二十八. 智能驾驶笔记之基于PointNet++的三维点云分类和语义分割
第一部分 基于三维点云的分类和语义分割介绍
第二部分 PointNet和PointNet++
第三部分 PointNet++关键代码分析
第一部分 基于三维点云的分类和语义分割介绍
基于二维图像的神经网络技术已经非常成熟, 扩展的基于三维点云的神经网络, 这不同于二维的分类和分割(二维边界框), 三维点云分类检测的主要任务是: 识别出目标物体的种类信息; 三维点云语义分割的主要任务是: 区分出不同种类不同各个的物体, 同时确定三维边界框,包括3维位置信息, 目标朝向等信息.
对于二维的图像数据,其像素点在数据中分布是有序的, 可以方便地通过(x,y)坐标对齐索引等操作. 而对于三维点云,首先其数据存储方式就是无序的, 因此在使用神经网络对点云数据处理之前,需要对点云数据进行处理,使其有序化.
目前,针对三维点云数据的深度学习有四个方向:
1. 体素网格(Voxel Grid)法:
将无序的三维点云划分为有空间依赖关系的有序的体素网格(Voxel Grid). 比如: VoxelNet. 这种方法的精度依赖于体素网格的跟分割精度, 分割精度提高,带来的就是计算量的增加,且分割效果一般, 现在已经很少使用.
2.基于点云的多视角投影(Multi-view):
其原理就是将三维任务转换为已经十分成熟的二维任务. 基本过程是: 从特定角度,如: 前视图(Front-view),鸟瞰图(Bird-view),将点云数据投射到响应的二维平面上; 再将多视图下的二维图像组合为三维物体. 也可以通过相机和Lidar联合标定获取和融合RGB图像信息后再进一步提取特征.如YOLO三维, 以及基于多传感器前融合技术方法的MV3D.
3.直接基于点云的点云网络(PointNet):
该类方法直接在点云进行深度学习, 典型的如本文介绍的PointNet/PointNet++, PolarNet, 百度的CNN_SEG,PointPillars及其改进版Apollo7.0中的Mask-Pillars.
4. 基于深度学习的二维图像与三维点云融合:
基于深度学习的多传感器前融合技术, 如: F-PointNet.
第二部分 PointNet和PointNet++
PointNet
PointNet针对点云数据的无序性和空间变换的不变性进性给出了自己的解决方法:
- 无序性:
我们知道点云数据存储是由可任意排列的数据组成的集合.而使用深度学习模型的前提是: 保证不论点云顺序如何,都应该提取到相同的特征.在PointNet中作者提出用最大池化对称函数来提取特征,解决无序性问题. 最大池化即在每一维的特征都选取N个点对应的最大的特征值.
- 变换不变性:
这类似于三维建模,以Unity3D游戏为例, 3D游戏世界的没有个物体,比如一辆汽车模型,都是由非常多的3维点(x,y,z)构成,进而由这些3维点按一定规则构成无数三角形平面, 又由这些三角形平面,构成了汽车模型的3为mesh网格,最终展现出完整的汽车模型,由这些3为点构成的汽车模型,就具有旋转不变性,无论怎么旋转,我们都能识别出它是一辆汽车模型.如下图(图片来源于网络,仅用来帮助理解):

点云数据所表示的目标经过一定的空间变换(旋转,平移)后应该保持不变, 在坐标系中即为点云数据坐标发生变化后,不论其用何种坐标系表示,网络都能正确地识别目标. 作者提出在对点云数据提取特征前, 先用空间变换网络(Spatial Transform Network, STN)对齐以保证其不变性. 网络中,T-Net子网络为了让特征对齐,会通过学习点云的位置信息来找到最适合的旋转角度,得到一个旋转矩阵, 并通过将其与输入点云数据相乘来保证数据的不变性.
即: (x,y,z)' = (x,y,z) * R
下面是原作者的PointNet网络结构图:
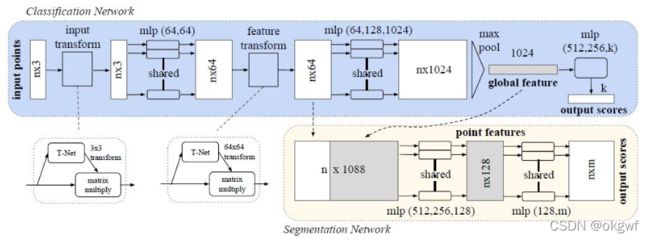
第1步:
输入原始点云数据: 张量形状为: X[n,3], 这里n表点云中3维点的总数,3即为3维坐标(x,y,z).
第2步:
将输入点云张量X[n,3]经过一个STN网络学习到期转换矩阵R[3,3], 然后对张量X[n,3] 乘 R[3,3],得到一个新张量X[n,3],即完成对齐工作,保证其对空间变换保持不变性.
第3步:
上一步得到的张量X[n,3]经过一个多层感知机(MLP),来提取点云的数据特征,并升维得到张量X[n,64],在通过一个STN进行特征对齐,得到一个输出张量X[n,64].
多层感知机(Multi-layer Perception,MLP)我们知道就是一个全连接网络,即一些列的Linear+ReLu层组成.MLP主要用来做多分类学习.
第4步:
在经过一个MLP提取点云数据特征,此时张量升维到X[n,1024], 进一步利用最大值池化得到其全局特征X_classification[n,512].
我们知道对于二维图像领域,池化层的主要目的: 一般是对卷积后得到的特征映射进一步处理,主要是降维,降低特征图的参数量,这里主要减小特征尺寸,通道数保持不变,提升计算速度,增加感受野,是一种降采样操作. 起到对特征数据进一步浓缩的效果,从而缓解计算时内存的压力. 同时,池化可以使模型更关注全局特征而非局部出现的细节,这种降维的过程可以保留一些重要的特征信息,提升容错能力,并且还能在一定程度上起到防止过拟合的作用.
一般原特征数据,经池化后, 通道数不变,特征数据尺寸会大大减小;采用最大值池化后, 图像边缘特征会更加明显;
第5步:
根据目的不同,若为分类任务,则将上一步的X_classification[n,512]再经一次MLP,输出k个分类的得分值; 若为实例分割任务,则将上一步的X[n,1024](全局细节特征)与第3步的X[n,64](富含局部细节特征)进行拼接,再经过两次MLP对每个点进行分类,完成语义分割任务,输出张量[n,m]. 这里m个物体.
总结, PointNet的实际应用依赖于比较稠密的3为点云, 比如对众多的3维建模数据进行分类识别. 而对于自动驾驶汽车这种激光雷达生成的稀疏的点云,因为其在局部特征上提取不充分,分类特别是语义分割效果并不好. 于是就有其升级版: PointNet++.
PointNet++
PointNet++(总有种大学时学了C语言,又学C++的赶脚~)针对PointNet在局部特征提取不足,提出了一种分层神经网络结构(Hierarchical Neural Network),它主要由下面三个抽象集合组成, 分别是: 采样层, 组合层,特征提取层, 并且PointNet++在不同尺度下提取特征作为局部特征(有点FPN网络的意思),并通过多层网络结构得到深层特征.
一张来自原作者的PointNet++结构图如下:
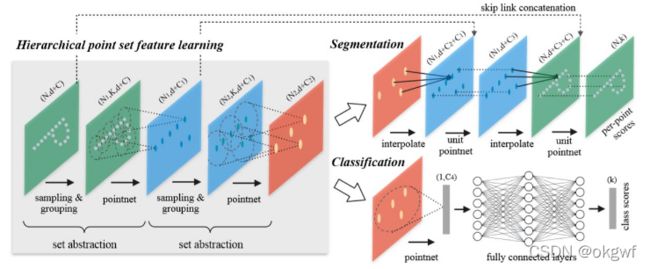
对于PointNet++这个结构如果不对照代码来理解,的确很抽象. 先简单介绍下吧, 后面再结合关键代码来理解.
一. 采样层(sampling):
由于网络采用多层神经网络(指多次执行PointNet)结构,每次在处理点云数据之前, 先进行采样处理.即使用了一种称为迭代最远点采样(Farthest Point Sampling,FPS)方法. 首先根据超参数设置选定一个点云数据子集,然后抽取子集中距离每个点最远的点,作为一个新的子集. 新老两个子集合并作为一个样本空间.
二.组合层(grouping):
根据采样步骤确定的局部区域,在这一区域提取特征. 这里暂时先这些, 待稍后结合代码再来扩充.
三. 特征提取层(也就是其其前身PointNet):
这一层就是使用PointNet对组合层中的局部区域进行特征提取. 详细见PointNet网络结构分析.
四. 其他补充:
由于点云数据在空间分布上密度极度不均匀, 在距离较远的地方激光点十分稀疏. 如果不加区别的提取特征会使网络很容易在低密度的地方无法提取到局部特征. 而导致PointNet训练效果变差,造成较大误差. 从模型样本不均衡角度看, 这样属于一个难易样本不均衡问题.直接会导致网络在较远距离的点云上识别精度不高.
为此,在点云密度较稀疏的点可以考虑加大选取的局部区域来更好的提取特征. 原作者提出一种密度自适应PointNet层,来组合不同密度点云数据的特征.具体采用了多分辨率组合(Multi-resolution Grouping,MRG)方法.
怎么理解MRG方法呢? 我觉的和物体检测CNN网络里的感受野(Receptive Field)概念应用很相似.物体检测网络中为了检测大物体而扩大感受野,在语义丰富的深层特征图上获取大物体的特征,检测小物体,则在浅层的高分辨率特征图上采用小感受野来提取小物体特征.
具体到多分辨率组合(MRG),通俗讲就是对同一个局部区域:
第1步: 先进行一个特征提取(基于PointNet),这一层特征分辨率较高,物体细节丰富,或者说感受野较小;
第2步: 在第1步提取的特征之上,再进行一次特征提取(基于PointNet). 本次获取的特征语义强但分辨率低,或者说感受野较大;
第3步: 将前两步提取的特征做拼接,作为一次完整的特征. 这多么像很多CNN网络中的深浅层特征按通道拼接啊. 其实就是.
为了帮助理解,下面是二维图像的CNN网络感受野感念和本文中的多分辨率组合(MRG)概念对比图:
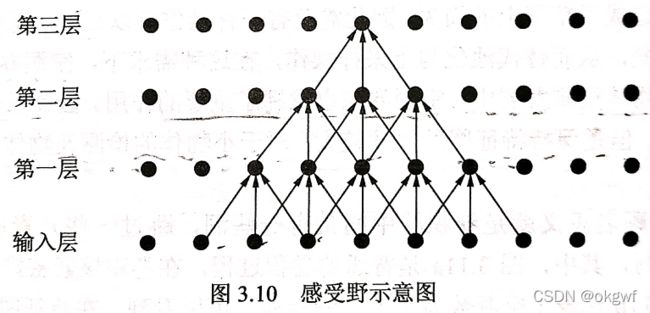
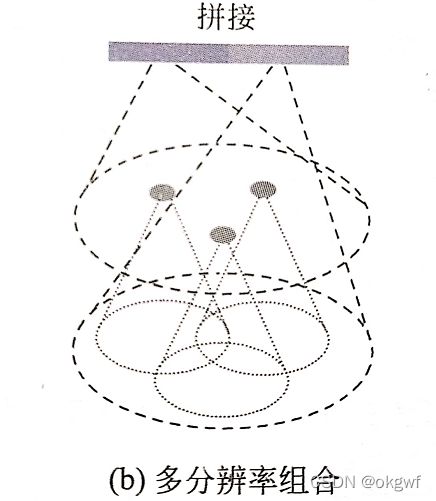
如上图多分辨率组合(MRG),上面一层提取的特征是基于下面一层特征提取的基础上二次提取而来. 很明显基于下面那层提取的特征富含更丰富的细节信息, 在点云较为稀疏的远距离位置, 很明显下面那一层的特征更可靠.
第三部分 PointNet++关键代码分析
一.STN网络
由于PointNet++完全包含PointNet,只是对PointNet的扩展,所以先介绍PointNet中的STN网络. STN网络有两种STN_3X3和STN_64x64.这里以STN_3x3为例:
class STN3d(nn.Module):
def __init__(self, channel):
super(STN3d, self).__init__()
self.conv1 = torch.nn.Conv1d(channel, 64, 1) #[n,64]
self.conv2 = torch.nn.Conv1d(64, 128, 1) #[n,128]
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 9)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
def forward(self, x): #x: torch.Size([B, C:3, N])
batchsize = x.size()[0] #B
x = F.relu(self.bn1(self.conv1(x))) #[B,64,N]
x = F.relu(self.bn2(self.conv2(x))) #[B,128,N]
x = F.relu(self.bn3(self.conv3(x))) #torch.Size([B, 1024, N])
x = torch.max(x, 2, keepdim=True)[0] #torch.Size([B, 1024, 1])
x = x.view(-1, 1024) # torch.Size([B, 1024])
x = F.relu(self.bn4(self.fc1(x))) # torch.Size([B, 512])
x = F.relu(self.bn5(self.fc2(x))) # torch.Size([B, 256])
x = self.fc3(x) # torch.Size([B, 9])
#identity matrix
identify = torch.from_numpy(np.array([1, 0, 0, 0, 1, 0, 0, 0, 1]).astype(np.float32))
identify = identify.view(1, 9).repeat(batchsize, 1) #torch.Size([1, 9]) -> torch.Size([B, 9])
if x.is_cuda:
identify = identify.cuda()
x = x + identify # torch.Size([B, 9])
x = x.view(-1, 3, 3) # torch.Size([B, 3, 3])
return x一个STN网络实际解决了3维点云的两个问题: 无序性 和 变换不变性.
先看如何解决点云无序性:
如前面所述: 在PointNet中作者提出用最大池化对称函数来提取特征,解决无序性问题. 最大池化即在每一维的特征都选取N个点对应的最大的特征值. 目的就是要保证:点云所描述的物体形状和点云存储顺序无关. 对应上面STN代码如下:
x = F.relu(self.bn1(self.conv1(x))) #[B,64,N]
x = F.relu(self.bn2(self.conv2(x))) #[B,128,N]
x = F.relu(self.bn3(self.conv3(x))) #torch.Size([B, 1024, N])x = torch.max(x, 2, keepdim=True)[0] #torch.Size([B, 1024, 1])
x = x.view(-1, 1024) # torch.Size([B, 1024])
我们知道在二维图像的卷积网络,一系列图片的Batch张量为[B,3,H,W],我们可以只考虑一张图片张量为:[1,3,H,W],然后经过若干卷积层,会把图片中每一个像素点的RGB值3通道经过提取特征扩展到1024甚至4096个通道,最终变为形如:[1,1024,H,W]张量形成, 这里的1024个通道表征了什么? 是从图像中提取的轮廓信息,灰度信息,纹理信息,.热力图等细节信息. 这就把一个3通道RGB升维到更丰富细节的1024个通道. 随后对特征进行下一步分类或语义分割.
这里的针对[B,3,N] (B:点云batchsize,3:x,y,z, N:点云点个数),同样通过多层卷积后,将一个3通道的(x,y,z)升维到更丰富细节的1024个通道. 代码中对生成的[B,1024,N]张量在第2个维度方向求最大值(max)运算, 注意这里描述点坐标已经不是简单的(x,y,z)3维了, 而是(c1,c2,c3,c4......c1024)的1024维. 结果就是在N方向上对每个ci通道求最大值. 输出结果: [B, 1024, 1]. N个点(c1,c2,c3,c4......c1024)变为1个点(c1,c2,c3,c4......c1024). 这个结果是从升维到1024的更高维度上求得的,其包含的信息远比3个坐标(x,y,z)丰富. 试想,如果先升维到1024通道, 而是直接对[B,3,N]在N方向分别对x,y和z求最大值,得到一个结果:[B,3,1], 以下从N个点(x,y,z),变为一个点(x,y,z),物体形状丢失的信息得多大? N个点组成的一个物体,直接变为一个3维点(x,y,z)了.
再看,如果解决变换不变性:
如前面描述的: 网络中,T-Net子网络为了让特征对齐,会通过学习点云的位置信息来找到最适合的旋转角度,得到一个旋转矩阵, 并通过将其与输入点云数据相乘来保证数据的不变性.
这一步其实是基于解决点云无序性问题的. 保证点云所描述的物体形状和点云存储顺序无关后.
经过两层全连接网络,相当于做了个9分类, 为什么是9分类,因为一个3x3的旋转矩阵R是9个值.如下代码.
x = F.relu(self.bn4(self.fc1(x))) # torch.Size([B, 512])
x = F.relu(self.bn5(self.fc2(x))) # torch.Size([B, 256])
x = self.fc3(x) # torch.Size([B, 9])
至此, 作者的解决点云无序性和旋转不变性的思想,就十分明了了.
关于PointNet++中的采样层,组合层和特征提取层, 限于篇幅原因就不展开了.