关于目标检测RCNN(Fast-RCNN/Faster-RCNN)系列的理解
目前较为成熟的目标检测算法可总结如下:

RCNN(2014年)
RCNN是一个多阶段训练模型,包括生成候选区域,CNN微调,SVM分类训练以及边界框回归等多个步骤(Selective Research+CNN+SVM)。
整体流程
类似于滑动窗口思想,R-CNN 采用对区域进行识别的方案,具体是:
1、给定一张输入图片,从图片中提取 2000 个类别独立的候选区域。
2、对于每个区域利用 CNN 抽取一个固定长度的特征向量。
3、再对每个区域利用 SVM 进行目标分类。
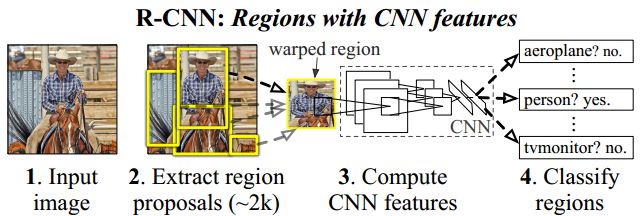
候选区域生成
利用基于区域推荐的Selective Search方法,在图像中提取2000个候选区域。相较于之前的滑窗法(windows sliding)有很大的提升。
CNN提取特征
RCNN的结构实际是5个卷积层、2个全连接层。输入是Region Proposal计算的推荐区域的图像,由于该CNN网络输入限定为2000 x 227 x 227 x 3(RGB)的输入,故在RCNN中将Region Proposal的推荐区域仿射变形到227 x 227的格式上,网络输出是2000 x 4096 x 1的特征向量。

SVM分类
使用训练过的对应类别的SVM给特征向量中的每个类进行打分,每个类别对应一个二分类SVM,CNN输出2000 x 4096,SVM输出2000*N(N是数据集中目标的类别),然后为了减少重复的bounding box,使用了非极大值抑制法:
如果一个区域的得分与大于它得分的区域有很大程度的交叉(intersection-overunion(IoU))根据score进行排序,把score最大的bounding box作为选定的框,计算其余bounding box与当前最大score与box的IoU,去除IoU大于设定的阈值的bounding box。然后重复上面的过程,直至候选bounding box为空,然后再将score小于一定阈值的选定框删除得到一类的结果。
bounding box回归
受DPM (Object detection with discriminatively trained part based models)的灵感,训练一个线性回归模型,给定pool5层的特征预测一个新的检测窗口。
训练细节
1、使用ILSCRC2012训练集对CNN Alexnet模型进行预训练 ;
2、使用Select Research对每张图片上生成2000个左右的候选的区域(IoU>0.5的标记正样本,IoU<0.5的标记负样本),将候选框大小调整为227*227大小 ;
3、将生成的候选区域送入预训练完成的Alexnet网络中进行微调,微调时使用SGD,并将学习率设置为预训练时的1/10;
4、微调完成后,在进行SVM之前需要重新定义正负样本,其中IoU<0.3的为背景负样本,正样本用GT box来表示 ;
5、将重新定义的候选框从Alexnet中得到4096维度的特征向量,进行SVM训练,为每一个类别训练一个二分类器;
6、线性回归模型回归边界框
测试细节
1、测试集上的图片使用SelectResearch生成2000个大小的候选区域,并调整到227*227大小;
2、使用CNN计算每个特征图的特征向量;
3、使用多个SVM二分类器进行预测每个类的概率;
4、对每一类别执行NMS(非极大值抑制),保留该类别概率值较大的候选框,对保留的候选框进行边界框回归。
优缺点
1、训练时有多个任务,CNN微调,SVM分类器,边界框回归等,且彼此之间存在联系,增加潜在范围的误差
2、训练过程在时间和空间上时非常耗时和昂贵的
3、在测试时,物体检测速度比较慢
论文中的一个观点,就是当你缺乏大量的标注数据时,比较好的可行的手段是,进行神经网络的迁移学习,采用在其他大型数据集训练过后的神经网络,然后在小规模特定的数据集中进行 fine-tune 微调。
Fast-RCNN(2015年)
Fast-RCNN解决了RCNN中的三个大问题:测试、训练速度慢、需要空间大

原因及改进:
-
R-CNN中用CNN对每一个候选区域反复提取特征,而一张图片的2000个候选区域之间有大量重叠部分,这一设定造成特征提取操作浪费大量计算。
-
Fast R-CNN将整个图像归一化后直接送入CNN网络,卷积层不进行候选区的特征提取,而是在最后一个池化层加入候选区域坐标信息,进行特征提取的计算。
-
R-CNN中目标分类与候选框的回归是独立的两个操作,并且需要大量特征作为训练样本。
-
Fast R-CNN将目标分类与候选框回归统一到CNN网络中来,不需要额外存储特征。
结果对比:
Fast R-CNN和R-CNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。在PASCAL VOC 2007上的准确率相差无几,约在66%-67%之间。
最大贡献
- 引入RoI池化层
- 全连接层中目标分类与检测框回归微调的统一。
RoI池化层
不同于R-CNN多次对每个图像提取特征,Fast R-CNN使用特征提取器(CNN)先提取整个图像的特征,然后将候选区域直接映射到特征图中(就是坐标乘以原图像与特征图比例)
(1)根据输入image,将ROI映射到feature map对应位置;
(2)将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
(3)对每个sections进行max pooling操作;

特征提取
首先将图片用selective search得到2000个候选区域(region proposals)的坐标信息。另一方面,直接将图片归一化到CNN需要的格式,整张图片送入VGG,将第五层的普通池化层替换为RoI池化层。图片然后经过5层卷积操作后,得到一张特征图(feature maps),开始得到的坐标信息通过一定的映射关系转换为对应特征图的坐标,截取对应的候选区域,经过RoI层后提取到固定长度的特征向量,送入全连接层。因为 Fast-RCNN 不会重复提取特征,因此它能显著地减少处理时间。

目标分类与检测框的回归
在R-CNN中的流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression进行候选框的微调。Fast R-CNN是将候选框目标分类与bbox regression并列放入全连接层,形成一个multi-task模型

损失函数如下:
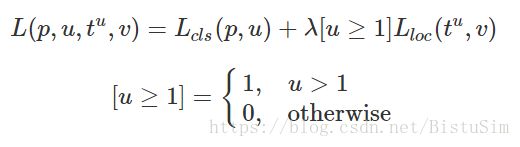
测试细节
1、将任意大小的图片送入CNN 网络,得到图片的特征图;
2、使用SelectResearch得到2000个左右的候选框,根据原图像到特征图的映射关系,得到候选框在特征图上的位置;
3、将提取的特征框送入ROI层得到固定大小的特征向量;
4、将特征向量分别送入两个全连接层(使用SVD分解),得到回归框的位置和类别的概率;
5、根据得到的概率和位置进行非极大值抑制,得到概率较高的窗口
SVD全连接加速网络
在实现时,相当于把一个全连接层拆分为两个全连接层,第一个全连接层不含偏置,第二个全连接层含偏置;实验表明,SVD分解全连接层能使mAP只下降0.3%的情况下提升30%的速度,同时该方法也不必再执行额外的微调操作

参考部分:原文点击这里