Hadoop中常见组件的常用命令:Hadoop、Flume、Hive、Zookeeper、Hbase、Spark、Kafka、Redis、Flink
一、Hadoop
(1)启动
start-all.sh
(2)停止
stop-all.sh
(3)查看进程
jps
jps -m
ps -ef |grep 进程名称

(4)查看History
1)启动historyserver进程
mapred --daemon start historyserver
2)开启日志聚合功能
vi yarn-site.xml 新增如下内容:
yarn.log-aggregation-enable
true
yarn.log.server.url
http://bigdata01:19888/jobhistory/logs/
注意:需要重启集群
1、hdfs
hdfs dfs -ls /
hdfs dfs -put hello.txt /
hdfs dfs -cat /hello.txt
hdfs dfs -get /hello.txt ./
hdfs dfs -mkdir -p /test/hello
hdfs dfs -ls -R /
hdfs dfs -rm -r /test/hello
hdfs dfs -rm /hello.txt
# 统计根目录下文件的个数
hdfs dfs -ls / |grep /| wc -l
# 统计根目录下每个文件的大小,最终把文件名称和大小打印出来
hdfs dfs -ls / |grep / | awk '{print $8,$5}'
2、MapReduce
(1)提交MapReduce任务
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCountJob /test/hello.txt /out
hadoop:表示使用hadoop脚本提交任务,其实在这里使用yarn脚本也是可以的,从hadoop2开始支持使用yarn,不过也兼容hadoop1,也继续支持使用hadoop脚本,所以在这里使用哪个都可以,具体就看你个人的喜好了,我是习惯于使用hadoop脚本
jar:表示执行jar包
db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar:指定具体的jar包路径信息
com.imooc.mr.WordCountJob:指定要执行的mapreduce代码的全路径
/test/hello.txt:指定mapreduce接收到的第一个参数,代表的是输入路径,这里的输入路径可以直接指定hello.txt的路径,也可以直接指定它的父目录,因为它的父目录里面也没有其它无关的文件,如果指定目录的话就意味着hdfs会读取这个目录下所有的文件,所以后期如果我们需要处理一批文件,那就可以把他们放到同一个目录里面,直接指定目录即可。
/out:指定mapreduce接收到的第二个参数,代表的是输出目录,这里的输出目录必须是不存在的,MapReduce程序在执行之前会检测这个输出目录,如果存在会报错,因为它每次执行任务都需要一个新的输出目录来存储结果数据
(2)命令查看日志方式
yarn logs -applicationId application_1587713567839_0001
yarn logs -applicationId application_1587713567839_0001 | grep k1,v1
(3)停止Hadoop集群中的任务
yarn application -kill application_1587713567839_0003
3、Yarn
(1)YARN多资源队列配置和使用
修改集群中etc/hadoop目录下的capacity-scheduler.xml配置文件
[root@bigdata01 hadoop]# vi capacity-scheduler.xml
yarn.scheduler.capacity.root.queues
default,online,offline
队列列表,多个队列之间使用逗号分割
yarn.scheduler.capacity.root.default.capacity
70
default队列70%
yarn.scheduler.capacity.root.online.capacity
10
online队列10%
yarn.scheduler.capacity.root.offline.capacity
20
offline队列20%
yarn.scheduler.capacity.root.default.maximum-capacity
70
Default队列可使用的资源上限.
yarn.scheduler.capacity.root.online.maximum-capacity
10
online队列可使用的资源上限.
yarn.scheduler.capacity.root.offline.maximum-capacity
20
offline队列可使用的资源上限.
二、Flume
1、启动flume任务方式1:
flume-ng agent --name a1 --conf conf --conf-file conf/example.conf -Dflume.root.logger=INFO,console
后面指定agent,表示启动一个Flume的agent代理
--name:指定agent的名字
--conf:指定flume配置文件的根目录
--conf-file:指定Agent对应的配置文件(包含source、channel、sink配置的文件)
-D:动态添加一些参数,在这里是指定了flume的日志输出级别和输出位置,INFO表示日志级别,console表示是控制台的意思,也就是说默认会把日志数据打印到控制台上,方便查看,一般在学习测试阶段会指定这个参数
2、启动flume任务方式2:
flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
这里面的-n属于简写,完整的写法就是–name
-c完整写法的–conf
-f完整写法是–conf-file
3、后台启动
nohup bin/flume-ng agent --name a1 --conf conf --conf-file conf/example.conf &
4、查看进程
jps
出现:Application
或者使用
jps -m
信息更加详细:Application --name a1 --conf-file conf/example.conf
或者使用
ps -ef|grep flume
root 9581 1500 0 10:54 pts/0 00:00:00 /data/soft/jdk1.8/bin/java -Xmx20m -cp /data/soft/apache-flume-1.9.0-bin/conf:/data/soft/apache-flume-1.9.0-bin/lib/*:/lib/* -Djava.library.path= org.apache.flume.node.Application --name a1 --conf-file conf/example.conf
root 9672 1500 0 10:57 pts/0 00:00:00 grep --color=auto flume
三、Hive
1、连接方式1
hive
2、连接方式2
要开启hiveserver2才能连接进去
开启hiveserver2
hiveserver2
然后进行连接
beeline -u jdbc:hive2://localhost:10000
beeline -u jdbc:hive2://192.168.18.100:10000
beeline -u jdbc:hive2://localhost:10000 -n root
beeline -u jdbc:hive2://localhost:10000 -n root
3、hive -e命令
hive -e "select * from t1"
四、Zookeeper
1、启动
zkServer.sh start
2、停止
zkServer.sh stop
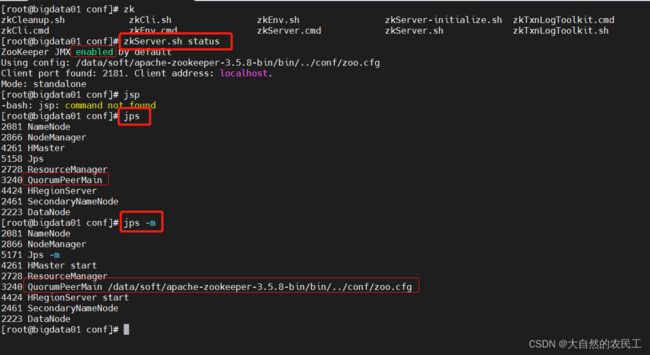
3、查看进程
zkServer.sh status
或者
jps
jps -m
4、连接到zookeeper
zkCli.sh
五、Hbase
1、启动
start-hbase.sh
2、停止
stop-hbase.sh
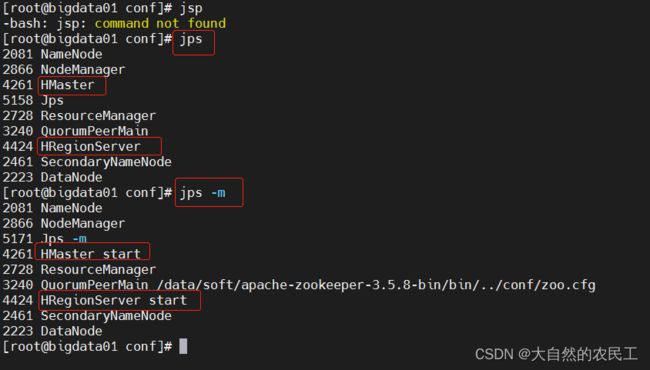
3、验证
jps
jps -m
web页面:
http://bigdata01:16010/
4、HBase的shell命令行
hbase shell

六、Scala
无常用命令
七、Spark
1、standalone模式
(1)启动
注意,这里的start-all.sh和hadoop注意区别。
cd /data/soft/spark-2.4.3-bin-hadoop2.7
sbin/start-all.sh
(2)停止
cd /data/soft/spark-2.4.3-bin-hadoop2.7
sbin/stop-all.sh
(3)验证
jps
Master进程、Worker进程
web页面:
http://bigdata01:8080/
(4)提交任务
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://bigdata01:7077 examples/jars/spark-examples_2.11-2.4.3.jar 2
2、on yarn模式
无需启动,可以直接提交任务。
(1)提交任务
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.11-2.4.3.jar 2
3、spark任务提交几种方式
(1)idea
方便在本地环境调试代码
(2)spark-submit
使用spark-submit提交到集群执行,实际工作中会使用这种方式
[root@bigdata04 sparkjars]# vi wordCountJob.sh
spark-submit \
--class com.imooc.scala.WordCountScala \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--num-executors 1 \
db_spark-1.0-SNAPSHOT-jar-with-dependencies.jar \
hdfs://bigdata01:9000/test/hello.txt
(3)spark-shell
这种方式方便在集群环境中调试代码
spark-shell
4、Spark Job的三种提交模式【spark-submit】
(1)standalone模式基于Spark自己的standalone集群。
指定–master spark://bigdata01:7077
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://bigdata01:7077 examples/jars/spark-examples_2.11-2.4.3.jar 2
(2)是基于YARN的client模式。
指定–master yarn --deploy-mode client
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client examples/jars/spark-examples_2.11-2.4.3.jar 2
(3)是基于YARN的cluster模式。【推荐】
指定–master yarn --deploy-mode cluster
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.11-2.4.3.jar 2
八、Kafka
1、启动
bin/kafka-server-start.sh -daemon config/server.properties
2、停止
3、验证
jps
4、新增topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --partitions 2 --replication-factor 2 --topic hello
5、查看topic
bin/kafka-topics.sh --list --zookeeper localhost:2181
6、查看指定topic
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic hello
7、修改topic
注:只能增加
bin/kafka-topics.sh --alter --zookeeper localhost:2181 --partitions 5 --topic hello
8、查看topic详细信息
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic hello
9、删除topic
删除Kafka中的指定Topic
bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic hello
10、向这个topic中生产数据
(1)创建一个topic【5个分区,2个副本】
[root@bigdata01 kafka_2.12-2.4.1]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --partitions 5 --replication-factor 2 --topic hello
Created topic hello.
(2)向这个topic中生产数据
[root@bigdata01 kafka_2.12-2.4.1]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic hello
>hehe
(3)创建一个消费者消费topic中的数据
# 默认消费最新的数据
[root@bigdata01 kafka_2.12-2.4.1]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic hello
# 从头消费
[root@bigdata01 kafka_2.12-2.4.1]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic hello --from-beginning
hehe
九、Redis
1、启动
redis-server redis.conf
2、验证
ps -ef|grep redis
3、连接
redis-cli
4、停止
[root@bigdata04 redis-5.0.9]# redis-cli
127.0.0.1:6379> shutdown
not connected>
或者
[root@bigdata04 redis-5.0.9]# redis-cli shutdown
十、Flink
1、standalone
(1)启动
bin/start-cluster.sh
(2)验证
jps
(3)停止
bin/stop-cluster.sh
2、flink on yarn
Flink ON YARN两种使用方式
(1)第一种
1)描述
在Yarn中初始化一个Flink集群,以后提交任务都提交到这个Flink集群中,这个Flink集群会常驻在Yarn集群中,除非手工停止。
2)适合场景
适合运行规模小,短时间运行的作业。
3)在集群中初始化一个长时间运行的Flink集群
使用yarn-session.sh脚本
bin/yarn-session.sh -jm 1024m -tm 1024m -d
4)使用flink run命令向Flink集群中提交任务
bin/flink run ./examples/batch/WordCount.jar
5)停掉Flink集群,使用yarn的kill命令
yarn application -kill application_1768906309581_0005
(2)第二种
1)描述
每次提交任务都会创建一个新的Flink集群,任务之间互相独立,互不影响,方便管理,任务执行完成后创建的集群也会消失。
2)适合场景
适合长时间运行的作业
3)flink run -m yarn-cluster (创建Flink集群+提交任务)
bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar
bin/flink run -m yarn-cluster -c com.imooc.scala.SocketWindowWordCountScala -yjm 1024 -ytm 1024 db_flink-1.0-SNAPSHOT-jar-with-dependencies.jar
十一、Elasticsearch
1、启动
(1)前台启动
bin/elasticsearch
(2)后台启动
bin/elasticsearch -d
2、验证
jps
web页面:
http://bigdata01:9200/
3、核心日志
ES的相关日志都在ES_HOME的logs目录下,ES服务的核心日志在elasticsearch.log日志文件中。
[root@bigdata01 elasticsearch-7.13.4]# cd logs/
[root@bigdata01 logs]# ll
total 208
-rw-rw-r--. 1 es es 0 Feb 26 10:48 elasticsearch_audit.json
-rw-rw-r--. 1 es es 554 Feb 26 11:20 elasticsearch_deprecation.json
-rw-rw-r--. 1 es es 332 Feb 26 11:20 elasticsearch_deprecation.log
-rw-rw-r--. 1 es es 0 Feb 26 10:48 elasticsearch_index_indexing_slowlog.json
-rw-rw-r--. 1 es es 0 Feb 26 10:48 elasticsearch_index_indexing_slowlog.log
-rw-rw-r--. 1 es es 0 Feb 26 10:48 elasticsearch_index_search_slowlog.json
-rw-rw-r--. 1 es es 0 Feb 26 10:48 elasticsearch_index_search_slowlog.log
-rw-rw-r--. 1 es es 23653 Feb 26 11:10 elasticsearch.log
-rw-rw-r--. 1 es es 42094 Feb 26 11:10 elasticsearch_server.json
-rw-rw-r--. 1 es es 37878 Feb 26 11:10 gc.log
-rw-rw-r--. 1 es es 1996 Feb 26 10:48 gc.log.00
-rw-rw-r--. 1 es es 85728 Feb 26 11:37 gc.log.01
-rw-rw-r--. 1 es es 1996 Feb 26 11:10 gc.log.02