第六届中文语法错误诊断大赛,哈工大讯飞联合实验室再获多项冠军
来自:哈工大讯飞联合实验室
近日,第六届中文语法错误诊断大赛(CGED)研讨会于AACL 2020大会的“面向教育技术的自然语言处理(NLPTEA)”workshop中顺利举行。今年共有国内外14支队伍参赛,提交了44个系统。讯飞、阿里、上交、南大、有道、外研社、新华社等团队均有精彩表现。其中,哈工大讯飞联合实验室(下文简称HFL)团队获得综合排名第一的成绩,多项核心指标保持领先。
A.I.也能改作文,我们拿下多项冠军!

中文语法错误诊断大赛官方网页
曾经,语文老师批改作文的场景还历历在目——从文章里找出赘余、少词、语序不当、语意不通的地方,然后一一改正。
最近,这场世界级比赛就把上述场景作为考点——第6届中文语法错误诊断大赛(CGED)。主办方会挑选外国人写作的中文句子作为考题,参赛团队需要利用A.I.算法技术对其中的语法语义错误进行识别,对部分类别错误进行修正,并进行系统性能评估。

可别小看了这场“语法批改大赛”,它所考验的能力十分综合。涉及到参赛队伍的语病识别能力(识别句子是否有错误)、语病分类能力(识别具体的错误类型)、语病定位能力(识别错误的位置和类型)、语病修正能力(对于缺失和用词不当,提供修正建议)等等。

语病错误类型举例表
最终,在语病识别、语病分类、语病定位、语病修正四类核心指标中,HFL在两项关键指标中获取冠军,另外获得一项第二和一项第三。这也是继上一届大赛(CGED2018)夺冠后(https://mp.weixin.qq.com/s/1vTyx-RpQ3TxdptDpxWCdA),持续保持技术领先的又一份成绩单。
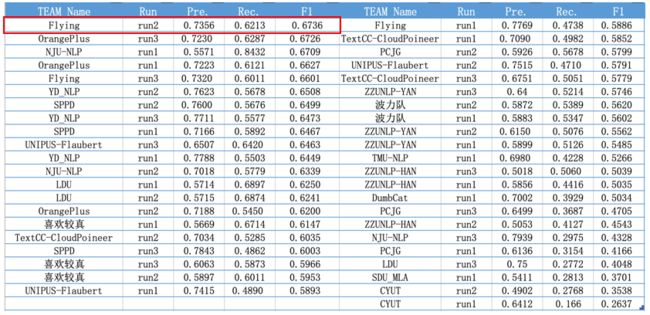
CGED 2020 Identification-level指标情况

CGED 2020 Position-level指标情况

CGED 2020 Correction top1 指标情况
纵观最近几年的比赛成绩,中文语法检错技术不断进步,检错效果在不断提升。

为什么最近几年的语法检错水平提升显著?
原来,随着深度学习相关技术的快速发展,越来越适合任务本身的模型被研究出来;并且随着预训练语言模型的发展,更多的外部知识被加入到模型中,使得模型的表征能力越来越强。HFL就是以深度学习技术与预训练语言模型为基础,结合集成学习相关技术,完成对语病的精准识别、定位与修正。
真题实战,看看这位A.I.冠军如何修炼
本次HFL参赛评测方案,主要分为检测和修正两部分,相关工作发表在NLPTEA 2020 workshop中,论文题目为《Combining ResNet and Transformer for Chinese Grammatical Error Diagnosis》。
在检测任务中,我们提出了ResBERT模型,在BERT模型基础上融入残差网络,增强输出层中每个输入字的信息,使模型可以更好地检测语法错误位置。

ResBERT模型结构图
在修正任务中,由于序列标注模型无法直接给出语法错误的修正结果,我们针对缺失错误和用词不当错误分别采用如下两种方法进行修正:针对缺失错误,我们首先预测缺失位置缺失的字数,然后再使用BERT语言模型生成修正候选结果,最后通过比较多个候选修正句子的困惑度来确定缺失修正结果。针对用词不当错误,我们使用RoBERTa模型选取候选字,然后再综合考虑字音、字形相似度以及语言模型打分来选出最终的修正结果。
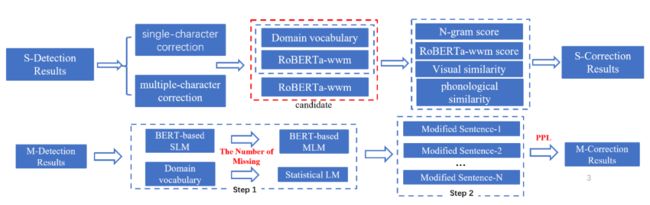
修正技术框架图
当然,我们看到今年的比赛中语病修正的指标还很低,最高的F1值也未超过0.2,原因是什么呢?我们分析评测数据来看,数据以单句形式给出,比如“那个时候我尝尝去美术馆参观画。”语病修正的参考答案为:将“尝尝”改为“尝试”,而合理的修正方法其实有很多种,比如也可以改成“常常”等。仅通过单句的信息,无法确定唯一的修正结果,需要更多的上下文信息才能确定作者所要表达的真实意图。这给评测数据的构建也提出了不小的挑战。
因此,要想提升语病修正的效果并在实际产品中应用,对于篇章级文本的诊断分析是非常有必要的,这也给未来的评测和技术提出了更高的要求。
技术落地应用,我们让A.I.走得更远
在坚持核心技术研究不断创新进步的同时,我们也不断让A.I.赋能于应用,服务于生活的方方面面。
多种办公场景下,人们长时间从事文字工作难免出错。无论是撰写文档,还是在信息共享与储存场景中,当前流行的办公工具对中文文本校对未能提供很好支持,智能办公亟待升级。
HFL基于长期以来的技术积累,早在2019年12月1日,便正式发布了“飞鹰智能文本校对系统”:http://202.85.216.21:8095/review。
飞鹰校对涵盖文本校对的别字纠错、语法纠错、标点纠错及敏感词检测等不同校对模块,并且可针对不同领域的文本校对需求,为行业客户提供定制化的解决方案,现已支持通用领域、司法领域和教育领域文本校对服务。
最近这项技术也在讯飞开放平台上线,为广大开发者提供文本纠错能力,欢迎体验(https://mp.weixin.qq.com/s/wXrHcv2sLYASCgx6Su4IlA)。
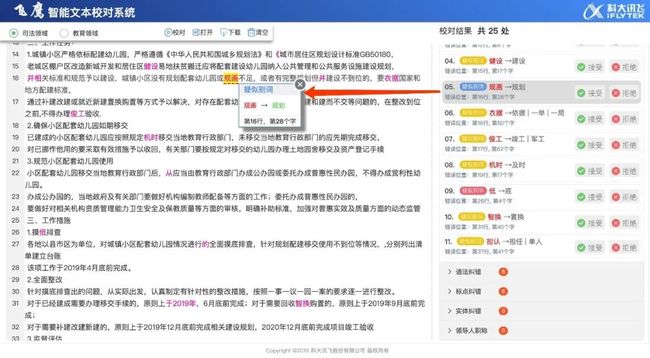
飞鹰智能文本校对系统
此外,中文语法错误诊断技术还被应用于作文自动批改中,包括错别字修正、语法检错等功能,目前已在中小学作业、讯飞学习机等产品中应用落地,辅助减轻老师作文批改的工作负担,也可以帮助学生在自主学习中及时获得作文批改的反馈。

科大讯飞作文自动批改
未来,随着技术的不断进步,以中文语法错误诊断与修正技术为核心的文本校对将在编辑出版、公文撰写、作文批改以及广大自媒体文稿写作等场景中发挥越来越大的作用,应用前景广阔。
•••
布局讯飞超脑,HFL让机器能理解会思考
哈工大讯飞联合实验室(HFL)是科大讯飞针对“讯飞超脑”项目计划,重点引进和布局的核心研发团队之一,成立于2014年,由哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)与科大讯飞AI研究院共同创办。
根据联合实验室建设规划,双方在语言认知计算领域进行长期、深入合作,具体开展阅读理解、自动阅卷、类人答题、人机对话、语音识别后处理、社会舆情计算等前瞻课题的研究,支撑科大讯飞实现从“能听会说”到“能理解会思考”的技术跨越,并围绕教育、司法、人机交互等领域实现科研成果的规模化应用与落地。
2017年至2019年,哈工大讯飞联合实验室在国际权威机器阅读理解评测SQuAD、SQuAD 2.0多次获得冠军。其中2019年3月,在SQuAD 2.0评测中全球首次超过人类平均水平并成为里程碑事件。2018年获得国际语义评测(SemEval 2018)阅读理解赛道冠军。2019年至2020年,在多步推理阅读理解评测HotpotQA双赛道均获得冠军。2020年,在国际权威通用自然语言理解评测GLUE中获得冠军。
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
后台回复【五件套】
下载二:南大模式识别PPT
后台回复【南大模式识别】
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
专辑 | NLP论文解读
专辑 | 情感分析
整理不易,还望给个在看!