命名实体识别(NER)综述
文章目录
- 1. NER介绍
-
- 1.1 理论
- 1.2 常见命名实体
- 1.3 标注方案
- 1.4 数据集
- 1.5 评测指标
- 2. NER方法
-
- 2.1 方法概览与选择
- 2.2 深度学习模型
-
- 2.2.1 字词双粒度embedding + bi-LSTM + CRF + 后处理规则
- 2.2.2 BERT + CRF + 后处理规则
- 2.2.3 Lattice LSTM
- 2.2.4 FLAT
- 3.NER优化/拓展
-
- 3.1 模型加速与优化
-
- 3.1.1 加速包cudnn-LSTM
- 3.1.2 优化CRF路径选择
- 3.2 数据增强方法
-
- 3.2.1 规则模板 + 领域实体词典
1. NER介绍
1.1 理论
命名实体识别(NER)是自然语言处理领域的核心技术之一,它的目标是从一段非结构化文本中识别出属于特定类别的命名实体,进而支持下游任务。例如,为了接入地图搜索服务API,查询POI信息,我们从“我要去北京市北三环西路”中,识别出市辖区类“北京市”和道路类“北三环西路”这两个实体,并作为参数值传入搜索服务API(这一步骤被称为填槽),搜索完成后可获取对应的查询结果。
1.2 常见命名实体
在公开NER语料中,命名实体类别以“时间TIME、地名LOC、人名PER、机构ORG”最为常见。
不同领域的语料可能包含不同类型的命名实体。在语料构建阶段,命名实体的设计应该结合考虑语料的来源和应用场景。例如智能导航领域,可包含如下命名实体:
| 命名实体 | 命名实体含义 |
|---|---|
| ROAD | 道路 |
| HOTEL | 酒店 |
| DISTRICT | 行政区/市辖区 |
| ADDRESS | POI地址 |
| PARK | 公园 |
| RESTAURANT | 饭店 |
| POI_ GENERIC | POI |
| CHARGING | 充电桩/充电站 |
| POI_TYPE | POI类别 |
1.3 标注方案
传统的NER解决方法是序列标注,也就是为文本序列中的每个字标注其所属的命名实体类别。由于一个命名实体通常由多个字组合而成,例如”北 京 市”组成一个DISTRICT实体;并且存在两个同类别命名实体连续出现的情况,例如“北京市 海淀区”是两个DISTRICT实体,所以在实际应用时,通常采用特殊字母来帮助人们判断命名实体的开始与结束。在不同的标注方案下,特殊字母的含义不同,如下:
-
BIO标注方案
B 表示Begin,命名实体的第一个字
I 表示 Inside,命名实体中除了第一个字以外的其他字
O 表示 Outside,不属于命名实体由此,语料就可以确定了,如下示例:
我 O 要 O 去 O 北 B-DISTRICT 京 I-DISTRICT 市 I-DISTRICT 北 B-ROAD 三 I-ROAD 环 I-ROAD 西 I-ROAD 路 I-ROAD 北 B-DISTRICT 京 I-DISTRICT 市 I-DISTRICT 海 B-DISTRICT 淀 I-DISTRICT 区 I-DISTRICT -
BIOES标注方案
B 表示Begin,命名实体的第一个字
I 表示Inside,命名实体中除了第一个字和最后一个字以外的其他字
O 表示Outside,不属于命名实体
E 表示End,命名实体的最后一个字
S 表示Single,仅由一个字组成的命名实体由此,语料就可以确定了,如下示例:
我 O 要 O 去 O 北 B-DISTRICT 京 I-DISTRICT 市 E-DISTRICT 北 B-ROAD 三 I-ROAD 环 I-ROAD 西 I-ROAD 路 E-ROAD 北 B-DISTRICT 京 I-DISTRICT 市 E-DISTRICT 海 B-DISTRICT 淀 I-DISTRICT 区 E-DISTRICT
1.4 数据集
本文整理了中文NER语料,以备下次接触NER任务时快速开始研究和实战,也希望能够帮助各位读者朋友减少语料准备的时间投入。
| 领域 | 语料 | 样本个数 | 实体类别示例 | 语料简介 | 数据地址 |
|---|---|---|---|---|---|
| 通用 | MSRA | 46k | PER, ORG, LOC | MSRA微软亚洲研究院开源命名实体识别数据 | 数据下载 |
| 通用 | Ontonotes | 15k | 由英语、汉语和阿拉伯语组成,涵盖新闻、电话对话、网络日志、usenet新闻组、广播、脱口秀 | 数据下载 | |
| 新闻 | 人民日报NER | 23k | PER, ORG, LOC | 1998年人民日报的实体标注语料 | 数据下载 |
| 玻森Boson NER | 2k | company_name, product_name | 由玻森中文语义开放平台提供 | 数据下载 | |
| 微博 | 1890 | PER.NAM, LOC.NAM | 包含2013 年11 月至2014 年12月期间从微博中采样的1,890 条博文 | 数据下载 | |
| 简历 | resume | 4k | TITLE, NAME, CONT | 随Lattice LSTM论文一同发布,从新浪财经爬取,收录了中国股市上市公司高管的简历 | 数据下载 |
| 新闻 | CLUENER 2020 | 10k | organization, name, position | 中文细粒度命名实体识别数据集,在清华大学开源的文本分类数据集THUCTC基础上,选出部分数据进行细粒度命名实体标注,原数据来源于Sina News RSS. | 数据下载 |
| 电子病历 | CCKS2017-Task2 | 800 | 身体部位;疼痛 | 由清华大学知识工程实验室,微软亚洲研究院,北京极目云健康科技有限公司提供,数据来源于其云医院平台的真实电子病历数据 | 详细介绍 数据下载 |
| 音乐 | CCKS2018-Task2 | 15k | song;artist | 主要来自人机对话系统中音乐领域以及非音乐领域的真实用户utterance请求记录 | 数据下载 |
| 口语理解 | NLPCC-Task4 | 20k | music.play, navigation.start_navigation, phone_call.make_a_phone_call | 采集自一个商用的任务型对话系统的线上数据,实体所属领域包括音乐、导航、电话 | 数据下载 |
1.5 评测指标
通常,正确的命名实体识别结果,既要确保实体边界正确,也要确保实体类型正确。实体边界和分词类似,找到实体的开始和结束,如果把实体“中关村SOHO”识别为“中关村”和“SOHO”两个实体,就发生了边界错误。而实体类型是分类结果,是命名实体所属的类别,例如“中关村SOHO”的正确实体类型是POI_GENERIC。
命名实体识别任务的常用评测指标是准确率P、召回率R、F1分值。具体计算又分为micro和macro,前者是直接计算所有样本的评测指标,更常用;后者是分别计算每个类别所属样本的评测指标,再求平均值,使得样本数较少的类别的正确与否变得“重要”起来,因此更适用于类别不均衡的数据集(不均衡的命名实体识别语料很常见)。
以下以Presion的计算公式,举例说明micro和macro的不同之处:
m i c r o P = 正确数量 样本总数 _{micro}P = \frac{\text{正确数量}}{\text{样本总数}} microP=样本总数正确数量 m a c r o P = 实 体 类 别 1 正 确 数 量 实 体 类 别 1 样 本 总 数 + 实 体 类 别 2 正 确 数 量 实 体 类 别 2 样 本 总 数 + . . . + 实 体 类 别 N 正 确 数 量 实 体 类 别 N 样 本 总 数 实 体 类 别 个 数 N _{macro}P = \frac{\frac{实体类别1正确数量}{实体类别1样本总数} + \frac{实体类别2正确数量}{实体类别2样本总数} + ... + \frac{实体类别N正确数量}{实体类别N样本总数}}{实体类别个数N} macroP=实体类别个数N实体类别1样本总数实体类别1正确数量+实体类别2样本总数实体类别2正确数量+...+实体类别N样本总数实体类别N正确数量
2. NER方法
2.1 方法概览与选择
经过上文的理解和分析,我们知道命名实体识别是从文本序列中找出属于预定义类别的一串或多串文字。简而言之,先找出命名实体的边界,再判断命名实体的类别。从两个角度来粗略地思考解决方法,一种方法是判断每个字与字之间的间隙是不是分割点,以及分割点前/后属于哪个命名实体类别,也就是分类;另一种方法是使用特殊标记界定每个字是不是实体部分,以及属于哪个命名实体类别,也就是序列标注。
2.2 深度学习模型
2.2.1 字词双粒度embedding + bi-LSTM + CRF + 后处理规则
英文NER普遍以word为输入单元和序列标注单元。不同的是,由于中文分词不一定准确,甚至Word2Vec等词嵌入表示存在OOV问题,导致基于char(字)比基于word的模型效果更好,所以中文NER普遍以char为输入单元和序列标注单元。
字词双粒度embedding是在char的基础上,融合了词边界信息。字词双粒度embedding融合做NER的方法有许多,此处介绍一个我在实践中使用过的方法“char + softword”(16年Peng等人论文):首先获取字级char embedding,设向量维度为100,再拼接当前字的seg embedding,设向量维度为20,得到新的字级char embedding,作为模型输入,向量维度为120。其中,seg embedding取决于jieba分词后当前字在其所属词中的位置,分为4种,分别是Begin、Inside、End、Single,也就是BIES。例如,“到北京大学”由“到”和“北京大学”两个词组成,这五个字的seg embedding依次对应Single、Begin、Inside、Inside、End的向量表示。
说起NER标配,我们首先想到的是bi-LSTM + CRF组合。bi-LSTM用于捕获全局序列特征,CRF 用于模拟相邻标签之间的依赖关系。在送入CRF层之前,bi-LSTM的输出应首先经过全连接层转换为logits,logits分数表示字/词属于特定标签的发射分数(emission score)。在CRF层中,训练相邻字符的标签转移矩阵,通过结合发射分数和转移矩阵,为每一种可能的标签序列分配一个得分,并使用维特比算法解码得分最高的标签序列。以“北京市”为例,不带CRF的模型可能会输出“I-DISTRICT B-DISTRICT I-DISTRICT”,而带有CRF的模型由于学习了标签与标签的状态转移概率,减少了输出这样的错误答案的情况。
然而,再优秀的模型,难免有“人工智障”的时刻,不过没关系,后处理规则可以帮它纠正错误。还是以“北京市”为例,模型输出“I-DISTRICT B-DISTRICT I-DISTRICT”,显然是错误的,使用后处理规则句首标注为 I 时,将其修改为 B,此时如果句子第二个字标注为 B,将其修改为 I,最终模型输出“B-DISTRICT I-DISTRICT I-DISTRICT”。在对模型的准确性要求较高时,比如公司要上线一个模型,面对模型的各式各样的错误输出,人工分析badcase并总结后处理规则是必要的。
2.2.2 BERT + CRF + 后处理规则
BERT的面世对各大NLP任务产生了深远的影响,小到NLPer的个人练习,大到企业应用,都迅速换上BERT,为原有模型升级。我第一次使用BERT,就是用它来做NER。写到这里,还记得当年我“它竟然认识xxx这个地方诶”的惊叹,为它的模型容量和推理能力折服。
引入BERT后,由于BERT+bi-LSTM+CRF推理慢的问题,应该优化bi-LSTM,下文会提到,或者把bi-LSTM模型部分去掉。
2.2.3 Lattice LSTM
前文提到,中文分词难免有误影响模型的效果,因此普遍采用基于char的NER模型。但是基于char的NER也并不完美,没能充分利用词信息。为了解决这个问题,ACL 2018论文《Chinese NER Using Lattice LSTM》提出采用char+领域词典的格子模型,避免了中文分词错误(重点),又合理利用了词边界信息。
让我们带着两个问题来学习Lattice模型。第一个问题是“怎么避免分词错误”,第二个问题是“怎么利用Lattice格子融合char和词边界信息”。
问题一:怎么避免分词错误?
这篇论文在一个大型的自动分割的语料Giga-Word上,预训练了一个word2vec词嵌入词典D,包含704.4k个词。在做NER时,首先进行句子和大型词典D的匹配,所有匹配得来的词都是词典中现有的边界准确的词,从而避免了分词错误。例如,句子“北京市”和词典D匹配后,得到两个词典词“北京”和“北京市”。(作者也提到存在匹配得来的词与原句语境无关的情况,这些噪声对NER的影响将在后续研究中讨论,不在这篇论文的研究范围内。)
问题二:怎么利用Lattice格子融合char和词边界信息?
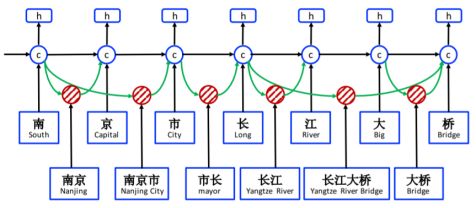
我们先来看上图,这是Lattice LSTM结构图,底部蓝色框内的字和词典词组成了LSTM的输入。图中h表示字的LSTM output,c表示字的LSTM cell。图中cell之间黑色的箭头表示基于字的循环信息流,cell之间绿色的箭头表示基于词的循环信息流。为了更加直观一些,我们擦除掉词典词的信息,如下图,剩余部分就是常见的基于字的LSTM结构。

这篇论文提出的基于Lattice的字-词典词融合,就是在字级cell中累加以该字结尾的词级cell信息流,如下图以“桥”为例,则需把“长江大桥”和“大桥”两个词的cell信息流,累加到"桥"这个字的cell信息流中。
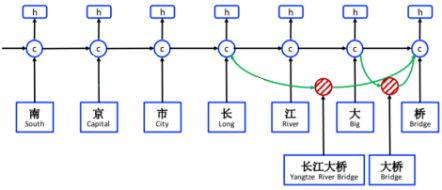
到此,就完整地介绍了Lattice LSTM结构。
接下来,我们看看Lattice LSTM具体是如何实现呢?
第一步,计算字级cell信息流,和常规的LSTM计算公式相同,计算公式如下,其中上标c表示char。
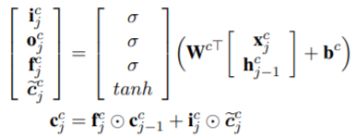
第二步,计算词级cell信息流,计算公式如下,其中上标w表示word。词级cell和字级cell的计算区别在于,公式中绿色框出的部分,字级cell的输入是前一个字的隐层输出hj-1,而词级cell的输入是当前词的第一个字的隐层输出hb,其中下标b表示begin;另一个区别是,词级cell只需计算input gate和forget gate这两个LSTM gate,无需计算output gate,因为不对词进行序列标注,没有输出。
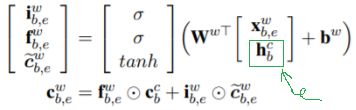
第三步,在每个字级cell中累加以该字结尾的词级cell信息流,计算公式如下,其中a是归一化后的加权系数。

第四步,利用融合了词信息的字cell信息流cj,计算基于字的LSTM输出,计算公式如下。这里要特别说明的是,只对字进行序列标注,不对词进行序列标注,所以也就只有基于字的LSTM输出。
![]()
2.2.4 FLAT
ACL 2020论文《FLAT: Chinese NER Using Flat-Lattice Transformer》将本文前一节介绍的Lattice引入到Transformer中。这样做的好处很多,比如解决了Lattice LSTM无法并行的问题,以及使得字和词典词信息的融合更加灵活。
总结来讲,这篇论文主要做了两个工作:
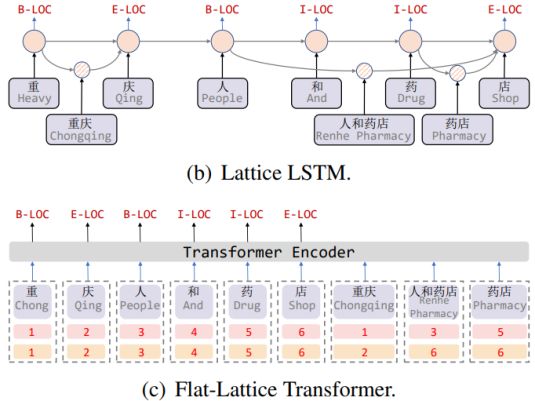
第一个工作是把Lattice铺平(flat)作为Transformer的输入,引入head和tail编码,从而替代Lattice的层级结构。Lattice LSTM和FLAT的对比图更加直观一些,如下图,与Lattice LSTM不同的是,在FLAT的输入中,字和词典词并列作为Transformer的输入,第一行橙色数字表示当前字/词的head位置编码,第二行橙色数字表示当前字/词的tail位置编码,这使得可以从FLAT中重建Lattice的层级结构,所以作者认为FLAT保留了Lattice结构。
这篇论文的第二个工作是采用了相对位置编码,计算公式如下,使得在self-Attention的向量点乘计算中最大化保留方向信息。
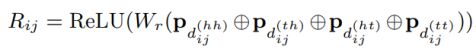
其中,W_r是参数,⊕表示拼接,P_d是论文《Attention is all you need》中的三角函数位置编码,计算公式如下,大家都有所了解,这里就不详细介绍了。
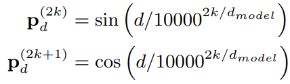
这里要介绍的是公式中的 dhh、dth、dht、dtt,这是这篇论文提出的四种相对距离,用于表示两个字/词之间的关系,计算公式如下。
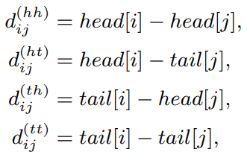
其中,head[i]、tail[i]就是前文介绍的在FLAT的输入中的两行橙色数字。以 dhh 为例,表示 xi 的第一个字与 xj 的第一个字的距离。
3.NER优化/拓展
3.1 模型加速与优化
3.1.1 加速包cudnn-LSTM
如果采用BERT+bi-LSTM+CRF模型,可能无法满足企业的模型性能要求。关键问题在于bi-LSTM的推理耗时较高,是拖慢推理速度的主要模块。最简单的解决方法是使用cudnn-LSTM 这个Python包,它基于nvidia显卡实现了LSTM的加速优化。
3.1.2 优化CRF路径选择
说到NER模型优化,不得不提到一篇有意思的论文。
论文《Masked Conditional Random Fields for Sequence Labeling》:尽管CRF在NER任务中取得了巨大的成功,但是偶尔会生成非法的标签序列,例如在“O”标签之后包含“I-”标签的序列,这是底层 BIO 标签方案所禁止的。为了解决这个问题,现有的方法是采用人工制作的后处理规则,正如本文前一章节所提到的,重新修正非法段的标记。但这种处理是任意的,会导致性能欠佳。这篇论文提出了Masked Conditional Random Field (Masked-CRF),这是一种易于实现的变体 CRF,它可以掩盖 CRF 训练期间的非法转换,把原来的路径搜索空间P缩减到路径搜索空间P - I,其中I是非法路径集合,以有原则的方式消除非法结果。
掩盖CRF训练期间的非法转换路径的方法如图:

上图是对CRF的转移矩阵做了一些改动,其中 a13 被掩码,在图上标注为红色,即非法路径的一部分,是由于标注为 O 的字和标注为 I 的字不可能相邻,其状态转移概率值被替换为 c,一个远小于零的数字。采用掩码的目的是惩罚非法转换,使它们在维特比解码期间永远不会被选中,并且非法路径作为一个整体在训练期间仅构成可忽略不计的概率质量。这些非法路径组成了非法转移集合 Ω。
3.2 数据增强方法
3.2.1 规则模板 + 领域实体词典
对于模型难学习的口语化样本比如“我要吃北京烤鸭”,把“要吃”用标签“[D: search]”替换,把”北京烤鸭”用标签”[D: poi_type]”替换,构建这样一个句式模板,结合标签对应领域的实体词典,生成并扩充样本。