重要论文——Dynamic Filter Networks
2016 NIPS ESAT-PSI, KU Leuven, iMinds
这篇文章,作者针对 以往的卷积操作中的卷积核,经过训练以后就是固定的,因此作者,提出一个 Dynamic Filter Networks,这个模型中的卷积核是 可学习的。我们来看一下这篇文章的方法:
Method
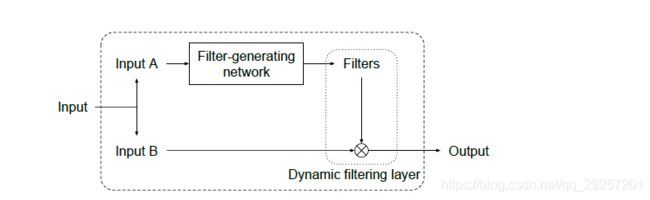
从上图可以看出, Dynamic Filter Networks包含两部分:Filter-generating network和Dynamic filtering layer。从名字可以看出来,第一部分的作用是,产生卷积核,第二部分是实现卷积核的乘法操作。
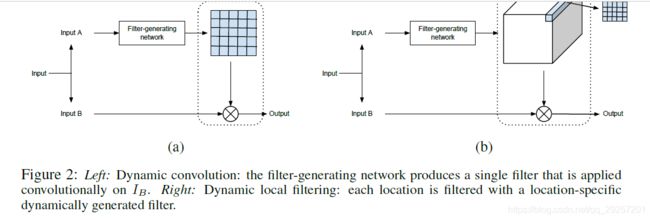
Dynamic convvolution layer
上图的左边部分,就是此操作,这种操作是Sample-specific,也就是说,每个样本的卷积核相同,但是针对input图片,每个位置的卷积核共享,这个也就平时的卷积操作,只是卷积核是 可学习型的
Dynamic local filtering layer
上图的右边部分,就是此操作,这种操作是:sample specific 和 position specific。也就是说,每个像素点对应的卷积核不相同。
思考
依照文章所说的,这种模型适用于有约束地方,比如:医学图像中,对图像的文字描述,可以通过文字描述生成卷积核。
实现
https://github.com/dbbert/dfn/blob/master/experiment_bouncingMnistOriginal_tensorflow.ipynb
# Unfold + matmul + fold flawlessly
# 可以实现tf中的extract_patch
# 链接忘记了
import torch
import torch.nn.functional as F
batch_size = 128
channels = 16
height, width = 32, 32
x = torch.randn(batch_size, channels, height, width)
kh, kw = 3, 3
dh, dw = 1, 1
# Pad tensor to get the same output
x = F.pad(x, (1, 1, 1, 1))
# get all image windows of size (kh, kw) and stride (dh, dw)
patches = x.unfold(2, kh, dh).unfold(3, kw, dw)
print(patches.shape) # [128, 16, 32, 32, 3, 3]
# Permute so that channels are next to patch dimension
patches = patches.permute(0, 2, 3, 1, 4, 5).contiguous() # [128, 32, 32, 16, 3, 3]
# View as [batch_size, height, width, channels*kh*kw]
patches = patches.view(*patches.size()[:3], -1)
print(patches.shape)
> torch.Size([128, 32, 32, 144])
2019/8/3