用数组实现堆(TopK及堆排序详解)
文章目录
- 堆的介绍
- 一、树的表示
- 二、堆的实现
- 总结
堆的介绍

这是一棵树,下面介绍一下树的相关概念。
节点的度:一个节点含有的子树的个数称为节点的度。例:A有6个节点,所以A节点的度为6
叶节点或终端节点:没有子树的节点(度为0)称为叶子节点。如:B节点 c节点等
一、树的表示?
树的表示有两种,一种是数组,一种是链表,数组更适合于完全二叉树也就是堆,其他二叉树用数组表示会造成空间浪费。
顺序存储:

链式存储:

二、堆的实现
我们先来看一下怎么判断是不是堆

如图要判断是不是堆我们可以把书拿出来链成一棵树:

我们看到A明显是一个大堆,所以正确答案就是A了,了解判断大小堆后我们就开始实现堆了。
#include
#include
#include
#include
#include
typedef int HeapData;
typedef struct Heap
{
HeapData* a;
int capcity;
int size;
}Heap;
//堆的创建
void HeapCreat(Heap* ps, HeapData* a, int n);
//堆的初始化
void HeapInit(Heap* ps);
//堆的释放
void HeapDestroy(Heap* ps);
//入堆
void HeapPush(Heap* ps,HeapData x);
//删除堆顶
void HeapPop(Heap* ps);
//拿堆顶元素
HeapData HeapTop(Heap* ps);
//堆的大小
int HeapSize(Heap* ps);
//堆的判空
bool HeapEmpty(Heap* ps);
//堆的打印
void HeapPrint(Heap* ps);
//堆的创建
void HeapCreat2(Heap* ps, HeapData* a, int n);
//堆排序
void HeapSort(Heap* ps,int n);
//TopK问题
void HeapTopK(HeapData* a, int n, int k); 如图在实现堆之前我们需要包含相对应的头文件,将int重命名为HeapData是为了以后更好修改,我们可以发现堆的结构体与顺序表一样,都是一个记录下标的位置的size和记录大小的capcity。我们要实现的有以下几个功能,堆的创建分为两种,一种是向上调整建堆,一种是向下调整建堆,后面我们会讲到向上调整建堆的时间复杂度要比向下的更优。然后是堆的初始化,堆的释放,入堆,删除堆顶元素,拿取堆顶元素,堆的大小,堆的判空,堆的打印(为了测试其他功能),堆的创建,堆排序,TopK问题。
第一个:堆的初始化
void HeapInit(Heap* ps)
{
assert(ps);
ps->a = NULL;
ps->capcity = 0;
ps->size = 0;
}堆的初始化与顺序表初始化一样,都是将指针a置为NULL,将capcity和size初始化为0.
第二个:堆的释放
void HeapDestroy(Heap* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->capcity = 0;
ps->size = 0;
}堆的释放也和顺序表一样,将a开辟的空间释放后,将a置为NULL,然后将capcity和size初始化为0
第三个:入堆
void swap(HeapData* p1, HeapData* p2)
{
HeapData tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void AdjustUp(HeapData* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] > a[parent])
{
swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void HeapPush(Heap* ps, HeapData x)
{
assert(ps);
if (ps->size == ps->capcity)
{
int newcapcity = ps->capcity == 0 ? 4 : 2 * ps->capcity;
HeapData* tmp = (HeapData*)realloc(ps->a, sizeof(HeapData) * newcapcity);
if (tmp == NULL)
{
perror("realloc:\n");
exit(-1);
}
ps->a = tmp;
ps->capcity = newcapcity;
}
ps->a[ps->size] = x;
ps->size++;
AdjustUp(ps->a, ps->size - 1);
}入堆刚开始与顺序表一样,先判断是不是需要开辟空间,当capcity等于size的时候就需要开辟空间,我们定义一个newcapcity来记录要开辟空间的个数,当capcity==0的时候说明此时没有空间,那么直接给4个空间,当capcity不为0的时候就需要在原来空间的基础上继续开辟空间,我们将空间设为原先空间的2倍,这里可以自行修改为想要的大小。由于存放数据是用HeapData类型的数组所以我们定义一个tmp来开辟相同类型的空间,这里一定是realloc,如果写成malloc就会出错,因为顺序表是连续的。开辟的大小就是newcapcity的大小。判断是否开辟成功,如果失败则报错并且退出程序。成功开辟空间后将空间给a然后将原先的capcity改为新的newcapcity。接下来进行入堆操作,首先我们能想到这个数进入肯定是先在size的下标位置,但是我们不能确定这个数进入后这个数组还是一个堆,如果是则不需要调整,反之则需要调整成为新的堆。那么该如何调整呢,以下图为例:

看完图后我们来讲解一下代码:
void AdjustUp(HeapData* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] > a[parent])
{
swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}如图,向上调整函数需要数组以及孩子节点,这个孩子节点的下标默认是size-1,因为在放入一个数后size会++只有-1才是放入的那个数的下标。知道孩子节点我们计算父节点,当child>0的时候进入循环,在大堆中如果孩子节点的内容大于父亲节点的内容就进行交换,这里的交换是交换的数组下标位置的内容,如果不大于的话就退出循环。
第四个:删除堆顶元素
void AdjustDown(HeapData* a, int n, int parent)
{
int child = 2 * parent + 1;
while (child < n)
{
if (child+1 < n && a[child + 1] < a[child])
{
child++;
}
if (a[parent] > a[child])
{
swap(&a[parent], &a[child]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
void HeapPop(Heap* ps)
{
assert(ps);
assert(ps->size > 0);
swap(&ps->a[0], &ps->a[ps->size - 1]);
ps->size--;
AdjustDown(ps->a, ps->size, 0);
}删除堆顶元素的时候我们就要思考该如何删除,这里肯定是不能直接删除的,因为直接删除就破坏了原来的结构并且很难恢复。所以这个时候我们想到了一个办法,将堆顶元素和最后一个元素交换,然后size--原来的堆顶元素就删掉了,但是这个时候堆就不是大堆了,所以这个时候需要新换上去的堆顶元素依次向下调整,调整完后就又变成了大堆。如图:

void HeapPop(Heap* ps)
{
assert(ps);
assert(ps->size > 0);
swap(&ps->a[0], &ps->a[ps->size - 1]);
ps->size--;
AdjustDown(ps->a, ps->size, 0);
}当然我们删除前要断言数组中是否有数据,如果没有数据则不能删除,如果有则交换堆顶和堆尾元素,然后让size--,然后向下调整。
void AdjustDown(HeapData* a, int n, int parent)
{
int child = 2 * parent + 1;
while (child < n)
{
if (child+1 < n && a[child + 1] < a[child])
{
child++;
}
if (a[parent] > a[child])
{
swap(&a[parent], &a[child]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
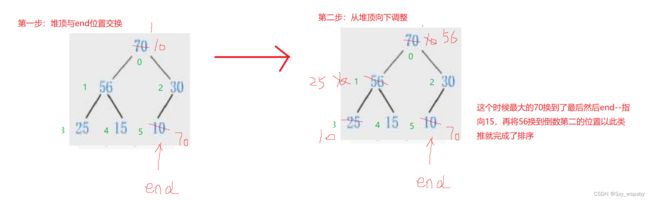
}再向下调整的过程中,我们可以默认每次大的孩子是左孩子,进入循环后判断左孩子和右孩子谁打,如果右孩子大则child++变成右孩子,当然有一种特殊情况,那就是完全二叉树是有可能没有右孩子的,这个时候需要判断右孩子是否存在,当child+1 第五个:取堆顶元素 取堆顶元素前判断一下数组是否有数据。 第六个:堆的大小 堆的大小就是size的大小,size每次放完数后会++难道大小不应该是size-1吗?错了顺序表本质是数组,数组是从0开始的,所以size刚好就是堆的大小。 第七个:堆的判空 当size==0的时候说明堆里没有元素。 接下来讲解两个建堆方法: 第一个:向上调整(这里的向上调整与我们上面实现的向上调整函数不同,这里的向上是指从数组的最后一个元素的父节点开始,每一个节点用向下调整函数调整,然后依次减减直到数组为0 的节点) 建堆需要传入一个有数的数组,数组中的元素任意,将这个数组和其数组元素传给建堆函数,给堆开辟n个数组中元素类型大小的空间,然后将数组中的数拷贝到堆中,然后将size和capcity置为n,end为堆尾元素,我们找到堆尾元素的父节点,从他的父节点开始一次向下调整建堆,如图: 用图对照着代码来看,一开始要进行向下调整的是65,然后调整完end--到了70然后70不用调整end--变成了60然后调整60最后将这些数变成了大堆。 第二个:向下调整建堆 向下调整就是从第一个数开始依次向上调整,很明显第一层是不需要调整的等到i等于n的时候就调完了所有数。如图: 下面是向上调整的时间复杂度: 如图我们可以看出当N特别大时,log的影响不大,所以最后向上调整的时间复杂度为O(N) 而向下调整法为: 而向下调整的时间复杂度从图上可以看出是O(NlogN)。 第九个:堆排序 怎么样将一个堆排序为升序或者降序呢?当我们要升序的时候,是要建大堆还是要建小堆呢?在这里我们通过画图发现,如果升序建小堆的话很难完成升序的目的,因为小堆的左右子树的大小是不确定的,而如果我们要交换子树的位置那么堆的结构就会被破坏,再往下遍历的时候找不到原先的子树。当然也有一种麻烦的解决方法就是复制一个新的堆然后遇到左子树大于右子树的时候将复制的那个堆里的数交换,每次遍历旧的数需要交换就去交换新的数的数据。相信看到这里大家也发现了此方法非常麻烦,所以这里会讲一种非常简单的方法,那就是升序建大堆,降序建小堆。我们以升序为例子,创建一个下标指向最后一个元素,建一个大堆那么可以保证堆顶的数据一定是最大的,然后让堆顶的数据和下标的数据进行交换,这样最大的数就到了最后面,然后让下标--指向倒数第二个位置,然后让堆顶数据向下调整找到堆中第二个最大的数,然后再和下标位置的元素交换,直到下标小于0的时候那么就将堆里所有的数排完序了。 第十个:TopK问题 topk就是排行榜,比如说中国最有钱的前十个人,这要从十几亿数据中找到10个最大的数,这样的问题该怎么用堆来解决呢?直接建堆吗?答案是不可以直接建堆,因为当数据非常大的时候那么所需要的空间也非常大,不可以因为一个排序去浪费几十G的空间内存,所以这个时候就需要想出一个能解决的办法。在这里我们直接说了,就是建一个小堆,这个小堆有多少个数是根据你需要最大的多少个数,比如刚刚最有钱的十个人那么堆就只存放10个数,然后遍历这些数据,当这些数据中有比小堆堆顶元素大的数的时候我们将这个数替换到堆顶,然后让这个小堆从堆顶依次向下调整,将堆顶保留堆中最小的数,然后再去进行刚刚的操作,直到遍历完所有的数据那么这个时候的小堆中就是所有数中10个最大的数了。 min就是我们创建的小堆,我们给堆开辟好空间,然后先随便给堆里放K个数,然后用向上调整的方法建一个小堆,小堆建好后用一个下标去访问需要找最大数的那个数组,当这个下标小于数组元素个数的时候进入循环,当外边的元素大于堆顶元素的时候就交换然后从堆顶向下调整,最后不要忘记了不管要不要交换堆顶元素下标J都要++。然后打印出这个小堆里的数即可。最后不要忘记了将给小堆开辟的空间释放掉以免造成内存泄漏。 堆的创建本质上就是顺序表,只有完全二叉树才方便用顺序表存储,堆中的难点在于向上调整和向下调整以及TOPk问题和堆排序问题,但是只要掌握了两种调整方法那么TopK问题和排序问题都能得以解决。HeapData HeapTop(Heap* ps)
{
assert(ps);
assert(ps->size > 0);
return ps->a[0];
}int HeapSize(Heap* ps)
{
assert(ps);
return ps->size;
}bool HeapEmpty(Heap* ps)
{
assert(ps);
return ps->size == 0;
}
void HeapCreat(Heap* ps, HeapData* a, int n)
{
//向上调整建堆
ps->a = (HeapData*)malloc(sizeof(HeapData) * n);
if (ps->a == NULL)
{
perror("malloc\n");
exit(-1);
}
memcpy(ps->a, a, sizeof(HeapData) * n);
ps->size = ps->capcity = n;
int end = n - 1;
for (int i = (end - 1) / 2; i >= 0; i--)
{
AdjustDown(ps->a, 10, i);
}
}
void HeapCreat2(Heap* ps, HeapData* a, int n)
{
//向下调整建堆
ps->a = (HeapData*)malloc(sizeof(HeapData) * n);
if (ps->a == NULL)
{
perror("malloc\n");
exit(-1);
}
memcpy(ps->a, a, sizeof(HeapData) * n);
ps->size = ps->capcity = n;
for (int i = 0; i < n; i++)
{
AdjustUp(ps->a, i);
}
}


//堆排序 升序建大堆 降序建小堆
void HeapSort(Heap* ps, int n)
{
int end = n - 1;
while (end >= 0)
{
swap(&ps->a[0], &ps->a[end]);
AdjustDown(ps->a, end, 0);
end--;
}
}
//TopK问题 找最大的前几个建小堆
void HeapTopK(HeapData* a, int n, int k)
{
HeapData* min = (HeapData*)malloc(sizeof(HeapData) * k);
if (min == NULL)
{
perror("malloc:");
exit(-1);
}
for (int i = 0; i < k; i++)
{
min[i] = a[i];
}
for (int i = (k - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(min, k, i);
}
int j = 0;
while (j < n)
{
if (a[j] > min[0])
{
min[0] = a[j];
AdjustDown(min, k, 0);
}
j++;
}
for (int i = 0; i < k; i++)
{
printf("%d ", min[i]);
}
printf("\n");
free(min);
min = NULL;
}
总结