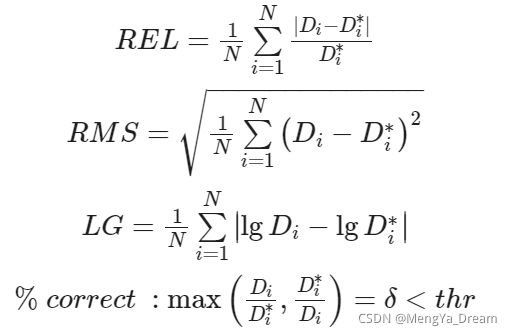单目深度估计技术进展综述
阅读分享中国图像学报《单目深度估计技术进展综述》
单目深度估计技术进展综述
目录
深度估计概述
基于多幅/单幅图像的深度估计方法
监督学习和无监督学习
深度估计相关数据集
基于深度学习的单目深度估计
【单任务】
1) 绝对深度
(1)有监督回归模型
(2)有监督分类模型
(3)无监督模型
2)相对深度
【多任务】
Conclusion
深度估计概述
根据场景类型的不同,数据集可分为室内数据集、室外数据集与虚拟场景数据集。
- 按照数学模型的不同,单目深度估计方法可分为基于传统机器学习的方法与基于深度学习的方法。
- 基于传统机器学习的单目深度估计方法:一般使用马尔可夫随机场(MRF)或条件随机场(CRF)对深度关系进行建模,在最大后验概率框架下,通过能量函数最小化求解深度。依据模型是否包含参数,该方法又可进一步分为参数学习方法与非参数学习方法,前者假定模型包含未知参数,训练过程即是对未知参数进行求解;后者使用现有的数据集进行相似性检索推测深度,不需要通过学习来获得参数。
- 基于深度学习的单目深度估计方法:国内外研究现状及优缺点,同时依据不同的分类标准,自底向上逐层级将其归类。
- 第1层级为仅预测深度的单任务方法与同时预测深度及语义等信息的多任务方法。图片的深度和语义等信息关联密切,因此有部分工作研究多任务的联合预测方法。
- 第2层级为绝对深度预测方法与相对深度关系预测方法。绝对深度是指场景中的物体到摄像机的实际距离,而相对深度关注图片中物体的相对远近关系。给定任意图片,人的视觉更擅于判断场景中物体的相对远近关系(相对深度)。
- 第3层级包含有监督回归方法、有监督分类方法及无监督方法。
- 对于单张图片深度估计任务,大部分工作都关注绝对深度的预测,而早期的大多数方法采用有监督回归模型,即模型训练数据带有标签,且对连续的深度值进行回归拟合。
- 考虑到场景由远及近的特性,也有用分类的思想解决深度估计问题的方法。
- 有监督学习方法要求每幅RGB图像都有其对应的深度标签,而深度标签的采集通常需要深度相机或激光雷达,前者范围受限,后者成本昂贵。而且采集的原始深度标签通常是一些稀疏的点,不能与原图很好地匹配。因此不用深度标签的无监督估计方法是研究趋势,其基本思路是利用左右视图,结合对极几何与自动编码机的思想求解深度。
- 场景的深度估计是计算机视觉中的经典问题,对3维重建、遮挡处理与光照估计等问题有重要作用。
- 为了获取深度,研究者们尝试直接从RGB图像中估计深度,利用摄像机拍摄的图像估计每个像素对应的物点到相机的距离,在重建过程中不与重建物体接触。
- 相较于通过激光测距仪等各种硬件设备获取物体表面上一定数量点的深度,基于图像的深度估计方法由于不需要昂贵的设备仪器和专业人员,具有更广的应用范围。
基于多幅/单幅图像的深度估计方法
基于图像的深度估计方法根据不同的输入图像数量可分为多幅图像深度估计方法与单幅图像深度估计方法。
- 基于多幅图像的深度估计方法包括多视立体几何(MVS)算法、运动中恢复结构(SFM)算法与从阴影中恢复形状(SFS)算法等,但这些算法对输入图片均有各自的要求,普适性不足。
- MVS利用三角测量法对左右视图进行匹配计算深度,其原理类似人眼的双目立体成像过程;
- SFM利用单摄像机捕获的时间序列图像获取深度;
- SFS一般利用灰度图像中变化的阴影恢复物体表面形状。
- 基于单幅RGB图像中估计深度的方法也称单目深度估计方法,是计算机视觉领域近年来热门的研究课题,但该问题是一个病态问题,其原因在于单张RGB图片对应的真实场景可能有无数个,而图像中没有稳定的线索来约束这些可能性。
- 早期的研究根据光学原理,利用图像中的离焦信息恢复深度(DFD),其基本假设是图像中焦点所在位置景物最为清晰,离焦点越远模糊程度越深,但是这种算法仅适用于小景深图像。
- 目前机器学习方法在物体识别、场景理解及手势识别等领域得到了广泛的应用。基于RGB图像与深度图之间存在着某种映射关系这一基本假设,基于数据驱动的机器学习方法逐渐应用于单目深度估计问题中。
监督学习和无监督学习
机器学习旨在赋予计算机学习的能力, 通过研究并构建算法使得计算机能够从特定的数据集中学习规律并做出预测和判断。
- 根据训练数据是否带标签,机器学习方法可分为监督学习方法与无监督学习方法。
- 监督学习是将样本数据和其对应的输出数据作为输入,从中学习出一个将输入映射到输出的规则并对新的样本做出预测和判断。
- 无监督学习方法则不需要训练标签。
深度估计相关数据集
在深度估计的研究中,由于室内外场景类型与深度范围具有较大的差异,对应不同的场景分别会构造不同的数据集。
- 真实场景数据集
- NYU depth v2(来自纽约大学)是常用的室内数据集之一,
- 选取了464个不同的场景,
- 利用RGB相机和微软的Kinect深度相机同时采集室内场景的RGB信息和深度信息,收集了407 024帧RGBD图像对构建数据集。
- 由于红外相机和摄像机之间的位置偏差,深度相机采集的原始深度图存在缺失部分或是噪点,
- 作者从中选取了1 449幅图像,利用着色算法对深度图进行填充得到稠密深度图,同时人工标注语义信息。
- Make3D(斯坦福大学)是常用的室外场景数据集之一,
- 使用激光扫描仪采集室外场景的深度信息,
- 选取的场景类型为白天的城市和自然风光,深度范围是5~81 m,大于该范围统一映射为81 m。
- 数据集共包含534幅RGBD图像对,其中400幅用于训练,134幅用于测试。
- KITTI(德国卡尔斯鲁厄理工学院和美国丰田技术研究院)自动驾驶领域常用的数据集之一,
- 包含深度数据标签
- 通过一辆装配有2台高分辨率彩色摄像机、2台灰度摄像机、激光扫描仪和GPS定位系统的汽车采集数据,其中激光扫描仪的最大测量距离为120 m。
- 图像场景包括卡尔斯鲁厄市、野外地区以及高速公路。
- 数据集共包含93 000个RGBD训练样本。
- Depth in the Wild(DIW)(密歇根大学)以相对深度作为标签的数据集
- 从词典中随机选取单词作为搜索关键字,然后从互联网中收集得到原始的RGB图像。
- 标注工作外包给专门的工作人员,为了更加高效,每一幅图像选取了两个高亮的点,工作人员只需判定两个点的远近关系即可。
- 对于采样点对之间的位置关系,采用50%随机采样,另外50%对称采样的方法以使构建的数据集尽可能平衡。最终获得的有效标注图像约5×E11张。
- 虚拟场景数据集
- SceneNet RGB-D数据集
- SYNTHIA数据集
- 由于是通过虚拟场景生成,数据集中包括更多天气、环境及光照,场景类型多样。各数据集有各自的优缺点,在实际研究中,应根据具体研究问题来选择合适的数据集。
基于深度学习的单目深度估计
参数学习方法和非参数学习方法都实现了单幅图像的深度估计,但总体看来,两种方法的缺点主要体现在人为假设较多、处理过程烦琐等方面,因而更自然、更统一的模型框架是提高算法的发展方向。
随着深度学习的迅速发展,深度神经网络以其强大的特征拟合能力和优异的性能,在计算机视觉、自然语言处理和语音识别等各个领域发挥了重要作用。
神经网络由诸多神经元按照一定的拓扑结构连接而成。对于高维的图像数据,实验中常利用在Lenet架构中提出的CNN进行处理。CNN利用权值共享的策略让一组神经元共享参数来节省计算开销。类似于动物视觉系统的多层抽象机制,CNN利用卷积核提取图像特征,通过深度神经网络对特征逐层抽象来完成高级的视觉任务。
基于深度学习的单幅图像估计方法,按照不同的分类标准,可以分为以下几类:
1) 有监督/半监督/无监督;
2) 绝对深度/相对深度;
3) 有后处理/无后处理;
4) 单任务/多任务;
5) 回归/分类。
【单任务】
1) 绝对深度
(1)有监督回归模型
图片的深度和语义等信息关联密切,因此有部分工作研究多任务的联合预测方法,在此先对单任务的深度估计方法进行讨论。绝对深度是指场景中的物体到摄像机的实际距离,而相对深度关注图片中物体的相对远近关系。对于单幅图像深度估计任务,大部分工作都关注绝对深度的预测,而早期的大多数方法采用有监督回归模型,即模型训练数据带有标签,且对连续的深度值进行回归拟合。
Eigen等人(2014)首次将深度神经网络用于单目深度估计任务。
- 提出使用两个尺度的神经网络对单张图片的深度进行估计:粗尺度网络预测图片的全局深度,细尺度网络优化局部细节。
- 网络由两个堆栈组成,如图所示,两个网络均以RGB图片作为输入,原始图片输入粗尺度网络后,得到全局尺度下场景深度的粗略估计结果。
- 然后将粗尺度网络的输出作为附加的第一层图像特征传递给细尺度网络,对全局预测进行局部优化以添加更多的细节信息。
- 粗尺度网络的任务是预测场景的全局深度,有效地利捕获诸如消失点、目标位置和空间对齐等深度线索。
- 为了获得足够的接收域,网络上层使用的是全连接层。
- 底层和中间层使用max-pooling将来自图像不同区域的信息组合成一个维度更小的特征图,以此整合对整个场景的理解。
- 粗尺度网络的结构包含五个特征提取层以及两个全连接层,输出图片的分辨率是输入的1/4。
- 细尺度网络的任务是对全局预测的结果进行局部优化,网络结构仅包含卷积层和池化层,输出的神经元的感受野为45×45像素。
- 通过设计,全局输出与细尺度网络第一层输出的尺寸大小相同,两者连接在一起,后续层使用零填充卷积以保持输出尺寸大小。
- 除了最后一个卷积层是线性的,其他层均使用ReLU作为激活函数。
- 训练时先对粗尺度网络进行训练,然后固定粗尺度网络的参数训练细尺度网络。作者还提出了一个尺度不变的误差评价函数,不同于考虑单个点的预测值与真值的误差,尺度不变误差考虑的是点对之间的误差,以此消除全局尺度的影响。

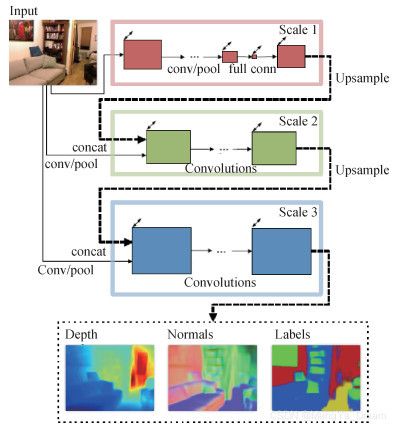
Eigen等人(2015)基于上述工作改进后提出了一个统一的多尺度网络框架,分别将其用于深度预测,表面法向量估计和语义分割3个任务。
- 值得一提的是,这里是将同一框架独立应用于不同任务,并不是多任务统一学习,因此将此归为单任务方法。
- 不同的任务设定不同的损失函数,使用不同的数据集训练。
- 网络模型是端到端的,不需要后处理。
- 网络结构如图所示,共包含3个尺度的网络,scale1网络对整张图片做粗略估计,然后用scale2和scale3网络对全局预测进行细节优化。相较于Eigen等人(2014)的模型,Eigen等人(2015)网络模型作了如下改进:
- 使用了更深的基础网络VGG (visual geometry group) Net;
- 利用第3个细尺度的网络进一步增添细节信息,提高分辨率;
- 将scale1网络的多通道特征图输入scale2网络,联合训练前面两个尺度的网络,简化训练过程,提高网络性能。
- scale1网络为了保证全局感受野使用了两层全连接层,输出特征图尺寸是输入图片的1/16,通道数为64。
- Scale1输出经4倍上采样后输入到scale2网络中,最终scale3网络的输出尺寸是原图的一半。
- 训练方法上,作者联合深度预测与法向量估计,共享scale1网络的参数。对深度估计任务的损失函数,作者在尺度不变损失的基础上添加了梯度正则项,计算预测梯度和真实梯度值的差异,对输出结果进行平滑优化。
Liu等人(2015)将深度卷积神经网络与连续条件随机场结合,提出深度卷积神经场,用以从单幅图像中估计深度。对于深度卷积神经场,使用深度结构化的学习策略,在统一的神经网络框架中学习连续CRF的一元势能项和成对势能项。通过解析地求解配分函数的积分,可以精确地求解似然概率优化问题。对输入图像使用超像素分割,得到的超像素作为图模型中的节点,超像素利用其质心的深度描述。(未细)
Liu等人(2016)基于Trigueiros等人(2012)改进后的工作整体框架类似,但由于原方法对原图需要生成众多超像素,对每一个超像素需要截取一个图片块输入网络进行训练,整体计算耗时。为此作者将超像素信息编码进神经网络中以提高计算效率。(未细)
Li等人(2015)提出多尺度深度估计方法,首先用深度神经网络对超像素尺度的深度进行回归,然后用多层条件随机场后处理,结合超像素尺度与像素尺度的深度进行优化。具体过程如下:对于给定输入图像,用SLIC (simple linear iterative clustering)算法生成超像素;对每一个超像素,以其质心为中心截取多个尺度的图片块;用神经网络拟合输入图像块和对应深度之间的关系;最后用多层CRF对深度结果进行优化。 (未细)
Laina等人(2016)提出了一种基于残差学习的全卷积网络架构用于单目深度估计,网络结构更深,并且不需要后处理。为了提高输出分辨率同时优化效率,文中提出了一种新的上采样方法;考虑到深度的数值分布特性,还引入了逆Huber Loss作为优化函数。 (未细)
(2)有监督分类模型
深度估计与语义分割任务具有一定的相似性,两者都是像素级的预测。不同之处在于深度值是连续的,常被当做回归处理,而语义标签是离散的,常被当做分类问题处理。考虑到场景由远及近的特性,也有用分类的思想解决深度估计问题的方法。
Cao等人(2018)将深度估计问题当做像素级的分类问题处理。首先将深度值离散化,然后训练一个深度残差网络预测每个像素对应的类别。分类之于离散不同之处在于能够得出一个概率分布,便于后面使用条件随机场作为后处理进行细节优化。(未细)
(3)无监督模型
有监督学习方法要求每幅RGB图像都有其对应的深度标签,而深度标签采集通常需要深度相机或激光雷达,前者范围受限后者成本昂贵。再者,采集的原始深度标签通常是一些稀疏的点,不能与原图很好的匹配。因此不用深度标签的无监督估计方法是近年的研究趋势,其基本思路是利用左右视图,结合对极几何与自动编码机的思想求解深度。
Garg等人(2016)提出利用立体图像对实现无监督单目深度估计,不需要深度标签,其工作原理类似于自动编码机。训练时利用原图和目标图片构成的立体图像对,首先利用编码器预测原图的深度图,然后用解码器结合目标图片和预测的深度图重构原图,将重构的图片与原图对比计算损失。(未细)
Godard等人(2017)对上述方法进行了进一步改进,利用左右视图的一致性实现无监督的深度预测。利用对极几何约束生成视差图,再利用左右视差一致性优化性能,提升鲁棒性。(未细)
RGBD数据集采集时通常需要同步使用RGB相机和传感器同时获取RGB图像和深度图像,但传感器中心和相机中心通常无法对齐。而且传感器采集的深度是稀疏的,存在噪点。Kuznietsov等人(2017)提出将以稀疏深度图为标签的监督学习方法和无监督的学习方法相结合,即半监督学习,来进一步提高性能。
2)相对深度
给定任意图片,人们往往更善于判断场景中物体的相对远近关系。无监督学习方法不需要深度图作为标签,同样地,利用相对远近关系,不用深度值标签也可对深度进行估计。
Zoran等人(2015)关注相对深度关系,不同于使用深度值作为标签训练网络的方法,提出利用图像中点对之间的相对关系推断深度信息。网络输出点对之间的相对关系,然后利用数值优化方法将稀疏的输出稠密化为最终结果。
- 利用相对关系有如下几个优点:
- 比数值回归更加简单;
- 人们能够很容易判断相对关系,
- 训练数据集获取成本低;
- 相对关系不受数据的单应变换影响,因此系统更加鲁棒。也把该框架应用于反射率预测等其他任务上。
- 整体框架由3部分组成:
- 第1部分从图像中选择点对:
- 第1部分选取的点对最好是远离边缘,在某一块同质区域的中心,而两点之间的连线最好能够跨过边缘区域,这样才能尽可能多的考虑相对关系,一条边上的两个点即是需要比较的点对。作者利用超像素分割,选取超像素的质点作为基点。同时为了考虑更长距离的点对,作者结合了不同尺度的超像素信息。
- 第2部分估计每一个点对的相对关系,提取相关信息并做三分类
- 第2部分从点对到相对关系估计,相对关系仅有3种,更近更远或相等,即可以转化为三分类问题。训练神经网络做三分类,网络的输入由两部分组成,一是两个点对的局部特征与局部关系,二是全局信息与ROI(感兴趣区域)。对点对中的每一个点,截取其周边的一小块作为局部特征,每个点相对于ROI的位置作为附加标记;将原图降采样后作为全局输入,ROI相对于全图的位置作为附加标记。
- 第3部分将点对之间的相对关系扩展至全局,得到稠密输出。
- 第3部分将点对之间的关系扩展至全局,一是需要保证全局关系的一致性,二是要填充稀疏的点。前者可作为一个带约束的优化问题加以解决,后者在超像素尺寸足够小的条件下可假设同一超像素中的结果均为同一常数。
Chen等人(2016)创建了一个新的数据集“Depth in the Wild”,包含任意图像以及图像中随机点对之间的相对深度关系,同时也提出了一个利用相对深度关系估计数值深度的算法。单幅图像估计常用数据集诸如NYU depth或Make 3D都是在固定的摄像机参数下采集的,由此训练出的网络模型难以适用于任意测试图片。而实际场景多种多样,数据集中的图片往往无法囊括所有场景。为此构建了一个新的数据集DIW,它包含4.95 E+5幅图像,每一幅图像都有随机采样的点对和它们的相对深度。 对于数据集的构建,传统方法采集时都需要使用深度相机,场景类型受限。作者从网上收集图片,每一幅图像中选取两个高亮点,通过众包方式利用人工标注它们的远近关系。考虑到图片信息与人力利用率,每张图片仅选取一对点进行标注。点位置的选取原则是一半随机选取,另一半选取对称点。
沙漏型架构:保证输出图像的尺度大小与输出一致

基于3D传感器的数据集有一些限制,包括:
场景类型有限,如NYU仅含室内图像;
数据集样本数量有限,如Make3D仅包含少量训练样本;
深度标签稀疏,如KITTI数据集。
Li等人(2018)提出使用互联网上的图像,通过从运动中恢复结构(SFM)和多视点立体(MVS)方法生成训练数据,构造了一个深度数据集MegaDepth。
MVS方法会产生噪点,图像中有些对象也无法重建,因此提出了新的数据清理方法,并使用语义分割生成的相对深度关系来自动增强数据。
数据集的创建,从Flickr上下载图像,然后使用SFM或MVS方法重建3维模型,由此获得每张图片对应的深度图。
由于瞬态物体,前背景遮挡以及深度的不连续性等原因,MVS得到的深度图存在噪点,像素点稀疏,为此采用了如下方法:
首先改进了MVS方法,迭代计算深度图,采用宁缺毋滥的原则,尽可能保证其与邻近深度图几何上一致。
其次,结合语义分割,利用语义信息优化深度。使用PSPNet进行语义分类,将像素分为前景背景和天空三类。对前景中的某一块连通域,如果其中大于一半的像素都没有重建出深度,则将该连通域舍弃。对于一幅图像,如果其中大于30%的像素能够得到深度,则该图像将被标注深度值,否则标注相对深度关系。为了标注相对深度,在语义分割得到的结果后,前景区域选一块作为前景,背景区域选一块作为背景。网络结构上,作者比较了VGG、ResNet和沙漏网络,实验表明沙漏网络效果最好。损失函数由尺度不变误差项,梯度平滑项与相对深度关系3项构成。
【多任务】
由深度信息和其他信息之间的互补性,部分工作提出利用统一的框架联合多任务进行训练,不同任务提取的特征互相通信,提升最终效果。
由深度信息和语义信息之间的互补性,Wang等人(2015)提出了一个统一的框架联合深度估计和语义分割任务。给定一幅输入图像,用一个训练好的网络做全局预测,得到像素级的深度值和语义标签,两者联合训练比单一训练可获得更高的精度。
为了进一步提高精度,将原图分割成各个区域,然后在全局预测的指导下得到区域级的深度和语义标签。最后利用两层的条件随机场,由像素级的全局预测和区域级的局部预测得到最后的优化结果。条件随机场的下层是由全局网络得到的像素级的深度和语义标签,下层是由局部网络得到的区域级的深度和语义标签。全局网络预测全局尺度和趋势,局部网络优化边缘细节。通过CNN的联合训练和HCRF的强化,深度估计和语义分割的结合在了一个统一的框架中。
HCRF中包含三种边,即相邻像素之间、相邻区域之间、上层区域与下层对应区域的像素之间。能量函数包括像素级的一元势能、成对势能、区域级的一元势能、成对势能、区域与相应像素之间的势能。
为了联合预测深度和语义标签,全局网络的损失函数包含两部分:前者计算预测深度与实际深度的损失,后者计算分类损失。
训练方法上,由于数据中的语义标签较少,先训练深度网络,然后加上语义标签微调。最终的网络同时预测深度和语义标签。对于局部网络,其输入为图像区域,以该区域像素数占比最多的语义类别作为该区域的语义标签,以归一化后的相对深度作为该区域的深度标签。但是由于图像的全局信息缺失,局部区域的深度难以学习,但局部区域的深度类型有限,因此作者用深度模板加以代替。
HCRF多尺度联合深度语义网络架构
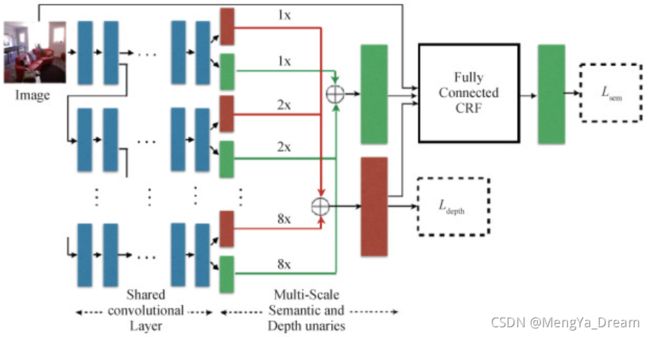
Mousavian等人(2016)提出一个同时预测深度和语义标签的模型,对每个任务先训练网络的一部分,再使用单个损失函数对两个任务同时优化微调整个网络,最后结合CNN与CRF,利用语义和深度线索对细节进行优化。该方法把深度信息作为辅助,主要关注语义分割性能的提升。
输入一幅RGB图像,
首先对深度和语义标签做初始预测,
然后将两个预测结果利用CRF结合得到最终的语义标签。
使用一个语义和深度统一的损失函数对网络参数训练优化,
最终训练好的网络模型既可以用于单任务预测,也可用于多任务预测。
网络结构如图,蓝色部分是共享参数,红绿色部分是独立参数,损失函数包含深度损失和语义损失两项,语义使用softmax损失函数,深度使用尺度不变误差。初始语义标签、深度标签和输入图片最终通过一个全连接CRF进行优化。CRF的能量函数包含一元势能和成对势能,一元势能即网络输出的概率,成对势能关注像素之间关系对语义标签的影响,其权值由深度值,RGB值和空间位置三者决定。网络训练分3个阶段,第1阶段只需要语义分割网络,第2阶段在添加深度网络进一步优化,第3阶段联合CNN和CRF用反向传播进行优化。
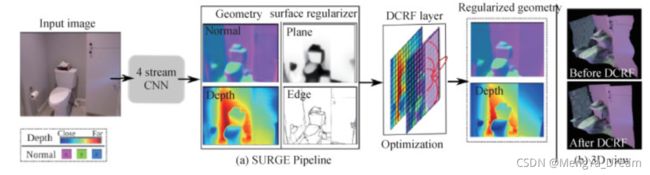
Wang等人(2016)提出将深度与多种信息结合的框架,如图所示,首先用4个支路的CNN同时预测输入图片的表面法向量、深度、平面、边缘;然后用稠密条件随机场,以平面信息和边缘信息作为辅助,使得表面法向量和深度的预测结果兼容。该方法将CRF与CNN结合,推导了能量函数的梯度,使得整体框架能够通过反向传播算法加以优化。文章重点在于DCRF能量函数的设计,包括综合考虑深度与法向量的一元势能,将4种信息结合的成对势能。
Conclusion
在单目深度估计问题中,常用的精度评估指标有相对误差(REL)、均方根误差(RMS)、对数误差(LG)及阈值误差(% correct)
综上,可以看到基于深度学习的单目深度估计是本领域的发展方向。
目前,该领域的发展主要集中在数据集和深度学习模型两方面。
首先,数据集的质量在很大程度上决定了模型的鲁棒性与泛化能力,深度学习要求训练数据必须有更多的数量、更多的场景类型,如何构建满足深度学习的数据集成为一个重要的研究方向。
目前,基于虚拟场景生成深度数据具有不需要昂贵的深度采集设备、场景类型多样、节省人力成本等优势,结合真实场景和虚拟场景的数据共同训练也是未来深度学习方法的趋势。
其次,为了提高深度学习估计单幅图像深度的精度,要求更新的更复杂的深度框架。
除了神经网络模型本身结构的优化,更新颖的算法设计也能有效地提升预测精度。
研究工作大多采用有监督回归模型对连续的绝对深度值进行回归拟合。
考虑到场景由远及近的特性,也有用分类模型进行绝对深度估计的方法。
由深度信息和其他信息之间的互补性,部分工作结合表面法线等信息提升深度预测的精度。
深度学习发展迅速,新的模型层出不穷,如何将这些模型应用于单幅图像深度估计问题中需要更加深入地研究。
另外,探索神经网络在单目深度估计问题中学到的是何种特征也是一个重要的研究方向。