超越自注意力!清华提出EA和EAMLP:使用两个线性层的新注意力机制
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:国孟昊 | 已授权转载(源:知乎)
https://zhuanlan.zhihu.com/p/376929247
本文是对最近我们更新到 arxiv 的 paper :Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks (External attention) 的解读论文,也分享一下在做这篇论文时候的实验过程中一些问题和想法。

论文 :https://arxiv.org/abs/2105.02358
代码:https://github.com/MenghaoGuo/-EANet
本次更新主要包含了三个方面:
加入了 multi-head external attention 机制,multi-head external attention 也可以使用两个线性层实现,由于有了 multi-head external attention 结构,我们实现了一个 MLP 结构,我们把它叫做 EAMLP。
补充了一个 ablation study 的实验以及一些分析,可以更清楚的理解这种 external attention 机制。
补充了 COCO 上的 object detection 和 instance segmentation 的实验和 Tiny ImageNet 上的生成实验。现在已经在图像分类、检测、分割、实例分割、图像生成、点云的分割和分割上证明了 external attention 的有效性。
先从 self-attention 说起
自注意力机制,通过计算两两之间的相似度,然后更新根据相似度更新特征,达到特征增强的作用。具体的,对于输入特征 ,QKV 是 F 的一种线性变换,自注意力可以写成如下的形式。
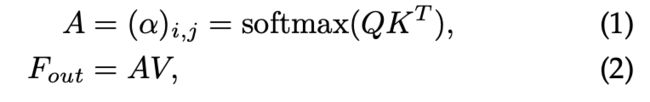
为了表达简单,我们把 self-attention 可以简记为下面公式(3) 和 公式(4) 所示,

External attention
对于(3)(4)中这种简记的注意力机制,我们可以认为这是 F 对 F 的注意力,也就是 self-attention。这种注意力是非常有效的,但是也有它的不足。首先,它使用的是一个 F 对 F 的注意力形式,这种注意力只会考虑单个样本内部的关联,而会忽略样本之间的潜在联系,这种联系对于视觉任务来说是有用的,比如对于语义分割这个任务来说,我们希望分布在不同样本中的同类物体能有着相似的表征。其次,由于是算 F 对 F 的注意力,它不够灵活,这种不灵活带来的是 级别的复杂度,难以用到高分辨率图像场景。
下面考虑这样一个问题,如果有一个共享的矩阵 , M 是随机初始化的,我们可以把上面那个形式,记成一种 M 对 F的注意力,即如下公式(5)(6)所示。

对于上述形式,首先,M 是共享的,所以可以隐式的考虑不同样本之间的关联,其次,由于 S 是非常灵活的,我们可以通过控制 S 的大小,来使得整个 external attention 变得灵活,使得 attention 变成 N 复杂度,以便用于高分辨率的情况。
对于 self-attention, 简化的 self-attention 以及这个 M 对 F的 attention (external attention),可以用下图来表示。
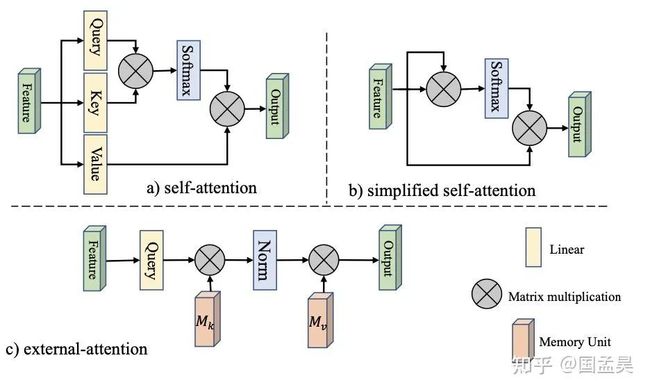
External attention 和 线性层
进一步考虑公式 (5)(6),可以发现,公式(5)(6) 中的 是什么呢 ?是矩阵乘法,也就是是我们常用的线性层 (Linear Layer)。这就是解释了为什么说线性可以写成是一种注意力机制。写成代码就是下面这几行, 就是线性层。

Multi-head external attention
到这里,我们已经把 attention 写成了 Attention = Linear(Norm(Linear(F))) 的形式,不妨把该式子记为 Attention=G(F) 。考虑多层 attention 的堆叠,也就是现在常用的 Transformer。那么就是 Transformer = G(G’.....G(x)) 。没错,是可以这么做,我们也做了实验,在 ImageNet 仅获得了 63.2 的准确率(对标同级别的 transformer 71.7),我们反思了一下,到底是哪出了问题,发现 multi-head 机制在这里面起到了关键的作用。我们吧 multi-head self-attention 改成 single head 之后发现了其性能也只能达到 67.4,直接降低了 4.3 个点。有了这个 insight 之后,我们设计了我们的 multi-head external attention。如下所示:
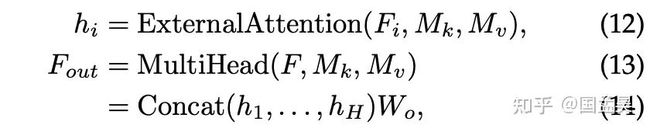
和 self-attention 的 multi-head 不同,我们的 multi-head 的每个 head 是共享 的,multi-head self-attention 每个 head 是独立的。这个multi-head external attention 也可以写成线性层,具体写法如下:

Normalization
在通常的 attention 中,我们常常只使用一个 softmax 作为中间的归一化层,这种归一化的目的是使得 attention map 中的某一行或者某一列和为1。这种只用 softmax 有什么问题呢 ?问题在于,当某一个特征值特别大(特别小)的时候,他对其他特征的点乘也会变得特别大(特别小),这种情况下,只使用 softmax 会破坏 attention 原始的含义。我们使用了 softmax + L1 norm 的这种 double normalization 的方式,去避免这个问题,公式如下:

值得注意的是,external attention 非常依赖这种 double norm 的方式,这种 norm 也对self-attention 有提升作用,实验结果如下:
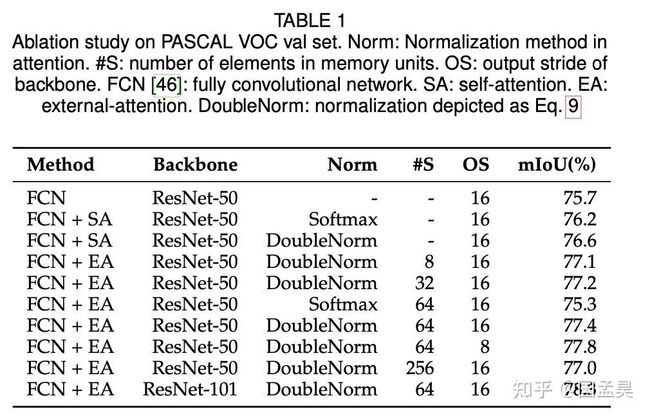
这种 double norm 的方式在 ImageNet 上面也会让 T2T-VIT 有 0.1 - 0.3 个百分点的提升。
实验中的一些感想
我们在 ImageNet 上做了一个纯 MLP 的结构,我们叫它 EAMLP,实验结果如下:

同时我们可视化了最后一层 external attention 的 attention map,如下所示:
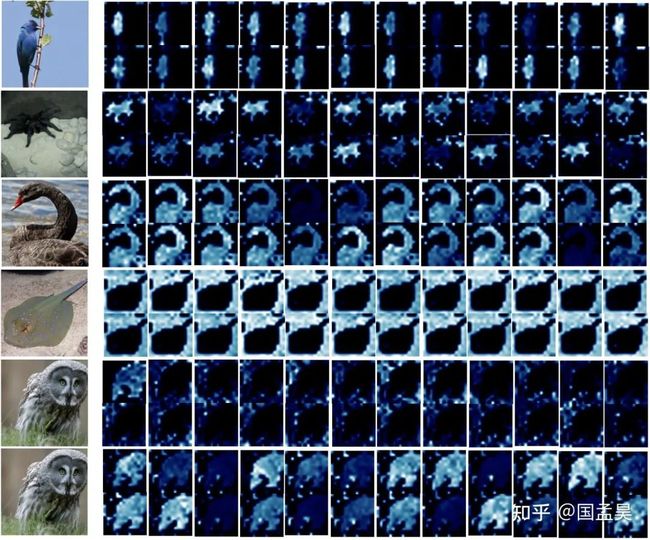
关于这个实验,说几点感想
我们采用了 MoCo V3 中的将 LayerNorm 换成 BatchNorm 的尝试,也在 EAMLP-7 上取得了 1.1 个点的提升,但是在大模型上梯度会崩掉。这个实验让我感觉,在视觉里面,Transformer 中的 LayerNorm 在视觉中可能不如 BatchNorm 好,这可能是 Norm 本身造成的,也有可能是优化器不适合造成。
multi-head 这种结构是重要的,之前也看过一些轻量级结构,比如 EMANet, HamNet、OCRNet、CCNet、ANN...这些结构如果设计一个合理的multi-head 结构应该也可能用到 transformer 里面代替 self-attention。
另外,值得注意的是,softmax 不一定就是最合适的归一化方式。当然 double norm 也极大可能不是最合适的归一化方式。external attention 非常依赖这种 double norm 的方式,这种 norm 也对self-attention 有提升作用。attention 里面的归一化方式应该是一个非常值得探索的 topic。
另外,简单写了一些我们对最近的 MLP 的一些观点和一些未来可能的方向,一个 4 页纸的short paper :Can Attention Enable MLPs To Catch Up With CNNs?
上述论文和代码下载
后台回复:EAMLP,即可下载上述论文和代码
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看