网络边缘的使能智能:联邦学习
摘要:
机器学习和无线技术的迅速发展正在为未来网络创造新的范式,人们期望通过大量数据集的推理获得更高程度的智能、并能够及时对当地响应作出反应。由于终端设备产生的海量数据,以及人们对隐私信息共享的日益关注,一个新的机器学习模型分支——联邦学习在人工智能和边缘计算的交叉领域应运而生。与传统的机器学习方法相比,联邦学习将模型直接带到设备中进行训练,将得到的参数发送到边缘服务器。该模型在设备上的本地副本带来了消除网络延迟和保护数据隐私的巨大优势。然而,要是联邦学习成为可能,我们需要应对新的挑战,这些挑战需要从根本上背离分布式优化标准方法。本文,我们的目标是提供一个联邦学习的综述。具体来说,我们首先研究联邦学习的基础,包括学习结构和鱼传统机器学习模型不同的特点。然后,我们列举几个在无线网络中部署联邦学习的关键问题。从算法设计、设备训练到通信资源管理等角度,展示为什么以及如何将技术联合起来促进全面实施。最后,对一些潜在的应用和未来的趋势进行展望。
关键词:联邦学习、边缘智能、学习算法、有效提出、隐私安全
1.简介
网络系统正在经历一个范式变换,从传统的云计算架构到移动边缘计算。云计算将计算资源聚集到一个数据中心,边缘计算将计算资源部署在网络边缘以满足应用程序(常见的、在不可靠网络连接、支持资源受限的节点)的需要。随着机器学习研究的蓬勃发展,通过整合机器学习算法到边缘节点,预计未来的网络将能够利用本地数据执行智能推理和管理多个活动。例如,学习手机用户的活动、从可穿戴设备中预测健康情况,或者利用智能家居设备检测偷窃。
但是,由于数据提出由终端设备产生,海量的数据数据集和对隐私信息的日益关注,用户不愿意将原始数据发送到边缘服务器参与任何模型的训练,即便最终对用户有利。为了应对这一难题,联邦学习出现了,它允许数据采集和计算在中央单元解耦。具体来说,不是在中央单元收集所有数据进行训练,联邦学习将模型直接带到终端设备进行训练,只将训练后的参数发送给边缘服务器。这个特征有很多优势,消除了大的通信开销和保留数据隐私,使得联邦学习与移动应用程序特别相关。这些特征也确定了联邦学习是智能移动边缘网络最有前途的因素之一。
然而,为了实现一个成功的联邦学习部署,面临些许挑战。联邦学习发生在移动边缘系统,一个服务器安排一系列终端设备进行训练,设备间不是独立同分布的、不平衡的数据集、通信资源有限。因此,这使得学习架构脆弱,解决这些问题需要从许多方面进行联合研究,包括:学习算法、系统设计、通信和信息理论。【10】讨论了当面对异构的数据集时,提高训练效率的可能方法。【6】研究了应用联邦学习的边缘网络端到端延迟、可靠性、和可扩展性。【8】探索了在网络边缘整合学习算法的挑战和解决方法。【9】讨论了一系列利用无线信道部署联邦学习的指导方针。经过不懈探索,成果显著:将在第4部分赘述。文章安排如下:第二章介绍基础框架和联邦学习的模型的特征。第三章介绍联邦学习实际部署的核心技术。第四章讨论讨论联邦学习潜在的应用和未来发展趋势。第五章,总结。
2.联邦学习:基础和特征
2.1基础架构
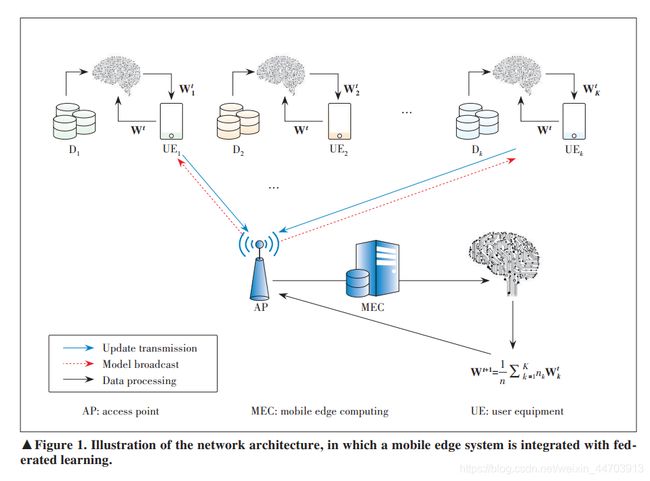
如图1所示,网络单元包括一个中央单元(通常部署在基站或者接入点的边缘服务器)和一些终端设备,它们一起有合作地学习一个模型。这个模型由工程师专为某一应用专门设计的,然后,服务器通过重复下面的步骤协调终端用户的学习过程:
- Client selection:服务器选择符合要求的终端。例如当前存在无线连接的手机或者平板电脑进行一轮训练。
- Broadcast:被选择的终端从服务器端下载最先的模型,包括权重和训练程序。
- End-user computation:在一个周期内,每个被选择的终端执行本地计算,通常采用随机梯度下降(SGD)的方式,并上传最终参数到服务器。
- Update aggregation:服务器从终端收集和更新——以训练参数或梯度的形式。或聚合——通常通过加权平均的方式聚合收集的结果。
- Model update:服务器对模型进行更新。
经过大量的训练和更新交流(通常称为通信回合),全局统计模型收敛到最优形式,终端可以从这个协作学习模型中受益。
- 优点:联邦学习中,用户能够直接下载模型和执行训练,并将最终的训练参数反馈给服务器。用户终端避免了分享本地数据因此保护了隐私。此外,本地训练减少了原始数据的上传,原始数据规模很大上传将消耗大量的能量。最后,联邦学习与无线应用尤其相关。
- 挑战:联邦学习的缺点同样明显。由于训练发生在大量异构的实体中。例如:不同的终端有不同的处理能力和通信状态,学习效率比在数据中心要低。联邦学习环境下的通信可靠性差,安全性问题更严峻。
2.2显著特征
联邦学习与传统分布式学习的相同点:都由大量的终端执行计算,由中央实体负责协调终端之间的迭代。
联邦学习传统分布式学习的不同点:
- Non-i.i.d dataset:联邦学习最显著的特点是每个终端设备都是高度个性话的,因此数据集非独立同分布。相互依赖的和非独立的的原因是用户的个性化、特定的地理环境、特定的时间阶段。因此,不同于传统场景中数据集是完全打乱和独立同分布的,联邦学习的非独立同分布架构导致每个设备从全局最小化转向局部最小化,需要重新考虑学习模型,并在过程中考虑这些不同。
- Unbalanced data size:抛开非独立同分布,每个终端的数据集大小也不相同。因此,每个终端的训练程序也不同,因为一些终端的数据集较小可以短时间内完成训练,但是一些数据集大的终端需要耗费很多时间完成本地训练。此外,数据集大的终端可能对整个模型的贡献较大,因此如何在学习算法中衡量这些不同也十分重要。
- Limited communication resources:由于终端设备与中央实体之间要进行通信,因此通信是不可靠的。此外,无线资源通常是有限的,每个循环选择合适署数量的用户进行通信是必要的。
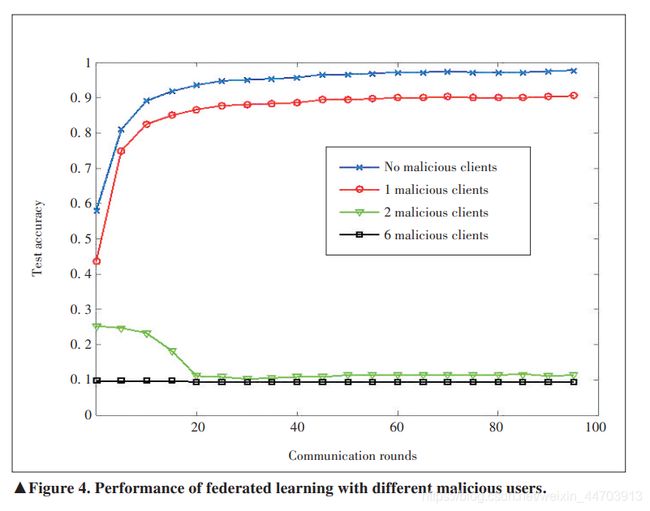
- Privacy/security issues:虽然联邦学习下不需要共享本地数据,这并不意味着隐私的绝对保护。事实上,可以从上传的参数中提取信息,并检索原始信息来近似扩展。此外,在联邦学习场景中,终端很容易被恶意攻击,黑客更容易向系统注意恶意信息。
值得注意的是,上述特征的一个显著特点是本质上跨学科,解决它们不仅需要机器学习,还需要分布式优化、安全性、差异隐私、公平性、压缩感知、系统、信息论、统计等方面的技术。事实上,许多最困难的问题都在这些领域的交叉点上,因此夸领域的研究与合作很是重要。
3.实际实施
3.1高效的学习算法
实现联邦学习的首要因素是一种高效的算法。由于数据集的非独立同分布,联邦学习的模型训练过程与传统的学习过程有很大的区别。具体来说,不同于分布计算(每个终端拥有一个统计独立的模型,名为经验主义损失函数),联邦学习由于数据集的个性化,每个终端有不同的经验主义损失函数。因此,局部最小值可能不同于全局最小值,学习算法应当重新设计以说明这一事实。此外,由于通信资源有限,服务器在每一轮通信中智能选择一部分用户进行更新,如何恰当地选择终端对整体学习效率也起着至关重要的作用。
3.1.1优化和模型聚合
由于用户数据集的非统计独立,在全局模型中对等的处理所以样本可能没有意义。因此,设计一个更加合理的目标函数是一个重要的研究方向。此外,目前最先进的训练是基于SGD的,以收敛慢著称。因此设计更有效率的算法对联邦学习很重要。此外,由于数量庞大,在训练全局模型时,每个设备可能只参与几轮,所以无状态算法的研究十分必要。
在聚合阶段,常用的算法是求平均的方法,一种根据数据集大小对收集到的参数自适应并行SGD加权求平均算法。虽然这种方法的有效性已经在不同模型中得到了证明,但仍不确定这是否是最优的聚合参数的方法,需要进一步研究。
3.1.2采样和用户选择
由于数据集架构不平衡和传输带宽的有限,每一轮数据的采样和用户的选择对全局学习的有效性很重要。具体地说,一方面,由于每个终端拥有属于自己特定的局部最小化经验主义损失函数,在局部花费大量的时间进行训练可能面临参数偏离全局最小化的风险。另一方面,由于全局通信比本地计算花费更多的时间,因此需要减少通信轮次。一次,怎样平衡局部计算和全局通信对联邦学习具有重要意义。每个局部训练的采样数据集大小需要根据全局训练阶段自适应调整。
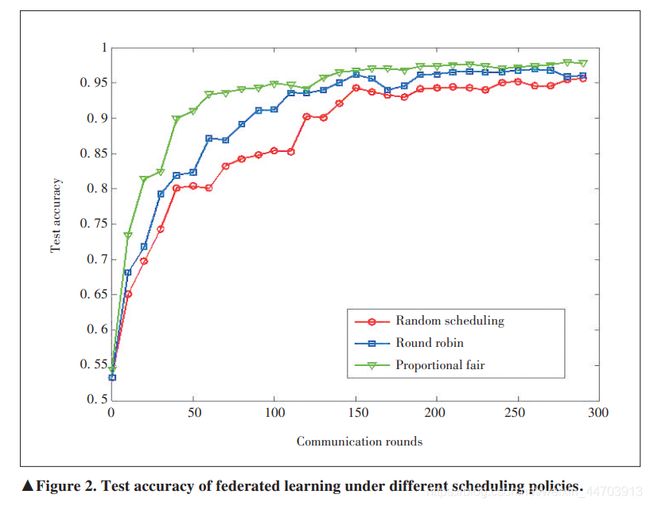
在全局聚合阶段,由于可用带宽有限,边缘服务器只能从总体用户数中选择一部分。因此,选择终端设备对联邦学习很重要。在边缘系统中,考虑信道质量,选择信道质量最好的终端,可以有效提高学习效率,如图2所示。在终端选择阶段考虑更新的时效性也很重要。
3.2模型压缩
虽然在过去的十年间,硬件水平改善,移动终端的处理能力大幅提高,但仍受功率和存储方面的限制,这是深度学习和联邦学习部署过程中遇到的问题。归因于深度神经网络往往由大量的激活单元和连接组成,因此训练这样的模型必然要消耗大量的能量,和占用存储空间。另一方面,即便模型训练任务可以完成,但上传参数需要较高的传输功率和很宽的带宽,这会带来很高的通信成本。方法如下:
- Architecture compression:从神经网络计算的角度看,通过修剪连接和压缩网络的大小减少成本。连接修剪的观点来自这样一个事实,即大多数连接权重通常是非常小的,简单来说,神经网络最有效的组成部分在结构上是稀疏的。因此,修剪一些权重较小的连接时可行的,并不会对精度产生很大影响,同时节省了存储空间。此外,在许多应用中,使用小型神经网络可以取得与大型神经网络同样好的性能,因此在终端直接减少神经网络的大小也是很好的办法。
- Gradient compression:从通信的角度,牺牲模型精度来降低通信开销。具体来说,提出机器学习在实际应用中提出不需要非常高的准确度,将训练梯度进行量化和压缩。这样就可以减小数据包的大小,节省通信资源,便于服务器解码。需根据终端的性质平衡通信成本和训练准确度开选择适当的量化水平。
图3描述了一个完整的模型压缩过程,可以发现移除神经网络中一些权重较小的连接是可取的。此外,连接较少的神经元也可以移除。架构压缩将模型转换成稀疏形式,并获得与传统神经网络相同的性能。另一部分是梯度压缩,由于参数是连续的,需要用较长的字符串表示,这对无线传输不利。通过适当量化,上传的数据量将大幅减小,这减少发射功率、节省传输带宽、便于边缘服务器解码。为了缓和量化噪声的影响,需要对量化策略进行研究,以减少模型精度损失。由于存在发送失败和重传的可能,编解码之前和之后的参数可能在不同的时序出现,尽管如此,服务器仍然可以利用序列号在全局聚合之前重拍参数。

3.3先进的通信和网络技术
通信:MIMO、NOMA、Full duplex、URLLC、联合处理能力和通信效率设计。
网络:服务器是最大的潜在失败点,尤其是终端数量十分庞大时,服务器成为了瓶颈。因此,端到端(D2D)的通信和干扰管理机制,自组织网络对联邦学习的性能有很大的影响。
3.4隐私保护技术
虽然联邦学习不明确共享原始数据,但黑客仍有可能提高检索原始信息来近似拓展。尤其是当学习架构和参数没有完全被保护起来。例如在通信过程中,优化算法的更新参数被直接暴露在外,这将泄露隐私信息。联邦学习的隐私和安全问题存在几个致命的点,如下:
3.4.1终端侧的隐私保护
联邦学习中,终端需要反复上传它们的学习结果到服务器来进行全局聚合。由于可能某个实体在监听上传的参数来推断重要信息,这些终端可能不信任服务器。未解决这个问题,终端可使用如下技术:
- Perturbation:加扰,终端在上传的数据中添加噪声,使用差分隐私来模糊某些敏感属性,直到第三方无法区分属性,从而无法恢复数据,保护用户隐私。
- Dummy:假参数、假模型。
3.4.2服务器侧的隐私保护
收集完来自终端更新的参数后,服务器通常执行加权平均来生成一个新的模型。但是,当服务器广播聚合参数反馈给终端时,可能发生信息泄露。
- Privacy-enabled aggregation:
- Secure multi-party computation (SMC):
3.4.3学习框架的隐私保护
1)Homomorphic encryption
2)Back-door defender
4.潜在应用和未来趋势
5.结论
我们对联邦收入系统进行了概述。具体地说,我们阐述了联邦学习模型的基本架构和显著特征,特别是非i.i.d。不平衡的数据集,不可靠和有限的通信资源,以及隐私和安全问题,这些都是它与传统通信的区别。此外,我们还介绍了一些实用的方法,使联邦学习的实现成为移动边缘系统。其中,从算法设计、模型压缩和通信效率等方面强调了其重要性。最后,我们介绍了几个应用程序,它们最有可能从应用联邦学习中获益。综上所述,我们认为联邦学习是实现智能网络的一个基石,我们期待在这一领域会出现更多有趣的研究问题。