【轻量卷积】组卷积(GC)、深度可分离卷积(DSC)与异构卷积(HC)(Pytorch实现)
为了提高网络性能,目前的研究趋向于更深,更复杂的网络,ImageNet刷分的前几名网络的参数量也非常巨大,没有高性能GPU的玩家只有长太息以掩涕兮了,然而,目前嵌入式设备和移动平台对深度学习模型部署的大量需求,促使轻量级网络成为一个热门的研究方向。于是,就记录一下看到的走轻量级路线的卷积吧。

1. 标准卷积
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
一般文献里面把我们常说的卷积核叫Filter,卷积核所含的一个通道叫Kernel,对于标准卷积过程,in_channels为特征输入的通道数,out_channels为Filter的个数,一个Filter带一个偏置。
import torch
import torch.nn as nn
k1 = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=3)
print('k1的偏置:\n', k1.bias)
k2 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
print('k2的偏置:\n',k2.bias)
输出为:
k1的偏置:
Parameter containing:
tensor([0.0128], requires_grad=True)
k2的偏置:
Parameter containing:
tensor([ 0.1486, -0.0689, 0.0052], requires_grad=True)
标准卷积过程如图所示【nn.Conv2d(in_channels=3, out_channels=1, kernel_size=2)】:

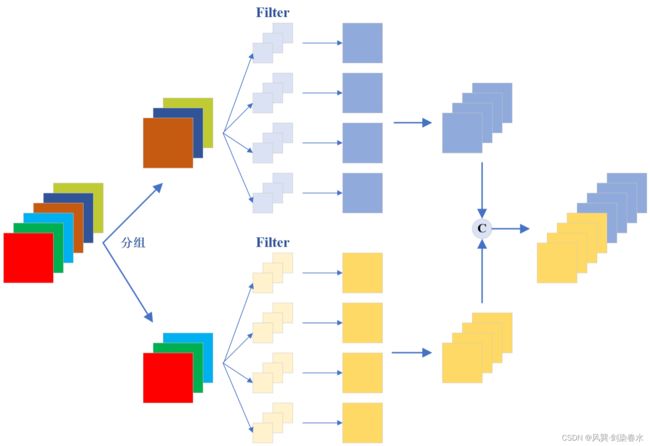
2. 组卷积(Group Convolution)
GroupConv的概念最早是在AlexNet中,由于GPU性能有限,当时模型被分成两个GPU进行训练。GroupConv将卷积Filter分为G组,输入特征映射通道也分为G组,每组卷积Filter处理对应的一组输入特征映射通道。由于每一组卷积Filter只应用于相应的输入通道组,卷积的计算代价显著降低。
但是,通道信息并不在不同的组之间共享,即不同组的输出Feature map通道只从对应组的输入通道接收信息。这阻碍了不同组通道之间的信息流动,降低了GroupConv的特征提取能力。为了解决这一问题,ShuffleNet进行了通道洗牌操作,增强了不同组通道之间的信息交换。
组卷积减少参数示例计算:
设In_channels = 6,Out_channels = 8,Filter为3×3:
【1】对于标准卷积:3×3×6×8 = 432
8个Filter,每个Filter有6个Kernel,每个Kernel有3×3 = 9个参数,故一共有3×3×6×8 = 432个参数。
【2】对于组卷积(分2组):3×3×3×4 + 3×3×3×4 = 216
若分为两组,则输入和输出通道都降低为原来的一半
一组有4个Filter,每个Filter有3个Kernel,每个Kernel有3×3 = 9个参数,一共有2组,故一共有2×3×3×3×4 = 216个参数。
组卷积过程如下图所示【nn.Conv2d(in_channels=6, out_channels=8, kernel_size=3, groups=2)】
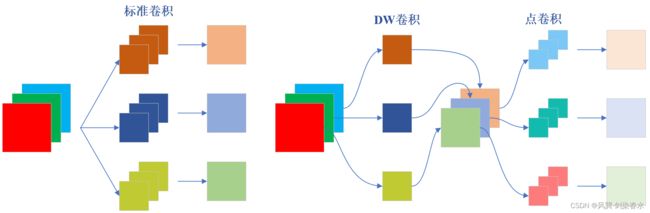
3. 深度可分离卷积(Depthwise Separable Convolution)
标准卷积同时对输入的特征图进行特征提取和通道融合。MobileNetV1中的深度可分离卷积将标准卷积分解为深度卷积,即DW卷积(depthwise convolution, DW)和点卷积(pointwise convolution, PW),在DW卷积中,对每个输入通道应用一个卷积核,通常3×3卷积用于特征提取,点卷积对DW卷积的输出Feature map进行1×1标准卷积,实现通道尺度上的融合。
故,通过分割特征提取与通道融合,深度可分离卷积显著减少了参数量。
标准卷积与DSC卷积的过程差异如下图所示:
深度可分离卷积减少参数示例计算:
设In_channels = 5,Out_channels = 10,Filter为3×3:
【1】对于标准卷积:3×3×5×10 = 270
10个Filter,每个Filter有5个Kernel,每个Kernel有3×3 = 9个参数,故一共有3×3×5×10 = 270个参数。
【2】对于DSC卷积:3×3×5 + 1×1×5×10 = 95
(1)DW:5个Filter,每个Filter有1个Kernel,共3×3×5 = 45个参数;
(2)PW:10个Filter,每个Filter有5个Kernel,每个Kernel有1个参数,一共有1×1×5×10 = 50个参数;
二者相加则有3×3×5 + 1×1×5×10 = 95个参数
DSC卷积实现代码(DW卷积也相当于分组为in_channels的组卷积):
class DSCConv(nn.Module):
def __init__(self,in_ch,out_ch):
super(DSCConv, self).__init__()
self.depth_conv = nn.Conv2d(in_channels=in_ch,
out_channels=in_ch,
kernel_size=3,
stride=1,
padding=1,
groups=in_ch)
self.point_conv = nn.Conv2d(in_channels=in_ch,
out_channels=out_ch,
kernel_size=1,
stride=1,
padding=0,
groups=1)
def forward(self,x):
out = self.depth_conv(x)
out = self.point_conv(out)
return out
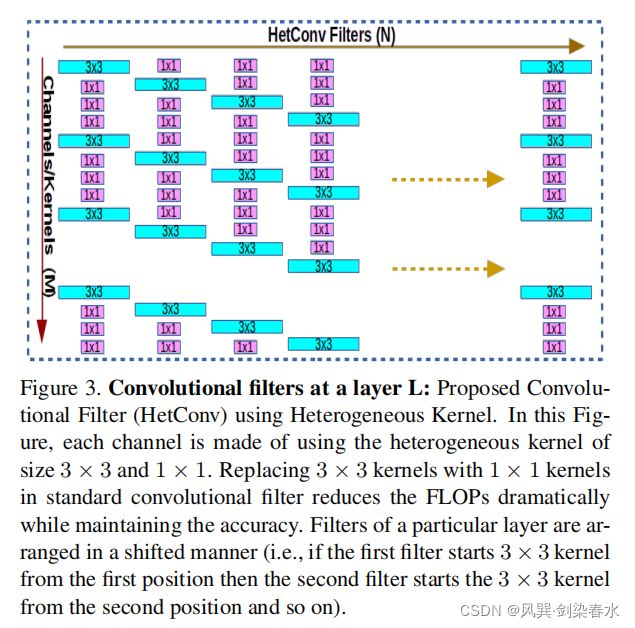
4. 异构卷积(Heterogeneous Convolution)
HetConv在一个卷积Filter中同时包含3×3卷积核和1×1 卷积核,异构Filter以移位方式排列,3×3卷积Kernel是离散排列的,3×3和1×1的卷积Kernel在Filter中交替使用。使用异构卷积,原始3×3标准卷积的计算复杂度可以降低3到8倍,而异构设计从本质上破坏了跨通道信息集成的连续性,并对输入特征图的完整信息的保存产生了负面影响。因此,这种策略会降低网络的准确性。

原论文中图示如上:即输入特征图的一部分通道应用k×k的卷积核,其余的通道应用1×1的卷积核。其中,P为控制卷积核为k的比例,若M为一个Filter中的Kernel个数,则M/P为一个Filter中3×3卷积核的个数。多个Filter采用循环位移的方式排列3×3卷积核与1×1卷积核。
异构卷积减少参数示例计算:
设In_channels = 6,Out_channels = 4:
【1】对于标准卷积:3×3×6×4 = 216
Filter中每个Kernel都为3×3大小
4个Filter,每个Filter有6个Kernel,每个Kernel有3×3 = 9个参数,故一共有3×3×6×4 = 216个参数。
【2】对于异构卷积(P = 3):( 3×3×2 + 1×1×4 ) × 4 = 88
4个Filter,每个Filter有6个Kernel,其中有2个为3×3大小,4个为1×1大小,故一共有( 3×3×2 + 1×1×4 ) × 4 = 88个参数
异构卷积实现代码:
class HetConv(nn.Module):
def __init__(self, in_channels, out_channels, p):
super(HetConv, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
num_k3 = in_channels // p
num_k1 = in_channels - num_k3
interval = num_k1 // num_k3
self.kernels = []
for i in range(num_k3):
self.kernels.append(1)
for j in range(interval):
self.kernels.append(0)
self.all_filters = nn.ModuleList()
for k in range(out_channels):
if k == 0:
self.all_filters.append(self.make_filter())
else:
temp = self.kernels.pop(-1)
self.kernels.insert(0, temp)
self.all_filters.append(self.make_filter())
def make_filter(self,):
filters = nn.ModuleList()
for i in range(self.in_channels):
if self.kernels[i] == 1 :
filters.append(nn.Conv2d(1, 1, 3, 1, 1))
elif self.kernels[i] == 0:
filters.append(nn.Conv2d(1, 1, 1, 1, 0))
return filters
def forward(self, x):
out = []
for i in range(self.out_channels):
out_ = self.all_filters[i][0](x[:, 0: 1, :, :])
for j in range(1, self.in_channels):
out_ += self.all_filters[i][j](x[:, j:j + 1, :, :])
out.append(out_)
return torch.cat(out, 1)
打印查看:
k = HetConv(in_channels=6, out_channels=4, p=3)
print(k)
HetConv(
(all_filters): ModuleList(
(0): ModuleList(
(0): Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(3): Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(5): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
)
(1): ModuleList(
(0): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(3): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(4): Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
)
(2): ModuleList(
(0): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(4): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(5): Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(3): ModuleList(
(0): Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(3): Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(5): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
)
)
)
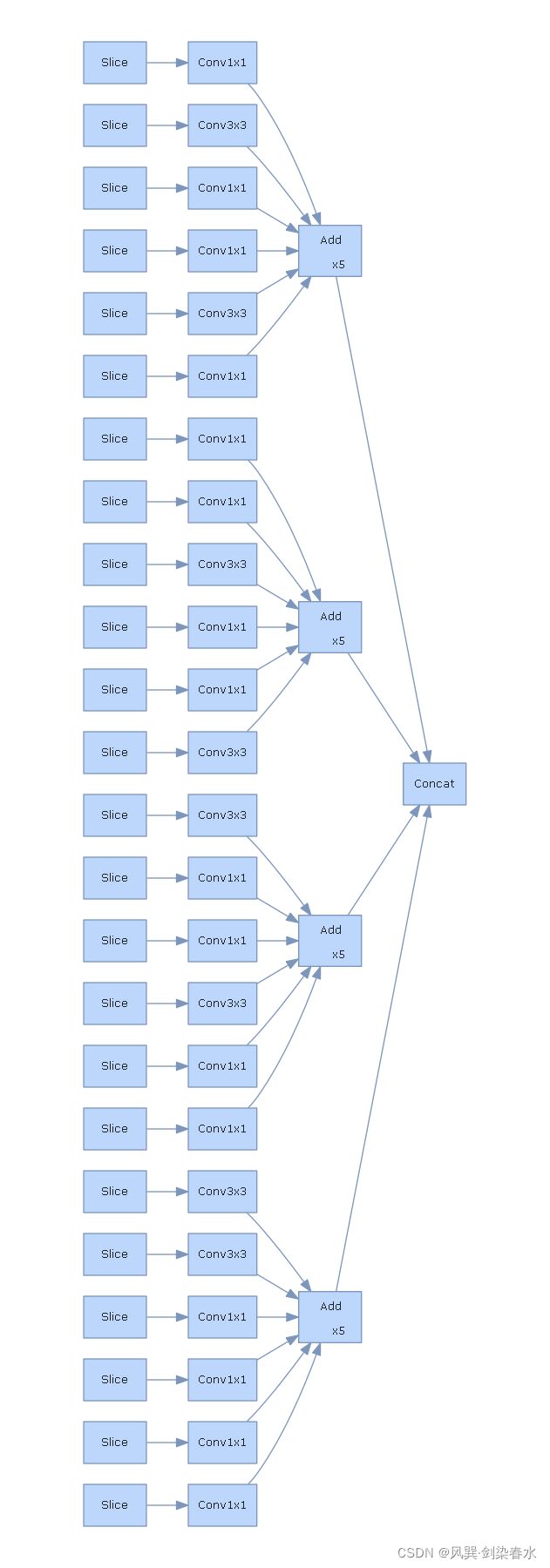
hiddenlayer可视化:
import hiddenlayer as hl
k3 = HetConv(in_channels=6, out_channels=4, p=3)
hl_graph = hl.build_graph(k3, torch.zeros([3, 6, 224, 224]))
hl_graph.theme = hl.graph.THEMES['blue'].copy()
hl_graph.save('./k3.png', format='png')
参考文献:
【1】HetConv: Heterogeneous Kernel-Based Convolutions for Deep CNNs
【2】DualConv: Dual Convolutional Kernels for Lightweight Deep Neural Networks