FlowFusion: Dynamic Dense RGB-D SLAM Based on Optical Flow 论文阅读笔记
FlowFusion: Dynamic Dense RGB-D SLAM Based on Optical Flow 论文阅读笔记
ICRA2020
摘要
直接法动态SLAM,创新之处是利用光流残差来突出RGBD点云中的动态语义,为相机跟踪和背景重建提供更准确和高效的动态/静态分割。
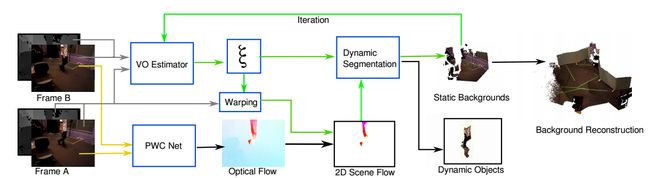
图1是提出的FlowFusion的工作框架,输入连续两帧RGB-D帧A和B,RGB图像输入PWC网络来获取光流估计,同时强度-深度图像对输入相机运动估计(前端里程计),获取相机初始位姿ξ(Section III-A具体介绍),然后根据位姿ξ 投影图像A到A‘,获得投影的2D场景流((Section III-B具体介绍)),用场景流来进行动态分割,在几次迭代之后(Section III-C,具体介绍)静态场景被重建。
III基于光流的联合动态分割与密集融合
我们的方法以两个RGB-D帧A和B作为输入,RGB图像被送入PWC来估计光流(黄色箭头)。
同时,A和B的强度和深度对被馈送到稳健的摄像机自我运动估计器以估计初始摄像机运动ξ(在第III-A节中介绍)。然后,我们使用ξ将帧A扭曲到A‘,并获得用于动态分割的投影2D场景流(在第III-B节中)。
经过多次迭代(第III-C节,绿色箭头),获得了静态背景,为后续的环境重建做好准备。由于该方法将光流残差应用于动态分割,因此我们将其命名为FlowFusion(FF)。
A. 稠密RGB-D Fusion(融合/滤波)方式的视觉里程计
VO前端被表述为色彩(光度)和深度(几何)对齐误差的优化问题。
强度图像I,深度图像D
通过针孔相机模型,可以从(IA,DA)中生成三维点云数据(PCD)。
我们首先根据超体素聚类[16],将图像A的三维点云PCD分割成N个聚类V,得到邻接图G {聚类V,误差Ei j}
(类似于JF [Fast odometry and scene flow from rgb-d cameras based on geometric clustering]和StaticFusion(SF),为了提高聚类效率,我们使用强度距离代替RGB距离)
每一个聚类视作一个刚体,定义ξ∈Se(3)为初始位姿估计。
假设机器人一开始在一个静态环境中移动,ξ可以根据光度和深度残差的能量函数中求解:

其中,αI是一个尺度因子来确定强度项和深度相比较的系数,wD和wI分别是深度和强度想根据测量误差得到的预权重,光度残差r可计算为:
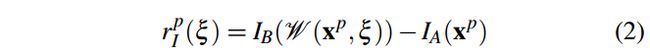
IA和IB是连续帧,这个应该就是直接法的光度误差公式
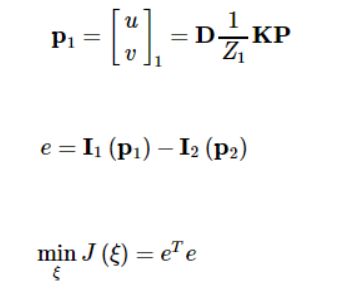
由深度测量得到几何残差rD:

变换用T(ξ ) ∈ SE(3)表示,其中,ξ ∈ se(3), 由A到B的旋转和平移组成(也就是欧式变换),除此之外W表示图像扭曲操作:
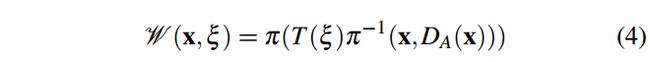
其中,xp表示像素p对应的2D图像坐标,|·|D 表示对应点的深度值,用π 表示从世界坐标系把点投影到相机平面,用T(ξ )表示外参矩阵

图2 在图像平面中投影的二维场景流。
- xp是一个目标点在帧A中的投影像素点,xq是同一个3D点在帧B中的投影点
- 红色的箭头是场景流,蓝色箭头是光流,绿色箭头是场景流xf在相机平面的2D投影,黄色箭头是由相机自我运动产生的自我流xe
最后,C®函数是一个鲁棒惩罚函数,以平衡优化计算的鲁棒性和收敛性。
对于RGB-D视觉里程计,指[7],[8],通常采用柯西鲁棒惩罚,因为它比L1/L2规范更鲁棒:
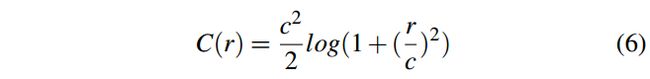
深度和强度残差对于基于环境刚性运动假设的VO估计有很大影响。为了处理动态物体,我们定义了直接表示非刚性环境运动的光流残差。
B. 基于场景流投影的光流残差估计
理论上我们可以通过位姿ξ 来区分一个聚类是动态还是静态的,当(IA,DA)被ξ值扭曲时,我们计算每个簇的平均残差。
真实背景不移动,其像素簇随摄像机运动ξ值而移动,因此残差较低。随着动态物体运动的动态簇应包含较高的残差,因为它们的运动与摄像机运动ξ值不一致。
因此,可以通过设置高低rI、rD残差阈值来提取动态聚类。然而,在实际情况下,强度和深度残差并不是很好的度量标准,原因如下:
- 深度和强度图像是由不同的镜头获得的,由于时间延迟的原因,它们无法完美地配准。(这一点没太明白,在RGB-D运行之前的对准工作不是将深度图像和RGB对齐了吗,是说只能近似对齐吗)
- 深度测量在边界区域是离散的,这导致了错误的对齐
- 深度测量误差随测量范围的增大而增大。
为了解决这些问题,我们需要找到一个能直接表示像素或点云动态水平的概念。
场景流法是估计运动的3D点,但不能直接得到(如在JF中,场景流是经过多次VO估计迭代得到的)。另一方面,从图像对中容易获得的光流常被用于描述静态摄像机捕捉到的运动物体。因此,受[14]启发,为了摆脱相机的自我运动,我们引入了光流残差的概念,它被定义为投影的二维场景流,以突出像素的动态特性。
具体来说,估计时间t到t +1之间的光流:
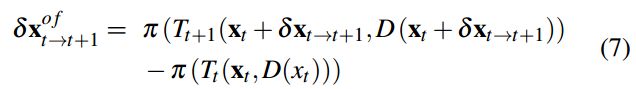
光流定义为像素在图像坐标上的运动,如图3 (b)所示,其中颜色表示流动方向,强度表示像素位移。在(a)的真实场景中,机器人向左移动,人类向右移动。
因此,蓝色的流动是由相机自我运动的结果。我们将这种流定义为相机自运动流
这意味着观测到的光流纯粹是由相机运动(不运动物体)产生的。如果我们从光流中减去自我流,可以得到像平面上的场景流分量,如©和(d)所示。
对于帧A的一个二维像素x,给定摄像机运动ξ∈se(3),则摄像机自运动流可计算为:

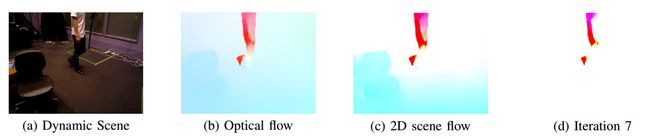
图三 迭代估计动态场景中的二维场景流。(a)为机器人向左移动,人类向右移动的场景。(b)是由(a)的图像对估计的光流,颜色表示流方向,强度表示像素位移。蓝色的流动是由相机自我运动造成的。我们从光流中减去自我流,得到像平面上的场景流分量,如图©所示。迭代去除(b)中的场景流和自我流,经过7次迭代,可以得到(d)更好的2D场景流结果。
在像面上投影的场景流可计算为:
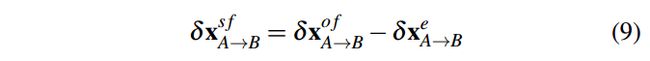
对于静态像素,式9接近于零,因为它的光流来自于相机的运动。对于动态像素,二维场景流是非零的,其绝对值随移动速度的增大而增大。
本文采用GPU加速密集光流估计方法PWC-net代替了公式7
C. 动态聚类分割
到目前为止,我们已经使用VO得到的ξ值投影了帧A,我们已经定义了三个残差,分别是相对于强度、深度和光流的rI、rD和rF。
们提出了根据平均残差来区分一个聚类是否静态的方法。这将通过两个步骤来完成。
首先,我们计算一个度量来组合这三个残差,其次,我们构造一个最小化函数来限定聚类的动态水平
为了结合残差,定义聚类i的平均残差δi为:

其中Si表示聚类大小,Di表示聚类的平均深度,αF和αI控制场景流和强度权重,对每一个聚类,我们计算他的动态等级bj∈ [0,1],bi=0意味着聚类i被设为静态分割
然后我们得到聚类b的能量函数:

其中,Eδ(b)为bi与阈值的关系。设上下平均残差分别为θt,θb,则,

关于赋值函数:

为增加高残差部分的贡献,权值wδ定义为:
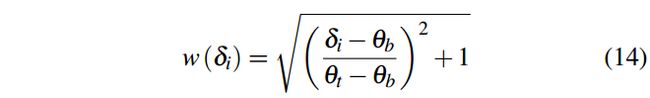
参考SF《static fusion》为了提高相邻集群的连通性,并将相似的集群推到相同的动态/静态段,我们形成EG:

EG(b)是凸的,因为它是用所有平方项设计的。得到b后,对式1进行修改,考虑动静分割:
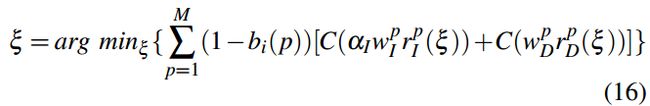
其中bi§为包含像素x p的聚类I的动态评分。M是静态像素的大小。我们可以用[18],[17]提供的迭代重加权最小二乘求解器解出这个方程16和解出的b。
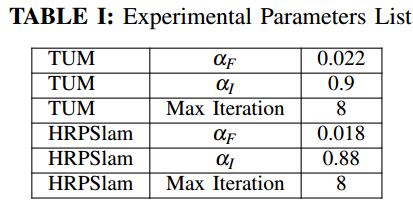
其中一些参数的取值
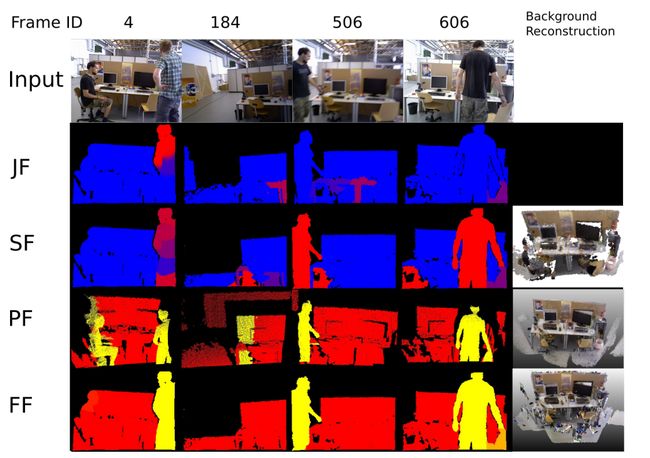
图四 比较了JF、SF、PF和FF方法的动态分割性能。蓝色部分在JF和SF中是静态的。红色部分在PF和FF是静态的。第一行为输入RGB帧,其余行为各方法的动态/静态分割结果,最后一列为背景重构结果(JF除外,它不提供重构功能)。