在斯坦福,做 Manning 的 phd 要有多强?
每天给你送来NLP技术干货!

文 | 付瑶
编 | 小轶来自 | 夕小瑶的卖萌屋
博士的毕业论文是我们博士学位教育重要的一环,不仅仅是获得学位的最后一个难关,也是读博期间工作的总结展现。那么一个优秀的博士在读博期间会做出多少成果?ta 的博士论文又长什么样?今天,让我们打开一篇最新的斯坦福博士的毕业论文,来看看都讲了些什么。
作者是刚刚8月份毕业于斯坦福的女博士Abigail See。Abigail 的研究方向是开放式的文本生成,导师是大名鼎鼎的 Chris Manning。目前在谷歌学术上已经拥有 2139 的引用量。同时,她也是斯坦福 AI Salon,AI woman 两个组织的主要负责人,还连续担任过是斯坦福 cs224n (NLP导论)的助教组长。
Abigail 在读博期间共计发表了 6 篇一作文章。她在博士毕业论文中对自己读博 6 年间的科研成果进行了总结。单论数量而言,平均每年一篇的产量,可能即使放之国内普通高校也不能算十分突出。难得的是篇篇高质量,其中不乏引用量 1700+ 的超高影响力论文,以及获得最佳论文提名的高认可度工作。
 ▲Abigail See 读博期间的一作论文
▲Abigail See 读博期间的一作论文
博士论文标题:
NEURAL GENERATIONOF OPEN-ENDED TEXT AND DIALOGUE
论文链接:
https://purl.stanford.edu/hw190jq4736
作者主页:
https://cs.stanford.edu/people/abisee/
 工作概述
工作概述
Abigail 博士期间的研究方向在开放式文本生成,但具体应用的下游任务并不集中,主要涉及 摘要、对话、故事生成 三类。在这三个子领域上,作者对自己的 contribution 总结如下:
摘要:提出指针生成器模型(pointer-generator network)来提高复制的准确性,以及一个覆盖机制来减少生成摘要的重复。
对话:通过收集大规模用户评价,揭示了机器人行为(如重复、特异性、话题停留和提问)和用户质量判断之间的关系,改善用户体验
故事生成:描述了大规模预训练和解码算法对生成文本的句法、语义、结构和文体方面的影响。作为成果,作者部署研究了一个生成式聊天模型,能够通过分析机器人与用户的交互,确定了机器人的主要错误类型、与用户不满的关系,从而改善对话系统。
 文章架构
文章架构
作者在毕业论文中分为了5大部分来主要叙述自己的研究工作分别是:
引言
研究背景
指针生成网络
控制聊天对话的属性
预训练对故事生成的影响
用户聊天对话中的不满
引言和背景介绍部分我们就略去不表了,主要关注后面四个部分。
指针生成网络概述
本章节中主要叙述了作者构建的指针生成网络 Pointer-Generator的相关工作。该文发表于ACL'17,目前引用量已达1700+。对 NLG 有过了解的同学想必都听说过。
相关论文:
Get to the point: Summarization with pointer-generator networks
论文链接:
https://arxiv.org/pdf/1704.04368.pdf
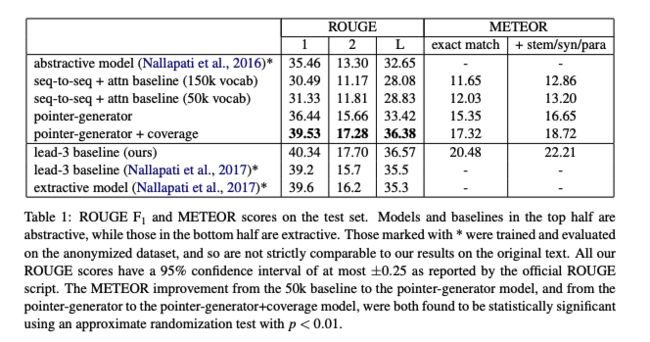
Pointer-Generator 构建了一个融合网络以及指针网络的混合模型,既允许通过指针复制单词,也允许从固定词汇表中生成新的单词。把sequence-to-sequence模型应用于摘要生成时存在两个主要的问题:(1)难以准确复述原文的事实细节、无法处理原文中的未登录词(OOV);(2)生成的摘要中存在重复的片段。针对这两个问题,本文提出的融合了seq2seq模型和pointer network的pointer-generator network以及覆盖率机制(coverage mechanism),在CNN/Daily Mail数据集上,相比于state-of-art,ROUGE分数提升了两个点。
控制聊天对话的属性
相关论文:
What makes a good conversation? How controllable attributes affect human judgments
论文链接:
https://arxiv.org/pdf/1902.08654.pdf
作者提出:一个好的对话需要有以下特性:简洁与细节 持续主题与更换主题 问问题和回答问题,对应四种属性:重复性、独特性、回复相关性和问与答。在这部分内容中作者旨在设计通用且易于调整的的控制方法,研究了两种控制方法条件训练(conditional Traning)和加权解码(weighted decoding)。使用条件训练和加权解码来控制四个属性:repetition重复性、secificity特异性、response-relatedness反映相关性和question-asking提问。在测试该任务改进的效果子作者对28种模型配置进行了大规模的人工评估,并进行了人机对话以进行比较。


预训练对故事生成的影响
相关论文:
Do Massively Pretrained Language Models Make Better Storytellers?
论文链接:
https://arxiv.org/pdf/1909.10705.pdf
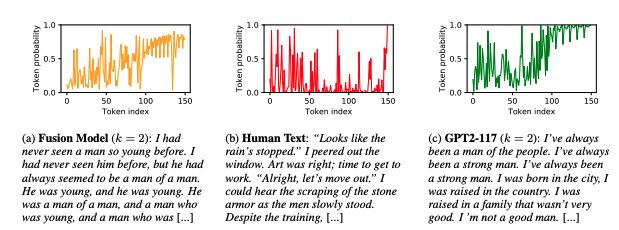
在大规模语料中训练得到的预训练语言模型在很多NLP任务中都取得了较好的表现,但是在开放文本生成中的能力仍未被明确。一些实验结果虽然展现了其潜在的能力,但是并没有关于预训练模型在文本生成的能力的具体研究。作者通过在WritingPrompts-1024上评估,对比了GPT2-117与Fusion model等模型在故事生成的表现。通过多种指标评估生成文本后,研究人员发现了一些可以很好生成故事的模型,以及一些表现不太好的模型。虽然 GPT2-117 在语境上更好,对事件的顺序更敏感,而且使用了更多不常用的词汇,但是它在使用最大似然解码算法时只能生成重复的、没有多样性的文本。
用户聊天对话中的不满
相关论文:
Understanding and predicting user dissatisfactionin a neural generative chatbot
论文链接:
https://sigdial.org/sites/default/files/workshops/conference22/Proceedings/pdf/2021.sigdial-1.1.pdf
Nominated for Best Paper Award
神经生成对话代理已经显示出越来越多的能力进行简短的闲谈对话,神经生成可以实现更强大的社交聊天机器人,能够比以前基于规则或基于检索的对话系统灵活地讨论更广泛的主题。然而,它们在实际部署中的表现-尤其是在嘈杂的环境中与内在动机的用户对话,却没有得到很好的研究。

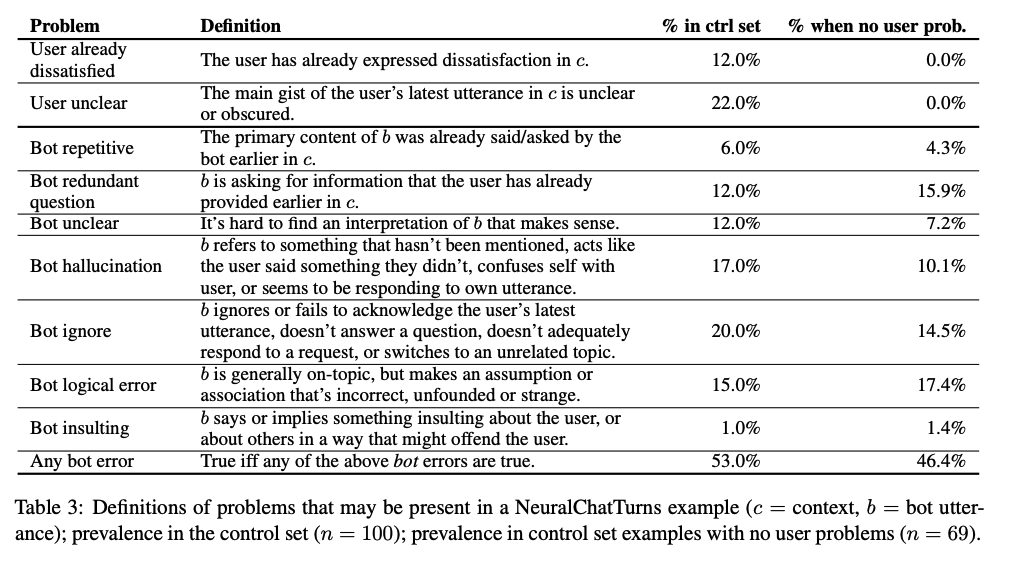
作者对一个神经生成模型进行了详细的案例研究,该模型部署在Chirpy Cardinal (Alexa Prize socialbot)上,在一系列的实验中,发现了不够明确的话语是生成错误的主要来源,如忽略、幻觉、不清楚和重复。除此之外,作者证明了不满意的用户话语可以作为半监督学习信号来改进对话系统,训练了一个predictor用于改进下一轮来减少不满,并通过人类评价表明,作为一个排名函数,它选择了更高质量的神经生成的话语。
 小结
小结
当我们打开论文来看作者在读博期间的研究工作,虽然她在读博期间的论文数量并不算多,但是每一篇章的质量都很高,不仅获得过最佳论文的提名,而且有引用量高达1700的文章,即使有的论文没有太高的引用量,也是对在该领域有深刻影响,是立足所研究课题长远发展的角度进行科研工作。比起快速切换热点来迎合顶会的青睐,她选择了坚定沿着自己的思路,来创立自己的学术宇宙。对一个普通研究生来说,能有一两篇顶会论文已实属不易。但如果志存高远,以领域内的贡献要求自己,你将会看到不一样的峰顶。Chris Manning 和他的 phd 给我们树立了一个很好的榜样。
博士毕业文是各位攻读博士学位的同学获取学位必须经历的一道难关,除了学术态度之外,写作的技巧也非常重要。通过这次的拜读经历,小编总结了几条tips分享给大家:
(1)梳理脉络:博士毕业论文篇幅较大,如果作者脉络梳理的不够清晰,不仅会显得研究工作、学术思路杂乱无章,而且会导致读者一头雾水,读不透论文的内容。
(2)内容组织 :毕业论文是在读博期间几年围绕课题开展的研究的集合,框架的设定、章节的展开都应与你的研究历程关联,层层剥茧,互为支撑。
(3)凸出重点:支撑大论文写作的研究内容和数据的数量会非常庞大,将与论文相关性较弱的数据剔除,删掉旁支末节,以此来突出自己的主要研究重点及关键实验结果。
(4)撰写细节:在大篇幅写作中,搭配不当、语义重估、语序颠倒等错误的出现不是罕事,这些会对你的论文将会非常的减分。因此,一定要多检查几遍细节。除此之外,论文中的图片也是一种重要的成果展展示,控制所有图片的颜色、尺寸、图中文字的字体、字号,使得你的论文看起来整洁统一。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
记得备注呦
整理不易,还望给个在看!
