标签稀疏类别不平衡问题解决方案总结
知乎主页https://www.zhihu.com/people/shuang-shou-cha-dai-53 https://www.zhihu.com/people/shuang-shou-cha-dai-53
https://www.zhihu.com/people/shuang-shou-cha-dai-53
目录
1:定义
2:解决方法
2.1:采样
2.2:阈值调整(权重调整)
2.3:模型融合
2.4:多分类的不平衡问题
2.5:其他方法
1:定义
类别不平衡(class-imbalance)是指分类任务中不同类别的训练样例数目差别很大的情况。
在现实的分类任务中,我们会经常遇到类别不平衡的问题。一般来说,不平衡样本会导致训练模型侧重样本数目较多的类别,而“轻视”样本数目较少类别,这样模型在测试数据上的泛化能力就会受到影响。比如在金融反欺诈中,欺诈交易的应该是很少部分,绝大部分交易是正常的,这就是一个正常的类别不平衡问题,假设数据集中有99个正例样本,1个负例样本。在不考虑样本不平衡的很多情况下,学习算法会使分类器放弃负例预测,因为把所有样本都分为正,也可获得高达99%的训练分类准确率。
一般而言,如果类别不平衡比例超过4:1,那么其分类器会大大地因为数据不平衡性而无法满足分类要求的。因此在构建分类模型之前,需要对分类不平衡性问题进行处理。
备注:相对的,这里不是说类别平衡的训练集一定比类别不平衡的训练集效果好,这里不一定能够保证,单对于大多数情况,类别平衡的数据对模型训练来说更加友好,因为模型不会倾向与类别数量较多的那一类别。
2:解决方法
2.1:采样
采样时针对数据类别不平衡问题的最简单、最暴力的方法。
欠采样:如果负样本太多,那就对负样本进行欠采样,就是随机的从负样本中抽取一部分样本,然后与正样本合并成训练集丢给模型训练。这样有个很明显的弊端,就是会造成严重的信息损失,数据收集不易,还要丢弃一部分,很显然不合理。
过采样:如果正样本太少,那就对正样本进行过采样,就是对正样本进行复制。
或者如果是NLP、CV邻域的任务,可以做一些数据增强,以此来增加正样本的数量。比如说CV中,可以对类别较少的图像进行旋转,缩放等操作来增加该类别的数据量。而对于一般的任务来说,如果仅仅通过简单的对正样本进行复制,这样会使模型在这正样本上过拟合,因为模型学习到太多遍这样的样本。
上面介绍了对正样本进行过采样,会使模型产生过拟合风险,SMOTE也是基于过采样的方法,但是SMOTE可以降低过拟合的风险。
SMOTE:通过对训练集中的小类数据进行插值来产生额外的小类样本数据。产生新的少数类样本,产生的策略是对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。
总结:采样算法容易实现,运行速度快,且效果也不错。
在欠采样、过采样中的经验总结:
1. 考虑对大类下的样本(超过1万、十万甚至更多)进行欠采样,即删除部分样本;
2. 考虑对小类下的样本(不足1为甚至更少)进行过采样,即添加部分样本的副本;
3. 考虑尝试随机采样与非随机采样两种采样方法;
4. 考虑对各类别尝试不同的采样比例,不一定是1:1,有时候1:1反而不好,因为与现实情况相差甚远;
5. 考虑同时使用过采样与欠采样,对二者进行结合;
2.2:阈值调整(权重调整)
对于二分类任务来说,一般会以0.5作为阈值来划分正负样本(比如逻辑回归),预测概率值大于0.5则判定为正样本,反之为负样本。对于类别不平衡的训练集来说,这个阈值就不再合适了,因为当使用负样本来更新模型权重时,权重的更新会使模型的输出尽量偏向于0,如果负样本太多,那么负样本对于模型权重的更新量就比较多,使得模型输出接近0的概率就比较大,所以可以根据正负样本所占的比例来调整阈值。比如正样本只占10%,则可以将阈值调整为0.1,输出概率大于0.1的则判定为正样本,这样可以很好的解决类别不平衡问题,调整阈值是个简单且高效的方法。
在SVM中,如果是类别不平衡数据,可以设置class_weight='balanced'。
# Create support vector classifier
svc = SVC(kernel='linear', class_weight='balanced', C=1.0, random_state=0)
# Train classifier
model = svc.fit(X_std, y)
在支持向量机中,C 是负责惩罚错误分类数据的超参数。决数据类别不平衡的一个方法就是使用基于类别增加权重的C值:
![]()
其中,C是误分类的惩罚项, 是与类别 j 的出现频率成反比的权重参数,
是与类别 j 的出现频率成反比的权重参数,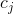 就是类别 j 对应的加权C值,主要思路就是增大误分类少数类别带来的影响,保证少数类别的分类正确性,避免被多数类别掩盖。
就是类别 j 对应的加权C值,主要思路就是增大误分类少数类别带来的影响,保证少数类别的分类正确性,避免被多数类别掩盖。
在scikit-learn 中,使用 svc 方法时,可以通过设置参数class_weight='balanced',参数‘balanced’ 会自动按照以下公式计算权值:
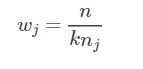
其中,为类别 j 对应权值,n为数据总数,k为类别数量,即数据有 k个种类,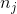 是类别j 的数据个数,因此类别 j 的样本越多,权重越小,反之越大。
是类别j 的数据个数,因此类别 j 的样本越多,权重越小,反之越大。
另外在XGBoost算法中,也可以设置参数值scale_pos_weight,官方文档中对该参数的介绍如下:

可以看到,也是通过控制样本权重值来调整,即:如果设置scale_pos_weight的话,那么应该设置成number of negative samples / number of positive samples。
2.3:模型融合
模型融合不仅可以提升预测的准确性,其实也可以解决类别不平衡问题。
比如对于正样本(10%)、负样本(90%)的训练集,可以将负样本均等拆分为9份(注意一定要同分布拆分),然后每一份都与正样本组合成为一个小训练集,得到9份类别平衡的数据。然后用9个模型分别去训练(可以使用有差异性的模型, 使预测精度更高),然后可以对9个模型的预测结果加权累加,作为最终的输出。最优的权重通常难以抉择,可以使用一个LR将9个模型的输出作为输入,通过训练让模型自己学习每个模型对应的权重即可。
通过模型融合就可以保证每个模型的训练数据都是类别平衡的数据,并且还能提升预测的准确性。
2.4:多分类的不平衡问题
LightGBM对多分类的不平衡问题也进行了完美地处理。它设计了参数class weight。在文档中介绍如下:

一共提到了以下几点:
- 要么传入是dict,格式是class_weight={1: 1, 0: 2}这样;要么传入"balanced";要么传入是None。如果传入的是dict,那么每个类的权重正如你传入的那样。
- 使用class weight仅仅适用多分类任务。
- 如果是二分类任务,使用参数is_unbalance 或者scale_pos_weight 。
- 如果传入的是"balanced",那么会自动根据标签的值来算出每个类的权重,每个类的权重是与每个类别样本出现的次数成反比的。具体是根据公式: n_samples / (n_classes * np.bincount(y))。np.bincount(y)是numpy的一个很有趣的函数,不了解的可以参考该篇文档。为了更形象地说明,这里举一个例子,假如有10个样本,标签分别为[ 0 , 2 , 2 , 1 , 1 , 1 , 1 , 1 , 1 , 1 ] [0,2,2,1,1,1,1,1,1,1][0,2,2,1,1,1,1,1,1,1],这典型是多分类不平衡。那么np.bincount(y)输出的值为[ 1 , 7 , 2 ] [1,7,2][1,7,2],n_samples / (n_classes * np.bincount(y))输出的值分别为10/(3*1),10/(3*7),10/(3*2)。这显然类别权重是与类别的样本个数成反比的。与上面的SVM 权重设置的思路类似(注:这里有一个背景,就是LightGBM中多类别必须设置为0,1,2,3…这样的形式)
- 如果传入的是None,那么每个类别的权重是一样的。
- 当然,与二分类一样,如果我们也传入了sample_weight,那么每个类的权重还要再乘以sample_weight。(注:sample_weight是LGBM是很少用到的一个功能,它一般是通过fit方法传入的,关于它的使用需要详细参考官方文档)
2.5:其他方法
假如遇到了太稀疏的情况,可以构建一个白噪声的分布,比如说 ,然后加上原数据构建新的数据来让整体的数据变得平衡。或者用别的标准来看模型的好坏,比如说F1-Score
知乎主页https://www.zhihu.com/people/shuang-shou-cha-dai-53https://www.zhihu.com/people/shuang-shou-cha-dai-53