【数据挖掘】Kaggle泰坦尼克号分类与预测
一:题目解读
1.1数据读取
读取训练集的数据。
data = pd.read_csv('data/train.csv')
data.head()
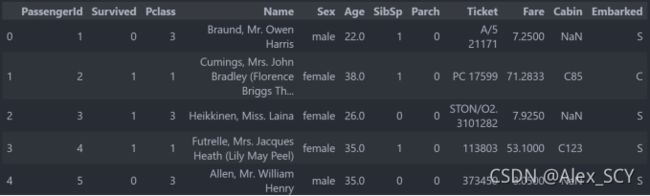
1.2字段解释
PassengerId: 乘客ID
Survived: 是否生存,0代表遇难,1代表还活着
Pclass: 船舱等级:1Upper,2Middle,3Lower
Name: 姓名
Sex: 性别
Age: 年龄
SibSp: 兄弟姐妹及配偶个数
Parch:父母或子女个数
Ticket: 乘客的船票号
Fare: 乘客的船票价
Cabin: 乘客所在的仓位(位置)
Embarked:乘客登船口岸
1.3题目要求
通过除Survived字段外的其他字段,预测出乘客的存活情况
二:数据分析
2.1 数据集整体情况
2.1.1 统计缺失值
data.isnull().sum()
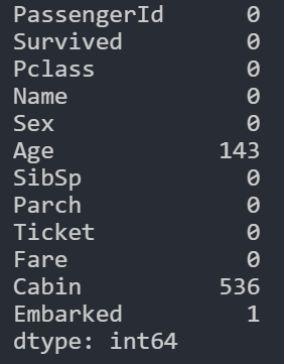
由此可以看到在Age与Cabin中存在大量缺失值,需要要后续数据处理步骤中进行填充。
2.1.2 查看数据统计数据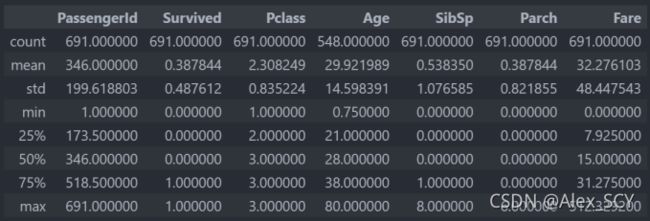
由此可以看到大部分数据的分布情况
2.1.3 查看已知数据集的获救比例
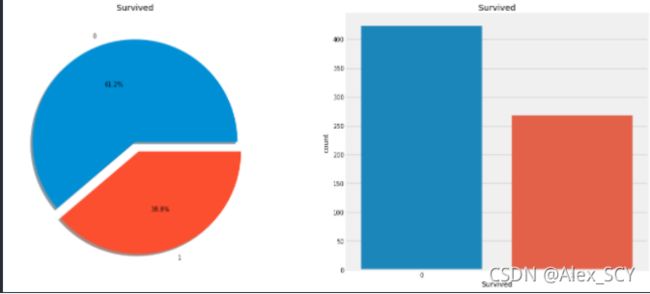
显然,这次事故中没有多少乘客幸免于难。在训练集的691名乘客中,只有大约270人幸存下来,只有38.8%的机组人员在空难中幸存下来。我们需要从数据中挖掘出更多的信息,看看哪些类别的乘客幸存下来,哪些没有。
三:特征分析 & 缺失值填充
在这一部分中,我将对部分特征进行数据分析(性别、船舱等级、年龄、登船地点、兄弟姐妹数量、父母孩子数量、船票价格),分析其与结果之间的相关性。同时对于有缺失值的数据进行填充。
3.1 性别比例和性别获救情况
data.groupby(['Sex', 'Survived'])['Survived'].count() #对性别进行分组,并计数
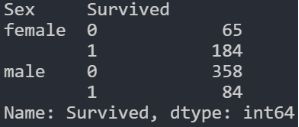

船上的男人比女人多得多。不过,挽救的女性人数几乎是男性的两倍。生存率一个女人在船上是75%左右,而男性在18-19%左右。
3.2 船舱等级跟获救情况的关系
pd.crosstab(data.Pclass, data.Survived, margins = True). style. background_gradient(cmap='summer_r')
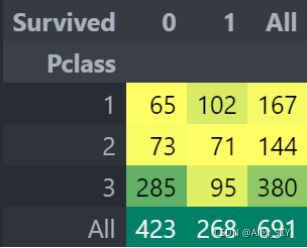

我们可以清楚地看到,船舱等级为1的被给予很高的优先级而救援。尽管数量在pClass 3乘客高了很多,仍然存活数从他们是非常低的,大约25%。对于pClass1来说存活是63%左右,而pclass2大约是48%。所以金钱和地位很重要。
3.3 船舱等级和性别对结果的影响
pd.crosstab([data.Sex,data.Survived], data.Pclass, margins=True).style.background_gradient(cmap='summer_r')
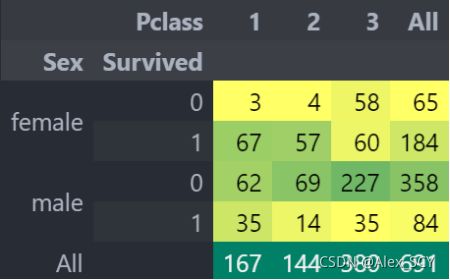

我们可以很容易地推断,从pclass1女性生存是95-96%,如70人中只有3的女性从pclass1没获救。显而易见的是,不论pClass,女性优先考虑。看来Pclass也是一个重要的特征。
3.4 Age对结果的影响
print('Oldest Passenger was of:', data['Age'].max(), 'Years')
print('Youngest Passenger was of:', data['Age'].min(), 'Years')
print('Average Age on the ship:', data['Age'].mean(), 'Years')

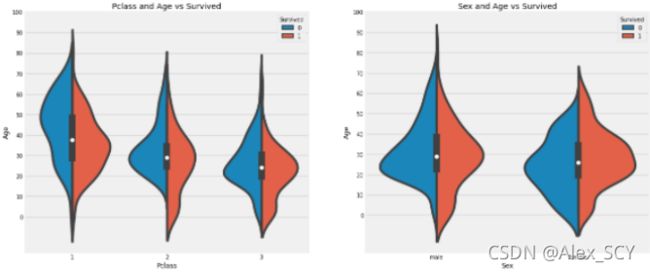
1)10岁以下儿童的存活率随passenegers数量增加。
2)生存为20-50岁获救几率更高一些。
3)对男性来说,随着年龄的增长,存活率降低。
*年龄特征有154个空值。为了替换这些缺失值,我们可以给它们分配数据集的平均年龄。但问题是,有许多不同年龄的人。最好的办法是找到一个合适的年龄段。
data['Initial'] = 0
for i in data:
data['Initial'] = data.Name.str.extract('([A-Za-z]+)\.')
pd.crosstab(data.Initial, data.Sex).T.style.background_gradient(cmap='summer_r') #用性别核对姓名首字母

我们可以检查名字特征。根据这个特征,我们可以看到名字有像先生或夫人这样的称呼,这样我们就可以把先生和夫人的平均值分配给各自的组。
data['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don'],['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr'],inplace=True)
data.groupby('Initial')['Age'].mean()
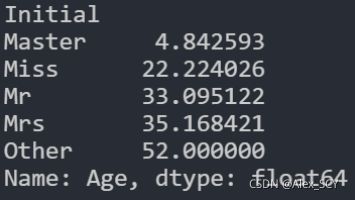
填充缺失值
data.loc[(data.Age.isnull()) & (data.Initial == 'Mr'), 'Age'] = 33
data.loc[(data.Age.isnull()) & (data.Initial == 'Mrs'), 'Age'] = 35
data.loc[(data.Age.isnull()) & (data.Initial == 'Master'), 'Age'] = 5
data.loc[(data.Age.isnull()) & (data.Initial == 'Miss'), 'Age'] = 22
data.loc[(data.Age.isnull()) & (data.Initial == 'Other'), 'Age'] = 52
最终填充后的年龄分布如下图所示:
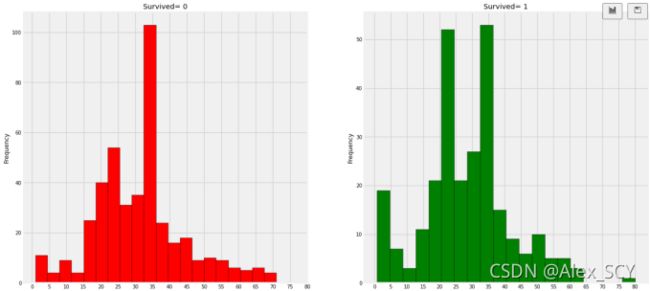

1)幼儿(年龄在5岁以下)获救的还是蛮多的(妇女和儿童优先政策)。
2)最老的乘客得救了(80年)。
3)死亡人数最高的是30-40岁年龄组。
3.5 Embarked–> 登船地点对结果的影响
pd.crosstab([data.Embarked, data.Pclass], [data.Sex, data.Survived], margins=True).style.background_gradient(
cmap='summer_r')
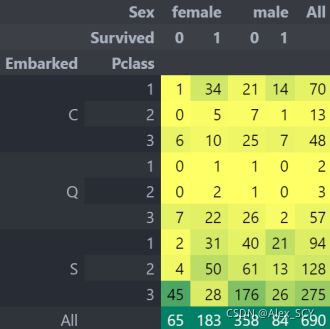
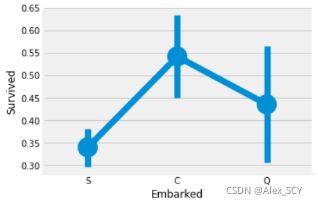
C港生存的可能性最高在0.55左右,而S的生存率最低。
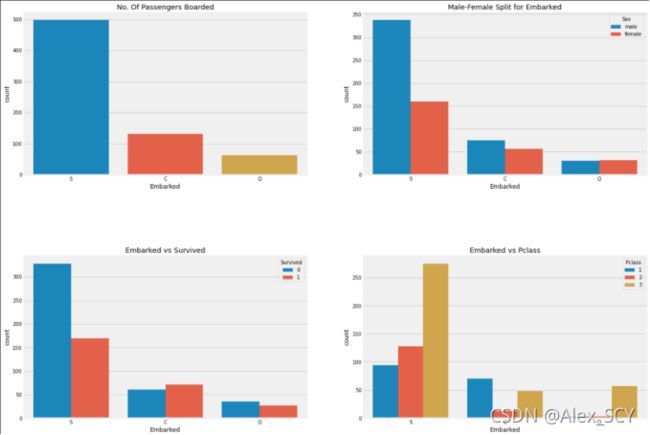
1)大部分人的船舱等级是3。
2)C的乘客看起来很幸运,他们中的一部分幸存下来。
3)S港口的富人蛮多的。仍然生存的机会很低。
4)港口Q几乎有95%的乘客都是穷人。
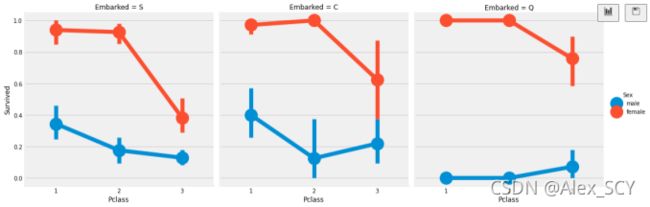
1)存活的几率几乎为1 在pclass1和pclass2中的女人。
2)pclass3 的乘客中男性和女性的生存率都是很偏低的。
3)端口Q很不幸,因为那里都是3等舱的乘客。
港口中也存在缺失值,在这里我用众数来进行填充了,因为S登船人最多
3.6 sibsip -->兄弟姐妹的数量对结果的影响
这个特征表示一个人是独自一人还是与他的家人在一起。
pd.crosstab([data.SibSp], data.Survived).style.background_gradient(cmap='summer_r')



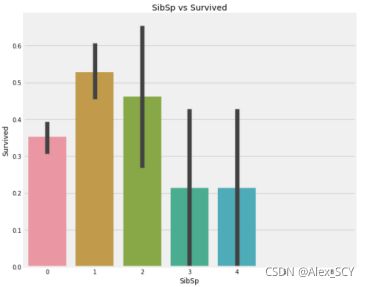
barplot和factorplot表明,如果乘客是孤独的船上没有兄弟姐妹,他有35%的存活率。如果兄弟姐妹的数量增加,该图大致减少。这是有道理的。也就是说,如果我有一个家庭在船上,我会尽力拯救他们,而不是先救自己。但是令人惊讶的是,5-8名成员家庭的存活率为0%。原因可能是他们在pclass=3的船舱。
3.7 Parch --> 父母和孩子的数量对结果的影响
pd.crosstab(data.Parch, data.Pclass).style. background_gradient(cmap='summer_r')
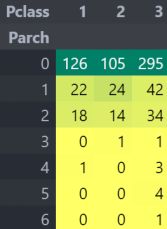
再次表明,大家庭都在pclass3。
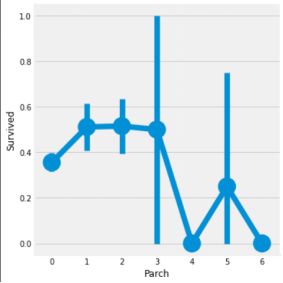

这里的结果也很相似。带着父母的乘客有更大的生存机会。然而,它随着数字的增加而减少。在船上的家庭父母人数中有1-3个的人的生存机会是好的。独自一人也证明是致命的,当船上有4个父母时,生存的机会就会减少。
3.8 Fare–> 船票的价格对结果的影响
print('Highest Fare was:', data['Fare'].max())
print('Lowest Fare was:', data['Fare'].min())
print('Average Fare was:', data['Fare'].mean())
可以看到最高、最低、平均的船票价格。


3.9 数据分析总结
- 性别:与男性相比,女性的生存机会很高。
- Pclass:有,第一类乘客给你更好的生存机会的一个明显趋势。对于pclass3成活率很低。对于女性来说,从pclass1生存的机会几乎是。
- 年龄:小于5-10岁的儿童存活率高。年龄在15到35岁之间的乘客死亡很多。
- 港口:上来的仓位也有区别,死亡率也很大。
- 家庭:有1-2的兄弟姐妹、配偶或父母上1-3显示而不是独自一人或有一个大家庭旅行,你有更大的概率存活。
四:特征工程
特征之间的相关性
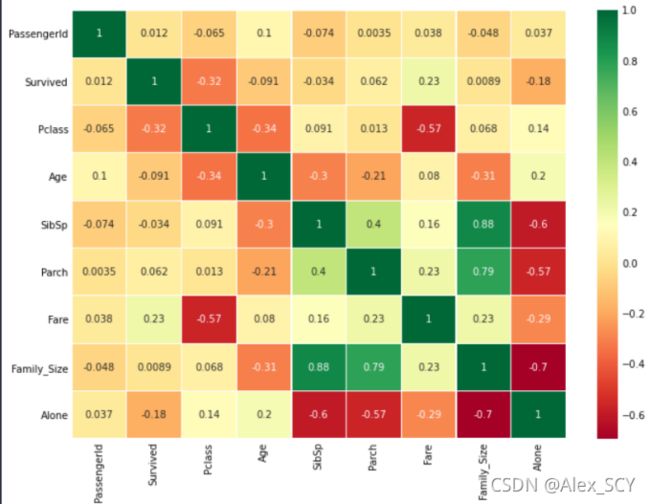
在制作或训练模型时,我们应该尽量减少冗余特性,因为它减少了训练时间和许多优点。
现在,从上面的图,我们可以看到,特征不显著相关。
在此部分中,我将对一些连续/离散特征进行处理(年龄、家庭总人数、船票价格、性别、登船地点、称谓),以便进行模型训练。
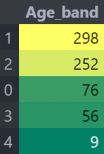
4.1 年龄特征Age_band
data['Age_band'] = 0
data.loc[data['Age'] <= 16, 'Age_band'] = 0
data.loc[(data['Age'] > 16) & (data['Age'] <= 32), 'Age_band'] = 1
data.loc[(data['Age'] > 32) & (data['Age'] <= 48), 'Age_band'] = 2
data.loc[(data['Age'] > 48) & (data['Age'] <= 64), 'Age_band'] = 3
data.loc[data['Age'] > 64, 'Age_band'] = 4
年龄是连续的特征,在机器学习模型中存在连续变量的问题。我们需要对连续值进行离散化来分组。乘客的最大年龄是80岁。所以我们将范围从0-80成5项。所以80/5=16。
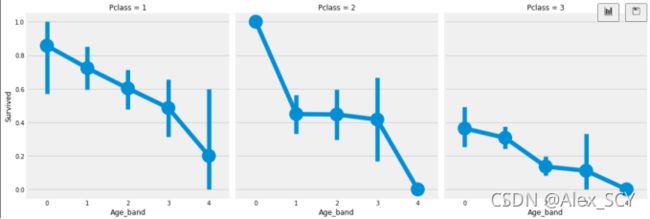
生存率随年龄的增加而减少,不论Pclass。
4.2 家庭总人数Family_size
data['Family_Size'] = 0
data['Family_Size'] = data['Parch'] + data['SibSp'] #family size
data['Alone'] = 0
data.loc[data.Family_Size == 0, 'Alone'] = 1 #Alone
光看兄弟姐妹和老人孩子看不太直接,咱们直接看全家的人数
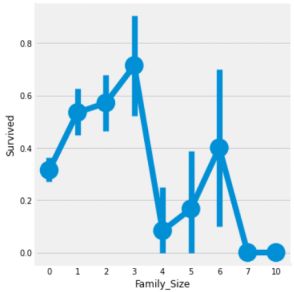

family_size = 0意味着passeneger是孤独的。显然,如果你是单独或family_size = 0,那么生存的机会很低。家庭规模4以上,机会也减少。
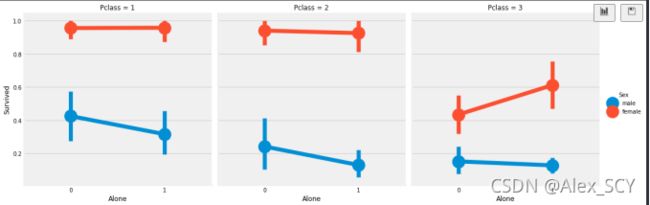
4.3 船票价格Fare_cat
因为票价也是连续的特性,所以我们需要将它转换为数值。
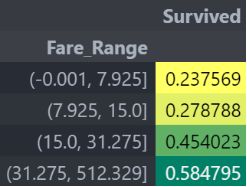
我们可以清楚地看到,船票价格增加生存的机会增加。
data['Fare_cat'] = 0
data.loc[data['Fare'] <= 7.925, 'Fare_cat'] = 0
data.loc[(data['Fare'] > 7.925) & (data['Fare'] <= 15.0), 'Fare_cat'] = 1
data.loc[(data['Fare'] > 15.0) & (data['Fare'] <= 31.275), 'Fare_cat'] = 2
data.loc[(data['Fare'] > 31.275) & (data['Fare'] <= 512.329), 'Fare_cat'] = 3
因为我根据船票的价格,每25%为一档进行了分类处理。最终结果如下:

显然,随着fare_cat增加,存活的几率增加。随着性别的变化,这一特性可能成为建模过程中的一个重要特征。
4.4 性别、登船地点、称谓特征
data['Sex'].replace(['male', 'female'], [0, 1], inplace=True)
data['Embarked'].replace(['S', 'C', 'Q'], [0, 1, 2], inplace=True)
data['Initial'].replace(['Mr', 'Mrs', 'Miss', 'Master', 'Other'], [0, 1, 2, 3, 4], inplace=True)
将字符串值转换为数字 因为我们不能把字符串一个机器学习模型
五:数据清洗
去掉不必要的特征
- 名称:我们不需要name特性,因为它不能转换成任何分类值
- 年龄:我们有age_band特征,所以不需要这个
- 票号:这是任意的字符串,不能被归类
- 票价:我们有fare_cat特征,所以不需要
- 船仓号:这个也不要没啥含义
- passengerid :不能被归类
data.drop(['Name', 'Age', 'Ticket', 'Fare', 'Cabin', 'Fare_Range', 'PassengerId'], axis=1, inplace=True)
六:预测模型
6.1 测试集数据处理
对测试集做类似于测试集的数据特征处理
test_data = pd.read_csv('data/test.csv',header=None,names=['PassengerId','Survived','Pclass','Name','Sex','Age','SibSp','Parch','Ticket','Fare','Cabin','Embarked'])
test_data.head()
test_data['Initial'] = 0
for i in test_data:
test_data['Initial'] = test_data.Name.str.extract('([A-Za-z]+)\.')
test_data['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don'],['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr'],inplace=True)
## 使用每组的均值来进行填充
test_data.loc[(test_data.Age.isnull()) & (test_data.Initial == 'Mr'), 'Age'] = 33
test_data.loc[(test_data.Age.isnull()) & (test_data.Initial == 'Mrs'), 'Age'] = 35
test_data.loc[(test_data.Age.isnull()) & (test_data.Initial == 'Master'), 'Age'] = 5
test_data.loc[(test_data.Age.isnull()) & (test_data.Initial == 'Miss'), 'Age'] = 22
test_data.loc[(test_data.Age.isnull()) & (test_data.Initial == 'Other'), 'Age'] = 52
test_data['Embarked'].fillna('S', inplace=True)
test_data['Age_band'] = 0
test_data.loc[test_data['Age'] <= 16, 'Age_band'] = 0
test_data.loc[(test_data['Age'] > 16) & (test_data['Age'] <= 32), 'Age_band'] = 1
test_data.loc[(test_data['Age'] > 32) & (test_data['Age'] <= 48), 'Age_band'] = 2
test_data.loc[(test_data['Age'] > 48) & (test_data['Age'] <= 64), 'Age_band'] = 3
test_data.loc[test_data['Age'] > 64, 'Age_band'] = 4
test_data['Family_Size'] = 0
test_data['Family_Size'] = test_data['Parch'] + test_data['SibSp'] #family size
test_data['Alone'] = 0
test_data.loc[test_data.Family_Size == 0, 'Alone'] = 1 #Alone
test_data['Fare_Range'] = pd.qcut(test_data['Fare'], 4)
test_data['Fare_cat'] = 0
test_data.loc[test_data['Fare'] <= 7.91, 'Fare_cat'] = 0
test_data.loc[(test_data['Fare'] > 7.91) & (test_data['Fare'] <= 14.454), 'Fare_cat'] = 1
test_data.loc[(test_data['Fare'] > 14.454) & (test_data['Fare'] <= 31), 'Fare_cat'] = 2
test_data.loc[(test_data['Fare'] > 31) & (test_data['Fare'] <= 513), 'Fare_cat'] = 3
test_data['Sex'].replace(['male', 'female'], [0, 1], inplace=True)
test_data['Embarked'].replace(['S', 'C', 'Q'], [0, 1, 2], inplace=True)
test_data['Initial'].replace(['Mr', 'Mrs', 'Miss', 'Master', 'Other'], [0, 1, 2, 3, 4], inplace=True)
test_data.drop(['Name', 'Age', 'Ticket', 'Fare', 'Cabin', 'Fare_Range', 'PassengerId'], axis=1, inplace=True)
最终测试集与训练集的数据如下图所示

6.2 切分训练集与测试集
train_X = data[data.columns[1:]]
train_Y = data[data.columns[:1]]
test_X = test_data[test_data.columns[1:]]
test_Y = test_data[test_data.columns[:1]]
train_X为训练输入数据(各种特征),train_Y为训练输出数据(存活标签)
Test_X为测试输入数据(各种特征),test_Y为测试输出数据(存活标签)
6.3 Logistic Regression模型
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(train_X, train_Y)
prediction3 = model.predict(test_X)
print('The accuracy of the Logistic Regression is', metrics.accuracy_score(prediction3, test_Y))
Logistic Regression模型的准确率为82.5%。
![]()
6.4 Gradient Boosting Classifier模型
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier()
model.fit(train_X,train_Y)
prediction4 = model.predict(test_X)
print('The accuracy of the GradientBoostingClassifier is', metrics.accuracy_score(prediction4, test_Y))
Gradient Boosting Classifier模型的准确率为85.5%。
![]()
七:模型评估
绘制混淆矩阵
from sklearn.model_selection import cross_val_predict #prediction
f,ax=plt.subplots(1,2,figsize=(12,6))
model = LogisticRegression()
model.fit(train_X, train_Y)
prediction1 = model.predict(test_X)
sns.heatmap(confusion_matrix(prediction1,test_Y),ax=ax[0],annot=True,fmt='2.0f')
ax[0].set_title('Matrix for Logistic Regression')
print('The accuracy-score of the Logistic Regression is', metrics.accuracy_score(prediction1, test_Y))
print('The recall-score of the Logistic Regression is', metrics.recall_score(prediction1, test_Y))
print('The f1-score of the Logistic Regression is', metrics.f1_score(prediction1,test_Y))
model = GradientBoostingClassifier()
model.fit(train_X, train_Y)
prediction2 = model.predict(test_X)
sns.heatmap(confusion_matrix(prediction2,test_Y),ax=ax[1],annot=True,fmt='2.0f')
ax[1].set_title('Matrix for GradientBoostingClassifier')
print('The accuracy-score of the GradientBoostingClassifier is', metrics.accuracy_score(prediction2, test_Y))
print('The recall-score of the GradientBoostingClassifier is', metrics.recall_score(prediction2, test_Y))
print('The f1-score of the GradientBoostingClassifier is', metrics.f1_score(prediction2,test_Y))
plt.subplots_adjust(hspace=0.2,wspace=0.2)
plt.show()
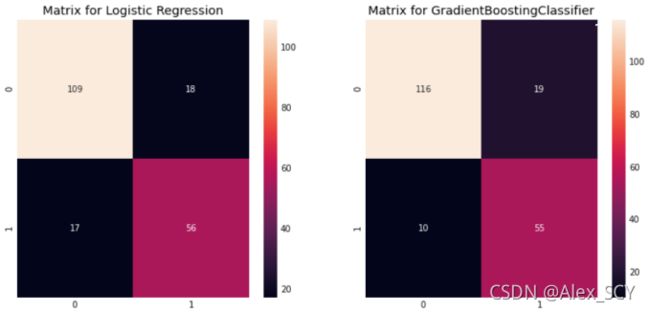
假定Survived=1(获救)为正例,Survived=0(遇难)为负例:
Logistic Regression模型:

Gradient Boosting Classifier模型:

由此可见,基于Gradient Boosting Classifier相对而言更好。