目标检测中YOLOv1、YOLOv1、YOLOv3算法介绍
一、YOLOv1算法介绍
1、YOLOv1简介
是one-stage系列中的一种,把检测问题转化到回归上来,一个CNN即可完成检测流程。
2、算法结构
① 他的核心思想就是利用整张图作为网络的输入,将目标检测作为回归问题解决,直接在输出层回归预选框的位置以及所属的类别,YOLO最左边是一个inceptionV1网络,共20层。但作者对inceptionV1进行了改造,他没有使用inception模块,而是用一个1x1的卷积并联一个3x3的卷积来代替。inceptionV1提取出的特征图再经过4个卷积层和2个全连接层,最后生成7x7x30的输出。

② YOLO将一副448x448的原图分割成了7x7=49个网络,每个网格要预测两个bounding box的坐标(x,yw,h)和box内是否包含物体的置信度confidence(每个bounding box有一个confidence),以及物体属于20类别中每一类的概率(YOLO的训练集数据为voc2012,是个20分类的数据集)。所以一个网格对应一个(4x2+2+20)=30维的向量。
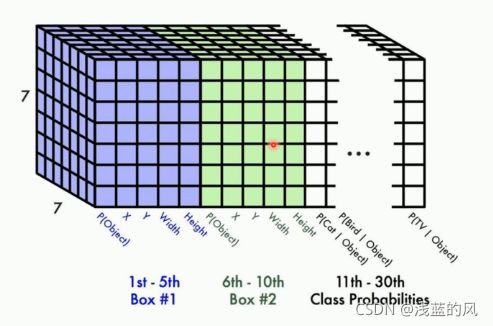
③ 7x7网格内的每个grid(红色框),对应两个大小形状不同的bounding box(黄色框)。每个box的位置为(x,y,w,h),x和y表示box中心点与该格子边界的相对值,w和h表示预测box的宽和高相对与整幅图像的宽度和高度的比例。(x,y,w,h)会限制在[0,1]之间。与训练数据集上标定的物体真实坐标(Gx,Gy,Gw,Gh)进行对比训练,每个grid负责检查中心点落在该格子的物体。这个置信度只是为了表达box有无物体的概率(类似于Faster-RCNN中的rpn层的softmax预测anchor是前景还是背景的概率),并不预测box内物体属于哪一类。
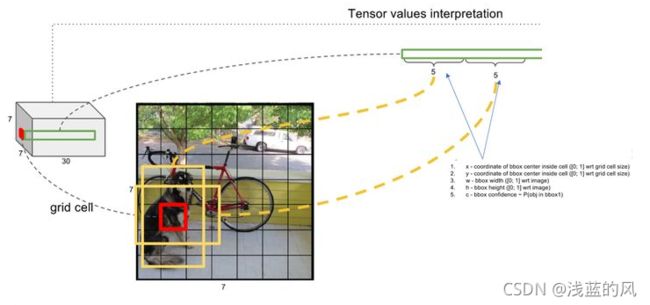
2、confidence置信度
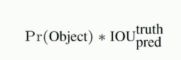
其中前一项表示有无人工标记的物体落入了网格内,如果有则为1,否则为0,第二项表示bounding box和真实标记的box之间的IOU,值越大则box越接近真实位置。confidence是针对bounding box的,每个网格有两个bounding box,所以每个网络会有两个confidence与之对应。
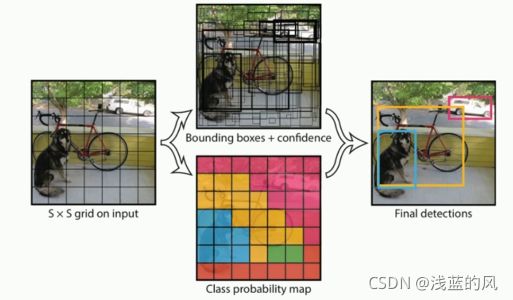
3、YOLOv1预测工作流程
① 每个格子得到两个bounding box
② 每个网格预测的class信息和bounding box预测的confidence信息相乘,得到了每个bounding box预测物体的概率和位置重叠的概率PrIoU
③ 对于每个类别,对于PrIoU进行排序,去除小于阈值的PrIoU,,然后做非极大值抑制
4、 YOLO的loss函数
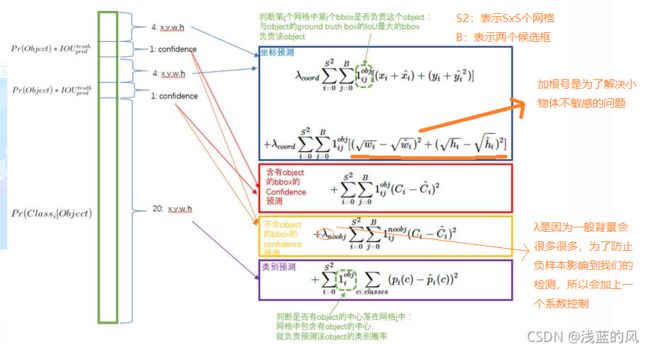
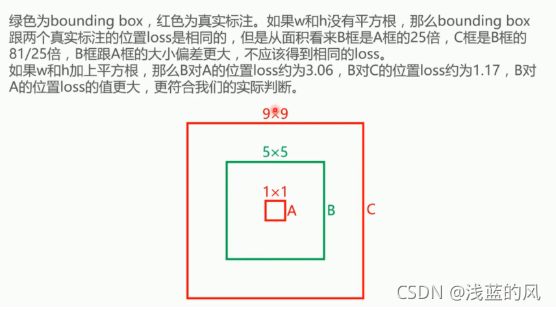
5、YOLOv1缺点
① 每个cell只预测一个类别,如果重叠无法解决
② 小物体检测一般,长宽比可选但单一
二、YOLOv2算法介绍
注:此处只讲优化点
1、YOLOv2的细节优化
① Batch Normalization
V2版本舍弃了Dropout,卷积后全部加入了Batch Normalization,网络的每一层的输入都做了归一化,收敛相对更容易。从现在的角度来看,Batch Normalization已经成网络必备处理。
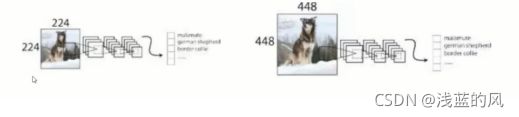
② 使用更大的分辨率
V1训练使用的是224x224,测试时使用448x448,可能导致模型水土不服,V2训练时额外又进行了10次448x448的微调,使用高分辨率。
③ 基于k-means来选择先验框的尺寸
faster-rcnn系列选择的先验框比例都是常规的,但是不一定完全适合数据集;
K-means聚类中的距离:
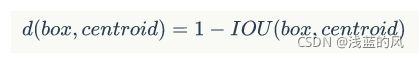
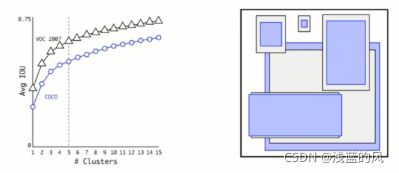
在论文中作者的K=5是最合适的,其实K越大说明每个聚类的差异越小。
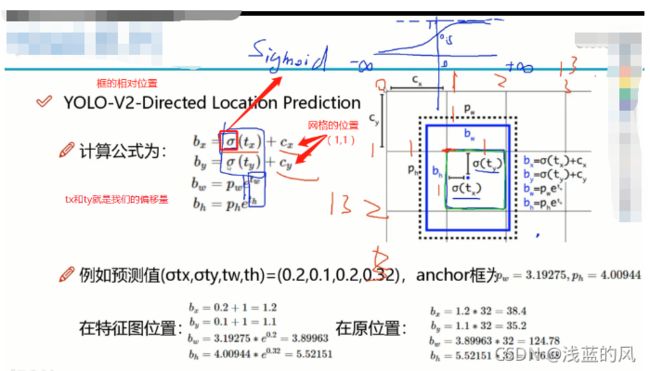
④ 直接位置预测

⑤特征融合
最后一层感受野太大了,小目标可能丢失,需要融合之前的特征

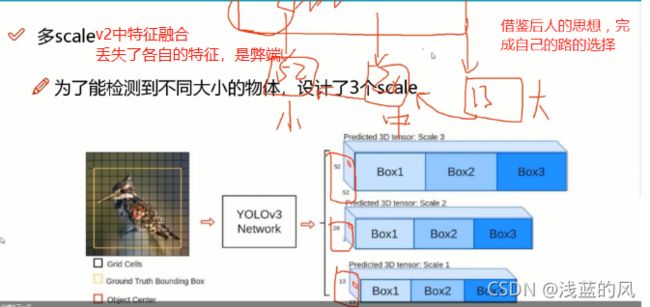
⑥ 多尺度

三、YOLOv3算法介绍
1、特点:
① 对网络结构做了改进,使其更适合小目标检测
② 特征做的更细致,融入了多持续特征图信息来预测不同规格物体
③ 先验框更丰富,3个scale,每种3个规格,一共9中
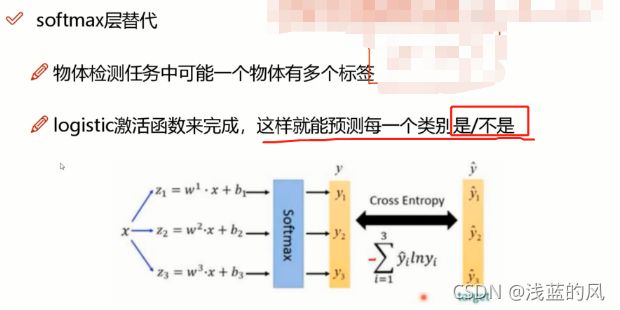
④ softmax改进,预测多标签任务
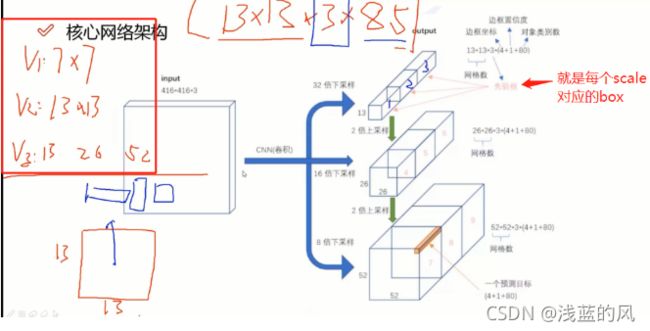
2、多尺度

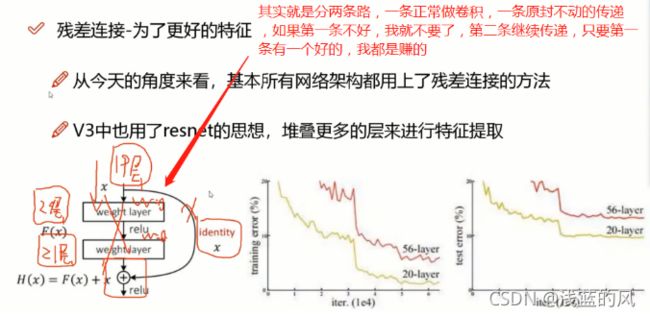
3、残差连接方法解读
4、整体网络模型架构分析
① 没有池化和全连接层,全部卷积
② 下采样通过stride为2实现
③ 3中scale,更多先眼眶


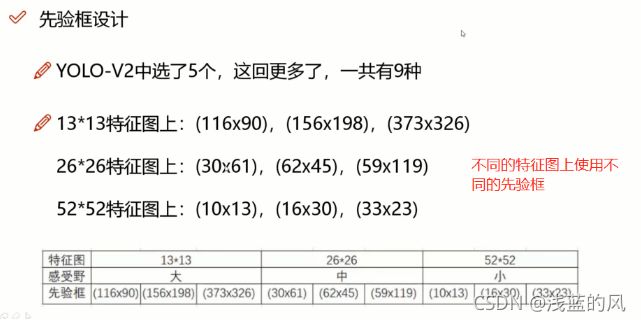
5、先验框设计改进
6、softmax层改进
三、拓展-DIoU边框回归loss计算
1、距离交并比
在YOLOv3中,交并比(Intersection over Union,IoU)作为衡量边界框置信度的评价指标,但是IoU存在明显的不足:无法衡量两个边界框的距离,不能反映两者的相交方式。而IoULoss仅与两框的交并比以及相交面积相关。当两框相交面积相同时,IoULoss 相等,无法给出预测框和真实框的重合度;当两框不相交时,IoU loss为零,无法优化边界框。故无法准确衡量位置信息,降低模型的性能。
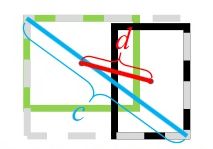
故就有了距离交并比(Distance-IoU, DIoU)代替IoU 作为评价边界框位置的参数,同时使用DIoU Loss 作为边界框位置预测的损失函数。DIoU 示意图如图4 所示,其中d 为两个候选框中心点之间的距离,c 为两框最小外接矩形的对角线距离。
2、公式介绍
DIoU在IoU的基础上加入一个包含边界框和真实框的最小凸包。DIoU公式定义如下:
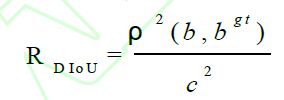
上式中ρ 代表两个框中心点之间的欧氏距离,b、bgt 分别代表两个候选框的中心点。c代表的是可以同时覆盖Anchor框和目标框的最小矩形的对角线距离为当两框的DIoU 值越大时,DIoU Loss 就越小。当边界框与目标框全部重合时,LDIoU = 0;当两框相距很进时,LDIoU = 2;所以能够更好地反应两框之间的重合度。DIoU Loss 公式定义如下:
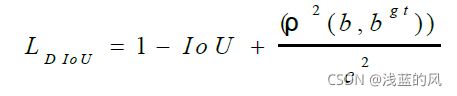
利用DIoU Loss 作为损失函数,当边界框与目标框不相交的情况,仍然可以为边界框提供更准确的移动方向。由于DIoU Loss 直接限制的是两个框的距离,因此会使模型收敛很快。对于两框包含的情况,DIoU Loss 仍可以
使回归快。同时利用DIoU 代替IoU 作为评价参数,当边界框与真实框上下或左右相邻时,DIoU 能够优化不相交的边界框,保留位置更准确的边界框,提高模型对目标位置预测的精确度,使其通过非极大值抑制筛选得到的结果更加合理。