2D栅格-3D八叉树地图及其概率更新
2D栅格-3D八叉树地图及其概率更新
-
- 一.栅格/体素概率更新
-
- 1.占据栅格地图
-
- 1.1概率更新公式
- 1.2 二维坐标系到栅格索引的转化
- 2.八叉树地图
-
- 2.1八叉树原理
- 2.2概率更新公式
- 二.八叉树工程解析
-
- 1.Octomap基本数据类型解析
- octomap::Vector3
- octomap::OcTreeNode
- octomap::OcTreeKey
- octomap::KeySet
- octomap::KeyRay
- octomap::PointCloud
- octomap::OcTree
- 2.Octree下的常用函数
-
- 2.1 概率更新相关的几个重要参数设置函数
- 2.2 节点信息查询函数
- 2.3 世界坐标到体素格索引转换函数
- 2.4 节点概率更新函数
- 2.5 点云插入函数
- 2.6光线追踪函数
八叉树地图与占据栅格地图有很多相关之处!之前参加过icra比赛接触过占据栅格地图相关知识,正好一起整理一下!
由于项目需求撰写此文档,既是记录也是学习的过程。由于水平有限有些地方可能会出现错误,欢迎大家指正,发现后会及时改正!
另外对自己编写不规范可能会引起疑惑的地方在此说明:
1.文中提到的二维/三维的坐标系都是指的在不同维度下的世界坐标系,与之对应栅格/体素坐标系指的的是在把空间划分成一个个小单元后,对每一个小单元的索引。可以理解为对x,y,z三个不同方向的栅格数数,数他是第几个栅格并且记录下来。因此,栅格/体素坐标系一定是整数类型的,不存在第2.5个栅格这样的说法。由于边想边写所以有的地方想表达的是同一个东西但是称呼可能没有统一,特此说明文中所提到的栅格/体素坐标系=栅格/体素索引=地图中的坐标,以后会修改统一规范化。
一.栅格/体素概率更新
1.占据栅格地图
1.1概率更新公式
我们先从基础的【占据栅格地图】说起~~

占据栅格地图 ( O c c u p a n c y G r i d M a p ) (Occupancy Grid Map) (OccupancyGridMap)是一种非常重要的地图形式,它把世界划分成一个个网格,每一个网格只有两种状态 ( s t a t e , s ) (state,s) (state,s):被占据 ( o c c u p i e d ) (occupied) (occupied)、或者空闲 ( f r e e ) (free) (free)。占用栅格地图将环境等分成小格子,那么总的地图 m m m就是由这些小格子组成: m = { m 1 , m 2 , ⋅ ⋅ ⋅ , m n } m=\{m_1,m_2,···,m_n\} m={m1,m2,⋅⋅⋅,mn} 。每个格子独立且同分布,因此转换成了一个独立求解每个栅格 m i m_i mi的问题。每个小格子要么是占有栅格,即在这个地方有障碍物,要么就是空闲栅格表示这个地方没有障碍物,还有就是我们系统还没有探测到这个地方有没有障碍物,就是未知栅格。
但是在机器人观测世界的过程充满了误差,武断地认为一个网格要么被占据要么空闲是不靠谱的,我们更愿意用概率来说话。因为所有的传感器测量都是有误差的,如果我们用一个激光测距仪测量一面墙的距离,测量了100次,会发现每次的测量值都不一样,统计一下分布频率的话,会发现其服从正态分布( N o r m a l d i s t r i b u t i o n Normal distribution Normaldistribution,也叫高斯分布)。如果测量次数足够多,我们可以认为,这个正态分布的均值即 μ μ μ为真值,而正态分布的方差 σ 2 \sigma^2 σ2取决于传感器本身的物理性质(由厂商提供或人工标定该参数)。反过来,如果我们只有一次测量,我们可以认为,真值服从以当前测量值为均值,方差仍然为 σ 2 \sigma^2 σ2的正态分布。
这样就能理解了,对于激光雷达,如果一个激光点落在某个栅格 m i m_i mi里,则该栅格的占据概率并不是1,而是正态分布在均值处的概率值 P ( m i ) P(m_i) P(mi);对于 m i m_i mi 附近没有被激光点击中的栅格,其概率值也并不是0,而是按照与的 m i m_i mi距离在正态分布曲线中查询出的那个概率值 p ( ¬ m i ) p(\neg m_i) p(¬mi) 。显然, p ( m i ) + p ( ¬ m i ) = 1 p(m_i)+p(\neg m_i)=1 p(mi)+p(¬mi)=1 。对于一个尚未被观测到的网格,其初始的占据概率和空闲概率都设为0.5(没有先验知识的情况下,当前栅格占据和不占据的概率五五开,很符合常理) 。
用 p ( m i ) p(m_i) p(mi)来表达网格是 ( o c c u p i e d ) (occupied) (occupied) 的概率直观易懂,但不便于处理,我们换个表达形式,引入两者的比值来作为点的状态,记作
O d d ( s ) = P ( m i ) P ( ¬ m i ) Odd(s)=\frac{P(m_i)}{P(\neg m_i )} Odd(s)=P(¬mi)P(mi)
接下来我们再认几个概率,按照激光点击中位置和正态分布曲线得到的当前这次观测 z i z_i zi下的 P ( m i ) P(m_i) P(mi)。
P ( m i ∣ z i ) P(m_i|z_i) P(mi∣zi)
一般来说我们的机器人在未知世界中一定会产生移动,那么自身的位姿在地图中也会发生变化,因此其实得到的每次观测都处于不同的位置姿态下,对于不同的位置姿态,我们用 x i x_i xi来表示。那么现在来看,我们的 z i z_i zi即是在 x i x_i xi位置下得到的观测值。
P ( m i ∣ x i , z i ) P(m_i|x_i,z_i) P(mi∣xi,zi)
( ps:要注意的是,在概率更新推导中,我们做的并不是 s l a m slam slam的过程而是注重在mapping上,因此我们并不需要去对机器人的位姿做一个最优的估计,而是我们假设已知机器人在每个时刻的位姿 x i x_i xi,也就说 x i x_i xi是个已知量,与概率更新推导并无太大关系。)
我们说过,传感器测量充满误差,仅凭一次观测很难得到靠谱的结果,所以,我们要综合考虑所有的历史观测,而把历史观测的结果叠加起来,那么我们就需要的不只是一次观测,而是一个观测的序列: { z 1 , z 2 , ⋅ ⋅ ⋅ , z t } \{z_1,z_2,···,z_t\} {z1,z2,⋅⋅⋅,zt},通常在概率中简写成 z 1 : t z_{1:t} z1:t的形式表示从1秒到 t t t秒所得到的观测值。
占用栅格地图构建要解决的问题是:已知机器人位姿序列 x 1 : t x_{1:t} x1:t和观测序列 z 1 : t z_{1:t} z1:t,求解环境地图 m m m。表达成概率形式,就是求地图的后验概率。
p ( m ∣ x 1 : t , z 1 : t ) p(m|x_{1:t},z_{1:t}) p(m∣x1:t,z1:t)
这里我们要求解地图形式是栅格形式,怎么求这个后验概率呢?
其实这个问题就是我们需要通过激光雷达的数据对地图的状态做一个估计。这里地图的状态仅有两种占据和空闲,对于这两种状态我们用 m i 和 ¬ m i m_i和\neg m_i mi和¬mi来表示。
我们还可以简化此次的问题:
贝叶斯滤波分为预测步和更新步,而我们此次不需要预测步,因为我们预测的状态是静止的,不会发生改变。所以我们假设这个世界是静止的,那么我们就不需要进行预测。所以我们仅需要更新步即可。同时我们可能的状态也只有两种。因此这种滤波的方式也叫做静态二值贝叶斯滤波 ( B i n a r y B a y e s f i l t e r f o r a s t a t i c s t a t e ) (Binary \ Bayes\ filter\ for\ a\ static\ state) (Binary Bayes filter for a static state)。
我们没有任何的控制,仅有每次的观测,这样就简化了我们的估计问题。
在正式开始推导之前先回顾一下概率论的一些知识:
贝叶斯公式
P ( x ∣ y ) = P ( y ∣ x ) P ( x ) P ( y ) P(x|y)=\frac{P(y|x)P(x)}{P(y)} P(x∣y)=P(y)P(y∣x)P(x)
带"背景知识 z z z"的贝叶斯公式:
P ( x ∣ y , z ) = P ( y ∣ x , z ) P ( x ∣ z ) P ( y ∣ z ) P(x|y,z)=\frac{P(y|x,z)P(x|z)}{P(y|z)} P(x∣y,z)=P(y∣z)P(y∣x,z)P(x∣z)
准备完毕下面我们就来开始推导:
p ( m i ∣ x 1 : t , z 1 : t ) = B e y e s p ( z t ∣ m i , x 1 : t , z 1 : t − 1 ) p ( m i ∣ x 1 : t , z 1 : t − 1 ) p ( z t ∣ x 1 : t , z 1 : t − 1 ) = M a r k o v p ( z t ∣ m i , x t ) p ( z t ∣ x 1 : t − 1 , z 1 : t − 1 ) p ( z t ∣ x 1 : t , z 1 : t − 1 ) = B e y e s p ( m i ∣ z t , x t ) p ( z t ∣ x t ) p ( m i ∣ x 1 : t − 1 , z 1 : t − 1 ) p ( m i ∣ x t ) p ( z t ∣ x 1 : t , z 1 : t − 1 ) = M a r k o v p ( m i ∣ z t , x t ) p ( z t ∣ x t ) p ( m i ∣ x 1 : t − 1 , z 1 : t − 1 ) p ( m i ) p ( z t ∣ x 1 : t , z 1 : t − 1 ) p(m_i|x_{1:t},z_{1:t})\\ \xlongequal[]{Beyes}\frac{p(z_t|m_i,x_{1:t},z_{1:t-1})p(m_i|x_{1:t},z_{1:t-1})}{p(z_t|x_{1:t},z_{1:t-1})}\\ \xlongequal[]{Markov}\frac{p(z_t|m_i,x_t)p(z_t|x_{1:t-1},z_{1:t-1})}{p(z_t|x_{1:t},z_{1:t-1})} \\ \xlongequal[]{Beyes}\frac{p(m_i|z_t,x_t)p(z_t|x_t)p(m_i|x_{1:t-1},z_{1:t-1})}{p(m_i|x_t)p(z_t|x_{1:t},z_{1:t-1})}\\ \xlongequal[]{Markov}\frac{p(m_i|z_t,x_t)p(z_t|x_t)p(m_i|x_{1:t-1},z_{1:t-1})}{p(m_i)p(z_t|x_{1:t},z_{1:t-1})} p(mi∣x1:t,z1:t)Beyesp(zt∣x1:t,z1:t−1)p(zt∣mi,x1:t,z1:t−1)p(mi∣x1:t,z1:t−1)Markovp(zt∣x1:t,z1:t−1)p(zt∣mi,xt)p(zt∣x1:t−1,z1:t−1)Beyesp(mi∣xt)p(zt∣x1:t,z1:t−1)p(mi∣zt,xt)p(zt∣xt)p(mi∣x1:t−1,z1:t−1)Markovp(mi)p(zt∣x1:t,z1:t−1)p(mi∣zt,xt)p(zt∣xt)p(mi∣x1:t−1,z1:t−1)
看最后这个式子,很难求吧,第一项是一个观测模型,这个还好说,是已知的。第二项怎么求?分母上后一项怎么求?这都不好办把。我们换一种思路,这个栅格空闲的概率是什么?
p ( ¬ m i ∣ x 1 : t , z 1 : t ) = p ( ¬ m i ∣ z t , x t ) p ( z t ∣ x t ) p ( ¬ m i ∣ x 1 : t − 1 , z 1 : t − 1 ) p ( ¬ m i ) p ( z t ∣ x 1 : t , z 1 : t − 1 ) p(\neg m_i|x_{1:t},z_{1:t})=\frac{p(\neg m_i|z_t,x_t)p(z_t|x_t)p(\neg m_i|x_{1:t-1},z_{1:t-1})}{p(\neg m_i)p(z_t|x_{1:t},z_{1:t-1})} p(¬mi∣x1:t,z1:t)=p(¬mi)p(zt∣x1:t,z1:t−1)p(¬mi∣zt,xt)p(zt∣xt)p(¬mi∣x1:t−1,z1:t−1)
写公式太复杂啦也没有什么直观感,所以手手写推导如下:



激光雷达的反演观测模型:

1.2 二维坐标系到栅格索引的转化
如何将真实世界中的坐标转化为栅格地图中的坐标呢
考虑一维的情况:

图中 x x x是真实世界中的坐标, i i i为离散化了的地图(栅格地图)中的坐标, r r r为一格的长度, 1 / r 1/r 1/r表示分辨率,显然我们有: i = c e i l ( x / r ) i=ceil(x/r) i=ceil(x/r)。
同理,二维情况下: ( i , j ) = ( c e i l ( x / r ) , c e i l ( y / r ) ) (i,j)=(ceil(x/r),ceil(y/r)) (i,j)=(ceil(x/r),ceil(y/r))。
2.八叉树地图
2.1八叉树原理
八叉树即是有八个子节点的树,八块示意图如下图所示。实际的数据结构就是一个树根不断往下扩展,每分8个小枝,直到叶子为止。叶子节点代表了分辨率最高的情况。如分辨率为0.01cm,则每个叶子就是1cm见方的小方块。

八叉树的实现步骤如下:
(1).设定最大递归深度
(2).找出场景的最大尺寸,并以此尺寸建立第一个立方体
(3).依序将单位元元素丢入能被包含且没有子节点的立方体
(4).若没有达到最大递归深度,就进行细分八等份,再将该立方体所装的单位元元素全部分担给八个子立方体
(5).若发现子立方体所分配到的单位元元素数量不为零且跟父立方体是一样的,则该子立方体停止细分,因为跟据空间分割理论,细分的空间所得到的分配必定较少,若是一样数目,则再怎么切数目还是一样,会造成无穷切割的情形。
(6) 重复3,直到达到最大递归深度。
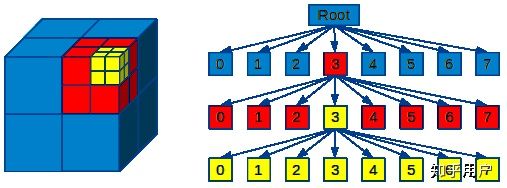
在Octomap库中实现的octomap::OcTree对于空间的划分方式如下图所示:

如图所示,体素格坐标系即体素格索引的原点在正方体左上角(图中的0位置处),那么该体素格0在体素格坐标系下的坐标即为原点(0,0,0),在图中用红色字体000表示。既然是对空间进行划分,那么肯定有个先后顺序,经过测试在Octomap库中的划分方式为:从上至下从左至右划分。也就是按图中0→1→2→···→7的方式进行划分。
特别注意的是,节点的展开只有可能是0个或者8个子节点,因此一旦展开顺序就固定了,可能展开后的八个节点中只有第三节点有值,那也需要按照顺序存放,0到2节点指针为空。这样划分后的结果如下图所示:
对于划分好的八叉树地图,每个小方块都有一个描述它是否被占据的数,通常用0-1之间的浮点数表示它被占据的概率,0.5表示未确定,越大表示被占据的可能性越高。下图是一棵八叉树:

用树结构的好处是:当某个节点的子结点都“占据”或“不占据”或“未确定”时,就可以把它(节点)给剪掉!换句话说,如果没必要进一步描述更精细的结构(子节点)时,我们只要一个粗方块(父节点)的信息就够了。这可以省去很多的存储空间。不用存一个“全八叉树”!
2.2概率更新公式
在八叉树中,我们同样也用概率来表达一个叶子是否被占据,并且栅格地图中对于一格栅格概率的推导完全和在三维世界中对于一个体素格的推导相同,因此我们可以得到:假设 T = { 1 , 2 , ⋅ ⋅ ⋅ , t } T=\{1,2,···,t\} T={1,2,⋅⋅⋅,t}时刻,观测的数据为 { z 1 , z 2 ⋅ ⋅ ⋅ z n } \{z_1,z_2···z_n\} {z1,z2⋅⋅⋅zn},那么第 n n n个叶子节点记录的信息为:
P ( n ∣ z 1 : t ) = [ 1 + 1 − P ( n ∣ z t ) P ( n ∣ z t ) 1 − P ( n ∣ z 1 : t − 1 ) P ( n ∣ z t − 1 ) P ( n ) 1 − P ( n ) ] − 1 P(n|z_{1:t})=\left[ 1+\frac{1-P(n|z_t)}{P(n|z_t)}\frac{1-P(n|z_{1:t-1})}{P(n|z_{t-1})}\frac{P(n)}{1-P(n)}\right]^{-1} P(n∣z1:t)=[1+P(n∣zt)1−P(n∣zt)P(n∣zt−1)1−P(n∣z1:t−1)1−P(n)P(n)]−1
同样的经过 l o g i t logit logit变换后的概率更新公式为:
L ( n ∣ z 1 : t ) = L ( n ∣ z t − 1 ) + L ( n ∣ z t ) − L ( n 0 ) L(n|z_{1:t})=L(n|z_{t-1})+L(n|z_t)-L(n_0) L(n∣z1:t)=L(n∣zt−1)+L(n∣zt)−L(n0)
对于概率的更新要加一个最大最小值的限制。最后转换回原来的概率即可。
p = l o g i t − 1 ( α ) = 1 1 + e − α p=logit^{-1}(α)=\frac{1}{1+e^{-α}} p=logit−1(α)=1+e−α1
八叉树中的父亲节点占据概率,可以根据孩子节点的数值进行计算。比较简单的是取平均值或最大值。如果把八叉树按照占据概率进行渲染,不确定的方块渲染成透明的,确定占据的渲染成不透明的,就能看到我们平时见到的那种东西啦!
二.八叉树工程解析
1.Octomap基本数据类型解析
-
octomap::Vector3
Vector3这个数据结构给我们提供了octomap命名空间下自定义的的三维向量表达,它可以表达三维空间中的一个平移向量,也可以表达以欧拉角形式表示的三维物体,还提供了多个与向量运算相关的函数,例如相对于坐标系的变换实现函数、向量归一化函数、向量点积函数等。
float data [3]
一般程序中使用的是 point3d的数据类型,是Octomap自定义的类型别名,原始的数据结构还得查看octomath::Vector3
typedef octomath::Vector3 octomap::point3d
-
octomap::OcTreeNode
AbstractOcTreeNode ** children
float value
OcTreeNode为在八叉树中使用的节点类。有一个数据域和一个指针域(指向一个数组里面存放的子节点的指针)。“value”存储体素单元格的对数概率 log O d d ( s ) \log Odd(s) logOdd(s)。

-
octomap::OcTreeKey
OcTreeKey 是用于内部键寻址的容器类。内部储存了在三维空间下从原点开始到某一体素格的离散地址。类似于栅格地图中的栅格序号的概念。这个数据结构是一个关键字,它可以实现对八叉树节点OcTreeNode的关键字查询。
OcTreeKey定义的成员变量:
key_type k [3]
其中key_type是一个类型别名
typedef uint16_t octomap::key_type
-
octomap::KeySet
typedef unordered_ns::unordered_set octomap::KeySet
KeySet是Octomap自定义的类型别名!它使用一个无序关联容器(std::unordered_set/boost::unordered_set)来存储一组关键字集合,由哈希函数来组织哈希表。
哈希函数也称散列函数,直观上,它是一个映射函数 f f f,实现的功能为:内存中记录的存储位置= f ( 关 键 字 ) f(关键字) f(关键字)。在Octomap中,关键字对应的哈希值由KeyHash结构体实现,该结构体存在octomap::OcTreeKey类中。
// OcTreeKey::KeyHash: Provides a hash function on Keys
struct KeyHash
{
size_t operator()(const OcTreeKey& key) const{
// a simple hashing function
// explicit casts to size_t to operate on the complete range
// constanst will be promoted according to C++ standard
//哈希函数:
return size_t(key.k[0]) + 1447*size_t(key.k[1]) + 345637*size_t(key.k[2]);
}
};
-
octomap::KeyRay
typedef std::vector< OcTreeKey >::const_iterator const_iterator
typedef std::vector< OcTreeKey >::iterator iterator
typedef std::vector::reverse_iterator reverse_iterator;
**KeyRay**是octomap自定义的类型别名。
KeyRay内部以下成员:
private:
std::vector ray;
std::vector::iterator end_of_ray;
const static size_t maxSize = 100000;
实际使用时,KeyRay在自身成员变量ray中保存单条光束在三维空间中raytracing(光线追踪)的结果。在Octomap工程文件OctomapServer.h中的描述也可以体现这一点:
//OctomapServer.h
...
octomap::KeyRay m_keyRay; // temp storage for ray casting ----光线追踪的临时容器
...
那么现在如果我们想整合每一条光束得到的结果,那么就不能用这个临时容器进行存储了,我们采用KeySet数据格式也就是一个关键字的集合来收纳所有光束(也即点云数据)raytracing的结果。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2C1qcRg9-1630489238187)(/home/zyc/.config/Typora/typora-user-images/image-20210805171639204.png)]
-
octomap::PointCloud
3D 坐标集合 (point3d)
在数据结构的设计上,它包括了两个受保护的成员变量:
pose6d current_inv_transform
point3d_collection points
其中
typedef std::vector octomap::point3d_collection
这里,points变量又是一个自定义的类型别名,可以看出octomap::PointCloud使用了vector容器保存点云数据。于是,很自然的在程序中需要从PCL点云数据中提取Octomap点云数据结构时,可以使用push_back压入数据。
-
octomap::OcTree
在上面将Octomap最基本的数据类型全部列出并加以解释,却唯独还没有解释八叉树类型OcTree的数据结构。可以认为OcTree八叉树类是建立在以上所有数据结构基础上的顶层类,并不是指其它所有类型都派生于它,而是它提供了操作以上所有数据结构的的方法(函数),也就是核心的函数都由八叉树类型OcTree中提供。

- tree_iterator
遍历完整树(内部节点和叶子)的迭代器。可通过迭代器的类内函数访问当前迭代器访问节点的各种数据。示例如下:
for (OcTree::tree_iterator it = tree.begin_tree(),end = tree.end_tree(); it != end; ++it) {
std::cout << "当前树深度为 Node depth: " << it.getDepth() << std::endl;
std::cout << "当前体素的中点坐标 Node center: " << it.getCoordinate() << std::endl;
if(tree.coordToKeyChecked(it.getCoordinate(),key))
{ cout<<"点的坐标转换树内体素的索引为:("<getValue() << std::endl;
std::cout << "Node Occupancy Probability: " << it->getOccupancy() << std::endl;
std::cout << "Node LogOdds: " << it->getLogOdds() << '\n' << std::endl;
}
2.Octree下的常用函数
以下列举出本人所遇到的常用的函数供以后参考学习,特别指出列举出的函数都有着各种方式的重载版本,可点击函数名链接去官方API文档进行查看。
2.1 概率更新相关的几个重要参数设置函数
| void | setProbHit (double prob) |
|---|---|
| void | setProbMiss (double prob) |
这两个函数决定了inverse sensor model(反演观测模型)的概率 log O d d \log Odd logOdd更新的具体参数,默认情况下占据体素被击中(Hit)的概率值为0.7,对应的 log O d d \log Odd logOdd为0.847298,空闲体素被穿越(traverse)的概率值为0.4,对应的 log O d d \log Odd logOdd为-0.405465。
| double | getProbHit () const |
|---|---|
| float | getProbHitLog () const |
| double | getProbMiss () const |
| float | getProbMissLog () const |
可以调用getProHit/getProHitLog、getProMiss/getProMissLog查看默认的参数设定。
| void | setClampingThresMax (double thresProb) |
|---|---|
| void | setClampingThresMin (double thresProb) |
这两个函数决定了一个体元执行 log O d d \log Odd logOdd更新的阈值范围。也就是说某一个占据体素的概率值爬升到0.971(对应的 log O d d \log Odd logOdd为3.5)或者空闲体素的概率值下降到0.1192(对应的 log O d d \log Odd logOdd为-2)便不再进行 log O d d \log Odd logOdd更新计算。对应了之前概率更新时所说的最大最小值的限制。
| double | getClampingThresMax () const |
|---|---|
| float | getClampingThresMaxLog () const |
| double | getClampingThresMin () const |
| float | getClampingThresMinLog () const |
可以调用getClampingThresMax/getClampingThresMaxLog、getClampingThresMin/getClampingThresMinLog查看默认的参数设定。
| void | setOccupancyThres (double prob) |
|---|
这个函数定义了octomap判定某一个体素属于占据状态的阈值(isNodeOccupied函数),默认是0.5,网上所说一般情况下将其设定为0.7。
2.2 节点信息查询函数
| OcTreeNode * | search (const point3d &value, unsigned int depth=0) const |
|---|
传入参数为一个point3d类型的三维点对象,如果在这个地图tree中,这个三维点对应的位置有节点(不管占用与否),那么将返回该位置的节点指针,否则将返回一个空指针;
2.3 世界坐标到体素格索引转换函数
| bool | coordToKeyChecked (const point3d &coord, OcTreeKey &key) const |
|---|
函数实现带有边界检查,返回参数为在上文介绍过的指向OcTreeKey类型的内部键寻址的容器类地址,传入参数为一个point3d类型的三维点对象,如果在这个地图tree中,将返回这个三维点对应的体素格的关键字,如果不在这个地图中则返回false。
2.4 节点概率更新函数
| virtual OcTreeNode * | updateNode (const point3d &value, bool occupied, bool lazy_eval=false) |
|---|
使用 u p d a t e N o d e ( ) updateNode() updateNode()函数将空间点信息更新到地图当中,第二个参数表示该空间点对应的节点是否被占用:占用(true)、未被占用(false);
特别注意的是,对于一个点 p o i n t ( x , y , z ) point(x,y,z) point(x,y,z),使用 u p d a t e N o d e ( ) updateNode() updateNode()函数将其更新到地图当中,那么 O c c u p a n c y P r o b a b i l i t y Occupancy Probability OccupancyProbability受到影响的节点将是:
n o d e ( x 0 . y 0 , z 0 ) , ( x − r e s o l u t i o n ≤ x 0 ≤ x , y − r e s o l u t i o n ≤ y 0 ≤ y , z − r e s o l u t i o n ≤ z 0 ≤ z ) node(x_0.y_0,z_0),(x-resolution≤x_0≤x,y-resolution≤y_0≤y,z-resolution≤z_0≤z) node(x0.y0,z0),(x−resolution≤x0≤x,y−resolution≤y0≤y,z−resolution≤z0≤z)
即小于point坐标值的最大节点。同时当我们用search ()函数对point进行查询时,返回的信息也将是小于point坐标值的最大节点信息。
举个例子:
point3d endpoint( 4.09f, 4.09f, 4.09f );
tree.updateNode( endpoint, true );
这两行代码,由于分辨率是0.1,并不能精确到0.01,所以要把这个(4.09,4.09,4.09)归到(4.0,4.0,4.0)这个节点。
之前也介绍过对于程序默认来说Occupancy probability最大值为0.971,最小值为0.1192,我们可以根据自己的需求设置最大最小值。
2.5 点云插入函数
| virtual void | insertPointCloud (const Pointcloud &scan, const octomap::point3d &sensor_origin, double maxrange=-1., bool lazy_eval=false, bool discretize=false) |
|---|
插入点云。相当于批量操作updateNode,地图中的每个体素只更新一次,占用节点优先于空闲节点。需要sensor_origin坐标(就是传感器在全局坐标系下的xyz)。
2.6光线追踪函数
| virtual bool | castRay (const point3d &origin, const point3d &direction, point3d &end, bool ignoreUnknownCells=false, double maxRange=-1.0) const |
|---|
光线从“原点origin”以给定方向投射,光线第一个碰到的占据单元的中心坐标存入参数end返回。 如果原点本身被占用或未知则返回本身。
如果光线投射击中了一个被占用的节点,castRay() 将返回 true。 如果光线投射返回 false,可以通过 search() 函数查看返回的end 处的节点是否是未知单元。
castRay函数中参数origin(光束起点)是世界坐标系下激光雷达的位置;参数direction也就是光束的方向向量,只需要给出sensor model光线的方向向量即可,且没有必要对方向向量归一化,castRay函数在内部会为我们完成这件事,返回的光束末端点end是世界坐标系下的坐标表达。
| bool | computeRayKeys (const point3d &origin, const point3d &end, KeyRay &ray) const |
|---|
从起点到(不包括)终点跟踪光线,返回光束穿过的所有节点的 OcTreeKey。参数origin(光束起点)和参数end(传感器末端击中点)都是世界坐标系下的坐标!