减少调度开销。在测试的snr模型上平均耗时稳定优化2ms。
3.3 动态感知的内存/显存分配器
在张量内存管理方面,通常存在两点问题,一个是内存碎片过多,另一个是没有考虑模型结构存在多分支的情况下算子并行带来的内存增长。其内存管理十分粗放,大体上都是运行时依据内存请求动态进行内存释放和分配,同时进行一些内存池管理。由于无法感知上层应用的分配请求特点,这种内存管理存在着内存碎片过多的特点。例如在不清楚后续内存请求的情况下,由于前期的多次内存分配和释放,会导致后来的大内存请求由于内存碎片的问题而需要一块新的内存或者OOM。
深度学习模型的内存分配由于其应用特点存在着明显的规律性,训练时都是以一个个mini-batch的形式训练,每个mini-batch的分配特征大体上保持一致,训练时前向过程一直分配内存,较少释放,而反向过程中会释放前向计算中的临时张量,释放大量内存,所以内存会周期性呈现先增长后降低的特征。基于此学习到执行过程中内存分配pattern,从而减少内存的动态分配以及对内存块做到最佳的复用。同时自适应内存分配器也是graph-aware的,这样使得不同子图之间存在较小的相互干扰,提高分配效率。自适应内存分配器基本架构如下图所示:
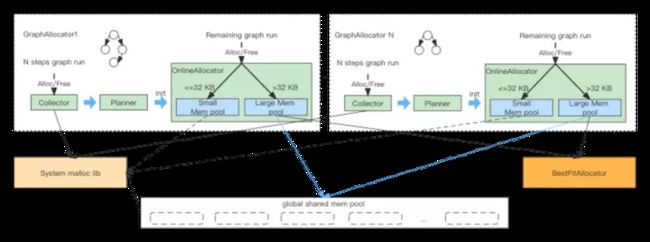
自适应内存分配器在训练过程对于前面的K轮进行一些统计,通过Allocator模块,对内存的分配,包括分配的时间点、分配的大小,统计好分配的时间点和大小后,在K轮结束之后会使用启发式的一些算法规划出一个较优的tensor cache planner,planner会创建allocator,并且预分配一些tensor内存块,后续的分配会优先通过此allocator进行分配。
自适应内存分配器基本原则是使用尽量少内存,同时提高内存的复用率。整体来讲,自适应内存分配器解决了在稀疏场景中内存分配上存在的一些问题,主要包括,第一,减少了在稀疏场景中,大量内存分配问题,包括小内存和大内存。譬如小内存分配出现在特征的处理过程中,包括一些特征的拼接,或者在做一些交叉特征,这里会存在大量的小内存的分配。同样在模型训练也存在很多大的内存,包括attention、RNN、或者全连接层,会有一些大内存的分配。减少大内存的分配,进而也减少了minor pagefault数量。第二,对于tensor能做到更好的复用,减少了总体的内存占用量。
4.DeepRec在业务中取得的收益
4.1 服务性能提升
热门微博已于9月将weidl的backend全量替换为DeepRec,线上服务与训练都取得了很大的收益,最明显的是精排多任务模型,图计算部分DeepRec比原生TensorFlow耗时降低50%,精排阶段整体耗时降低20%,单机吞吐量提升30%。
对于双塔和cold dnn模型,图计算部分耗时降低20%,粗排阶段整体耗时降低10%, 单机吞吐量提升20%,模型训练模块性能提升20%, 提升了训练速度并有效的改善了样本积压问题。
4.2 性能提升所带来的其他收益
推荐引擎模块整体耗时减少与吞吐量的提升,减少了推荐在训练与在线推理上所使用的机器资源,极大的降低了公司成本。
在线推理服务性能提升,使推荐引擎各个模块可以计算更多的候选物料,粗排阶段可以计算更多的候选物料,提升物料库总量与扩大召回条数,精排也由1000条扩到2000条,每个阶段候选物料数的增加,都会对整体指标有显著的提升。
更多关于 DeepRec 训练/预测引擎相关信息:https://github.com/alibaba/DeepRec