基于K210的yolo识别教程和maixhub下载的模型load报错解决方案
基于K210的yolo识别教程和maixhub下载的模型load报错解决方案
- 基于k210的yolo模型搭建
-
- 模型搭建的训练的几种方法
-
- 爬百度图片脚本-方便做训练集
- 修改训练集图片标签
- maixhub训练的模型在k210上无法加载问题
-
- 检查sd卡
- 模型损坏问题
- k210固件版本太低
基于k210的yolo模型搭建
以下介绍还是基于maixpy这样一个micropython的IDE开发的,用到的模型也是基于yolo,方便像我这样刚接触的迅速能入手做项目,但不涉及算法优化。
模型搭建的训练的几种方法
这个博主已经讲了四种最常见的方法,已经很全面了,需要的小伙伴可以去学习https://blog.csdn.net/moshanghuaw/article/details/113172455
由于袁老师已经开源了yolo3的模型训练可执行文件,但还是需要在系统默认环境下装一些配置,可能有些小伙伴电脑上已经有py的一些虚拟环境或者其他版本的py(像我还不止一个),可能偷懒不想再搞那些东西。
下面对自己在pc端训练模型或者在maixhub上训练模型的小伙伴提供几个比较有用的脚本,方便训练集。
爬百度图片脚本-方便做训练集
以下也是我从别的博主那里学习来的,只是一个罗列,方便大家一起学习,有python环境就能执行,本身代码并不难,有代码基础的学习一下一些函数功能就会了。(两个小脚本还需要特别感谢原作者,我确实不记学习链接了,如有冒犯还请原谅)
下面展示一些 内联代码片。
import re
import requests
from urllib import error
import os
num = 0
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
def dowmloadPicture(html, keyword): #用来找到和下载图片
global num #全局变量
pic_url = re.findall('"objURL":"(.*?)"', html, re.S)
# 先利用正则表达式找到图片url # re.findall(正则表达式,需要处理的字符串,说明匹配模式)
#(.*?)‘.’代表任意字符;‘*?’非贪婪模式匹配(匹配越少越好) ()代表输出括号内容,无括号和前后一起输出
print('找到关键词:' + keyword + '的图片,即将开始下载图片...')
for each in pic_url:
print('正在下载第' + str(num + 1) + '张图片,图片地址:' + str(each))
try:
if each is not None: #如果 each 不是空
pic = requests.get(each, timeout=7)
else:
continue
except BaseException:
print('错误,当前图片无法下载')
continue
else: #当没有异常发生时,else中的语句将会被执行
string = file + r'\\' + keyword + '_' + str(num) + '.jpg'
fp = open(string, 'wb')
fp.write(pic.content)
fp.close()
num += 1
if num >= numPicture:
return
if __name__ == '__main__': # 主函数入口
word = input("请输入搜索关键词(可以是人名,地名等): ")
# add = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%BC%A0%E5%A4%A9%E7%88%B1&pn=120'
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&pn='
numPicture = int(input('请输入想要下载的图片数量:'))
file = input('请建立一个存储图片的文件夹,输入文件夹名称即可:')
while os.path.exists(file) == 1: #判断括号里的文件是否存在
print('该文件已存在,请重新输入')
file = input('请建立一个存储图片的文件夹,输入文件夹名称即可:')
os.mkdir(file) #创建文件夹
t = 0
tmp = url
while t < numPicture:
try:
url = tmp + str(t)
result = requests.get(url, timeout=10,headers = headers) #timeout 设置连接超时的时间
print(url)
except error.HTTPError:
print('网络错误,请调整网络后重试')
t = t + 60
else:
dowmloadPicture(result.text,word)
t = t + 60
print('当前搜索结束,感谢使用')
修改训练集图片标签
import os
count=0
if __name__ == '__main__':
path = "F:/Mx-yolov3_app/train_picture/Python爬百度图片小程序/Tshirt"
file_list = os.listdir(path)
for file in file_list :
Olddir = os.path.join(path,file)
if os.path.isdir(Olddir):
continue
filename = os.path.splitext(file)[0]
file_type = os.path.splitext(file)[1]
Newdir = os.path.join(path
,str(count).zfill(4)+file_type)
os.rename(Olddir,Newdir)
count += 1;
编码只需要对倒数第三行的zfill()内的数字进行修改就可,比如 4 则编码为0001 0002 ……。
maixhub训练的模型在k210上无法加载问题
报错:kpu load error / can not read file
按照控制变量法一步一步找问题
检查sd卡
随便搞个txt文件,python主函数内open(“/sd/xxxxxx.kmodel”).read(1024)然后print出来,看看sd卡能不能正常读取
模型损坏问题
如果你是maixhub上训练的模型,先不谈正确率,发给你了boot测试程序,说明肯定是ok的,跳到第三步忽略不谈。
如果自己主机训练的模型,需要考虑模型文件是否转化成kmodel类型(sd卡),如果是烧到内存中,.kfpkg格式。不排除网络本身有问题。可尝试重新训练。
k210固件版本太低
这是很多小白注意不到的问题,首先到官网看看固件是不是最新的如果是maixhub下载的模型,他都是最新版本的固件。固件更新链接
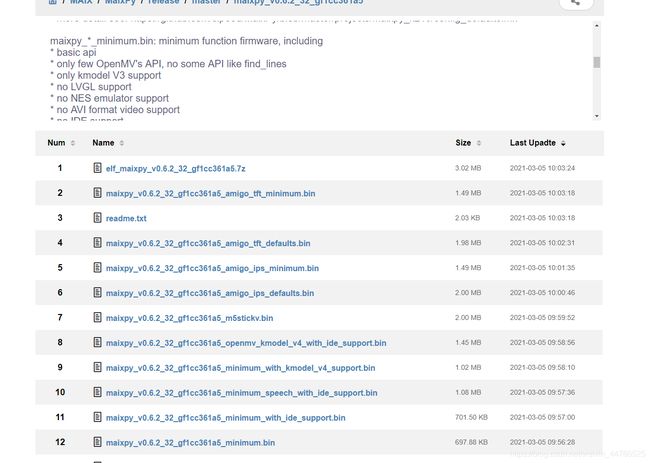
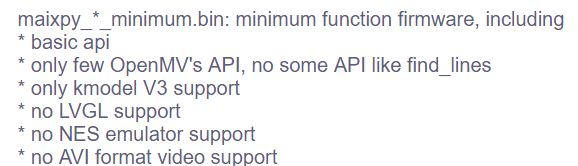
如图,需要注意的是读readme,同一版本推出了不同功能的固件文件,有些是只能kmodel v3 有些是v4
如图

同一版本如何选择需要下哪个固件呢?
给小白一个表格参考:
 建议第4个,内存占用小,支持运行需要的模型文件即可。一般maixhub下的模型都是最新的v4的。
建议第4个,内存占用小,支持运行需要的模型文件即可。一般maixhub下的模型都是最新的v4的。
如果是自己训练的模型也相对的找到对应的版本和功能即可,这方面我也没啥太多的建议,试错得出来的经验吧。
#菜鸡一枚,大佬轻喷,希望给刚接触k210的小白一点方向,对你有帮助。