PoS Tagging代码学习与应用
文章目录
-
-
- 代码学习(模型训练)
- 新数据集代入(模型应用)
- 此阶段总结
- 未来改进
-
代码学习(模型训练)
PyTorch PoS Tagging
import torch
import torch.nn as nn
import torch.optim as optim
# torchtext.legacy是torchtext 0.9.0版本的,现在在官方文档中已经找不到了
from torchtext.legacy import data
from torchtext.legacy import datasets
import spacy
import numpy as np
import time
import random
# Field类根据指令定义了一种用于转化为tensor的数据类型
# TEXT用于文本实例,UD_TAGS和PTB_TAGS分别是两种类型的词性标签
TEXT = data.Field(lower = True)
UD_TAGS = data.Field(unk_token = None)
PTB_TAGS = data.Field(unk_token = None)
# fields用于dataset传递信息
fields = (("text", TEXT), ("udtags", UD_TAGS), ("ptbtags", PTB_TAGS))
# 从datasets.UDPOS加载训练集、验证集、测试集
# UDPOS数据集每一行形式是years NOUN NNS,是句子中单词及其两种词性标注
# 训练集12543,验证集2002,测试集2077,形式如下图:
train_data, valid_data, test_data = datasets.UDPOS.splits(fields)

MIN_FREQ = 2
# build_vacab方法为当前field类实例,从一个或多个数据集中构建vocab对象(self.vacab)
# 增加的vocab就是词汇表的意思,语义上理解就是train_data中涉及的词汇集合
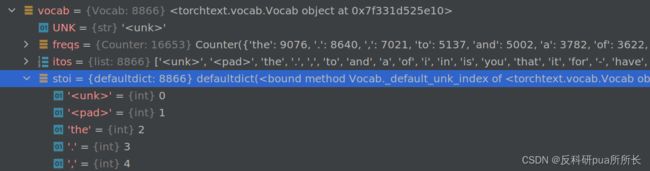
# vacab形式如下图,可以看到freqs是对词汇出现频次的统计,itos是所有词汇的list
# stoi词汇与给他们赋予的index的defaultdict
# TEXT.vocab.freqs.most_common(20)可以查看出现频次最高的20个词
# freqs是一个Counter变量,自动继承了most_common()函数,不用传参也可以
# vectors是将vocab中的单词利用glove转化为词嵌入的结果,(866, 100)
TEXT.build_vocab(train_data,
min_freq = MIN_FREQ,
vectors = "glove.6B.100d",
unk_init = torch.Tensor.normal_)
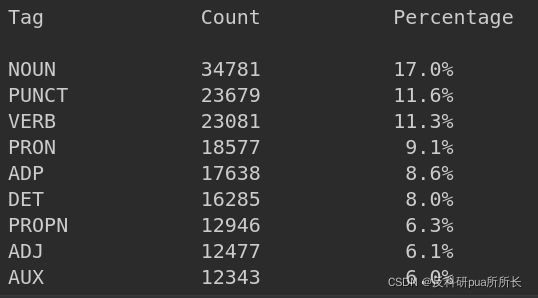
# UD_TAGS的vocab如下下图
UD_TAGS.build_vocab(train_data)
PTB_TAGS.build_vocab(train_data)

# 此函数用于统计field对象中vocab中的单词在examples中出现的频率(具体看的不是很懂),效果如下图:
def tag_percentage(tag_counts):
total_count = sum([count for tag, count in tag_counts])
tag_counts_percentages = [(tag, count, count/total_count) for tag, count in tag_counts]
return tag_counts_percentages
print("Tag\t\tCount\t\tPercentage\n")
for tag, count, percent in tag_percentage(UD_TAGS.vocab.freqs.most_common()):
print(f"{tag}\t\t{count}\t\t{percent*100:4.1f}%")
# 用dataset构造data_loader,但是这里调用了BucketIterator类进行构造
# BucketIterator类定义了一个用于batch相似长度的examples的迭代器
# 其能够在为一个新epoch生成新鲜乱序的batches时,最小化需要padding的量
# 其下定义了一个create_batches函数,由于是函数,因此在生成BucketIterator类时并不会执行
# 但是在真正运行时,就会运行这个函数,这个函数会生成self.batches对象,此函数如下图,会调用self.data()
# self.data()会按序、按类、或随机(由参数决定)返回dataset中的examples
# 结论是:真正运行时,调用batch就相当于调用bsz个examples的封装
BATCH_SIZE = 128
device = torch.device('cuda:5' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
下面开始构建模型,其中关于nn.Embedding的部分来自于通俗讲解pytorch中nn.Embedding原理及使用
# 构建模型
# 输入:batch.text (128, len)
class BiLSTMPOSTagger(nn.Module):
def __init__(self,
input_dim,
embedding_dim,
hidden_dim,
output_dim,
n_layers,
bidirectional,
dropout,
pad_idx):
super().__init__()
# nn.Embedding一个简单的查找表,能够存储一个固定字典的embeddings和大小
# 其中padding_idx指示的时不参与梯度计算的部分(以padding_idx为索引的实体,此处为1)
# 输入是要提取的任意维度的索引的tensor (max_len, 128)
# 输出是转化后的嵌入tensor (max_len, 128, embedding_dim=100)
# nn.Embedding对输入的要求(假设现在拿到的是最原始的句子):
# 1)句子标准化
# 2)按照单词数从多到少重新排列句子(方便之后进行pad)
# 3)将单词转化为单词表中的对应序号,即word2id过程,然后在句子结尾加EOS符号
# 4)记录句子长度
# 5)将所有句子pad为相同长度max_len,记录pad对应的idx,之后作为参数赋值给padding_idx
# 6)转化为RNN需要的形式(max_len, 128),因为RNN是以时序为单位的
# nn.Embedding层的参数与其他层不同,其存储的是一个查找表,因此此参数是一个结果,会被直接拿到当作下一层的输入(而其他层的参数大多是参与计算的权重)
self.embedding = nn.Embedding(input_dim, embedding_dim, padding_idx = pad_idx)
self.lstm = nn.LSTM(embedding_dim,
hidden_dim,
num_layers = n_layers,
bidirectional = bidirectional,
dropout = dropout if n_layers > 1 else 0)
self.fc = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
#text = [sent len, batch size]
#pass text through embedding layer
embedded = self.dropout(self.embedding(text))
#embedded = [sent len, batch size, emb dim]
#pass embeddings into LSTM
outputs, (hidden, cell) = self.lstm(embedded)
#outputs holds the backward and forward hidden states in the final layer
#hidden and cell are the backward and forward hidden and cell states at the final time-step
#output = [sent len, batch size, hid dim * n directions]
#hidden/cell = [n layers * n directions, batch size, hid dim]
#we use our outputs to make a prediction of what the tag should be
predictions = self.fc(self.dropout(outputs))
#predictions = [sent len, batch size, output dim]
return predictions
INPUT_DIM = len(TEXT.vocab) # 8866
EMBEDDING_DIM = 100
HIDDEN_DIM = 128
OUTPUT_DIM = len(UD_TAGS.vocab) # 18
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.25
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] # 1
model = BiLSTMPOSTagger(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)
# 初始化模型参数,以标准正态分布取样
def init_weights(m):
for name, param in m.named_parameters():
nn.init.normal_(param.data, mean = 0, std = 0.1)
model.apply(init_weights)
# 其中embedding层的参数初始化使用GloVe模型的参数
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
# 将pad_token全部置0,因此要对embedding这个查找表操作,即pad_idx那一列的所有值都为0
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
# 计算模型总参数量的函数
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
# 构造优化器
optimizer = optim.Adam(model.parameters())
# 使用交叉熵构造损失函数,交叉熵损失中需要预测和标签,我们设置的标签都为0,因为我们对pad对应的预测不感兴趣
# nn.CrossEntropyLoss的参数ignore_index指定了需要被忽略的目标值,因此将目标值中无需考虑的标签index设为0赋给ignore_index即可
TAG_PAD_IDX = UD_TAGS.vocab.stoi[UD_TAGS.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TAG_PAD_IDX)
# 模型和损失都放到gpu上
# 需要放在gpu上的一共三部分:输入、模型、损失函数
# (其中输入已经在之前通过train_dataloader放在gpu上了)
model = model.to(device)
criterion = criterion.to(device)
有个大问题,就是现在训练数据的标签是符合语境的吗?(是,是给语境的标签,那我请问我是否需要自己标数据?)(按照上面那篇文章,对于PoS Tagging部分他是不需要进行监督的,就是用预训练的提取?)(但是这里貌似不是预训练的哇)(但是有一个训练了10个epoch的模型,暂时先拿这个用,之后提升可以参考未来改进部分
def categorical_accuracy(preds, y, tag_pad_idx):
"""
Returns accuracy per batch, i.e. if you get 8/10 right, this returns 0.8, NOT 8
"""
max_preds = preds.argmax(dim = 1, keepdim = True) # get the index of the max probability
non_pad_elements = (y != tag_pad_idx).nonzero()
correct = max_preds[non_pad_elements].squeeze(1).eq(y[non_pad_elements])
return correct.sum() / y[non_pad_elements].shape[0]
def train(model, iterator, optimizer, criterion, tag_pad_idx):
epoch_loss = 0
epoch_acc = 0
# model.train()启用batch normalization和drop out
model.train()
for batch in iterator:
# text: (95, 128)
# train_data中的原始数据是examples,那么train_iterator就完成了nn.Embedding需要的六个步骤(除了第一步,因为标准化已经完成)
text = batch.text
tags = batch.udtags
optimizer.zero_grad()
#text = [sent len, batch size]
predictions = model(text)
#predictions = [sent len, batch size, output dim]
#tags = [sent len, batch size]
predictions = predictions.view(-1, predictions.shape[-1])
tags = tags.view(-1)
#predictions = [sent len * batch size, output dim]
#tags = [sent len * batch size]
loss = criterion(predictions, tags)
acc = categorical_accuracy(predictions, tags, tag_pad_idx)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def evaluate(model, iterator, criterion, tag_pad_idx):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
text = batch.text
tags = batch.udtags
predictions = model(text)
predictions = predictions.view(-1, predictions.shape[-1])
tags = tags.view(-1)
loss = criterion(predictions, tags)
acc = categorical_accuracy(predictions, tags, tag_pad_idx)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
# 开始训练
N_EPOCHS = 10
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion, TAG_PAD_IDX)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion, TAG_PAD_IDX)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut1-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')
新数据集代入(模型应用)
这一部分是利用已经训练好的模型tut1-model.pt,以Charades-STA数据集的文本部分为例,简单观察一下效果
工作:1)准备训练好的模型 2)处理sentence为输入形式+可视化tag 3)构造vmr的sentence
# 1)建立模型结构并加载训练好的模型
from pos_train import BiLSTMPOSTagger
device = torch.device('cuda:5' if torch.cuda.is_available() else 'cpu')
INPUT_DIM = len(TEXT.vocab) # 8866
EMBEDDING_DIM = 100
HIDDEN_DIM = 128
OUTPUT_DIM = len(UD_TAGS.vocab) # 18
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.25
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] # 1
model = BiLSTMPOSTagger(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)
model.load_state_dict(torch.load('tut1-model.pt'))
将句子处理为nn,Embedding的标准: 1)句子标准化 2)按照单词数从多到少重新排列句子(方便之后进行pad) 3)将单词转化为单词表中的对应序号,即word2id过程,然后在句子结尾加EOS符号 4)记录句子长度 5)将所有句子pad为相同长度max_len,记录pad对应的idx,之后作为参数赋值给padding_idx 6)转化为RNN需要的形式(max_len, 128),因为RNN是以时序为单位的
# 首先准备参数,text_field是一个Field类,需要经过的处理是:
TEXT = data.Field(lower = True)
# 出现频率两次才放入vocab(否则看作unknown)
MIN_FREQ = 2
TEXT.build_vocab(train_data,
min_freq = MIN_FREQ,
vectors = "glove.6B.100d",
unk_init = torch.Tensor.normal_)
# 2)处理输入
def tag_sentence(model, device, sentence, text_field, tag_field):
# model.eval()沿用batch normalization的值,并不使用drop out
model.eval()
if isinstance(sentence, str):
# spacy使用的语言模型是预先训练的统计模型,能够预测语言特征
# 对于英语,共有en_core_web_sm、en_core_web_md和en_core_web_lg三种语言模型
# 还有一种语言模型:en,需要以管理员权限运行以下命令来安装en模型:
# python -m spacy download en
# spacy.load用来加载语言模型,包括name和disable两个参数,后者表示禁用
# 加载之后得到的nlp及如果如下图所示
nlp = spacy.load('en_core_web_sm')
# 下下图是nlp的一个属性tokenizer,猜想是用来进行分词的,其中vocab表示分词的词典
tokens = [token.text for token in nlp(sentence)]
else:
tokens = [token for token in sentence]
# 变成小写,这两步是完成处理1)
if text_field.lower:
tokens = [t.lower() for t in tokens]
# 3)完成word2id
numericalized_tokens = [text_field.vocab.stoi[t] for t in tokens]
# 记录unknown单词的index
unk_idx = text_field.vocab.stoi[text_field.unk_token]
# 所有unknown单词的list,这一步是为了找出不在词汇表中的单词
unks = [t for t, n in zip(tokens, numericalized_tokens) if n == unk_idx]
# 将id转化为tensor并放到gpu上
# token_tensor: (vocab_len)
token_tensor = torch.LongTensor(numericalized_tokens)
# (1, vocab_len)
token_tensor = token_tensor.unsqueeze(-1).to(device)
# 一次性放入model
predictions = model(token_tensor)
# 获得预测结果
top_predictions = predictions.argmax(-1)
# 转化为可视化的tag
predicted_tags = [tag_field.vocab.itos[t.item()] for t in top_predictions]
return tokens, predicted_tags, unks

3)vmr数据构建(以charades为例)
from pos_train import BiLSTMPOSTagger
import torch
from torchtext.legacy import data
import spacy
from torch.utils.data import Dataset
from torchtext.legacy import datasets
nlp = spacy.load('en_core_web_sm')
from torch.utils.data import DataLoader
import itertools
class Charades_Text(Dataset):
def __init__(self, annotation_file, text_field):
self.data = [x.strip().split('##')[-1] for x in open(annotation_file)]
self.text_field = text_field
# self.data = []
# for x in open(annotation_file):
# sentence = x.strip().split('##')[-1]
# self.data.append(token.text for token in nlp(sentence))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
tokens = [token.text for token in nlp(self.data[idx])]
tokens = [t.lower() for t in tokens]
# 3)完成word2id
numericalized_tokens = [self.text_field.vocab.stoi[t] for t in tokens]
# 记录unknown单词的index
unk_idx = self.text_field.vocab.stoi[self.text_field.unk_token]
# 将id转化为tensor并放到gpu上
# token_tensor: (vocab_len)
token_tensor = torch.LongTensor(numericalized_tokens)
# (vocab_len, 1)
# token_tensor = token_tensor.unsqueeze(-1).to(device)
return token_tensor
def text_process(batch):
batch = torch.nn.utils.rnn.pad_sequence(batch, batch_first=False, padding_value=1)
return batch
if __name__=='__main__':
TEXT = data.Field(lower=True)
UD_TAGS = data.Field(unk_token=None)
PTB_TAGS = data.Field(unk_token=None)
# fields用于dataset传递信息
fields = (("text", TEXT), ("udtags", UD_TAGS), ("ptbtags", PTB_TAGS))
# 从datasets.UDPOS加载训练集、验证集、测试集
# UDPOS数据集每一行形式是years NOUN NNS,是句子中单词及其两种词性标注
# 训练集12543,验证集2002,测试集2077,形式如下图:
train_data, valid_data, test_data = datasets.UDPOS.splits(fields)
# 出现频率两次才放入vocab(否则看作unknown)
MIN_FREQ = 2
TEXT.build_vocab(train_data,
min_freq=MIN_FREQ,
vectors="glove.6B.100d",
unk_init=torch.Tensor.normal_)
UD_TAGS.build_vocab(train_data)
charades_data = Charades_Text('./charades/charades_sta_train.txt', TEXT)
charades_dataloader = DataLoader(charades_data, batch_size=128, collate_fn=text_process)
device = torch.device('cuda:5' if torch.cuda.is_available() else 'cpu')
INPUT_DIM = len(TEXT.vocab) # 8866
EMBEDDING_DIM = 100
HIDDEN_DIM = 128
OUTPUT_DIM = len(UD_TAGS.vocab) # 18
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.25
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] # 1
model = BiLSTMPOSTagger(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)
model.load_state_dict(torch.load('tut1-model.pt'))
model.eval()
for batch in charades_dataloader:
predictions = model(batch)
# 获得预测结果
top_predictions = predictions.argmax(-1)
# 转化为可视化的tag
top_predictions = top_predictions.view(-1)
predicted_tags = [UD_TAGS.vocab.itos[t.item()] for t in top_predictions]
还需要解决的问题是:1)重新构造vocab(现在的vocab,unknown太多了) 2)可视化预测的tag与原单词的对应(因为没有标签,不能直接计算准确率)3)nn.Embedding是怎么训练的呢?
此阶段总结
输入:句子
输出:len(tag)维度的predictions向量/直接的prediction
未来改进
- 使用准确率更高的模型,参考PoS leader board
- 修改nn.Embedding,修改为300d的向量(vmr中的常用方式)