支持向量机—核函数详解
文章目录
- 背景
- 引入核函数的SVM
- 常用核函数
- 非线性SVM算法流程
背景
支持向量机可以解决线性可分数据的分类问题,对于非线性可分的数据分类问题,SVM通过引入核函数实现。
如下图所示:
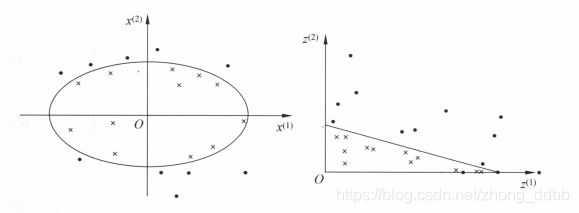
左图数据是线性不可分的,SVM无法直接进行分类。通过某种变换将数据转为右图所示的数据分布情况,这样数据就变成了线性可分了。就可以通过SVM算法轻松的实现分类。
设原始特征空间为: X ⊂ R 2 , x = ( x ( 1 ) , x ( 2 ) ) T ∈ X \mathcal X \subset R^2,x = (x^{(1)}, x^{(2)})^T \in \mathcal X X⊂R2,x=(x(1),x(2))T∈X,新的特征空间为: Z ⊂ R 2 , z = ( z ( 1 ) , z ( 2 ) ) T ∈ Z \mathcal Z \subset R^2,z = (z^{(1)}, z^{(2)})^T \in\mathcal Z Z⊂R2,z=(z(1),z(2))T∈Z。
定义原空间到新空间的映射为:
z = ϕ ( x ) = ( ( x ( 1 ) ) 2 , ( x ( 2 ) ) 2 ) T z = \phi(x) = ((x^{(1)})^2, (x^{(2)})^2)^T z=ϕ(x)=((x(1))2,(x(2))2)T
则原空间的椭圆:
w 1 ( x ( 1 ) ) 2 + w 2 ( x ( 2 ) ) 2 + b = 0 w_1(x^{(1)})^2 + w_2(x^{(2)})^2 + b = 0 w1(x(1))2+w2(x(2))2+b=0
变为了新空间的直线:
w 1 z ( 1 ) + w 2 z ( 2 ) + b = 0 w_1 z^{(1)} + w_2 z^{(2)} + b = 0 w1z(1)+w2z(2)+b=0
于是,只要把所有的样本都映射到新的空间中,就可以用线性可分SVM完成分类了。我们称这样的变换思想为核技巧。
这个过程中的关键步骤是如何找到这个变换将原空间的数据映射到新空间。这也是引入核函数的目的。
引入核函数的SVM
1、 核函数的定义:设 X \mathcal X X是输入空间, H \mathcal H H 是特征空间,存在一个 X \mathcal X X 到 H \mathcal H H 的映射:
ϕ ( x ) : X → H \phi(x): \mathcal X \rightarrow \mathcal H ϕ(x):X→H
使得对所有的 x , z ∈ X x,z \in \mathcal X x,z∈X ,函数 K ( x , z ) K(x,z) K(x,z) 满足条件:
K ( x , z ) = ϕ ( x ) ⋅ ϕ ( z ) K(x,z) = \phi(x) \cdot \phi(z) K(x,z)=ϕ(x)⋅ϕ(z)
则称 K ( x , z ) K(x,z) K(x,z) 为核函数, ϕ ( x ) \phi(x) ϕ(x) 为映射函数。
核技巧 的想法是:在学习与预测中只定义核函数 K ( x , z ) K(x,z) K(x,z) ,而不是现实的定义映射函数 ϕ \phi ϕ 。因为直接计算 K ( x , z ) K(x,z) K(x,z) 比较容易,而通过计算 ϕ ( x ) , ϕ ( z ) \phi(x),\phi(z) ϕ(x),ϕ(z) 计算 K ( x , z ) K(x,z) K(x,z) 计算量较大。
核函数和映射之间的关系:
(1)一个输入空间可以映射到不同的特征空间。
(2)同一特征空间也可以取不同的映射,即不同的映射实现同一种特征空间变换。
已知映射函数 ϕ \phi ϕ 中,可以通过中 ϕ ( x ) \phi(x) ϕ(x) 和 ϕ ( z ) \phi(z) ϕ(z) 的内积求得核函数 K ( x , z ) K(x, z) K(x,z)。不用构造映射 ϕ ( x ) \phi(x) ϕ(x)能否直接判断一个给定的函数K ( x , z ) (x,z) (x,z)是不是核函数? 或者说,函数 K ( x , z ) K(x,z) K(x,z)满足什么条件才能成为核函数?下面给出核函数(正定核函数)充分必要条件:
对任意的 x i ∈ X , i = 1 , 2 … , m , K ( x , z ) x_i \in \mathcal X, i=1,2\ldots,m, K(x,z) xi∈X,i=1,2…,m,K(x,z) 对应的Gram矩阵:
K = [ K ( x i , x j ) ] m × m K = [K(x_i,x_j)]_{m\times m} K=[K(xi,xj)]m×m
是半正定矩阵。此时 K ( x i , x j ) K(x_i,x_j) K(xi,xj) 称为正定核。
2、核技巧在支持向量机中的应用
回顾线性支持向量机中的目标函数:
min α 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i x j − ∑ i = 1 m α i \min\limits_{\alpha} \;\; \frac{1}{2}\sum\limits_{i=1}^{m} \sum\limits_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_ix_j - \sum\limits_{i=1}^{m}\alpha_i αmin21i=1∑mj=1∑mαiαjyiyjxixj−i=1∑mαi
决策函数(分离超平面):
f ( x ) = s i g n ( ∑ i = 1 m α i ∗ y i x i x + b ∗ ) f(x) = sign(\sum\limits_{i=1}^{m}\alpha_i^{*}y_ix_ix+ b^{*}) f(x)=sign(i=1∑mαi∗yixix+b∗)
都只涉及输入实例与实例之间的内积。将核函数引入目标函数则有:
min α 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i x j − ∑ i = 1 m α i min α 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j ϕ ( x i ) ϕ ( x j ) − ∑ i = 1 m α i min α 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j K ( x i ⋅ x j ) − ∑ i = 1 m α i \min\limits_{\alpha} \;\; \frac{1}{2}\sum\limits_{i=1}^{m} \sum\limits_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_ix_j - \sum\limits_{i=1}^{m}\alpha_i\\ \min\limits_{\alpha} \;\; \frac{1}{2}\sum\limits_{i=1}^{m} \sum\limits_{j=1}^{m}\alpha_i\alpha_jy_iy_j\phi (x_i) \phi(x_j) - \sum\limits_{i=1}^{m}\alpha_i \\ \min\limits_{\alpha} \;\; \frac{1}{2}\sum\limits_{i=1}^{m} \sum\limits_{j=1}^{m}\alpha_i\alpha_jy_iy_j K(x_i\cdot x_j) - \sum\limits_{i=1}^{m}\alpha_i αmin21i=1∑mj=1∑mαiαjyiyjxixj−i=1∑mαiαmin21i=1∑mj=1∑mαiαjyiyjϕ(xi)ϕ(xj)−i=1∑mαiαmin21i=1∑mj=1∑mαiαjyiyjK(xi⋅xj)−i=1∑mαi
同样的决策函数:
f ( x ) = s i g n ( ∑ i = 1 m α i ∗ y i K ( x i ⋅ x ) + b ∗ ) f(x) = sign(\sum\limits_{i=1}^{m}\alpha_i^{*}y_iK(x_i\cdot x)+ b^{*}) f(x)=sign(i=1∑mαi∗yiK(xi⋅x)+b∗)
这个过程体现了对偶算法自然引入核函数,减小计算量。
这等价于经过映射函数 ϕ \phi ϕ将原来的输入空间变换到一个新的特征空间,将输入空间中的内积 x i ⋅ x j x_i \cdot x_j xi⋅xj 变换为特征空间中的内积 ϕ ( x i ) ⋅ ϕ ( x j ) \phi(x_i) \cdot\phi(x_j) ϕ(xi)⋅ϕ(xj),在新的特征空间里从训练样本中学习线性支持向量机。当映射函数是非线性函数时,学习到的含有核函数的支持向量机是非线性模型。
常用核函数
1,线性核函数(Linear Kernel)
就是最普通的线性可分SVM,表达式为:
K ( x , z ) = x ⋅ z K(x, z) = x \cdot z K(x,z)=x⋅z
2,多项式核函数(Polynomial Kernel)
是线性不可分常用的核函数之一,表达式为:
K ( x , z ) = ( x ⋅ z + 1 ) p K(x,z)=(x\cdot z + 1)^p K(x,z)=(x⋅z+1)p
对应的支持向量机是一个p次多项式分类器。此时,分类决策函数为:
f ( x ) = s i g n ( ∑ i = 1 N α i ∗ y i ( x ⋅ x i + 1 ) p + b ∗ ) f(x) = sign(\sum\limits_{i=1}^{N}\alpha_i^{*}y_i(x\cdot x_i+1)^p+ b^{*}) f(x)=sign(i=1∑Nαi∗yi(x⋅xi+1)p+b∗)
p越大,维数越高,偏差越低,方差越高,容易出现过拟合的情况,相反维数越低,偏差就会越大,但是方差会随之减小,一般不宜选择过高的维度。
3,高斯核函数(Gaussian Kernel)
在SVM中也称为径向基核函数(Radial Basis Function,RBF),是非线性SVM最主流的核函数,libsvm默认的核函数就是它。表达式为:
K ( x , z ) = e x p ( − ∣ ∣ x − z ∣ ∣ 2 2 σ 2 ) K(x,z) = exp(-\frac{||x-z||^2}{2\sigma^2}) K(x,z)=exp(−2σ2∣∣x−z∣∣2)
其中 σ 2 \sigma^2 σ2是需要指定的超参数。此时,分类决策函数为:
f ( x ) = s i g n ( ∑ i = 1 N α i ∗ y i exp ( − ∣ ∣ x − x i ∣ ∣ 2 2 σ 2 ) + b ∗ ) f(x) = sign(\sum\limits_{i=1}^{N}\alpha_i^{*}y_i \exp(-\frac{||x-x_i||^2}{2\sigma^2})+ b^{*}) f(x)=sign(i=1∑Nαi∗yiexp(−2σ2∣∣x−xi∣∣2)+b∗)
高斯核的偏差和方差通过 σ 2 \sigma^2 σ2来控制, σ 2 \sigma^2 σ2越小,确保了高精度(低偏差)但是却很容易过拟合(高方差)。如下图所示:

其中: γ = 1 σ 2 \gamma = \frac{1}{\sigma^2} γ=σ21
4,Sigmoid核函数(Sigmoid Kernel)
也是线性不可分SVM常用的核函数之一,表达式为:
K ( x , z ) = t a n h ( γ x ∙ z + r ) K(x, z) = tanh(\gamma x \bullet z + r) K(x,z)=tanh(γx∙z+r)
其中 γ , r \gamma , r γ,r是需要指定的超参数。
非线性SVM算法流程
输入:训练集 T = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) T={(x_1,y_1), (x_2,y_2), ..., (x_m,y_m)} T=(x1,y1),(x2,y2),...,(xm,ym),其中x为n维特征向量, y ∈ { − 1 , 1 } y \in \{-1, 1\} y∈{−1,1}。
输出:分离超平面的参数 w ∗ , b ∗ w^*, b^* w∗,b∗以及分类决策函数。
算法流程:
(1) 选择适当的核函数 K ( x , z ) K(x,z) K(x,z)和一个惩罚系数 C > 0 C\gt0 C>0, 构造约束优化问题
min α 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j K ( x i , x j ) − ∑ i = 1 m α i \min\limits_{\alpha} \;\; \frac{1}{2}\sum\limits_{i=1}^{m}\sum\limits_{j=1}^{m}\alpha_i\alpha_jy_iy_jK(x_i,x_j) - \sum\limits_{i=1}^{m}\alpha_i αmin21i=1∑mj=1∑mαiαjyiyjK(xi,xj)−i=1∑mαi
s . t . ∑ i = 1 m α i y i = 0 0 ≤ α i ≤ C s.t. \; \sum\limits_{i=1}^{m}\alpha_iy_i = 0 \\ 0 \leq \alpha_i \leq C s.t.i=1∑mαiyi=00≤αi≤C
(2) 利用SMO算法求出最优解 α ∗ = ( α 1 ∗ , α 2 ∗ , . . . , α m ∗ ) T \alpha^* = (\alpha^*_1, \alpha^*_2, ...,\alpha^*_m)^T α∗=(α1∗,α2∗,...,αm∗)T
(3) 找出所有满足 0 < α s < C 0 < \alpha_s < C 0<αs<C对应的的S个支持向量,对支持向量集合中的每个样本 ( x s , y s ) (x_s,y_s) (xs,ys),通过:
y s ( ∑ i = 1 m α i y i K ( x i , x s ) + b ) = 1 y_s(\sum\limits_{i=1}^{m}\alpha_iy_iK(x_i,x_s)+b) = 1 ys(i=1∑mαiyiK(xi,xs)+b)=1
计算出每个支持向量 ( x s , y s ) (x_s, y_s) (xs,ys)对应的 b s ∗ b_s^{*} bs∗,即:
b s ∗ = y s − ∑ i = 1 m α i y i K ( x i , x s ) b_s^{*} = y_s - \sum\limits_{i=1}^{m}\alpha_iy_iK(x_i,x_s) bs∗=ys−i=1∑mαiyiK(xi,xs)
所有的 b s ∗ b_s^{*} bs∗对应的平均值即为最终的 b ∗ b^* b∗:
b ∗ = 1 S ∑ i = 1 S b s ∗ b^{*} = \frac{1}{S}\sum\limits_{i=1}^{S}b_s^{*} b∗=S1i=1∑Sbs∗
(4) 构造决策函数:
f ( x ) = s i g n ( ∑ i = 1 m α i ∗ y i K ( x , x i ) + b ∗ ) f(x) = sign(\sum\limits_{i=1}^{m}\alpha_i^{*}y_iK(x, x_i)+ b^{*}) f(x)=sign(i=1∑mαi∗yiK(x,xi)+b∗)