Pytorch实现多分类问题——Pytorch学习笔记二
本文所记录的内容是观看B站刘二大人的相关pytorch教学视频所做的笔记
视频链接:Pytorch深度学习实践
目录
一、多分类问题
1.softmax()
2.NNLLoss()函数——不建议使用
3.CrosssEntropyLoss()——建议采用
二、代码实现
1.数据集的下载和预处理
2.构建模型
3.定义优化器和损失函数
4.开始训练模型并测试
三、完整代码
一、多分类问题
1.softmax()
解决多分类问题,一般会在神经网络的输出最后一层使用softmax()函数,来获得每一个类别的预测概率。
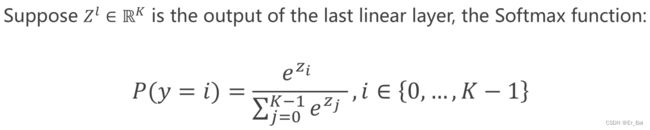
2.NNLLoss()函数——不建议使用
计算多分类问题的交叉熵有三个步骤:softmax过程,求log过程,以及最后取负相乘求和。NNLLoss()函数实现的就是最后一步:取负相乘求和。
【参考这个博主的博客:深度学习方法——NLLloss简单概括_时生丶的博客-CSDN博客_nllloss】
3.CrosssEntropyLoss()——建议采用
这个函数就是在求交叉熵损失,使用这个函数的好处是它能够同时实现softmax过程,求log过程,以及最后的交叉熵损失计算,使用这个函数可以避免分开定义softmax运算和交叉熵损失函数可能会造成数值不稳定,为什么分开定义会造成数值不稳定,原因如下:
softmax使用了exp,当上一个输出结点的输出较大时,可能会使得softmax的输出出现数值溢出(0.9999090990909090909078787890850980...之类的,超出数值类型的保存范围),同时再使用交叉熵,也会出现数值溢出的情况,所以会造成最后的交叉熵数值不稳定。

二、代码实现
首先导入如下功能包:
"""利用Mnist数据集实现多分类"""
import torch
import visdom # 绘图工具
from torchvision import datasets # 获取MNIST数据集的功能包
from torchvision import transforms # 对数据集进行类型处理的包
from torch.utils.data import DataLoader # 将数据集分成小批量过程使用到的
1.数据集的下载和预处理
# 将WxHxC转化成张量CxWxH,ToTensor()来实现, 再把像素值都转化成0-1
transform = transforms. Compose([
# 化成torch.tensor类型数据,因为原始的数据集可能是PIL或者numpy.array()等各种类型
transforms.ToTensor(),
# 归一化处理(正态分布)(均值,方差)
transforms. Normalize((0.1307,), (0.3018,))
])
"""以下步骤执行之后,数据train_loader和test_loader都是N(batch_size)X1X28X28,需要在后续变换形状为N(样本数)X784"""
batch_size = 64 # 如若显卡超内存,可以往下修改为32、16等
# 下载训练数据集,下载到C://用户名//dataset//mnist文件夹下, 并且对数据进行类型处理(transform)
train_dataset = datasets.MNIST(root=".//dataset//mnist", train=True, download=True, transform=transform)
# 分成批量数据集,打乱,同时每一批次有batch_size个样本
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
# 下载测试数据集,并且对数据进行类型处理(transform)
test_dataset = datasets.MNIST(root=".//dataset//mnist", train=False, download=True, transform=transform)
# 分成批量数据集,打乱,同时每一批次有batch_size个样本
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)2.构建模型
# 定义模型
class Model(torch.nn.Module): # Model继承自torch.nn.Module
def __init__(self):
super(Model, self).__init__() # 复写父类的初始化
self.linear1 = torch.nn.Linear(784, 512)
self.linear2 = torch.nn.Linear(512, 256)
self.linear3 = torch.nn.Linear(256, 128)
self.linear4 = torch.nn.Linear(128, 64)
self.linear5 = torch.nn.Linear(64, 10)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = x.view(-1, 784) # 每一行是一个样本
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.relu(self.linear3(x))
x = self.relu(self.linear4(x))
return self.linear5(x)
# 也可以这么写
class Model(torch.nn.Module): # Model继承自torch.nn.Module
def __init__(self):
super(Model, self).__init__() # 复写父类的初始化
self.model = torch.nn.Sequential(
nn.Flatten(1, -1) # 将batch_sizeXchannelXWXH-->batch_sizeX784(channel*W*H) 注意:channel=1
torch.nn.Linear(784, 512)
torch.nn.ReLU()
torch.nn.Linear(512, 256)
torch.nn.ReLU()
torch.nn.Linear(256, 128)
torch.nn.ReLU()
torch.nn.Linear(128, 64)
torch.nn.ReLU()
torch.nn.Linear(64, 10)
torch.nn.ReLU()
)
def forward(self, x):
return self.model(x)
# 生成模型
model = Model()
3.定义优化器和损失函数
# 损失函数
loss = torch.nn.CrossEntropyLoss()
# 优化器
# model.parameters会自动获取模型里面的所有参数
# lr是学习率
# momentum 是 动量因子,具体介绍可以参考这位博主的博客https://blog.csdn.net/dbdxwyl/article/details/122209565
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5)4.开始训练模型并测试
# 一次迭代训练函数
def train(epoch):
running_loss = 0.0
# enumerate即为循环遍历,同时返回索引和遍历数据,这里的0是指返回的索引从0开始
# enumerate解读
# lists = ['A', 'B', 'C']
# for i in lists:
# print(i)
# 结果是:
# A
# B
# C
# for idx, i in enumerate(list, 0)
# print(idx, i)
# 结果是:
# 0 A
# 1 B
# 2 C
for batch_idx, data in enumerate(train_loader, 0):
# 获取batch数据
inputs, labels = data
# forward
outputs = model(inputs)
l = loss(outputs, labels)
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
# backward
optimizer.zero_grad() # 梯度清零
l.backward()
# update
optimizer.step()# 测试函数
def test():
correct = 0 # 正确的数目
total = 0 # 总数目
# 测试时不需要计算梯度,不需要反向传播
with torch.no_grad():
for data in test_loader: # 取出测试数据
inputs, labels = data
outputs = model(inputs)
# 最大值,最大值下标
# predict = torch. Argmax(output.data, dim=1) # 用这句话也行
_, predicted = torch.max(outputs.data, dim=1) # dim=1意味着在(从左往右)上查找每一行的最大值作为实际
total += labels.size(0) # labels是一个NX1的矩阵,size是(N,1)的元组,所以size(0)是N
correct += (predicted == labels).sum().item() # 统计一次批量中预测正确的情况,相加作为正确预测数目
print('Accuracy on test set: %d %%' % (100 * correct / total))
# 使用visdom更新图像
vis.line(X=[epoch+1], Y=[100 * correct / total], win=acc_window, opts=opt, update='append')三、完整代码
代码中使用到的visdom的使用方法可以见我另外一篇博客:Visdom绘制损失函数图像_Er_Bai的博客-CSDN博客_利用visdom绘制损失函数可视化变化图
"""利用Mnist数据集实现多分类"""
import torch
import visdom
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
# 把像素值都转化成0-1,并将WxHxC转化成张量CxWxH,ToTensor()来实现
transform = transforms.Compose([
# 化成张量
transforms.ToTensor(),
# 归一化处理,均值,方差
transforms.Normalize((0.1307,), (0.3018,))
])
# 模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(784, 512)
self.linear2 = torch.nn.Linear(512, 256)
self.linear3 = torch.nn.Linear(256, 128)
self.linear4 = torch.nn.Linear(128, 64)
self.linear5 = torch.nn.Linear(64, 10)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = x.view(-1, 784)
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.relu(self.linear3(x))
x = self.relu(self.linear4(x))
return self.linear5(x)
# 一次迭代训练函数
def train(epoch):
running_loss = 0.0
# enumerate即为循环遍历,同时返回索引和遍历数据,这里的0是指返回的索引从0开始
for batch_idx, data in enumerate(train_loader, 0):
# 获取batch数据
inputs, labels = data
# forward
outputs = model(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
# backward
optimizer.zero_grad() # 梯度清零
loss.backward()
# update
optimizer.step()
# 测试函数
def test():
correct = 0 # 正确的数据
total = 0 # 总数据
# 测试时不需要计算梯度,不需要反向传播
with torch.no_grad():
for data in test_loader:
inputs, labels = data
outputs = model(inputs)
# 最大值,最大值下标
_, predicted = torch.max(outputs.data, dim=1) # dim=1意味着在行维度上查找最大值
total += labels.size(0) # labels是一个NX1的矩阵,size是(N,1)的元组,所以size(0)是N
correct += (predicted == labels).sum().item() # 张量之间的比较运算
print('Accuracy on test set: %d %%' % (100 * correct / total))
# 更新图像
vis.line(X=[epoch+1], Y=[100 * correct / total], win=acc_window, opts=opt, update='append')
if __name__ == '__main__':
batch_size = 64
# 数据准备
"""这里都是张量,但对于小批量来说张量都是N(样本数)X1X28X28,,需要在后续变换形状为N(样本数)X784"""
train_dataset = datasets.MNIST(root=".//dataset//mnist", train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root=".//dataset//mnist", train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# 模型定义
model = Model()
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 绘图
vis = visdom.Visdom(env='main') # 设置环境窗口的名称,如果不设置名称就默认为main
opt = {
'xlabel': 'epochs',
'ylabel': 'loss_value',
'title': 'accuracy'
}
acc_window = vis.line(
X=[0],
Y=[0],
opts=opt
)
# 训练100次
for epoch in range(100):
train(epoch)
test()