Python——Numpy库的学习
Numpy库
- NumPy 教程
-
- NumPy 简介
- NumPy 安装
- NumPy Ndarray 对象
- NumPy 数据类型
- NumPy 数组属性
- NumPy 创建数组
-
- NumPy 创建新数组
- NumPy 从已有的数组创建数组
- NumPy 从数值范围创建数组
- NumPy 切片和索引
-
- NumPy高级索引
- NumPy 广播(Broadcast)
- NumPy 迭代数组
- Numpy 数组操作
-
- 修改数组形状
- 翻转数组
- 修改数组维度
- 连接数组
- 分割数组
- 数组元素的添加与删除
NumPy 教程
NumPy 简介
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
NumPy 是一个运行速度非常快的数学库,主要用于数组计算,如下所示
NumPy 应用

NumPy 安装
Python 官网上的发行版是不包含 NumPy 模块的。
1、使用已有的发行版本【最简单的方法是下载以下的 Python 发行版】
Anaconda: 用于进行大规模数据处理、预测分析,和科学计算,致力于简化包的管理和部署。
Enthought Canopy: 提供了免费和商业发行版。
WinPython: 另一个免费的 Python 发行版,包含科学计算包与 Spyder IDE。支持 Windows。
2、使用 pip 安装
国外太慢,我们使用清华的镜像就可以:在CMD下输入如下命令
根据提示重复多安装几次就好了
pip3 install numpy scipy matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
安装验证——可以自己在编译器导入库测试是否安装成功
NumPy Ndarray 对象
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。


其内部结构如下图所示:

ndarray 对象由计算机内存的连续一维部分组成,并结合索引模式,将每个元素映射到内存块中的一个位置。内存块以行顺序(C样式)或列顺序(FORTRAN或MatLab风格,即前述的F样式)来保存元素。
NumPy 数据类型
数据类型
NumPy 数据类型基本上可以和 C 语言的数据类型对应上,比如bool,int,float……【需要的时候可以自己去查一下】
数据类型对象 (dtype)
用来描述与数组对应的内存区域是如何使用,它描述了数据的以下几个方面:
- 数据的类型(整数,浮点数或者 Python 对象)
- 数据的大小(例如, 整数使用多少个字节存储)
- 数据的字节顺序(小端法或大端法)
- 在结构化类型的情况下,字段的名称、每个字段的数据类型和每个字段所取的内存块的部分
- 如果数据类型是子数组,那么它的形状和数据类型是什么。

实例理解
import numpy as np #这是导入库的语句
# int8, int16, int32, int64 四种数据类型可以使用字符串 'i1', 'i2','i4','i8' 代替
dt = np.dtype('i4') #将值赋给一个变量
print(dt)
![]()
下面展示结构化数据类型的使用,类型字段和对应的实际类型将被创建
import numpy as np
dt = np.dtype([('age',np.int8)]) # 首先创建结构化数据类型
a = np.array([(10,),(20,),(30,)], dtype = dt) # 将数据类型应用于 ndarray 对象
print(a)
print(a['age']) # 类型字段名可以用于存取实际的 age 列
![]()
下面的示例定义一个结构化数据类型 student,并将这个 dtype 应用到 ndarray 对象。
import numpy as np
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student)
print(a)
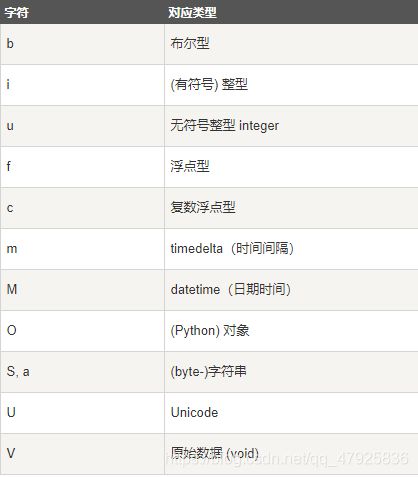
每个内建类型都有一个唯一定义它的字符代码,如下:
NumPy 数组属性
NumPy 数组的维数称为秩(rank),秩就是轴的数量,即数组的维度,一维数组的秩为 1,二维数组的秩为 2,以此类推。
在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。所以一维数组就是 NumPy 中的轴(axis),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
很多时候可以声明 axis。axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
重要 ndarray 对象属性

先定义numpy对象,即可直接输出上述属性,如下示例
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
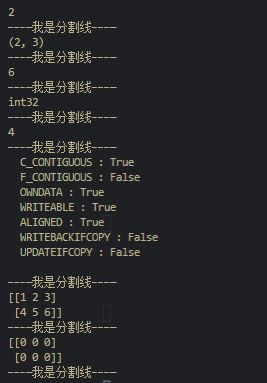
print (a.ndim)
print ("————我是分割线————")
print (a.shape)
print ("————我是分割线————")
print (a.size)
print ("————我是分割线————")
print (a.dtype)
print ("————我是分割线————")
print (a.itemsize)
print ("————我是分割线————")
print (a.flags)
print ("————我是分割线————")
print (a.real)
print ("————我是分割线————")
print (a.imag)
print ("————我是分割线————")
NumPy 也提供了 reshape 函数来调整数组大小
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
b = a.reshape(3,2)
print (b)

NumPy 创建数组
NumPy 创建新数组
ndarray 数组除了可以使用底层 ndarray 构造器来创建外,也可通过以下几种方式创建。

代码示例
import numpy as np
# 格式:numpy.empty(shape, dtype = float, order = 'C')
# order有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。
x1 = np.empty([3,2], dtype = int)
# 输出的数组元素为随机值,因为它们未初始化
# 格式:numpy.zeros(shape, dtype = float, order = 'C')
x2 = np.zeros(5) # 默认为浮点数
# x3 = np.zeros((5,), dtype = np.int) # 设置类型为整数,这个语句提示警告?
x4 = np.zeros((2,2), dtype = [('x', 'i4'), ('y', 'i4')]) # 自定义类型
# 格式:numpy.ones(shape, dtype = None, order = 'C')
x5 = np.ones(5) # 默认为浮点数
x6 = np.ones([2,2], dtype = int) # 自定义类型
print (x1)
print (x2)
# print (x3)
print (x4)
print (x5)
print (x6)
NumPy 从已有的数组创建数组

numpy.asarray用法示例如下:
import numpy as np
# 格式:numpy.asarray(a, dtype = None, order = None)
x1 = [1,2,3]
a1 = np.asarray(x1) #将列表转换为 ndarray
x2 = (1,2,3)
a2 = np.asarray(x2) #将元组转换为 ndarray
x3 = [(1,2,3),(4,5)]
a3 = np.asarray(x3) #将元组列表转换为 ndarray
x4 = [1,2,3]
a4 = np.asarray(x4, dtype = float) #设置了 dtype 参数
print (a1)
print ("————我是分割线————")
print (a2)
print ("————我是分割线————")
print (a3)
print ("————我是分割线————")
print (a4)
print ("————我是分割线————")

后面两种方法示例如下:
【这一部分没理解清楚……】
import numpy as np
#格式:numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)
#buffer 是字符串的时候,Python3 默认 str 是 Unicode 类型,所以要转成 bytestring 在原 str 前加上 b。
s = b'Hello World'
a = np.frombuffer(s, dtype = 'S1')
print (a)
#格式:numpy.fromiter(iterable, dtype, count=-1)
list=range(5) # 使用 range 函数创建列表对象
it=iter(list)
x=np.fromiter(it, dtype=float) # 使用迭代器创建 ndarray
print(x)
![]()
NumPy 从数值范围创建数组

numpy.arange的用法展示
import numpy as np
# 格式:numpy.arange(start=0, stop【不包含】, step=1, dtype【输入类型】)
x1 = np.arange(5) #生成 0 到 5 的数组
x2 = np.arange(5, dtype = float) #此处一定要写 dtype = 类型
x3 = np.arange(10,20,2) #设置了起始值、终止值及步长
print (x1)
print (x2)
print (x3)
numpy.linspace的用法展示
等差数列是否包含最后一个数都要先算公差,再去判断
import numpy as np
# 格式:np.linspace(start, stop, num=50, endpoint=True[包含stop值], retstep=False[不显示间距], dtype=None)
a1 = np.linspace(1,10,10)
a2 = np.linspace(1,1,10) #设置元素全部是1的等差数列
a3 = np.linspace(10, 20, 5, endpoint = False) #将 endpoint 设为 false,不包含终止值:
a4 = np.linspace(10, 20, 5, endpoint = True) #如果将 endpoint 设为 true,则会包含 20
print(a1)
print("-----------------分割线-----------------------")
print(a2)
print("-----------------分割线-----------------------")
print(a3)
print("-----------------分割线-----------------------")
print(a4)
print("-----------------分割线-----------------------")
b =np.linspace(1,10,10).reshape([10,1]) #设置间距
print(b)

numpy.logspace的用法展示
import numpy as np
# 格式:np.logspace(start, stop, num=50, endpoint=True, base=10.0[对数的底数], dtype=None)
a = np.logspace(0,9,10,base=2) #将对数的底数设置为 2
print (a)
![]()

NumPy 切片和索引
索引是从0开始的!

import numpy as np
a = np.arange(10)
#从索引 2 开始到索引 7 停止,间隔为 2
s = slice(2,7,2) # slice 函数切片法
print (a[s])
b = a[2:7:2] # 冒号分隔切片法
print(b)
![]()

import numpy as np
#各种切片索引
a = np.arange(10) # [0 1 2 3 4 5 6 7 8 9]
print(a[5])
print("-----------------分割线-----------------------")
print(a[2:5])
print("-----------------分割线-----------------------")
print(a[2:])
print("-----------------分割线-----------------------")
print(a[:5])
print("-----------------分割线-----------------------")
#多维数组同样适用上述索引提取方法
b = np.array([[1,2,3],[3,4,5],[4,5,6]])
print(b)
# 从某个索引处开始切割
print('从数组索引 a[1:] 处开始切割')
print(b[1:])
print("-----------------")
print(b[1:][1])
print("-----------------")
print(b[1:][1][1:2])
print("-----------------")
print(b[1:][1][1]) #这里自己去实验体会一下叭

import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
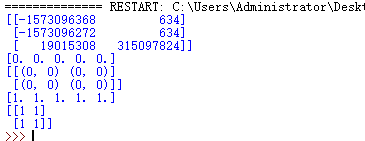
print (a[...,1]) # 第2列元素
print (a[1,...]) # 第2行元素
print (a[...,1:]) # 第2列及剩下的所有元素


NumPy高级索引
【这个记录一下大纲,还没有仔细理解】


NumPy 广播(Broadcast)
广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。
如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同
当运算中的 2 个数组的形状不同时,numpy 将自动触发广播机制。

例如:
import numpy as np
a = np.array([[ 0, 0, 0],
[10,10,10],
[20,20,20],
[30,30,30]])
b = np.array([1,2,3])
print(a + b)

广播的规则

NumPy 迭代数组
NumPy 迭代器对象 numpy.nditer 提供了一种灵活访问一个或者多个数组元素的方式。
迭代器最基本的任务的可以完成对数组元素的访问。
import numpy as np
a = np.arange(6).reshape(2,3)
print ('原始数组是:')
print (a)
print ('\n')
print ('迭代输出元素:')
for x in np.nditer(a):
print (x, end=", " )
print ('\n')
print ('转置后迭代输出元素:')
for x in np.nditer(a.T):
print (x, end=", " )
print ('\n')
print ('复制后迭代输出元素:')
for x in np.nditer(a.T.copy(order='C')): #置定按行
print (x, end=", " )
print ('\n')
for x in np.nditer(a, order=‘F’):Fortran order,即是列序优先;
for x in np.nditer(a.T, order=‘C’):C order,即是行序优先;
从上述例子可以看出 :a 和 a.T 的遍历顺序是一样的,也就是他们在内存中的存储顺序也是一样的,但a.T.copy(order = ‘C’) 的遍历结果是不同的,那是因为它和前两种的存储方式是不一样的,默认是按行访问
可以通过显式设置,来强制 nditer 对象使用某种顺序:
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print ('原始数组是:')
print (a)
print ('\n')
print ('以 C 风格顺序排序:')
for x in np.nditer(a, order = 'C'):
print (x, end=", " )
print ('\n')
print ('以 F 风格顺序排序:')
for x in np.nditer(a, order = 'F'):
print (x, end=", " )
修改数组中元素的值
nditer 对象有另一个可选参数 op_flags。 默认情况下,nditer 将视待迭代遍历的数组为只读对象(read-only),为了在遍历数组的同时,实现对数组元素值得修改,必须指定 read-write 或者 write-only 的模式。
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print ('原始数组是:')
print (a)
print ('\n')
print ('修改后的数组是:')
for x in np.nditer(a, flags = ['external_loop'], order = 'F'):
print (x, end=", " )
使用外部循环
nditer类的构造器拥有flags参数,它可以接受下列值:

广播迭代
如果两个数组是可广播的,nditer 组合对象能够同时迭代它们。 假设数组 a 的维度为 3X4,数组 b 的维度为 1X4 ,则使用以下迭代器(数组 b 被广播到 a 的大小)。
总结
numpy.copy 做了特殊处理,它拷贝的时候不是直接把对方的内存复制,而是按照上面 order 指定的顺序逐一拷贝。
flags = [‘external_loop’],当数组的 order 与在循环中指定的 order 顺序不同时,打印为多个一维数组,当相同时,是整个一个一维数组。
Numpy 数组操作
代码中的[ xxxx ] 都是补充说明,运行测试代码时请删除
修改数组形状

numpy.reshape 函数可以在不改变数据的条件下修改形状,格式如下:
#numpy.reshape(arr[原数组], newshape[新形状], order='C'[存储顺序])
#例如:
a = np.arange(8)
b = a.reshape(4,2)
numpy.ndarray.flat 对数组中每个元素都进行处理,可以使用flat属性,该属性是一个数组元素迭代器,可以按存储顺序遍历每一个数组元素,格式如下:
for element[可输出元素] in a.flat[调用方式]:
#用一个for循环遍历
numpy.ndarray.flatten 返回一份数组拷贝[一维数组],对拷贝所做的修改不会影响原始数组,格式如下:
ndarray.flatten(order='C')
#order:'C' -- 按行,'F' -- 按列,'A' -- 原顺序,'K' -- 元素在内存中的出现顺序。
numpy.ravel() 展平的数组元素,顺序通常是"C风格",返回的是数组视图(view),修改会影响原始数组。【感觉更像数据库里的外模式,直观上和flatten效果一致?】,格式如下:
numpy.ravel(a, order='C')
翻转数组

numpy.transpose 函数用于对换数组的维度,格式如下:
numpy.transpose(arr[操作数组], axes[默认转置,整数列表,对应维度])
numpy.ndarray.T 类似 numpy.transpose,直接就转置
numpy.rollaxis 函数向后滚动特定的轴到一个特定位置,格式如下:
numpy.rollaxis(arr[操作数组], axis[轴], start[默认为零,表示完整的滚动。会滚动到特定位置])
关于这个轴?感觉还是不太能理解。
轴的滚动就是下标的滚动【直接把下标换了?】
参考一下其他博客来理解
- 把特定的轴向后滚动,直到它到达指定的位置;
- 滚动后,其他轴与其他轴之间的相对位置不变。

import numpy as np
# 创建了三维的 ndarray
a = np.arange(8).reshape(2,2,2)
print ('原数组:')
print (a)
print ('获取数组中一个值:')
print(np.where(a==6))
print(a[1,1,0]) # 为 6
print ('\n')
# 将轴 2 滚动到轴 0(宽度到深度)
print ('调用 rollaxis 函数:')
b = np.rollaxis(a,2,0)
print (b)
# 查看元素 a[1,1,0],即 6 的坐标,变成 [0, 1, 1]
# 最后一个 0 移动到最前面
print(np.where(b==6))
print ('\n')
# 将轴 2 滚动到轴 1:(宽度到高度)
print ('调用 rollaxis 函数:')
c = np.rollaxis(a,2,1)
print (c)
# 查看元素 a[1,1,0],即 6 的坐标,变成 [1, 0, 1]
# 最后的 0 和 它前面的 1 对换位置
print(np.where(c==6))
print ('\n')
import numpy as np
# 三维数组 想象成魔方
a = np.arange(8).reshape(2, 2, 2)
print(a)
print('-----------看顶部 整个右转')
print(np.rollaxis(a, 2))
print('-------------看顶部 平面右转')
print(np.rollaxis(a, 2, 1))