基于Python实现的手写数字图像识别
目录
实验目的及实验内容 1
实验目的: 1
实验内容: 1
原理分析: 1
实验环境 13
实验步骤及实验过程分析 13
实验结果总结 18
实验目的及实验内容
(本次实验所涉及并要求掌握的知识;实验内容;必要的原理分析)
实验目的:
使用 python 进行图像处理
实验内容:
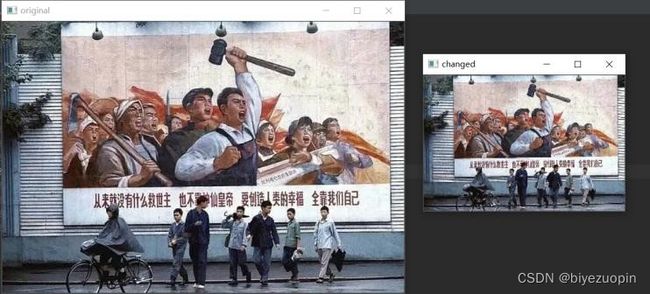
自己找一张图片,用 OpenCV 的仿射变换实现图片缩放。
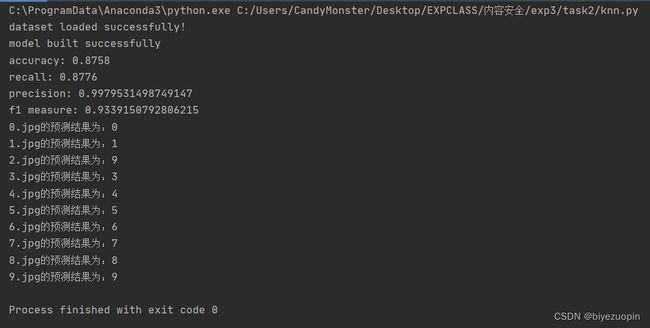
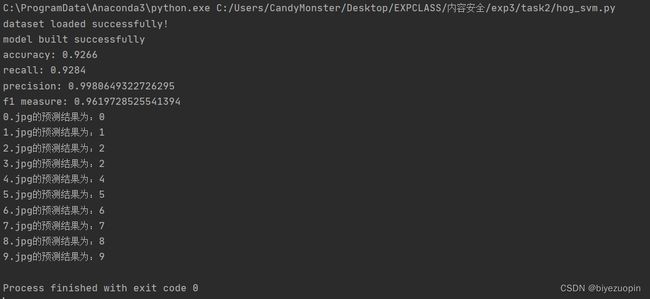
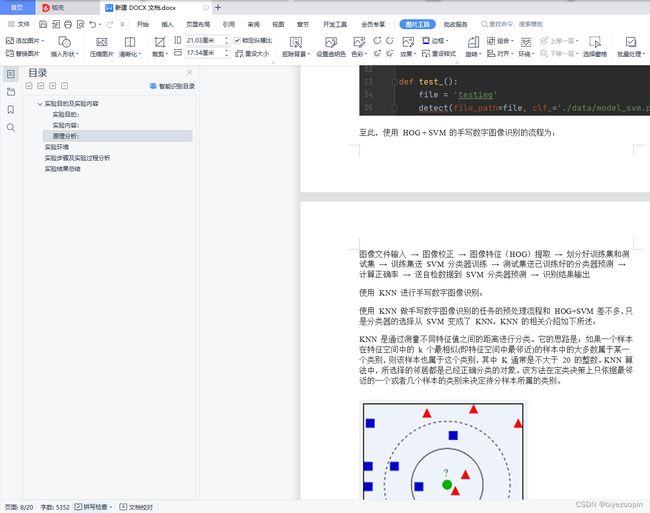
理解 HOG、ORC 过程,修改 digits.py 或独立编程,实现数字图像的识别,要求分别使用 SVM、knn(第六次课)以及 cnn 神经网络模型(第七次课),以群文件中 digit_data.rar 中 train 文件夹下数据作为训练集,test 文件夹下图片作为测试集,并计算测试集上分类正确率,本文转载自http://www.biyezuopin.vip/onews.asp?id=16706并自己找测试数据(可以是一个或多个数字)。
实验环境
(本次实验所使用的器件、仪器设备等的情况)
处理器:Intel® Core™ i5-9300H CPU @ 2.40GHz 2.40 GHz (2)操作系统环境:Windows 10 家庭中文版 x64 19042.867
编程语言:Python 3.8
其他环境:16 GB 运行内存
IDE 及包管理器:JetBrains PyCharm 2020.1 x64, anaconda 3 for Windows(conda 4.9.0)
实验步骤及实验过程分析
(详细记录实验过程中发生的故障和问题,进行故障分析,说明故障排除的过程及方法。根据具体实验,记录、整理相应的数据表格、绘制曲线、波形等)
说明:
本篇实验报告所记录的内容仅为写报告时(2021/05/12)的情况,可能与实际实验时/04/28)结果有出入。
一切以实际运行时所得到的结果为准。
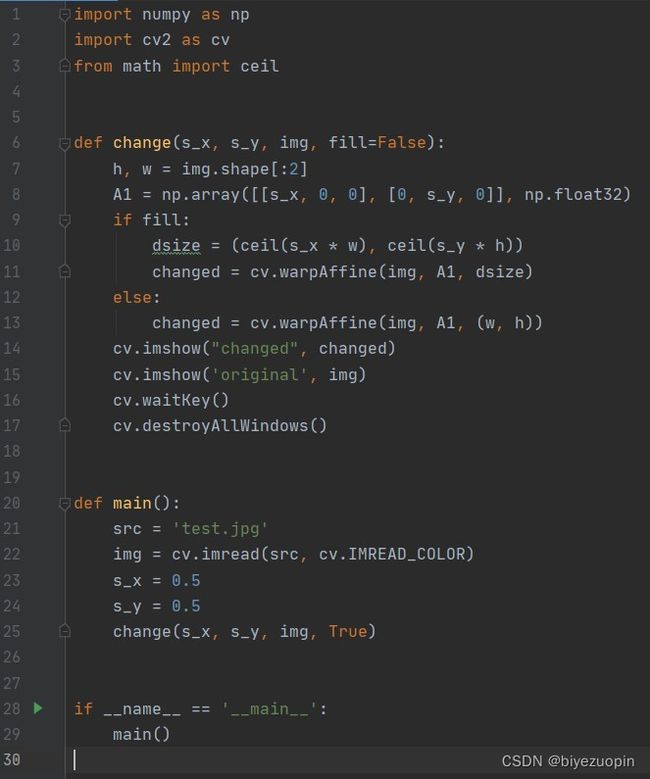
用 OpenCV 的仿射变换实现图片缩放:
import numpy as np
import torch
from torch import nn
import torch.nn.functional as F
import pickle
from utils import label_2_id, id_2_label
from torch.utils.data import TensorDataset, DataLoader
import matplotlib.pyplot as plt
import cv2 as cv
import os
class CnnImage(object):
def __init__(self, data_dir='../digit_data', save_dir='./data', batch_size=64,
epochs=50, learning_rate=0.0005, use_gpu=False):
self.data_dir = data_dir
self.mode = 'train'
self.save_dir = save_dir
self.batch_size = batch_size
if not use_gpu:
self.device = torch.device("cpu")
print('use device: cpu')
else:
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
if self.device == torch.device("cpu"):
print('no usable cuda detected! Use cpu instead')
else:
print('use device: gpu')
self.epochs = epochs
self.lr = learning_rate
self.loss_ = []
if not os.path.exists(self.save_dir):
os.mkdir(self.save_dir)
self.model = nn.Sequential(nn.Conv2d(1, 25, 3, 1),
nn.MaxPool2d(2, 2),
nn.Conv2d(25, 50, 3, 1),
nn.MaxPool2d(2, 2),
nn.Flatten(),
nn.Linear(50 * 5 * 5, 10))
self.model.to(self.device)
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=self.lr)
def train(self, train_loader, test_loader, save=True):
best_test = None
tmp_loss = []
best_model = self.model
for epoch in range(self.epochs):
for batch, label in train_loader:
y_predict = self.model(batch)
loss = F.cross_entropy(y_predict, label)
tmp_loss.append(loss.item())
loss.backward()
self.optimizer.step()
self.optimizer.zero_grad()
self.loss_.append(sum(tmp_loss)/len(tmp_loss))
correct_percent = 0
error_num = 0
with torch.no_grad():
for batch, label in test_loader:
y_predict = self.model(batch)
top_p, top_class = torch.topk(y_predict, 1)
top_class = top_class.squeeze(1)
correct_percent += torch.sum(label == top_class).item()
error_num += torch.sum(label != top_class).item()
correct_percent /= len(test_loader) * self.batch_size
if best_test is None or best_test < correct_percent:
best_test = correct_percent
best_model = self.model
self.model = best_model
if save:
tar = self.save_dir + '/' + 'model_cnn.pkl'
with open(tar, 'wb') as f:
pickle.dump(self.model, f)
print('model saved successfully, see it in: ', tar)
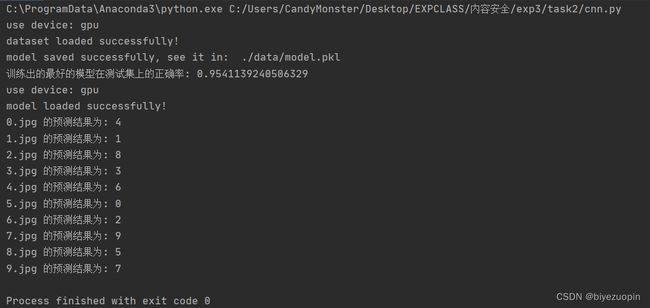
print('训练出的最好的模型在测试集上的正确率: ' + str(best_test))
def load_model(self):
tar = self.save_dir + '/' + 'model_cnn.pkl'
with open(tar, 'rb') as f:
self.model = pickle.load(f)
print('model loaded successfully!')
def predict(self, path):
if os.path.isdir(path):
files = os.listdir(path)
else:
print('no files detected!')
return None
x = []
y = []
for item in files:
file = path + '/' + item
img = cv.imread(file, 0) # 读灰度图
re_shape = cv.resize(img, (28, 28), interpolation=cv.INTER_CUBIC)
# shape: (28, 28), size of the reshaped image
x.append(re_shape)
y.append(0)
x_set = np.array(x)
# array, shape:(n, 28, 28)
y_set = np.array(y)
# array, shape:(n,)
x_tens = torch.tensor(x_set, dtype=torch.float).unsqueeze(1).to(self.device)
y_tens = torch.tensor(y_set, dtype=torch.long).to(self.device)
# x_tens: torch.Tensor, torch.Size([n, 1, 28, 28])
# y_tens: torch.Tensor, torch.Size([n])
sets = TensorDataset(x_tens, y_tens)
loader = DataLoader(sets, self.batch_size, True)
with torch.no_grad():
for batch, label in loader:
y_predict = self.model(batch)
top_p, top_class = torch.topk(y_predict, 1)
top_class = top_class.squeeze(1)
return top_class.cpu().tolist() # 返回的结果在CPU上, 是个列表
def set_data(self, save=True):
sets = self.save_dir + '/sets.pkl'
if os.path.exists(sets):
with open(sets, 'rb') as f:
loader = pickle.load(f)
train_loader = loader[0]
test_loader = loader[1]
print('dataset loaded successfully!')
else:
self.mode = 'train'
train_dataset = self.dataset()
train_loader = DataLoader(train_dataset, self.batch_size, True)
self.mode = 'test'
test_dataset = self.dataset()
test_loader = DataLoader(test_dataset, self.batch_size, True)
print('dataset built successfully!')
if save:
loader = (train_loader, test_loader)
with open(sets, 'wb') as f:
pickle.dump(loader, f)
print('dataset saved in: ', sets)
return train_loader, test_loader
def dataset(self):
path = self.data_dir + '/' + self.mode
labels = os.listdir(path)
x = []
y = []
for label in labels:
img_path = path + '/' + label
files = os.listdir(img_path)
for item in files:
file = img_path + '/' + item
img = cv.imread(file, 0) # 读灰度图
# shape: (28, 28), size of the image
x.append(img)
y.append(label_2_id[label])
x_set = np.array(x)
# array, shape:(n, 28, 28)
x_tens = torch.tensor(x_set, dtype=torch.float).unsqueeze(1).to(self.device)
# torch.Tensor, torch.Size([n, 1, 28, 28])
y_set = np.array(y)
# array, shape:(n,)
y_tens = torch.tensor(y_set, dtype=torch.long).to(self.device)
# torch.Tensor, torch.Size([n])
sets = TensorDataset(x_tens, y_tens)
return sets
def train_():
epochs = 100
cnn = CnnImage(data_dir='../digit_data', save_dir='./data', batch_size=64,
use_gpu=True, epochs=epochs, learning_rate=0.0005)
train_loader, test_loader = cnn.set_data(save=True)
cnn.train(train_loader=train_loader, test_loader=test_loader, save=True)
loss = cnn.loss_
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.set_title('epoch - loss')
ax.set_xlabel('epoch')
ax.set_ylabel('loss')
x_axis = [i for i in range(len(loss))]
plt.plot(x_axis, loss)
plt.show()
def test():
cnn = CnnImage(data_dir='../digit_data', save_dir='./data', batch_size=64,
use_gpu=True)
cnn.load_model()
test_path = 'testimg'
pre = cnn.predict(test_path)
if pre is None:
return
else:
files = os.listdir(test_path)
for i in range(len(files)):
res = files[i] + ' 的预测结果为: ' + str(pre[i])
print(res)
if __name__ == '__main__':
train_()
test()