大数据分析案例-基于逻辑回归算法构建垃圾邮件分类器模型

♂️ 个人主页:@艾派森的个人主页
✍作者简介:Python学习者
希望大家多多支持,我们一起进步!
如果文章对你有帮助的话,
欢迎评论 点赞 收藏 加关注+
目录
1.项目背景
2.项目简介
2.1项目说明
2.2数据说明
2.3技术工具
3.算法原理
3.1决策树算法
3.2朴素贝叶斯算法
3.3逻辑回归算法
4.项目实施步骤
4.1理解数据
4.2数据预处理
4.3探索性数据分析
4.4特征工程
4.5模型构建
4.6模型评估
4.7模型预测
5.实验总结
1.项目背景
垃圾邮件还没有一个非常严格的定义。一般来说,凡是未经用户许可就强行发送到用户的邮箱中的任何电子邮件都是垃圾邮件。
正常邮件与垃圾邮件的区分问题,在互联网上众说纷纭,很多专家与组织都试图给垃圾邮件下一个比较准确的定义。但是,国际上对垃圾邮件的认定尚未出台统一标准。
(1)1997年10月5日,国际互联网邮件协会召开的主题为《不请自来的大量电子邮件:定义与问题》报告中,就将不请自来的大量电子邮件定义为垃圾邮件,即UBE(Unsolicited Bulk E-mail)。美国弗吉尼亚州2003年《反计算机犯罪法》就采取了“不请自来的大量邮件”来定义垃圾邮件。这是从邮件的发送(大量)和接收(不请自来)这两方面的特征来定义垃圾邮件,更符合垃圾邮件泛滥的实际情况,不但能够涵盖泛滥的垃圾邮件的所有类型,也能涵盖未来可能出现的新类型。
(2)2002年5月20日,中国教育和科研计算机网公布了《关于制止垃圾邮件的管理规定》,其中对垃圾邮件的定义为:凡是未经用户请求强行发到用户信箱中的任何广告、宣传资料、病毒等内容的电子邮件,一般具有批量发送的特征。
(3)2003年2月26日,中国互联网协会颁布的《中国互联网协会反垃圾邮件规范》中的第三条明确指出,包括下述属性的电子邮件称为垃圾邮件:
①收件人事先没有提出要求或者同意接收的广告、电子刊物、各种形式的宣传品等宣传性的电子邮件;
②收件人无法拒收的电子邮件;
③隐藏发件人身份、地址、标题等信息的电子邮件;
④含有虚假的信息源、发件人、路由等信息的电子邮件。
企业邮箱怎么防止收到垃圾邮件
1、通过网页登录新网企业邮局,点击“设置”–“收信规则”–“反垃圾/黑白名单”。
2、对于不想收到的垃圾邮件,可以将垃圾邮件地址或者垃圾邮件的域名列入黑名单。
3、对于自己长期联系的邮件,如发现正常的邮件收到垃圾邮箱中了,可以添加白名单。
4、如果你在正常邮件中发现有垃圾邮件内容,可以点击举报,来避免以后再收到类似内容。
垃圾邮件的危害有哪些?
(1)占用大量网络带宽,浪费存储空间,影响网络传输和运算速度,造成邮件服务器拥堵,降低了网络的运行效率,严重影响正常的邮件服务。
(2)泛滥成灾的商业性垃圾信件,每5个月数量翻倍,国外专家预计每封垃圾邮件所抵消的生产力成本为1美元左右。我国开始被其他国家视为垃圾邮件的温床,许多IP地址有遭受封杀的危险,长期下去可能会使我国成为“信息孤岛”。
(3)垃圾邮件以其数量多、反复性、强制性、欺骗性、不健康性和传播速度快等特点,严重干扰用户的正常生活,侵犯收件人的隐私权和信箱空间,并耗费收件人的时间、精力和金钱。
(4)垃圾邮件易被黑客利用,危害更大。2002年2月,黑客先侵入并控制了一些高带宽的网站,集中众多服务器的带宽能力,然后用数以亿计的垃圾邮件发动猛烈攻击,造成部分网站瘫痪。
(5)严重影响电子邮件服务商的形象。收到垃圾邮件的用户可能会因为服务商没有建立完善的垃圾邮件过滤机制,而转向其他服务商。
(6)妖言惑众,骗人钱财,传播色情、反动等内容的垃圾邮件,已对现实社会造成严重危害。
2.项目简介
2.1项目说明
本项目旨在通过识别垃圾邮件和非垃圾邮件特征,构建分类算法模型,训练数据,最后得出一个模型效果较好的垃圾邮件分类器,以此来过滤识别垃圾邮件,净化邮箱环境。
2.2数据说明
数据集来源于kaggle平台,是一份国外垃圾邮件分类数据集,共有5572行,2列。具体字段信息如下:
| 属性名 | 属性描述 |
| Category |
类别(spam垃圾邮件和ham非垃圾邮件),object类型 |
| Message |
邮件内容,object类型 |
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
3.1决策树算法
决策树( Decision Tree) 又称为判定树,是数据挖掘技术中的一种重要的分类与回归方法,它是一种以树结构(包括二叉树和多叉树)形式来表达的预测分析模型。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。一般,一棵决策树包含一个根节点,若干个内部结点和若干个叶结点。叶结点对应于决策结果,其他每个结点对应于一个属性测试。每个结点包含的样本集合根据属性测试的结果划分到子结点中,根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定的测试序列。决策树学习的目的是产生一棵泛化能力强,即处理未见示例强的决策树。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。

决策树的构建
特征选择:选取有较强分类能力的特征。
决策树生成:典型的算法有 ID3 和 C4.5, 它们生成决策树过程相似, ID3 是采用信息增益作为特征选择度量, 而 C4.5 采用信息增益比率。
决策树剪枝:剪枝原因是决策树生成算法生成的树对训练数据的预测很准确, 但是对于未知数据分类很差, 这就产生了过拟合的现象。涉及算法有CART算法。
3.2朴素贝叶斯算法
(1)算法简介
朴素贝叶斯法是基于贝叶斯定理与特征条件独立性假设的分类方法。对于给定的训练集,首先基于特征条件独立假设学习输入输出的联合概率分布(朴素贝叶斯法这种通过学习得到模型的机制,显然属于生成模型);然后基于此模型,对给定的输入 x,利用贝叶斯定理求出后验概率最大的输出 y。
(2)朴素贝叶斯分类器的公式
假设某个体有n项特征(Feature),分别为F1、F2、…、Fn。现有m个类别(Category),分别为C1、C2、…、Cm。贝叶斯分类器就是计算出概率最大的那个分类,也就是求下面这个算式的最大值:
P(C|F1F2...Fn) = P(F1F2...Fn|C)P(C)/P(F1F2...Fn)
由于P(F1F2…Fn) 对于所有的类别都是相同的,可以省略,问题就变成了求
P(F1F2...Fn|C)P(C)的最大值。朴素贝叶斯分类器则是更进一步,假设所有特征都彼此独立,因此
P(F1F2...Fn|C)P(C) = P(F1|C)P(F2|C) ... P(Fn|C)P(C)
上式等号右边的每一项,都可以从统计资料中得到,由此就可以计算出每个类别对应的概率,从而找出最大概率的那个类。虽然“所有特征彼此独立”这个假设,在现实中不太可能成立,但是它可以大大简化计算,而且有研究表明对分类结果的准确性影响不大。
(3)朴素贝叶斯常用的三个模型
高斯模型:处理特征是连续型变量的情况
多项式模型:最常见,要求特征是离散数据
伯努利模型:要求特征是离散的,且为布尔类型,即true和false,或者1和0
(4) 朴素贝叶斯法的评价
朴素贝叶斯法的优点:
朴素贝叶斯算法假设了数据集属性之间是相互独立的,因此算法的逻辑性十分简单,并且算法较为稳定,当数据呈现不同的特点时,朴素贝叶斯的分类性能不会有太大的差异。换句话说就是朴素贝叶斯算法的健壮性比较好,对于不同类型的数据集不会呈现出太大的差异性。当数据集属性之间的关系相对比较独立时,朴素贝叶斯分类算法会有较好的效果。
朴素贝叶斯法的缺点:
属性独立性的条件同时也是朴素贝叶斯分类器的不足之处。数据集属性的独立性在很多情况下是很难满足的,因为数据集的属性之间往往都存在着相互关联,如果在分类过程中出现这种问题,会导致分类的效果大大降低。
3.3逻辑回归算法
1.逻辑回归
逻辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏。
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别)
回归模型中,y是一个定性变量,比如y=0或1,logistic方法主要应用于研究某些事件发生的概率
2. 逻辑回归的优缺点
优点:
1)速度快,适合二分类问题
2)简单易于理解,直接看到各个特征的权重
3)能容易地更新模型吸收新的数据
缺点:
对数据和场景的适应能力有局限性,不如决策树算法适应性那么强
3. 逻辑回归和多重线性回归的区别
Logistic回归与多重线性回归实际上有很多相同之处,最大的区别就在于它们的因变量不同,其他的基本都差不多。正是因为如此,这两种回归可以归于同一个家族,即广义线性模型(generalizedlinear model)。
这一家族中的模型形式基本上都差不多,不同的就是因变量不同。这一家族中的模型形式基本上都差不多,不同的就是因变量不同。
如果是连续的,就是多重线性回归
如果是二项分布,就是Logistic回归
如果是Poisson分布,就是Poisson回归
如果是负二项分布,就是负二项回归
4. 逻辑回归用途
寻找危险因素:寻找某一疾病的危险因素等;
预测:根据模型,预测在不同的自变量情况下,发生某病或某种情况的概率有多大;
判别:实际上跟预测有些类似,也是根据模型,判断某人属于某病或属于某种情况的概率有多大,也就是看一下这个人有多大的可能性是属于某病。
5. Regression 常规步骤
寻找h函数(即预测函数)
构造J函数(损失函数)
想办法使得J函数最小并求得回归参数(θ)
6. 构造预测函数h(x)
1) Logistic函数(或称为Sigmoid函数),函数形式为:

对于线性边界的情况,边界形式如下:

其中,训练数据为向量

最佳参数

构造预测函数为:

函数h(x)的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
P(y=1│x;θ)=h_θ (x) P(y=0│x;θ)=1-h_θ (x)
4.项目实施步骤
4.1理解数据
首先导入数据集

接着查看数据大小

从结果看出原始数据集中共有5572行,2列
查看数据基本信息

从结果看出,原始数据集中不存在缺失值,所以后期不需要进行缺失值处理。
4.2数据预处理
因为前面发现数据集不存在缺失值,所以这里我们就对重复值进行处理即可

从结果中看出,删除了415个重复值,重复数据还挺多,间接说明这些可能都是些重复的垃圾邮件。
4.3探索性数据分析
看看数据集中的Category的类别分布情况
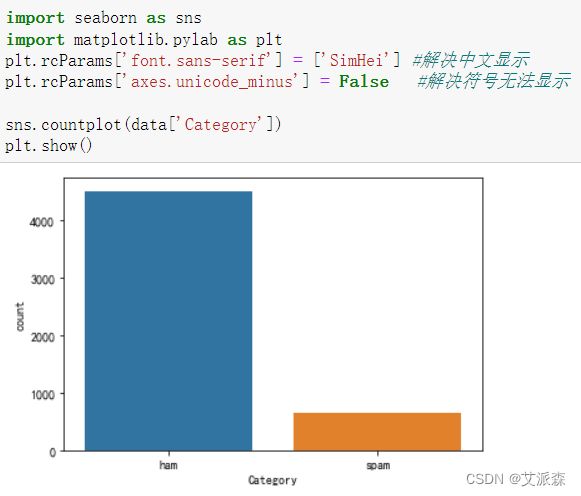
从图看出,垃圾邮件的数量远小于非垃圾邮件,数据分布不均衡,后期需要进行欠采样处理。
4.4特征工程
首先是对Category类别进行0 1编码处理,将字符型数据转换为模型能识别的数值型

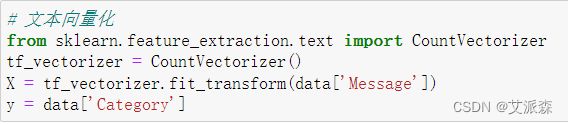
接着将Message文本型数据进行文本向量化
最后对数据进行欠采样处理,这里的imblearn库需要安装(pip install imblearn)

4.5模型构建
构建模型之前,首先对原始数据集进行拆分为训练集和测试集

构建决策树算法模型并输出模型准确率

构建朴素贝叶斯算法模型并输出模型准确率

构建逻辑回归算法模型并输出模型准确率

通过构建三个模型并对比其准确率得出,逻辑回归模型的准确率最高为0.96,故最后我们选择逻辑回归作为最后的训练模型。
4.6模型评估
首先使用模型分类报告进行评估


从结果可以看出模型在0和1分类上的精确率、召回率和F1值等信息。
接着是模型混淆矩阵图


从混淆矩阵中可以看出模型在测试集上预测0分类时,预测正确有117个,错误有4个,在预测1分类时,正确有128个,错误有8个。

最后画出ROC曲线来评估模型

通过ROC曲线看出,红色曲线向左上角方向趋势较大,与斜率为1的直线围成的面积趋近于1,AUC值为0.99,这些都说明了模型的效果较为不错。
4.7模型预测
最后使用模型进行预测,我们选取测试集中的前十个来检验

从结果看出,这十个结果模型全部预测正确,模型效果不错。
5.实验总结
本次实验使用逻辑回归算法构建了垃圾邮件分类器模型,模型准确率为0.96,模型效果较好,可以有效的精准识别垃圾邮件,提高工作效率,净化网络环境。
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。