kaggle经典题--“泰坦尼克号”--0.8275准确率--东北大学20级python大作业开源(附详细解法与全部代码以及实验报告)
kaggle经典题--“泰坦尼克号”--0.8275准确率--东北大学20级python大作业开源(附详细解法与全部代码以及实验报告)
- 前言
- 开发环境
- 一、导入包:
- 二、实验数据的读取,合并,以及显示info
- 三、数据的预处理
-
- (1)离散型字符串特征的处理
-
- 性别(Sex)的处理
- 港口Embarked处理
- (2)通过可视化来分析不同的特征数据
-
- Pclass、Sex、Embarked、SlibSp、Parch、Survived的存活与死亡的数据的可视化
- Pclass、Sex、Embarked、SlibSp、Parch、Survived的Sex数据可视化
- 各个特征的相关系数图
- (3)对于缺失值的处理
-
- 填充Age
-
- Age直方图
- ==Age离散化操作==
- 填充Fare
-
- Fare直方图
- ==Fare离散化操作==
- 填充Embarked
- 删除Cabin
- 四、特征选择
-
- (1)对于Name特征的处理,处理Name的身份
- (2)Title变为离散变量
- (3)SibSp与Parch的特征分析
- (4)Ticket特征分析
- (5)Woman or Child特征分析
- (6)新建列Family_TotalCount, Family_SurviviedCount和Family_SurvivalRate
- 五、分类器构建
- 六、模型验证
-
- (1)提取测试集与训练集数据
- (2)标准化处理
- (3)模型对比(均为默认参数)
-
-
- @决策树DecisionTreeClassifier( )
- @ 随机森林RandomForestClassifier( )
- @支持向量机SVM()
- @逻辑回归LogisticRegression()
- @梯度提升树GBDT()
-
- (4)网格搜索模型调参决策树模型
- (5)输出结果
- 总结
-
- ==**Kaggle网站得分0.82775(TOP 1.32%)**==
- ==**不足与优化**==
- 源代码以及实验报告
前言
其实python大作业10月下旬就写完了,一直没来得及发,忙着大创立项。参考了国外kaggle大佬的解题思路,Kaggle网站得分0.82775(TOP 1.32%):

kaggle-Titanic竞赛:
Titanic竞赛
所有代码以及实验报告下载:
泰坦尼克号代码以及实验报告
开发环境
编译器:PyCharm Community Edition 2021.2
pyhton版本:pyhton3.8
一、导入包:
主要是可视化包seaborn、matplotlib,机器学习包sklearn,以及python基础包
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.feature_selection import SelectKBest
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
from sklearn.preprocessing import StandardScaler
from numpy.random import seed
二、实验数据的读取,合并,以及显示info
读取csv文件,用到read_csv,连接数据集:concat,输出info()
axios=0;行操作
axios=1;列操作
# 读取文件
train_csv = pd.read_csv("train.csv")
test_csv = pd.read_csv("test.csv")
# 在分割数据集之前为每个数据集设置索引
train_csv = train_csv.set_index("PassengerId")
test_csv = test_csv.set_index("PassengerId")
# dataframe,连接两个数据集,方便处理数据
df_csv = pd.concat([train_csv, test_csv], axis=0, sort=False)
df_csv.info()
print(df_csv.isnull().sum())

输出结果:

三、数据的预处理
(1)离散型字符串特征的处理
性别(Sex)的处理
这里做一个map操作,female与male分别改成0和1,因为后面用到的模型-随机森林以及决策树等等,都是不易于字符串的处理的,对于字符串的特征,我们先转换成离散型数字。
df_csv.Sex = df_csv.Sex.map({'female':0,'male':1})
港口Embarked处理
一样的做一个map操作,转换成离散型数字
# 登录港口处理:用数字1,2,3,表示
df_csv.Embarked = df_csv.Embarked.map({'S':0,'C':1,'Q':2})
(2)通过可视化来分析不同的特征数据
Pclass、Sex、Embarked、SlibSp、Parch、Survived的存活与死亡的数据的可视化
因为seaborn优于matplotlib,所以用的是seaborn和matplotlib库
figure:创建一个可以绘画的窗口
countplot:直方图
里面很多参数都有注释,这儿就不重复说了
plt.figure(figsize=(16, 18))#面积
sns.set(font_scale=1.2)#字体
sns.set_style('ticks')#应该是四周都有刻度线的白背景
feature_name=['Pclass', 'Sex', 'Embarked', 'SibSp', 'Parch', 'Survived']
for i, feature in enumerate(feature_name):#枚举循环
plt.subplot(2, 3, i + 1)#一共6个,这是i+1个
sns.countplot(data=df_csv, x=feature, hue='Survived', palette='Paired')# x=数据,y=存活率,palette=颜色
sns.despine()#删除边框
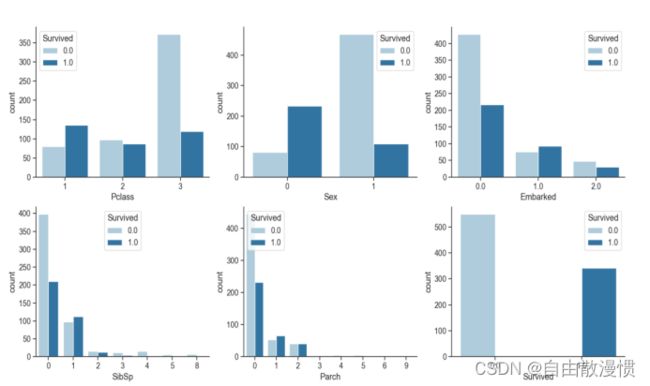
观点:女性的存活率更高;符合发生灾难时,让女性先走的事实。
有家人(SibSp与Parch)的存活率高,家人互帮互助存活率高
登录的港口(Embarked)看不出有啥影响
船舱(Pclass)的等级越高,存活率越高
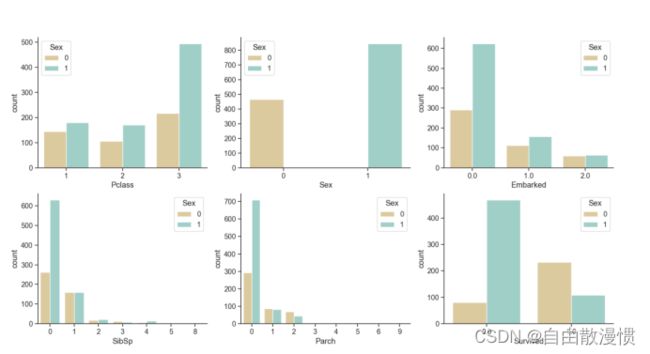
Pclass、Sex、Embarked、SlibSp、Parch、Survived的Sex数据可视化

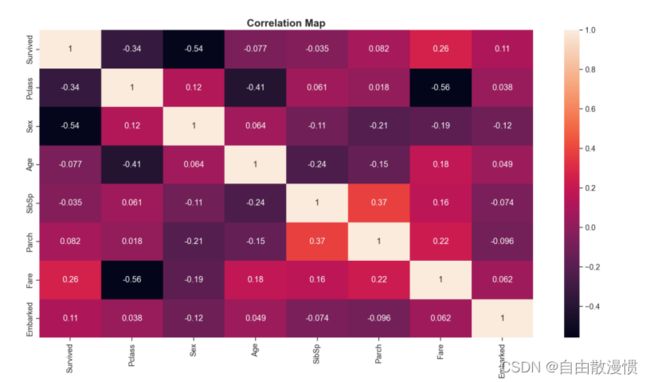
各个特征的相关系数图
![]()
(3)对于缺失值的处理
重点思想:对对象进行分类,再填充
例如填充Age:Age缺失较多,通过给数据集分组,先按Pclass、Sex分类,再填充,填充时根据不同分组的中位数来填。中位数更能反应一个类别人群的平均年龄,平均数容易受到极个别噪点数据的影响,所以不选择平均数填充。
缺失值(除开Survived)有Age、Embarked、Fare、Cabin
填充Age
方法部分:Age缺失较多,通过给数据集分组,按Pclass、Sex分组,填充时根据不同分组的中位数来填。中位数更能反应一个类别人群的平均年龄,平均数容易受到极个别噪点数据的影响,所以不选择平均数填充。


Age直方图


Age进行分类:


Age离散化操作
把age分成四类,再转换成离散变量0,1,2,3。方便以后跑模型
df_csv['Age'] = LabelEncoder().fit_transform(age_cut)#把age分成四类,再转换成离散变量0,1,2,3
pd.crosstab(df_csv['Age'], df_csv['Survived'])#用于统计分组频率的特殊透视表
填充Fare
方法部分:Fare缺失较多通过给数据集分组,按Pclass、Sex分组,填充时根据不同分组的中位数来填。中位数更能反应一个类别人群的平均票价,平均数容易受到极个别噪点数据的影响,所以不选择平均数填充。

Fare直方图


Fare离散化操作
df_csv['Fare'] = LabelEncoder().fit_transform(fare_cut)#把fare分成五类,再转换成离散变量0,1,2,3,4
pd.crosstab(df_csv['Fare'], df_csv['Survived'])#用于统计分组频率的特殊透视表
填充Embarked
方法部分:Embarked只有一个缺失,直接用所有Embarked数据的中位数来填值

删除Cabin
方法部分:Cabin的缺失值达到77.4%,缺失过多,容易产生噪点,所以不研究,直接删除。

四、特征选择
(1)对于Name特征的处理,处理Name的身份

最常见的是Mrs、Miss、Mrs、Master、把其他身份归为Rare

(2)Title变为离散变量

(3)SibSp与Parch的特征分析
新建特征列FamilySize,把家庭大小分为4类

(4)Ticket特征分析
发现含有字母与不含字母的全票存活率相差很大,含有字母的ticket对应的乘客存活率低 把含有字母的ticket变为0

(5)Woman or Child特征分析
女人or孩子的存活率相对较高,单独作为一个特征
![]()
(6)新建列Family_TotalCount, Family_SurviviedCount和Family_SurvivalRate
Family_ TotalCount
使用lambda函数在LastName、PClass和Ticked检测家庭的基础上对WomChi列进行计数,然后用布尔过程减去相同的乘客,该乘客是妇女或儿童。Family_
SurvivedCount
也使用lambda函数对WomChi列求和,然后使用掩码函数过滤器(如果乘客是妇女或儿童)减去生存状态,最后一个Family_
surviwalrate 仅除以Family_ SurvivedCount 和Family_ TotalCount。

五、分类器构建
离散特征的编码处理Sex、Fare、Pclass

删除部分容易产生噪点的特征Name、LastName、WomChi、Family_TotalCount,
Family_SurviviedCount,Embarked,Title(慢慢试出来的,这些特征真滴不行,影响结果)
六、模型验证
(1)提取测试集与训练集数据

![]()
(2)标准化处理
如果某个特征的方差比其他特征大几个数量级,那么它就会在学习算法中占据主导位置,导致学习器不能从其他特征中学习,从而降低精度。加快梯度下降求解的速度。

(3)模型对比(均为默认参数)
一共验证了5种经典模型:决策树、随机森林、SVM、逻辑回归、GBDT,发现决策树yyds
原理分析:决策树,我的理解是,开始有很多条件,通过if else,一步步筛选,最终得到一个结果,及一个决策。而随机森林是由很多棵决策树产生的森林,集合不同决策树的结果,来通票选出最终的结果,少数服从多数。
@决策树DecisionTreeClassifier( )

![]()
@ 随机森林RandomForestClassifier( )

![]()
@支持向量机SVM()

![]()
@逻辑回归LogisticRegression()
![]()
@梯度提升树GBDT()

![]()
(4)网格搜索模型调参决策树模型
这里是引用
#决策树调参
from sklearn.model_selection import GridSearchCV
tree_param_grid = { 'max_depth':list((5,10,12)),'min_samples_split': list((2,4,6)),'min_samples_leaf':list((1,2,4))}
grid = GridSearchCV(DecisionTreeRegressor(),param_grid=tree_param_grid, cv=5)
grid.fit(X_train, Y_train)
grid.cv_results_['mean_test_score'], grid.best_params_, grid.best_score_
print(grid.best_params_, grid.best_score_)
调参结果 :
![]()
![]()
发现准确率下降,分析原因为,默认参数下,决策树模拟Score已经很高了(99.89),网格搜索最优参数意义不大,而且容易造成过拟合或者欠拟合。
(5)输出结果


总结
1,优先级:数据预处理>模型选择>调参(预处理非常重要)
2,补充空缺值,要分类补充,不然正确率下降
3,调参不一定好,但是大部分调参可以提高正确率
4,数据少:决策树,数据多(百万):神经网络
5,记得降维,离散化数据处理
Kaggle网站得分0.82775(TOP 1.32%)
不足与优化
1,关于Cabin的数据处理不到位,由于Cabin缺失值太多,没有找到好的处理方法,没有深挖Cabin的处理机制,以及对于结果的影响。
2,关于Embarked数据的处理不到位,在离散特征的编码处理Embarked的值后,发现其有较大的噪点影响,加入模型分析后,极大的减少了模型的正确率,暂未找到好的处理Embarked值的方法。
3,对于Name的特征处理有待深挖,比如race姓名的人,可能为贵族,存活率更高。
4,对于用神经网络模型对于数据集进行分析,Kaggle模拟结果可以达到0.78,但是没有进行细致的调参,调参后或许结果更好。
5,还可以试试XWBOOST模型,因为没有学过其所需要的编程语言,所以没有进行试验。
源代码以及实验报告
泰坦尼克号代码以及实验报告