文字检测算法——PSENet阅读笔记
多种文本检测算法性能对比及算法介绍
(https://blog.csdn.net/qq_39707285/article/details/108754444)
Shape Robust Text Detection with Progressive Scale Expansion Network
- 0. 论文摘要
-
- 0.1 目前文字检测存在的挑战
- 0.2 本文解决办法
- 1. Introduction
- 2. 文本检测算法回顾
-
- 2.1 基于Regression的算法
- 2.2 基于Segmentation的算法
- 3. 提出的算法
-
- 3.1 算法综述
- 3.2 网络设计
- 3.3 渐进尺度扩展算法
- 3.4 标签的生成
- 3.5 损失函数
- 4. 实验
-
- 4.1 数据集
- 4.2 实验细节
- 4.3 分块分析
- 4.4 实验结果
- 4.5 速度分析
- 5. 结论和展望
0. 论文摘要
0.1 目前文字检测存在的挑战
- 大多数最先进的算法都需要精确的四边形bounding box来定位任意形状的文本,而不能检测curve文本,如Fig. 1(b)
- 对于两个比较接近的文本行可能会导致一个错误的检测,检测结果会覆盖两个实例,如Fig. 1(c)

0.2 本文解决办法
- 基于分割的方法可以解决第一个问题,但通常不能解决第二个问题。
- 提出了一种新的渐进扩展网络(Progressive Scale Expansion Network,PSENet),它可以精确地检测任意形状的文本实例。
1. Introduction
目前的文字检测算法可以简单的分为两大类: regression-based approaches(基于回归的方法) and segmentation-based approaches(基于分割的方法)。基于回归的方法不能解决曲形文本,基于分割的方法可以解决曲形文本,但是对于距离较近的文本行往往会检测出错(如上图c)。
本文提出的PSENet可以解决这些问题,PSENet有两大优点,第一,属于分隔的算法,用时可以处理任意形状的文本;第二,提出了一张渐进尺度扩展算法,对于临近的文本行可以成功的分离开,如上图d。
对于每个文本实例,用不同的分割区域进行预测,我们把这些分割区域成为"核",每个文本实例的核与原始文本形状类似,但尺寸不同,用Breadth-First-Search (BFS)的方法生成不同的分割target,BFS算法简介,1)最开始的核用最小的尺寸,文本实例在这一步就可以被检测出来;2)通过在更大的内核中包含更多的像素来扩展它们的区域;3)直到完整的文本实例(最大的内核)被找到。
2. 文本检测算法回顾
场景文本检测算法总体可分为两类:基于回归的方法和基于分割的方法。
2.1 基于Regression的算法
基于回归的方法经常使用目标检测的框架,例如Faster R-CNN
和SSD等,下面介绍一下其他基于回归的算法:
- TextBoxes 修改了anchor的比例和卷积核,来适应任意比例的文本。
- EAST 使用FCN去直接预测每一个像素的score、旋转角度和bbox。
- RRPN 采用 Faster R-CNN,设计了旋转的RPN,可以直接检测任意旋转的文本。
- RRD 从两个独立的分支中提取用于文本分类和回归的特征映射,以更好地进行长文本检测。
以上几种算法的缺点:
- 需要设计复杂的anchor,需要繁琐的多个阶段来完成
- 耗时,性能不佳
- 不能处理曲形文本
2.2 基于Segmentation的算法
基于分割的算法主要受FCN的启发。
- PixelLink 通过预测不同文本实例之间的像素连接,分离出彼此相近的文本
- TextSnake 使用规则的圆盘去表示用于曲线文本检测的曲线文本
- SPCNet 使用实例分割框架,利用上下文信息检测任意形状的文本,同时抑制假阳性
以上的这些方法在横向和任意方向的文本检测上都取得了不错的效果,但是这些算法除了TextSnake之外,没能够解决曲形文本。而TextSnake需要在算法预测之前进行非常耗时的预处理操作,本文的算法仅仅需要一步高效的操作。
3. 提出的算法
这一部分首先综述算法Progressive Scale Expansion Network
(PSENet),然后详细的展开来讲该算法如何高效的定位文本,接着介绍如何生成label,最后介绍loss函数的设计。
3.1 算法综述
整体的网络结构如下图所示。

PSENet使用ResNet作为backbone,整个网络结合低层的纹理特征和高层的语义特征,各个特征图最后一起融合成F,从直觉上看,融合之后的特征图能够检测不同尺度的文本。然后特征图F分为n个分支,每个分支产生不同的分割结果S1,S2,…Sn,每一个Si代表一个实例的不同尺度的mask,生成这些mask由超参数决定,这部分后面讲。S1是文本实例分割的最小尺度,Sn代表真实的标注结果。使用 progressive scale expansion algorithm不断的扩大S1到Sn,直到最终的结果R。
3.2 网络设计
PSENet的基础框架由FPN构成,首先从backbone中得到256通道的不同的特征图中(例如P2,P3,P4,P5),然后通过函数 C(·)融合成1024通道的特征图F,融合函数如下所示,其中“||”代表连接,Up ×2 (·)代表2倍上采样。之后F经过 Conv(3,3)-BN-ReLU降维到256,最后经过n个 Conv(1,1)-Up-Sigmoid生成n个分割结果S1,…Sn
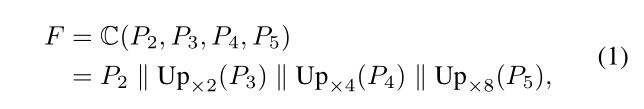
3.3 渐进尺度扩展算法
对于一般的分割算法很难区分相近的文本,如Fig. 1(c)所示,为了解决这个问题,提出了 渐进尺度扩展算法(progressive scale expansion algorithm),如图4所示,解释了整体的算法流程。

算法的中心思想来源于Breadth-First-Search (BFS),在图示的例子中,选用3个分割结果S = {S1 ,S2 ,S3 }, S 1 S_1 S1代表最小的kernel map,从 S 1 S_1 S1中可以很明显的看到四个联通组件,(b)中四个不同的颜色代表四个不同的文本组件,到这一步,就已经得到了所有文本的最小面积区域,然后,通过合并 S 2 S_2 S2中的像素逐渐的扩大这个kernel ,然后利用 S 3 S_3 S3继续扩大,两次扩充的结果如图©和(d)所示,最后提取不同颜色的区域,就得到了最终的文本区域。
图4(g)中说明了kernel 是如何扩展的,从多个kernel的像素开始,迭代地合并相邻的文本像素,合并时有可能会出现冲突,如图中(g)红色方框,处理这种有争论的像素,就是利用先到先得原则。由于渐进扩展处理,这些边界冲突不会影响最终的检测和性能,在算法1中总结了尺度扩展算法的详细内容。

T T T和 P P P是中间结果, Q Q Q是一个队列,Neighbor(·)代表 p p p的4个相邻像素,GroupByLabel(·)是按标签分组中间结果, “Si[q] = True”意味着像素 q q q的预测值在 S i S_i Si中属于文本部分, C C C和 E E E分别保存膨化前后的kernels。
3.4 标签的生成
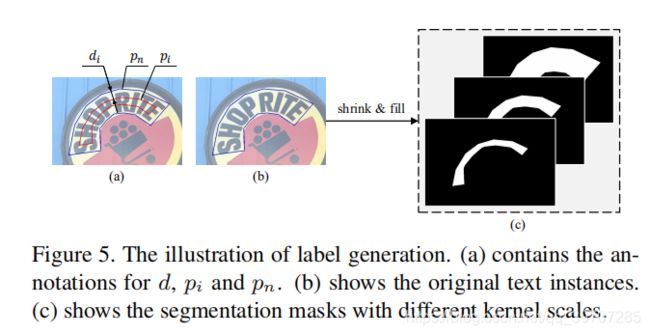
从图3的网络结构就能看出,网络输出多个分割结果( S 1 S_1 S1, S 2 S_2 S2,…, S n S_n Sn),因此训练时就需要有多个GT与其匹配,在本文中,通过收缩原始标签就可以简单高效的生成不同尺度的GT,如图5所示,(b)代表原始的标注结果,也表示最大的分割标签mask,即 S n S_n Sn,利用Vatti裁剪算法获取其他尺度的mask,如图5(a),将原始多边形pn缩小di像素得到pi,收缩后的 p i p_i pi转换成0/1的二值mask作为GT,用G1,G2,…Gn分别代表不同收缩尺度的GT,用数学方式表示的话,尺度比例为 r i r_i ri,距离 p n p_n pn和 p i p_i pi之间的距离 d i d_i di的计算方式为:

Area(·) 是计算多边形面积的函数, Perimeter(·)是计算多边形周长的函数,生成 G i G_i Gi时的尺度比例 r i r_i ri计算公式为:
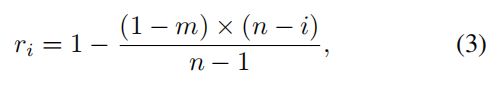
m代表最小的尺度比例,取值范围是(0,1],使用公式(3),通过m和n两个超参数可以计算出r1,r2,…rn,他们随着m变现线性增加到最大值1.
3.5 损失函数
PSENet的损失函数定义为:

L c L_c Lc表示完整文本的loss, L s L_s Ls代表收缩的文本loss, γ \gamma γ 用来平衡这两个loss。
当时用二值交叉熵时,对于那些极其小的文本,网络对非文本区域的预测有偏差,所以本文采用,dice coefficient,计算方式如下所示,

S i , x , y S_{i,x,y} Si,x,y和 G i , x , y G_{i,x,y} Gi,x,y分别表示像素 ( x , y ) (x,y) (x,y)在分割结果 S i S_i Si和GT G i , G_i, Gi,中的值。
有许多与文字笔划相似的图案,如栅栏、格子等,所以对于 L c L_c Lc采用Online Hard Example Mining (OHEM)。 L c L_c Lc关注的是文本区域和非文本区域的分割,把OHEM给出的训练mask看作是M,则 L c L_c Lc的计算方式为:

L s L_s Ls是收缩文本实例的loss,由于它们被完整文本实例的原始区域包围,因此为避免一定的冗余,忽略分割结果 S n S_n Sn中非文本区域的像素,,则 L s L_s Ls的计算方式为:
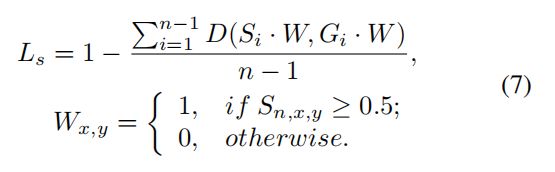
W W W是一个掩码,表示忽略 S n S_n Sn中非文本区域的像素, S n , x , y S_{n,x,y} Sn,x,y表示 S n S_n Sn中像素 ( x , y ) (x,y) (x,y)的值。
4. 实验
4.1 数据集
- CTW1500
- Total-Text
- ICDAR-2015
- ICDAR-2017 MLT
4.2 实验细节
使用ResNet50作为backbone,在ImageNet进行预训练,优化器选择SGD,使用7200张IC17-MLT训练集和1800张IC17-MLT验证集去训练模型,然后在IC17-MLT上进行测试。batchsize为16,在4块GPU上迭代共180K次,初始学习率为10e-3,在第10K个第120K次迭代时,学习率除以10.
在其他数据集上有两种训练策略:
- 从头开始训练,bs为16,4gpu,迭代36K次,初始学习率10e-3,分别在12K和24K迭代时除以10
- 在IC17-MLT进行微调,共迭代24K次,初始学习率为10e-4,在12K次迭代时除以10
数据增强:
- 随机rescale,比例为(0.5,1.0,2.0,3.0)
- 图片水平方向随机翻转,随机旋转角度[-10°-10°]
- 随机裁剪到640×640
4.3 分块分析
-
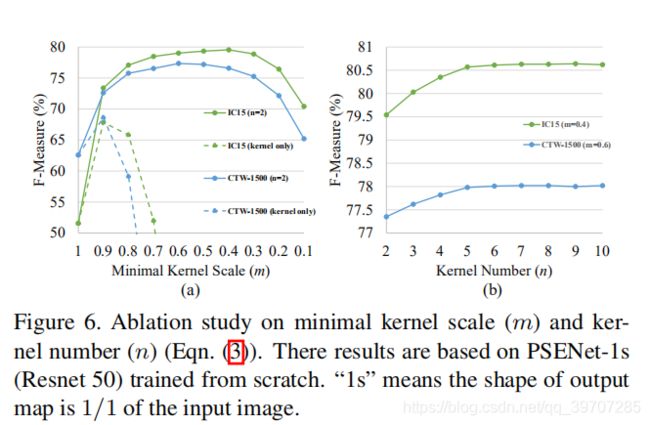
kernels可以用来作为最终的结果吗?
kernels的作用是用来粗略的定位文本区域,例如,最小的kernel不能够覆盖整个文本区域,这对检测和识别都是不利的,如图6中所示,只使用最小kernel(虚线部分)在ICDAR2015和CTW1500数据集上表现很糟糕,另外,外接CRNN,识别结果如图2所示,结果不好,所以kernel不能直接作为最后的检测结果。

-
最小kernel尺度的影响
设置超参数n为2,让最小尺度m从1减小到0.1,在数据集ICDAR2015和CTW1500上的测试结果如图6(a)所示,当m值为1时,没有使用渐进尺度扩展算法,这就导致相邻较近的文本区域相连的情况,很明显,没有使用PSE的表现很差,当m很大时,很难区分相近的文本,当m很小时,PSENet会吧一个整体的文本划分成多个不同部分,而且训练不能够很好的收敛。 -
kernel数量的影响
实验中保持最小尺度m,使用不同的n值,在ICDAR2015中m设置为0.4,CTW1500中m设置为0.6,n值从2到10,结果如图6(b)所示,从图中可以看到,随着n值增加F会变大,当n>=5时,F值几乎不变。多kernel的优点是,对于两个文本之间的距离很大的,它可以精确地重建两个文本实例。 -
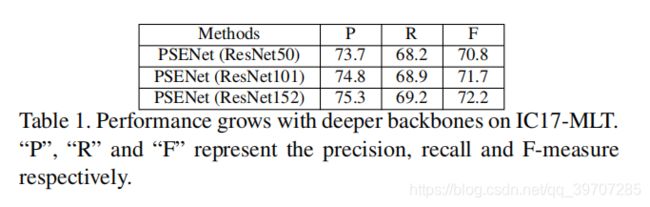
backbone的影响
分别使用ResNet{50,101,152},在IC17-MLT进行测试,结果图表1所示:backbone从52层到152层,性能从70.8%提升到72.2%
4.4 实验结果
-
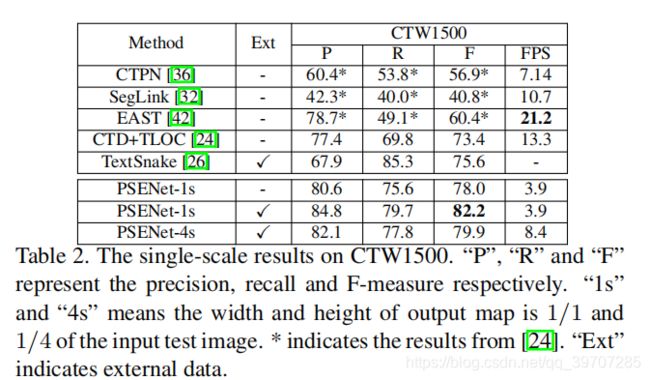
在CTW1500上的结果
-
在Total-Text上的结果

-
在IC15上的结果

-
在IC17-MLT上的结果

4.5 速度分析

5. 结论和展望
提出了一种新的**渐进尺度扩展网络(PSENet)**来检测自然场景图像中任意形状的文本实例,通过多次语义分割,将检测区域从小核逐步扩展到大而完整的实例地图,该方法是鲁棒的,可以很容易地分离那些非常接近甚至部分相交的文本实例,在场景文本检测基准上的实验结果表明了该方法的优越性。
未来有多个方向可以探索。首先,将研究扩展算法是否可以与网络端到端一起训练;其次,渐进尺度扩展算法可以应用于一般的实例级分割任务,尤其是在那些有很多拥挤的对象实例的基准测试中。