DIDL笔记(pytorch版)(八)
文章目录
- 前言
- NiN
- GoogLeNet
前言
LeNet、AlexNet和VGG都是不断的加深模型的层数,看网络结构可以看出后者有前者的影子,并且都是一系列卷积+最后全连接的操作。
NiN却是网络串联网络,并且NiN最后的分类方法也很不同。
NiN
之前的网络都是卷积提取特征之后带全连接做分类。NiN提供另一个思路,卷积层和全连接层交替。因为全连接层的输入输出要是二维,卷积通常是四维,为了方便全连接层使用1 × \times × 1 卷积代替。原理之前解释过。
贡献:
- 空间信息有效的传递到后层。
- 最后分类采用输出通道数等于标签类别数的NiN块,再加上全局平均池化来分类。可以显著减少模型参数尺寸,缓解过拟合。
import torch
from torch import nn
import torch.nn.functional as F
import d2l as d2l
def nin_block(in_channels, out_channels, kernel_size, stride, padding):
blk = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU())
return blk
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, stride=4, padding=0),
nn.MaxPool2d(kernel_size=3, stride=2),
nin_block(96, 256, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nin_block(256, 384, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, stride=1, padding=1),
d2l.GlobalAvgPool2d(), # 全局平均池化
# 将四维的输出转成二维的输出,其形状为(批量大小, 10)
d2l.FlattenLayer()
)
GoogLeNet
改进很大,除了吸收了NiN的串联网路的思想,设置的基础模块也更加复杂。它认为之前加深层数会导致参数太多、计算复杂难以应用、出现梯度消失的问题。要解决这个问题不得不引入稀疏性并且把全连接变为稀疏连接。
引入稀疏性可以从下面两个方面着手:
- 卷积的稀疏性
传统的神经网络是全连接的,后面每一层的单元都与它之前层的输入单元之间存在权重连接,而在卷积运算中,卷积核的尺寸是远小于输入图像的大小,一个神经元只受少数输入单元的影响,可以理解成有些输入单元的权重连接为0,不同于密集的全连接,称之为稀疏性。 - 特征维度的稀疏
使用多分支多个尺寸卷积核对图像进行卷积,每个尺寸卷积核(分支)提取出对应的高相关性特征,而每个分支得到的结果在通道维度上进行拼接,这就相当于把各个分支提取出的高相关性特征在通道维度上进行了聚合,这样一来作者就真正实现了使用稠密运算来近似稀疏连接的目的。
Inception模块
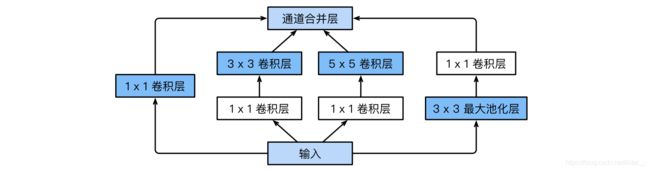
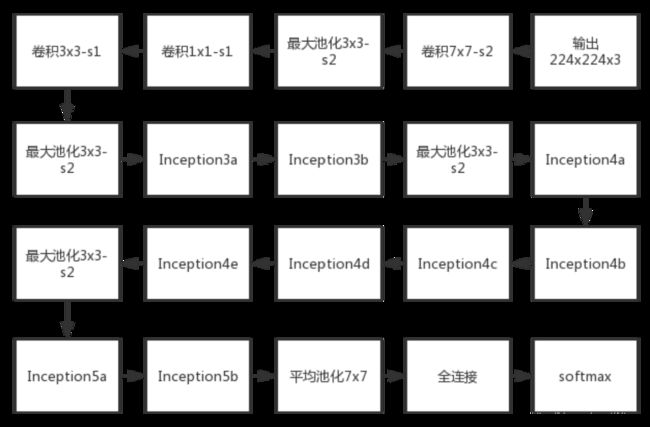
参考:https://blog.csdn.net/weixin_43624538/article/details/84863685
https://blog.csdn.net/weixin_30888027/article/details/97739699
https://www.cnblogs.com/leebxo/p/10315490.html
import torch
from torch import nn
import torch.nn.functional as F
import d2l as d2l
class Inception(nn.Module):
# c1 - c4为每条线路里的层的输出通道数
def __init__(self, in_c, c1, c2, c3, c4):
super(Inception, self).__init__()
# 线路1,单1 x 1卷积层
self.p1_1 = nn.Conv2d(in_c, c1, kernel_size=1)
# 线路2,1 x 1卷积层后接3 x 3卷积层
self.p2_1 = nn.Conv2d(in_c, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1 x 1卷积层后接5 x 5卷积层
self.p3_1 = nn.Conv2d(in_c, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3 x 3最大池化层后接1 x 1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_c, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
return torch.cat((p1, p2, p3, p4), dim=1) # 在通道维上连结输出
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
d2l.GlobalAvgPool2d())
net = nn.Sequential(b1, b2, b3, b4, b5,
d2l.FlattenLayer(), nn.Linear(1024, 10))