服务器开发系列(二)——Jetson Xavier NX
系列文章目录
服务器开发系列(一)——计算机硬件
文章目录
- 系列文章目录
-
- 服务器开发系列(一)——计算机硬件
- 前言
- 一、硬件情况
- 二、操作系统安装
- 三、操作系统的备份与恢复
- 四、预装软件工具
-
- 1. CUDA简介
- 2. DeepStream简介
- 3. TensorRT简介
- 五、常用Linux命令
- 六、常用apt命令
- 七、Jetson Xavier NX常用功能
-
- 1. 硬件性能调整
- 2. 查看关键软件版本信息
- 3. 安装中文输入法
- 4. 安装QQ
- 八、深度学习功能
- 总结
- 参考资料
前言
要想搞服务器开发总得现有硬件,由于手头并没有合适的Linux主机,因此从本博文开始,后续博文中Linux系统部分,都是在NVIDIA的Jetson Xavier NX开发板上进行研究测试的。这里先对该开发板进行介绍。
一、硬件情况
NVIDIA迄今为止共推出4款嵌入式计算平台,每款Jetson平台所提供的性能可提高自主机器软件的运行速度,而且功耗更低,每个系统都是一个完备的模块化系统SOM,具备CPU、GPU、电源管理集成芯片PMIC、动态随机存储器DRAM和闪存,还具备可扩展性。用户只需选择适合应用场景的SOM,即能够以此为基础构建自定义系统,满足特定的应用需求。截止目前共推出4款产品,其中Jetson Xavier NX是配置最高的。
Jetson平台使用的是NVIDIA推出的Tegra处理器,这款处理器是采用单片机系统设计的SoC芯片,集成了Arm架构处理器和NVIDIA的Geforce GPU,可以面向便携式设备提供高性能、低功耗体验。在Tegra芯片上运行的是Linux内核,采用U-Boot(Universal Boot Loader)实现系统引导,平台采用JetPack Ubuntu桌面系统,最新版本的JetPack已经集成了Ubuntu 18.04,还集成了BusyBox,包括300多个最常用的Linux命令和工具软件,并且结合相关硬件外设重新编译内核,被称为Linux4Tegra(简称L4T)。Ubuntu系统在2018年被评为“最好的嵌入式发行版”和“最好的服务器发行版”,目前该发行版最新稳定版本是Ubuntu 18.04.2 LTS。使用JetPack安装程序可以刷写Jetson平台,刷写成功后Jetson平台不但预装了L4T系统,而且安装了启动开发环境所需的库、API、样例和文档。
Jetson Xavier作为NVIDIA ISAAC平台的核心,是全球首款专为机器人设计的智能芯片。它有6个处理器,包括1个Volta Tensor Core GPU(512个CUDA核心,64个Tensor核心)、1个6核心Arm CPU(v8.2 x64)、2个NVDLA深度学习加速器、1个图像处理器和1个视频处理器,16GB 256位LPDDR4内存,32GB eMMC固态硬盘。其每秒可执行30万亿次操作,处理能力与配备了10万美元GPU的工作站大致相当,但功耗仅为30W。
二、操作系统安装
Jetson Xavier NX刷机安装的系统是Ubuntu 18.04,其固态硬盘版硬件的刷机过程如下:
①需要有一台安装了Ubuntu系统的主机来辅助刷机,Windows系统安装虚拟机(Linux系统的可跳过这一步)
注意:以下安装步骤均需在Ubuntu系统下进行!
②安装SDKmanager
<1>如果是Windows系统则登录虚拟机并加载Ubuntu系统。下载SDKmanager,https://developer.nvidia.com/zh-cn/embedded/jetpack。
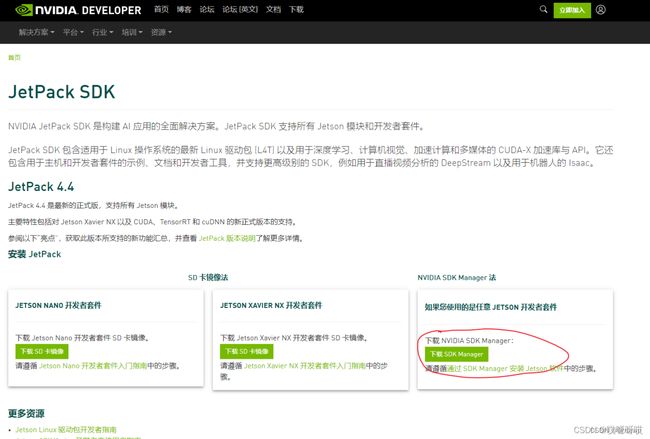
<2>之后需要注册一个开发者账号(有账号的小伙伴自动忽略这一步,直接登录)。
<3>之后就可以进行下载,等待下载完成:
你也可以在Windows系统下下载好SDKmanager,再拷入到虚拟机下进行安装。
下载好之后不用解压,在文件所在路径打开终端,进行安装。安装命令:sudo apt install ./SDK包的文件名
③进行NX系统烧录
首先将NX背面的SSD固态硬盘拆掉,将NX的FC REC引脚和GND引脚短接(第二个和第三个引脚)让NX进入烧写模式,连接USB到自己的电脑,开始系统的烧录。
打开SDKmanager,选择LOGIN,注意SDK在每次启动登录时都会检测你的网络状态,所以一定要确保网络畅通。
点击LOGIN之后会跳转到网页登录,检查网络状态,输入在下载SDK时用来注册会员的邮箱,点击Sign in。
输入密码进行登录,注意,在新设备第一次登录时会进行安全验证,注册邮箱会有验证邮件。
登录之后选择自己的边缘设备型号,选择Linux版本进行安装。
④安装裸系统
因为NX的内置sd卡只有16GB,所以只能安装裸系统,不能有其他复杂的包,选择Jetson OS,进行下载和安装:
等待下载和安装结束:
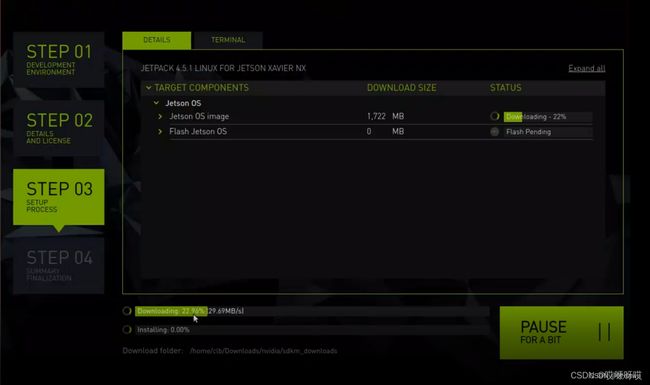
在进行到Create OS image时就可以将短接线拔掉。
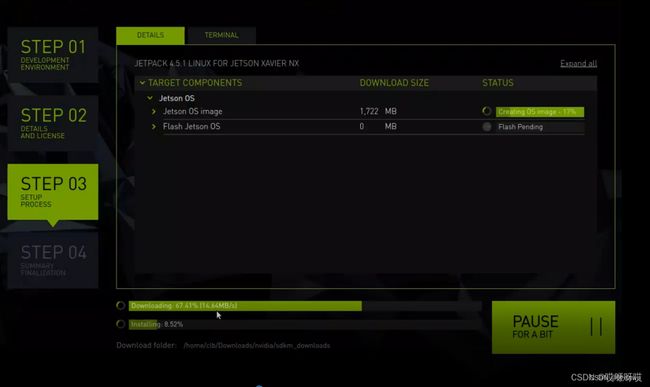
烧录完成,点击FINISH,然后关闭软件。这时系统已经烧录进NX的内置SD卡,最好给NX外接一个屏幕,然后进行新系统的设置(用户名,密码等),这里NX一般会自动重启进入烧录好的系统,如果烧录完成NX没有重启,手动拔插电源即可进入。

⑤进行系统迁移
将SD卡的系统迁移到SSD固态硬盘,这里需要先将前面拆下来的固态硬盘装上去。
注意:确保NX是开机状态并且与主机进行USB通信。
<1>格式化安装好的SSD固态硬盘,打开菜单并进行搜索磁盘(disk),然后打开:
<2>进入磁盘,选择自己安装的NX的SSD固态硬盘;
<3>按住Ctrl+F键或者点击右上角下拉菜单的第一项进行磁盘格式化:
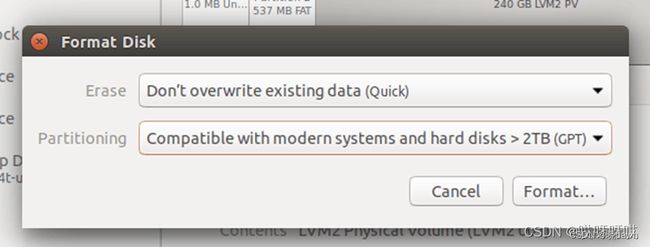
<4>进行磁盘分区,建议分割一个16GB(与真实内存大小相等)的swap区和主分区:
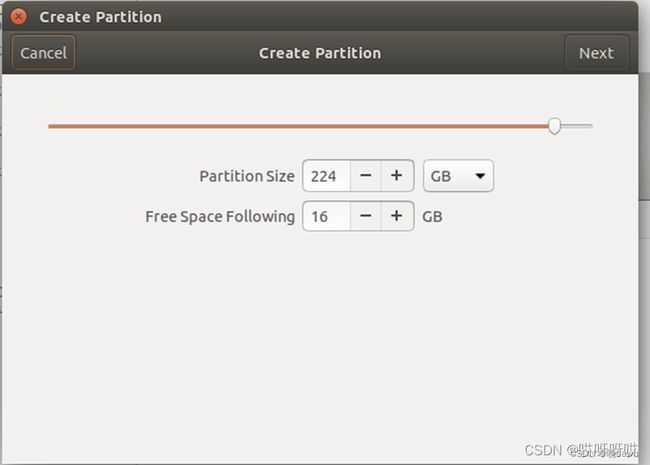
以前硬盘需要分区主要是基于以下原因:
①数据的安全性:因为每个分区的数据是分开的,所以当你需要将某个分区的数据重整时,例如将计算机中Windows的C盘重装系统,可以将其他重要数据移动到其他分区,使重整系统不会影响到其他数据;
②系统的效能考虑:由于分区将数据集中在某个磁柱的区段,例如第一个分区位于磁柱号码1-100号,于是当有数据要读取自该分区时,磁盘只会搜寻前1-100的磁柱范围。由于数据集中了,有助于数据读取的速度与效能。
随着操作系统越来越稳定,Win7以后产品以及Linux都非常稳定,基本上都已经不再需要频繁的重装系统了,所以数据的安全性已经不再是问题。而关于系统的效能考虑,主要是针对以前机械硬盘的特点,现在广泛使用的固态硬盘以及磁盘阵列都不再需要考虑机械特性,所以也不用再考虑。
一般来说,如果硬件的配备资源足够的话,那么swap应该不会被我们的系统所使用到,swap会被利用到时通常就是物理内存不足的情况。CPU所读取的数据都来自于内存,当内存不足时,为了让后续的程序可以顺利的运作,因此在内存中暂不使用的程序与数据就会被移到swap中,此时内存就会空出来给需要执行的程序加载。由于swap是用磁盘来暂时放置内存中的信息,所以用到swap时你的主机磁盘灯会闪个不停。
现在内存价格越来越便宜,上百GB内存的服务器也很常见,但依然需要swap设置,其原因为:
①交换分区主要是在内存不够用的时候,将部分内存上的数据交换到swap空间上,以便让系统不会因内存不够用而导致内存溢出OOM或者更致命的情况出现。如果物理内存不够大,通过设置swap可以在内存不够用的时候不至于触发OOM-Killer(pagefault out of memory)导致某些关键进程被杀掉,如数据库业务等。
②有些业务系统,如redis、elasticsearch等,主要使用物理内存的系统,不希望让它使用swap,因为大量使用swap会导致性能急剧下降。不设置swap的话,如果使用内存量激增,那么可能会出现OOM-Killer的情况,导致应用宕机。如果设置了swap,此时可以通过设置/proc/sys/vm/swappiness这个swap参数,调整使用swap的概率,此值越小,使用swap的概率就越低。这既可以解决OOM-Killer的情况,也可以避免出现swap过度使用的情况。swappiness=0的时候表示最大限度使用物理内存,然后才是swap空间;swappiness=100的时候表示积极使用swap分区,并且把内存上的数据及时搬运到swap空间里面。其默认值为60,即系统的物理内存在使用到100-60=40%时,就可以开始使用交换分区了。操作系统层面希望尽可能使用物理内存,所以将该值设置为10。
swap设置的原则为:物理内存在16GB以下的,swap设置为物理内存的2倍即可;而物理内存大于16GB的,推荐swap设置为8GB左右即可。
现在计算机使用的磁盘容量越来越大,流行的磁盘分区方案是:有多少块磁盘装置就分几个区,每个磁盘装置内部不再分区。推荐使用固态硬盘+NAS文件服务器的磁盘存储方案,固态磁盘分一个区,并划分一个临时的iSCSI分区,不管多少个NAS都统一管理(当成一个分区)。
iSCSI即Internet小型计算机系统接口,是一种基于因特网及SCSI-3协议的存储技术,其利用TCP/IP协议将计算机之间的局域网仿真成高性能存储总线,来加速计算机之间的数据传输速度,一般用其来连接服务器计算机和磁盘阵列。由于该功能属于高级内容,个人还不甚了解,所以分区时也就不考虑划分iSCSI分区。
<5>给磁盘命名并创建
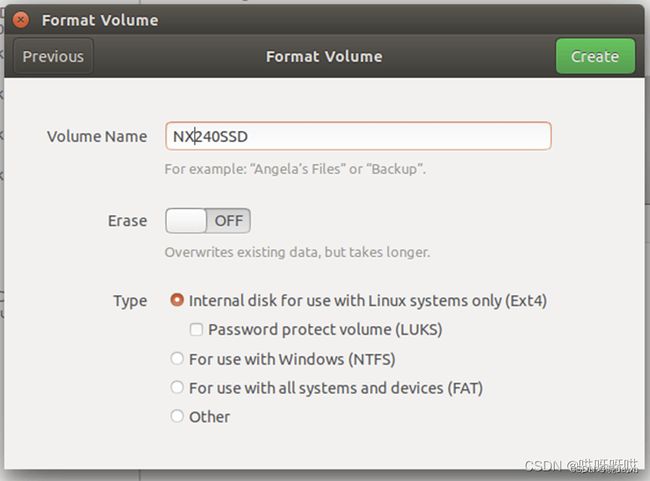
现在已经格式化了SSD固态硬盘,点击关闭,然后使用命令来将系统迁移到SSD。
<6>在终端输入命令克隆项目,git clone https://github.com/jetsonhacks/rootOnNVMe.git
下载好之后切换输入cd rootOnNVMe切换目录,再输入./copy-rootfs-ssd.sh将源文件复制到SSD固态硬盘,就完成了系统的迁移。
<7>迁移好之后,还需要将SSD设置为第一启动盘,系统才能从SSD启动,输入./setup-service.sh重启生效,至此,整个系统安装完成,并且已经迁移到SSD固态。
注意:迁移之后原sd卡的系统不能擦除,否则会无法启动。
⑥安装环境包
重复④中的所有步骤,但在第<5>步进行选择时,不要选择Jetson OS,选择Jetson SDK Componts,其他步骤相同,安装完成之后,基本所有的包都安装好了,如果自己的项目有特殊需求,自己再安装其他的包。
到此在Jetson Xavier NX上的Ubuntu系统安装完成。
三、操作系统的备份与恢复
使用NVIDIA SDK Manager刷写Jetson设备耗时较久,如果用户需要刷写多台Jetson设备,建议使用flash命令提供的备份与恢复功能。
Jetson Xavier NX配备了eMMC固态硬盘,系统的刷写只能经由上位机并通过局域网进行,因此在刷机前除了Jetson Xavier NX开发套件之外,还需要一台安装了Ubuntu系统的上位机。使用系统备份功能前,用户需要在Ubuntu主机上至少已成功刷写了一台Jetson Xavier NX,此时在主机的JetPack安装文件所在目录下会生成“nvidia”子目录,需要用到该目录下的文件完成备份与恢复操作。
①使用flash命令备份系统
将装有Ubuntu系统的主机和想要备份的Jetson Xavier NX通过USB线连接,操作Jetson Xavier NX启动进入recovery模式,运行lsusb命令,确认有“Nvidia Corp.”字样。在Ubuntu主机的Terminal中输入以下命令开始备份Jetson Xavier NX当前的系统:
$ cd ~/nvidia/nvidia_sdk/JetPack_4.2.1_Linux_GA_P2888/Linux_for_Tegra
$ sudo ./flash.sh -r -k APP -G system.img jetson-xavier mmcblk0p1
备份过程大约耗时20min。备份成功后,在Ubuntu主机的Terminal中输入ls命令,可以看到当前目录下生成了“system.img”文件。
②使用flash命令恢复系统
将Ubuntu主机和想要用备份镜像恢复的Jetson Xavier NX通过USB线连接,操作Jetson Xavier NX启动进入recovery模式,运行lsusb命令,确认有“Nvidia Corp.”字样。在Ubuntu主机的Terminal中输入以下命令开始恢复Jetson Xavier NX的系统:
$ cd ~/nvidia/nvidia_sdk/JetPack_4.2.1_Linux_GA_P2888/Linux_for_Tegra
$ mv bootloader/system.img bootloader/system.img.bak
$ mv system.img bootloader/
$ sudo ./flash.sh -r jetson-xavier mmcblk0p1
恢复过程大约耗时10min。
四、预装软件工具
JetPack系统预安装的开发工具有:
①CUDA:其是一种由NVIDIA推出的通用并行计算架构和编程模型,该架构使GPU能够解决复杂的计算问题;
②cuBLAS:其是CUDA专门用来解决线性代数运算的库,可以实现向量相乘、矩阵乘向量、矩阵乘矩阵等运算;
③cuFFT:其是CUDA提供的封装好的FFT库,它提供了与CPU上的FFT库相似的接口,能够让用户轻易地挖掘GPU的强大浮点处理能力,又不用自己去实现专门的FFT内核函数;
④cuDNN:其是NVIDIA专门针对深度神经网络中的基础操作推出的库,其为深度神经网络中的标准流程提供了高度优化的实现方式,如convolution、pooling、normalization、activation layers的前向及后向过程;
⑤TensorRT:其是一个高性能的深度学习推理引擎,用于在生产环境中部署深度学习应用程序,可提供最大的推理吞吐量和效率。使用TensorRT用户无须再部署硬件上安装并运行深度学习框架;
⑥VisionWorks:其是一个用于计算机视觉和图像处理的软件开发包,其实现并扩展了Khronos OpenVX标准,并针对支持CUDA的GPU和片上系统Soc进行了优化,使开发人员能够在可伸缩和灵活的平台上实现计算机视觉应用程序;
⑦OpenCV:其是一个跨平台计算机视觉库,实现了图像处理和计算机视觉方面的很多通用算法。OpenCV4Tegra是NVIDIA转为Tegra平台优化额定一个OpenCV版本;
⑧OpenGL:其是一个跨编程语言、跨平台的专业图形程序接口,可用于二维/三维图像,是一个功能强大、调用方便的底层图形库;
⑨libargus:其为相机应用程序提供了低级帧同步应用编程接口、每帧相机参数控制、多个(包括同步)相机支持和设备说明表EGL流输出;
⑩GStreamer:其是用来构建流媒体应用的开源多媒体框架,其目标是要简化音/视频应用程序的开发,主要用来处理像MP3、Ogg、MPEG1、MPEG2、AVI、Quicktime等多种格式的多媒体数据。
基于这些开发工具,Jetson平台主要支撑两大软件平台:
①基于CUDA的智能计算平台;
②基于DeepStream的智能视觉平台。
1. CUDA简介
CUDA是一个基于GPU开发的并行计算平台和编程模型,通过CUDA开发人员可以利用GPU的强大功能极大地加快计算应用程序的速度。在GPU加速的应用程序中,工作负载的顺序执行部分运行在单线程性能优化的CPU上,而应用程序的计算密集型部分并行运行在数千个GPU内核上。当使用CUDA时,开发人员可使用流行的语言如C、C++、Python和Matlab进行编程,并可通过一些基本关键字的扩展来表达并行性。
GPU并不是一个独立运行的计算平台,需要与CPU协同工作,可以看成是CPU的协处理器,因此在说GPU并行计算时,其实是指基于CPU+GPU的异构计算架构。在异构计算架构中,CPU与GPU通过PCIe总线连接在一起协同工作,CPU所在位置称为主机端host,GPU所在位置称为设备端device。
GPU具有更多的运算核心,特别适于数据并行的计算密集型任务,如大型矩阵运算;而CPU的运算核心较少,但其可实现复杂的逻辑运算,因此其适于控制密集型任务。另外CPU上的线程是重量级的,上下文切换开销大;而GPU由于存在很多核心,其线程是轻量级的。因此基于CPU+GPU的异构计算架构可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,进而发挥最大功效。
CUDA编程模型是一个异构模型,需要CPU和GPU协同工作。在CUDA中host和device是两个重要概念,用host指代CPU及其内存,而用device指代GPU及其内存。CUDA程序中既包含host程序又包含device程序,它们分别在CPU和GPU上运行,同时host与device之间可以进行通信,这样它们之间可以进行数据拷贝。
典型的CUDA程序执行流程如下:
①分配host内存并进行数据初始化;
②分配device内存并从host将数据拷贝到device上;
③调用CUDA的核函数,在device上完成指定的运算;
④将device上的运算结果拷贝到host上;
⑤释放device和host上分配的内存。
上述流程中最重要的是调用CUDA的核函数kernel来执行并行计算,核函数是CUDA中一个重要的概念,是在device上的线程中并行执行的函数。在CUDA中每个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID。
要深刻理解核函数必须要对核函数的线程层次结构有一个清晰的认识。首先GPU上有很多并行化的轻量级线程,核函数在device上执行时实际上是启动很多个线程。一个核函数启动的所有线程称为一个网格grid,同一个网格上的线程共享相同的全局内存空间,网格是线程结构的第一个层次,而网格又可以分为很多线程块block,一个线程块里面包含很多线程,这是第二个层次。网格和线程块都是定义为dim3类型的变量,dim3可以看成是包含3个无符号整数(x,y,z)成员的结构体变量,在定义时缺省值初始化为1,因此网格和线程块可以灵活地定义为一维、二维或三维结构。
一个线程块上的线程是放在同一个流式多处理器Streaming Multiprocessor,SM上的,但是单个SM的资源有限,这导致线程块中的线程数是有限的。现代GPU的线程块可支持的线程数可达1024个,核函数的这种线程组织结构天然适用于向量、矩阵等运算。
每个线程有自己的私有本地内存Local Memory,而每个线程块又包含共享内存Shared Memory,可以被线程块中的所有线程共享,其生命周期与线程块一致。此外所有的线程都可以访问全局内存Global Memory,还可以访问一些只读内存块:常量内存Constant Memory和纹理内存Texture Memory。一个核函数实际上会启动很多线程,这些线程在逻辑层是并行的但在物理层却并不一定。这其实和CPU的多线程有类似之处,多线程如果没有多核支持,在物理层也是无法实现并行的。但好在GPU存在很多CUDA核心,充分利用CUDA核心可以充分发挥GPU的并行计算能力。
GPU硬件的一个核心组件是SM,SM的核心组件包括:CUDA核心、共享内存、寄存器等。SM可以并发地执行数百个线程,并发能力取决于SM拥有的资源数。当一个核函数被执行时它的网格中的线程块被分配到SM上,一个线程块只能在一个SM上被调度。SM一般可以调度多个线程块,具体可调度线程块的数量取决于SM本身的能力,有可能一个核函数的各个线程块被分配多个SM,所以网格只是逻辑层,而SM才是执行的物理层。
SM采用的是单指令多线程Single-Instruction Multiple-Thread,SIMT架构,基本的执行单元是线程束wraps,线程束包含32个线程,这些线程同时执行相同的指令,但是每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径。所以尽管线程束中的线程同时从同一程序地址执行,但可能具有不同的行为,如遇到了分支结构,一些线程可能进入这个分支执行指令,但是另外一些线程有可能不执行,它们只能等待,因为GPU规定线程束中的所有线程在同一周期执行相同的指令,线程束分化会导致性能下降。
当线程块被划分到某个SM上时,它将进一步被划分为多个线程束,因为这才是SM的基本执行单元。但一个SM同时并发的线程束数是有限的,这是因为资源受限制,SM要为每个线程块分配共享内存,也要为每个线程束中的线程分配独立的寄存器,所以SM的配置会影响其所支持的线程块和线程束的并发数量。总之网格和线程块只是逻辑划分,一个核函数的所有线程其实在物理层不一定是同时并发的,所以核函数的网格和线程块的配置不同其性能会出现差异,这点是要特别注意的。
在Jetson平台上的实际开发中,大多数时候用户并不需要编写底层的CUDA核函数,因为NVIDIA在CUDA的基础上还提供了cuBLAS、cuFFT和cuDNN等运行库,这些运行库相当于对CUDA又做了一层封装,用户只需要对这些运行库提供的函数进行调用就可以完成计算的任务。
2. DeepStream简介
DeepStream是基于NVIDIA运行的工具,主要应用于视觉整个流程的解决方案。与其他视觉库(例如OpenCV)的区别在于DeepStream建立了一个完整的端到端的支持方案,换句话说用户的源无论是Camera、Video、还是云服务器上的视频,从视频的编解码到后台的图像推理,再到展示出来的画面,对这一完整流程上的各个细节DeepStream都能起到辅助作用。在这个流程中用户只需要加上自己的内容,例如视频检索需要训练出一个模型来识别或检测视频中的人脸,将人脸识别和人脸检测的相关模型添加到方案中即可;对于设置视频源的完整流程DeepStream可自动完成。
DeepStream是一个建立在GStreamer基础上的SDK,而GStreamer是一个开源的多媒体分析框架,由几个核心组件组成。GStreamer底层(第一个层次)里最基本的单元是插件plugins,它支持很多种不同的插件,每个插件具有自己特定的功能,这种最基本的插件是基于GStreamer的基本功能块。底层之上的第二个层次的基本单元是功能箱bin,在GStreamer和DeepStream里功能箱包含了很多前面提到的功能块,许多功能块一起工作来完成某种具体的功能,构成所谓的功能箱。最上层(第三个层次)实际上是一种总线,一种基于GStreamer或DeepStream的管理数据流动和同步的总线。
DeepStream提供了一个基于插件的模型,用户基于该模型可以创建一个基于图形的管道将这些插件组合到应用程序中,通过这些插件的互连应用程序得以深度优化。DeepStream允许应用程序利用GPU和CPU进行异构处理,这意味着当应用程序使用提供GPU加速的插件时,该插件将可以访问底层的NVIDIA优化库。DeepStream本身就是多线程的,通过启用多线程方面的异构化,使用构建管道架构的插件来处理应用程序的创建,DeepStream既可以针对NVIDIA GPU进行优化,还可以在CPU上有效运行。
基于插件这种构建块的特性,DeepStream将深度神经网络和其他复杂的处理任务引入到流处理管道中,这使得它能够实时理解丰富的多模态视频和传感器数据,可以通过流水线的处理模式支持深度学习能力及更多的图像、传感器处理和融合算法的流数据应用程序。
NVIDIA推出的最新版本DeepStream 4.0为所有的NVIDIA GPU提供了统一的代码库、可与物联网服务快速集成的特性,以及可方便部署的容器,这极大地提高了大规模应用程序的交付和维护效率。统一的代码库所支持代码的可移植性为开发人员提供了在单个平台上构建应用程序及在多个平台上部署的灵活性,新的通信插件提供了与Azure Edge IoT、MQTT和Kafka消息代理的总包集成,使得开发人员能够利用云资源来构建应用程序和服务。这些特性使开发人员能够更高效地为视频流处理的各个相关领域创建更智能的应用程序。DeepStream 4.0还推出了一种新的参考跟踪器设计,该设计为目标跟踪提供了鲁棒性,并通过GPU加速提高了精度,其还在应用程序中增加了对多种异构相机输入和相机类型的支持,这对机器人和无人机应用研究来说是非常重要的特性。
3. TensorRT简介
TensorRT是NVIDIA公司推出的高速推理引擎,它使用CUDA C进行编程,在GPU上做推理计算的同时还针对推理部分做了优化和加速,由于网络的权值已经固定下来,因此针对一个训练好的模型用户可以对计算流图进行优化。TensorRT解析了网络计算流图并对其进行优化,对计算流图的优化并未改变底层计算,而是对计算流图进行重构,使得操作更加快速高效。使用TensorRT的推理引擎runtime进行模型部署推理时,不需要再安装其他的深度学习框架。
当一个深度学习框架在推理过程中执行计算流图时,它为每一层调用多个函数。由于每一步操作都在GPU上进行,加之主机和GPU之间频繁地进行内存传输,多个CUDA kernel函数会被启动,而kernel函数的计算通常比上一级的启动和读写每层张量数据的开销快很多,后果就是有限的内存带宽会产生阻碍,以及GPU资源不能被充分利用。TensorRT可对进行时序操作的多个kernel函数进行纵向合并,解决了上述问题。这种层和层的合并减少了kernel函数的启动,避免了层和层之间的内存写入、读出,不同尺寸的卷积层、偏置层和激活层能够被整合成一个名为“CBR”的单一kernel。其还能识别出那些有着相同输入和滤波器尺寸但却不同权值的网络层,通过将每个矩阵直接连接到需要的地方,减少连接层来预分配输出缓冲区并以跨步的方式写入缓冲区。TensorRT优化减少了网络层和kernel函数的启动次数,得到一个更小更快、效率更高的计算流图,因此降低了推理的延迟时间,提高了实时性。
TensorRT会针对训练好的模型进行分析,针对特定的参数做优化,得到一个优化好的推理引擎,并将它序列化,优化模型和生成引擎。优化模型、生成引擎的过程耗时较长,所以将引擎保存为磁盘上的一个优化方案文件是十分必要的,在执行推理的时候可对其反复调用。在优化阶段TensorRT会从上百个专门的kernel函数中针对一系列参数和实验平台选择出最优的函数,例如有很多个计算卷积的算法,TensorRT会根据GPU、输入数据尺寸、滤波器尺寸、张量布局、每批训练的尺寸和其他参数,从kernel函数库中挑选出性能最优的实现方法。TensorRT还会减少内存占用的空间,只在每个张量的使用期间为其指明内存空间,增加内存的重复使用次数。
五、常用Linux命令
在Linux系统里大部分图形界面下可以完成的操作都可以在Terminal应用界面里通过键入相应的命令行来实现,对于Jetson平台的程序开发人员来说,大多数操作也都是在Terminal应用界面中完成的。这可通过按下Ctrl+Alt+T组合键直接运行。
如果快捷键无效,可通过以下命令修改配置文件使其生效:
sudo vim ~/.config/openbox/lxde-rc.xml
在文本中加入以下内容:
<keybind key="C-A-t">
<action name="Execute">
<command>lxterminal</command>
</action>
</keybind>
重启系统后即可生效。
针对Jetson Xavier NX,Ubuntu系统中的常用命令有:
<1>使用管理员权限执行命令:
$ sudo <命令> <参数>
<2>显示当前工作目录的路径:
$ pwd
<3>进入到指定目录:
$ cd <文件夹相对路径>
<4>列出指定目录下的文件/文件夹:
$ ls <文件夹相对路径>
<5>创建指定名称的文件夹:
$ mkdir <文件夹名称>
<6>删除指定名称的空文件夹:
$ rmdir <文件夹名称>
<7>将原始路径的文件复制到目标路径:
$ cp <原始路径> <目标路径>
<8>将原始路径的文件移动到目标路径,也可用于修改文件名:
$ mv <原始路径> <目标路径>
<9>删除指定文件:
$ rm <文件名>
<10>修改文件时间或创建新文件:
$ touch <文件名>
<11>对指定的文件/文件夹进行打包或解包:
$ tar -czf <文件名> .tar.bz2. /*
$ tar -xzf <文件名> .tar.bz2
在Linux系统中,压缩文件的扩展名大多是:.tar, .tar.gz, .tgz, .gz, .Z, .bz2, .xz。真正的压缩指令是gzip,但还需要tar命令将很多文件打包成一个文件!目前主要使用的压缩格式是bzip2,对应压缩文件扩展名bz2,其拥有更高的压缩比,且压缩花费时间又不会过长。
最简单使用的tar命令为:
- 压缩:
tar –zcv –f filename.tar.bz2 <要被压缩的文件或目录名>
- 查询:
tar –ztv –f filename.tar.bz2
- 解压缩:
tar –zxv –f filename.tar.bz2 –C <要解压缩的目录名>
目前Windows的WinRAR也支持.tar.bz2扩展名的压缩/解压缩。
<12>对.zip格式的压缩包文件进行解压缩:
$ unzip <文件名> .zip
<13>在指定路径下查找文件:
$ find <路径> -name <文件名>
<14>查看内核版本:
$ uname -a
<15>查看Ubuntu版本:
$ lsb_release -i -r
<16>查看CPU信息:
$ cat /proc/cpuinfo
<17>查看USB设备:
$ lsusb
<18>查看硬盘剩余空间:
$ df -h
<19>查看进程占用系统资源的实时情况:
$ top
<20>查看系统的当前使用者:
$ who
<21>查看系统的最近几个登录账号:
$ lastlog
<22>显示有线网卡当前连接信息(常用于查IP):
$ ifconfig eth0
<23>显示无线网卡当前连接信息:
$ ifconfig wlan0
<24>查询当前系统正在通过TCP/IP协议监听的进程信息:
$ netstat -lt
<25>查看在系统后台运行的程序:
ps -aux
<26>将数据同步写入硬盘:
$ sync
<27>重启系统:
$ reboot
<28>系统关机:
$ poweroff
六、常用apt命令
Ubuntu系统使用的应用程序管理器是Advanced Package Tool,简称apt。其优势在于出色的解决软件依赖关系的能力,使用apt可以自动从互联网的多个软件仓库中搜索、安装、升级、卸载软件或操作系统。早期的apt程序使用的命令是apt-get,从Ubuntu 16.04版后将apt-get命令和其他命令进行了整合,推出了apt命令。apt命令不仅支持apt-get命令常用的功能选项,还支持apt-cache和apt-config命令中的一些功能。apt命令具有更精简但足以满足用户需求的命令选项,而且参数选项的组织方式更为有效。它默认启用的几个特性对用户也非常有帮助,例如用户使用apt命令可以在安装或删除程序时看到进度条。apt命令一般需要管理员权限 执行,所以都会结合sudo命令执行。常用的apt命令有:
①更新安装源:
$ sudo apt update
一般在Linux系统安装完后的第一次登录时,最先运行的就是这个命令,目的是从所有的软件安装源里更新可安装软件信息列表。如果用户在使用apt命令安装指定软件包的时候被提示找不到该软件包,也可以考虑使用update参数更新一下安装源,或许问题就可迎刃而解;
②升级所有可升级的软件包:
$ sudo apt upgrade
一般在第一次运行apt update命令后,接下来就会运行apt upgrade命令;
③安装指定的软件包:
$ sudo apt install <软件包名称>
$ sudo apt -y install <软件包名称> # 使用参数“-y”可在命令行交互时自动输入“y”
$ sudo apt -no-install-recommends install <软件包名称> # 使用参数“-no-install-recommends”可以避免安装非必需的文件
④移除指定的软件包:
$ sudo apt remove <软件包名称>
⑤移除指定的软件包同时移除相关配置文件:
$ sudo apt purge <软件包名称>
⑥移除所有曾被自动安装但现在已经无任何依赖关系的软件包:
$ sudo apt autoremove
⑦删除所有已下载的软件包:
$ sudo apt clean
使用apt命令下载的软件包默认保存在“/var/cache/apt/archives”目录下,使用apt命令或dpkg命令默认将软件安装在“/usr/share”目录下,可执行文件默认安装在“/usr/bin”目录下,库文件默认安装在“/usr/lib”目录下,配置文件默认安装在“/etc”目录下;
⑧编辑apt的源列表:
$ sudo apt edit-sources
$ sudo gedit /etc/apt/sources.list # 使用gedit而不是vim只是为了便于操作
Jetson平台默认的apt安装源是由Ubuntu官方提供的,可以确保所需的软件包都会及时更新,但由于服务器在国外可能会出现网络连接较慢的现象,用户可以将安装源替换为国内的安装源以提高安装速度。由于Jetson平台是Arm内核,因此在替换源的时候一定要确认是Arm平台的软件源,不要换成了PC平台的软件源。
在使用apt命令时,偶尔会遇到“E: Could not get lock /var/lib/dpkg/lock”,“E: Could not get /var/lib/dpkg/lock-fronted”,“E: Could not get /var/cache/apt/archives/lock”等错误,这是由于用户上一次调用apt命令时没有正确退出,系统还锁定着apt进程,以避免同时运行两个apt进程而导致冲突。因此在实际操作时,用户应首先确认没有其他的apt进程正在工作,然后使用rm命令将相应的lock文件删除,就可以正常使用apt命令。rm命令的使用格式为:
$ sudo rm /var/lib/dpkg/lock
$ sudo rm /var/lib/dpkg/lock-fronted
$ sudo rm /var/cache/apt/archives/lock
注意:此时使用rm命令不要带“-r”参数,以免操作不慎将“dpkg”目录或其他目录删除。
⑨使用dpkg命令实现.deb格式软件包的安装与卸载:
$ sudo dpkg -i <安装包文件名> .deb # 使用参数“-i”可实现.deb格式软件包的安装
$ sudo dpkg -r <软件包名称> # 使用参数“-r”可实现.deb格式软件包的卸载
apt命令虽然功能强大,但必须配合网络服务器在线完成安装。如果Jetson平台的网络不可用,也可以从其他联网的机器上下载版本合适的.deb格式的安装文件,将安装文件拷贝到Jetson平台并使用dpkg命令完成离线安装。
注意:dpkg仅能安装或卸载指定的软件包,无法自动处理模块的依赖关系,并且它绕过apt包管理数据库对软件包进行操作,所以系统也无法记录相关的安装操作。
⑩更换镜像源:
先通过在Terminal界面输入下面命令来备份初始源:
$ sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
编辑sources.list文件内容:
$ sudo gedit /etc/apt/sources.list
可使用以下国内镜像源地址:
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main multiverse restricted universe
保存文件,然后更新apt源:
$ sudo apt update
七、Jetson Xavier NX常用功能
1. 硬件性能调整
Jetson平台上的风扇是PWM调速风扇,通电后默认并不会启动,可通过在Terminal界面输入以下命令驱动风扇:
$ sudo sh -c ‘echo 255 > /sys/devices/pwm-fan/target_pwm’
上面命令中的255对应最大风扇转速,将255替换为更小数字可以降低风扇转速。
Jetson平台还可以调整功率模式,可通过在Terminal界面输入以下命令开启开发版最佳性能模式:
$ sudo jetson_clocks
$ sudo nvpmodel -m 0
上述命令先将时钟值调到最大。nvpmodel是Jetson平台修改功率模式的命令,参数“-q”是查询当前工作模式,“-m”是设定当前工作模式,Jetson Xavier可以设定0-3挡,其中0档为最佳性能模式。
2. 查看关键软件版本信息
<1>可通过在Terminal界面输入以下命令查看驱动版本信息:
$ head -n 1 /etc/nv_tegra_release
<2>可通过在Terminal界面输入以下命令查看软件环境版本信息:
$ sudo jtop
<3>可通过在Terminal界面输入以下命令查看CUDA版本信息(安装目录下查看):
$ cat /usr/local/cuda/version.txt
<4>可通过在Terminal界面输入以下命令查看cudnn版本信息(安装目录下查看):
$ dpkg -l libcudnn8
<5>可通过在Terminal界面输入以下命令测试CUDA是否可用:
$ nvcc -V
如果出现bash:nvcc:command not found时需添加环境变量。可通过下面命令打开环境变量所在文件:
$ sudo gedit ~/.bashrc
并在.bashrc内容中最后三行加入:
export CUDA_HOME=/usr/local/cuda
export PATH=/usr/local/cuda-10.2/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
然后通过下面命令使文件改动生效:
$ source ~/.bashrc
<6>可通过在Terminal界面输入以下命令查看TensorRT版本信息:
$ dpkg -l tensorrt
整个Linux系统相关的参数都在/proc目录下面,相关的文件与对应的内容为:

3. 安装中文输入法
通过在Terminal界面输入下面命令来安装IBus框架:
$ sudo apt install ibus ibus-clutter ibus-gtk ibus-gtk3 ibus-qt4
通过下面命令启动IBus框架:
$ im-config -s ibus
通过下面命令安装拼音引擎
$ sudo apt install ibus-pinyin
其中ibus-pinyin是IBus下的一个智能中文输入法引擎。
通过下面命令设置IBus框架:
$ ibus-setup
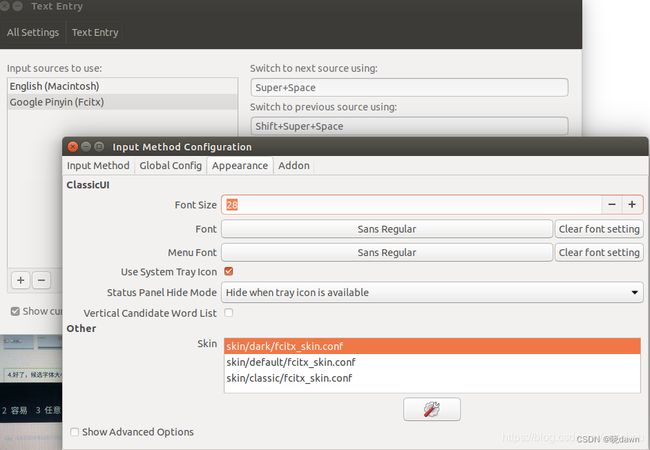
然后进入IBus设置界面,鼠标点击“Input Method”按钮;在“Input Method”界面鼠标点击“Add”按钮,选择“Chinese”;完成后按Shift键。如果不能进行转换则需要手动转换:在电脑任务栏中找到输入法,鼠标点击“Text Entry Settings”,进入设置界面点击“Add”按钮,添加“中文拼音”。
安装之后,如果发现中文输入法无候选框
$ killall fcitx-qimpanel
$ sudo apt-get remove fcitx-ui-qimpanel
然后进行参数设置
4. 安装QQ
QQ Linux版的官方网址为https://im.qq.com/linuxqq/download.html,在下载列表中选择ARM64架构+deb格式,下载文件为linuxqq_2.0.0-b2-1084_arm64.deb。
先确认是否安装了gtk2.0:
$ sudo apt install libgtk2.0-0
通过以下命令安装QQ:
$ sudo dpkg -i linuxqq_2.0.0-b2-1084_arm64.deb
运行QQ:
$ sudo qq
八、深度学习功能
Jetson Xavier NX尽管算力较强有16GB的显存,但Jetson平台显存与内存共用的模式使得它难以完成大型图像数据集的训练任务,也就是顶多训练一个基于AlexNet的图像分类模型。建议在配备高端显卡的CentOS服务器和基于Docker镜像环境下的深度学习框架进行训练。
Jetson平台的操作系统是专门针对硬件编译的,所以一些通用版本的软件在Jetson Xavier NX上并不一定能正常运行。如果想在Jetson Xavier NX上运行基于GPU的深度学习推理,推荐从NVIDIA Jetson下载中心https://developer.nvidia.com/embedded/downloads处,下载NVIDIA官方预编译好的深度学习框架工具。
总结
以上就是关于Jetson Xavier NX要讲的内容,欢迎大家对本文章进行补充和指正。
参考资料
《基于NVIDIA Jetson平台的人工智能实例开发入门》,哈尔滨工业大学出版社
《边缘计算原理与Jetson平台开发》,西安电子科技大学出版社
《鸟哥的Linux私房菜 基础学习篇》,人民邮电出版社出版
https://blog.csdn.net/six_sixsix666/article/details/124217780