django框架技术沉淀
Django 官网
Django是什么?
Django是使用Python语言开发的一款开源免费的Web应用框架。由于Python语言的跨平台性,所以 Django 同样支持 Windows、Linux 和 Mac 系统。
Django从何而来?
Django最初是被开发用来管理劳伦斯集团旗下一些以新闻内容为主的网站。2003 年,Lawerence Journal-World 报社的 Web 开发者艾德里安和威利森开始用Python语言去开发应用。新闻界的快节奏使他们必须提高产品的开发速度,于是他们两个人想办法构建出了节省开发时间的框架,这个框架将能复用的组件或者模块放在一起,使开发者不必重复的工作,这是 Django 诞生的根本原因。
Django的命名
To this day, he’s considered one of the best guitarists of all time, Listen to his music. You’ll like it.
Django是以一个名叫Django Reinhardt 吉他手的的名字来命名的。因为程序员的世界不能缺少音乐,开发者在他的音乐中得到灵感,为了感谢纪念这位吉他手,所以Django的名字也由此诞生!Django 的发音也非常有趣,大写字母D不发音ˈdʒæŋɡo。
Django框架的特点
相对于Python的其他Web框架,Django的功能是最完整的,Django 定义了服务发布、路由映射、模板编程、数据处理的一整套功能。这也意味着 Django 模块之间紧密耦合。
Django 的主要特点如下:
- 完善的文档:Django官方提供了完善的在线文档,为开发者解决问题提供支持
- 集成ORM组件:Django的Model层自带数据库ORM组件,为操作不同类型的数据库提供了统一的方式
- URL映射技术:Django 使用正则表达式管理URL映射,因此给开发者带来了极高的灵活性
- 后台管理系统:开发者只需通过简单的几行配置和代码就可以实现完整的后台数据管理Web控制台
- 错误信息提示:Django可以提供完整的错误信息帮助开发者定位问题
MVC设计模式
MVC设计模式它是Web设计模式的经典之作,MTV 模式也是在它的基础上衍生而来。MVC是 Model-View-Controller 的缩写,其中每个单词都有其不同的含义:

- Modle代表数据存储层,是对数据表的定义和数据的增删改查;
- View代表视图层,是系统前端显示部分,它负责显示什么和如何进行显示;
- Controller代表控制层,根据从View层输入的指令来检索Model层的数据,在该层编写代码产生结果并输出。
搭建Django开发环境
本文使用mac系统 python版本为python3.9 django为3.2
1、安装python开发环境
# 使用homebrew安装python
brew install python3.9
# 全局配置国内pip源
vim ~/.pip/pip.ini
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
2、安装数据库
# 安装redis
brew install redis
# 安装mysql
brew install mysql
3、安装django
pip3 install django==3.2
创建Django项目
1、项目创建
# 选择一个文件夹,然后输入下面命令以创建项目
django-admin startproject mydjango
2、项目目录结构
└─mydjango
├─manage.py # 管理django项目的重要命令行工具
└─mydjango # django项目配置目录
├─settings.py # 重要配置文件
├─urls.py # 记录路由映射关系
├─wsgi.py # 服务器程序的入口文件
├─__init__.py
3、settings配置文件详解
- BASE_DIR: 用于绑定当前项目所在的绝对路径
- SECRET_KEY:这个变量的本质是一个加密的盐,它一般配合加密算法 Hash、MD5 一起使用
- DEBUG: 配置 Django 项目的启用模式
- ALLOWED_HOSTS:用于配置能够访问当前站点的域名(IP地址),当 DEBUG = False 时,必须填写
- INSTALLED_APPS:当前项目中安装的应用列表
- MIDDLEWARE: 用于注册中间件
- ROOT_URLCONF:指定了当前项目的根 URL
- TEMPLATES:用于指定模板的配置信息
- WSGI_APPLICATION:项目部署时,Django 的内置服务器使用的Python路径。
- DATABASES: 用于指定数据库配置信息,默认配置的是 Django 自带的 sqllite3 数据库
- AUTH_PASSWORD_VALIDATORS:一个支持插拔的密码验证器
- LANGUAGE_CODE:语言配置项 (en-us/zh-Hans)
- TIME_ZONE: 服务端时区(Asia/Shanghai)
- USE_118N: 是否需要支持国际化
- USE_L10N:是否支持本地化
- USE_TZ: 对时区的处理方式
- STATIC_URL: 静态资源的存放位置
4、配置setting文件
配置语言
LANGUAGE_CODE = 'zh-hans' # 设置语言为汉语
TIME_ZONE = 'Asia/Shanghai' # 设置时区为亚洲上海
USE_TZ = False # 存储本地时区
MySQL配置
# pip install pymysql
# 在项目同名目录__init__.py下写入
import pymysql
pymysql.install_as_MySQLdb()
# mysql配置示例
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'mydjango',
'USER': 'root',
'PASSWORD': '123456',
'HOST': '127.0.0.1',
'PORT': '3306',
}
}
Redis配置
# pip install django-redis
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/1",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100}
# "PASSWORD": "密码",
}
}
}
# 使用redis
日志配置
# 日志配置
LOGPATH = os.path.join(os.path.join(os.path.dirname(BASE_DIR), 'mydjango'), 'logs')
# 创建存放日志的目录
if not os.path.exists(LOGPATH):
os.mkdir(LOGPATH)
LOGGING = {
'version': 1,
'disable_existing_loggers': True,
'formatters': {
'standard': {
'format': '[%(asctime)s] [%(filename)s:%(lineno)d] [%(module)s:%(funcName)s] '
'[%(levelname)s]- %(message)s'},
'simple': {
'format': '%(levelname)s %(message)s'
},
},
'handlers': {
'default': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler',
'filename': os.path.join(LOGPATH, 'all-{}.log'.format(time.strftime('%Y-%m-%d'))),
'maxBytes': 1024 * 1024 * 5,
'backupCount': 5,
'formatter': 'standard',
'encoding': 'utf-8',
},
'error': {
'level': 'ERROR',
'class': 'logging.handlers.RotatingFileHandler',
'filename': os.path.join(LOGPATH, 'error-{}.log'.format(time.strftime('%Y-%m-%d'))),
'maxBytes': 1024 * 1024 * 5,
'backupCount': 5,
'formatter': 'standard',
'encoding': 'utf-8'
},
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler',
'formatter': 'standard'
},
'info': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler',
'filename': os.path.join(LOGPATH, 'info-{}.log'.format(time.strftime('%Y-%m-%d'))),
'maxBytes': 1024 * 1024 * 5,
'backupCount': 5,
'formatter': 'standard',
'encoding': 'utf-8',
},
},
'loggers': {
'django': {
'handlers': ['default', 'console'],
'level': 'INFO',
'propagate': False
},
'mydjango': {
'handlers': ['error', 'info', 'console', 'default'],
'level': 'INFO',
'propagate': True
},
}
}
自定义日志
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import logging
def get_logger(logger_name, logger_path=LOGPATH):
# 实例化日志对象
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
# 创建handler
fh = logging.FileHandler(os.path.join(logger_path, logger_name), encoding='utf-8')
ch = logging.StreamHandler()
# 定义handler输出格式
formatter = logging.Formatter(
"[%(asctime)s] [%(levelname)s] [%(filename)s:%(lineno)d] %(message)s", "%Y-%m-%d %H:%M:%S"
)
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 将logger添加到handler里
logger.addHandler(fh)
logger.addHandler(ch)
return logger
5、完成数据库迁移
python manage.py makemigrations # 创建迁移文件
python manage.py migrate # 迁移文件
Django设置跨域
django跨域依赖django-cors-headers插件
1、安装依赖
pip install django-cors-headers
2、配置settings文件
-
添加应用
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'corsheaders', ] -
添加中间件
MIDDLEWARE = [
'corsheaders.middleware.CorsMiddleware',
]
-
配置允许跨站访问本站的地址
CORS_ORIGIN_ALLOW_ALL = True #
创建django应用
1、初始化应用
python manage.py startapp app01
2、应用目录结构
└─app01
├─ admin.py # django Admin 应用的配置文件
├─ apps.py # 用于应用程序本身的属性配置文件
├─ models.py # 用于定义应用中所需要的数据表
├─ tests.py # 文件用于编写当前应用程序的单元测试
├─ views.py # 用来定义视图处理函数的文件
├─__init__.py
└─ migrations # 存储数据库迁移时生成的文件
├─__init__.py
3、添加应用
在settings.py中INSTALLED_APPS中添加
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'corsheaders',
'app01'
]
到此应用初始化完成。
Django Admin数据表可视化
1、创建超级用户
# 用户名和密码可以自己设定
python manage.py createsuperuser --username=admin --email=admin@163.com
2、编写Model类
from django.db import models
# Create your models here.
class Info(models.Model):
user = models.CharField(max_length=32, verbose_name='用户名')
pwd = models.CharField(max_length=128, verbose_name='密码')
desc = models.CharField(max_length=128, null=True, verbose_name='描述')
class Meta:
db_table = "info"
verbose_name = "信息表"
verbose_name_plural = verbose_name
def __str__(self):
return self.id
3、将Model注册到后台
# 在app的admin.py中编写
from app01.models import Info # 这个需要我们自己导入相应的模型
# 单一模型可以只传一个模型,多个模型可以传list
admin.site.register(Info)
4、访问admin/登录

Django ORM应用
Django ORM Model官方文档
django ORM是django自带的操作数据库的工具,即对象关系映射。
1、ORM优势与不足
-
优势
-
使用该模块只需要面向对象编程
-
实现数据模型与数据库的解耦,屏蔽了不同数据库操作上的差异化
-
-
不足
- 在映射的过程中 ORM 需要与 SQL 之间进行转换,相比直接用 SQL 语句操作数据库会有性能损失
2、模型字段
| 字段 | 说明 | 属性 |
|---|---|---|
| AutoField | IntegerField,根据可用的 ID 自动递增 | settings默认做了配置 |
| BigAutoField | 64 位整数,与 AutoField很相似 | |
| BigIntegerField | 64 位整数,和 IntegerField很像 | |
| BinaryField | 用于存储原始二进制数据的字段,bytes等类型 | |
| BooleanField | 布尔字段 | |
| CharField | 字符串字段 | max_length必传 |
| DateField | 日期字段 | auto_now最后修改 |
| DateTimeField | 日期和时间,与 DateField类似 | auto_now_add首次创建 |
| DecimalField | 固定精度的十进制数 | max_digits/decimal_places |
| DurationField | 用于存储时间段的字段 | |
| EmailField | CharField校验邮箱 | |
| FileField | 文件上传字段 | |
| IntegerField | 整数字段 | |
| GenericIPAddressField | IPv4 或 IPv6 地址 | |
| JSONField | 用于存储 JSON 编码数据的字段 | |
| TextField | 大的文本字段 | |
| TimeField | 时间字段,与DateField类似 | |
| URLField | URL 的 CharField | |
| UUIDField | 用于存储通用唯一标识符的字段 | |
| ForeignKey | 多对一的关系 | on_delete |
| ManyToManyField | 多对多的关系 | |
| OneToOneField | 一对一的关系 |
3、Filed通用字段选项
| 选项 | 说明 | 备注 |
|---|---|---|
| blank | 默认值是 False,设置为 True 时,字段可以为空。 | |
| unique | 默认值是 False,它是一个数据库级别的选项,规定该字段在表中必须唯一 | |
| null | 默认为 False,如果设置为 True,表示该列值允许为空 | |
| db_index | 默认值是 False,如果设置为 True,Django 则会为该字段创建数据库索引 | |
| db_column | 这个选项用于设置数据库表字段的名称。 | |
| default | 用于给字段设置默认值 | |
| primary_key | 默认值是 False,如果设置为 True,表示该字段为主键 | |
| choices | 这个选项用于给字段设置可以选择的值 | |
| verbose_name | 设置此字段在 admin 后台管理系统界面上的显示名称 |
- 日期、时间、数字类型字段可以为空时,需要将 blank 与 null 均设为 True 才可以。
4、常用Meta属性
Mate属性详解
| 选项 | 说明 | 备注 |
|---|---|---|
| abstract | 如果 为True,这个模型将是一个 抽象基类 | |
| db_table | 模型数据库表的名称 | |
| base_manager_name | 管理器的属性名 | |
| indexes | 你想在模型上定义的 indexes 的列表 | |
| unique_together | 联合唯一 | |
| index_together | 一组字段名,合在一起,是有索引的 | |
| verbose_name | 对象的可读名称 | |
| verbose_name_plural | 对象的复数名称 |
5、__str__使用
# 在模型方法中使用str方法,可以将函数的返回值作为对象来显示。
def __str__(self):
return "%s" % self.id
6、数据创建
使用django shell测试 python manage.py shell
单条数据创建
>>> from app01.models import Info
>>> info = Info(user="python3")
>>> info.save()
>>>
创建多条数据
>>> lst = []
>>> lst.append(Info(user="python4"))
>>> lst.append(Info(user="python5"))
>>> Info.objects.bulk_create(lst)
[<Info: None>, <Info: None>]
7、数据查询
Manager查询管理器提供了查询Model实例的接口,这些接口通常会返回三种类型:单实例、RawQuerySet、QuerySet。通常的实际的开发工作中,我们会根据给定的条件查询数据库记录。Django 为实现返回单条查询数据提供了两个查询方法 get 和 get_or_create。
当被查询数据不存在的时候,get_or_create 方法会创建新的实例对象,而 get方法会抛出DoesNotExist异常。而当这两个方法的查询条件都能够匹配多条数据记录时,都会抛出MultipleObjectsReturned异常。这两个方法都只能返回一条数据。
使用get方法查询
因为get查询可能会抛出异常,所以若在项目使用get查询的时,经常会与 try…except 异常处理语句一起使用。
Info.objects.get(user="python3")
# 报错信息如下
MultipleObjectsReturned: get() returned more than one Info -- it returned 2!
# 查询不存在数据
Info.objects.get(id=4)
#报错信息如下:
DoesNotExist:Traceback (most recent call last)
使用get_or_create查询
Info.objects.get_or_create(user="ichpan") # 先查询是否存在若不存在则新建该实例对象
(<Info: id:1>, True) # 返回值是一个元组有两个元素
统计对象数量
# 根据查询条件查询到的数据做统计
Info.objects.all().count()
# 返回数量
判断数据记录是否存在
# 此查询条件下是否有数据
Info.objects.filter(user__exact="python").exists()
# 返回值是一个布尔值
Django查询谓词表
Django为了更好实现条件查询,提供了条件查询关键字,例如大于、小于、大于等于、是否包含等,使用方法是字段名后加上双下划线,再加上条件查询关键字,每个查询关键字都有其独立的查询功能。我们把这些查询关键字,也称做“查询谓词”。
| 条件查询关键字 | 代表含义 | 备注 |
|---|---|---|
| __gt | 大于 | |
| __gte | 大于等于 | |
| __lt | 小于 | |
| __lte | 小于等于 | |
| __exact | 等于 | |
| __iexact | 忽略大小写的等于 | |
| __in | 是否在集合中 | |
| __contains | 是否包含… | |
| __startswith | 以…开头 | |
| __endswith | 以…结尾 | |
| __range | 在…范围内 | |
| __year | 年 | |
| __month | 月 | |
| __day | 日 | |
| __isnull | 是否为空 |
获取所有数据记录
# 获取Info模型中所有数据
info = Info.objects.all()
获取对应的原生SQL查询语句
# 获取Info模型中所有数据
info = Info.objects.all().query
# 返回值
# SELECT `info`.`id`, `info`.`user`, `info`.`pwd`, `info`.`desc` FROM `info`
filter方法条件查询多条记录
filter方法返回一个新的QuerySet 它包含了与筛选条件相匹配的所有对象。这些筛选条件,通过参数的形式传递给filter 方法。filter方法会将传递的参数转换成 WHERE 子句实现过滤查询。若是多个条件那么它们之间属于 and 关系。在没有查询条件的情况下,它的与all方法是等价的。
Model.objects.filter(属性1=值1, 属性2=值2)
反向过滤
exclude它与 filter 方法正好正反,相当于在filter方法前面加上一个NOT,即过滤出来的结果是不满足条件的数据记录。
Info.objects.exclude(id=1)
实现自定义排序
order_by 方法可以实现自定义排序,同时也可以指定多个排序字段。order_by方法在执行之前,会清除它之前的所有排序,它和内部类 Meta 提供的 ordering 元数据项起到一样的作用,我们可以二者选择其一来实现字段的排序,如果是字符串将按照字母进行排序,如果是数字将按照大小进行排序。
Book.objects.order_by("-id","user") # 按照id逆序排序后 再按用户名正序排列
reverse方法逆序记录获取
reverse的使用方法和 all 方法相似,只不过返回的结果是逆序的数据记录,可以理解成逆序的查询方法。
values方法获取字典结果
values 方法返回字典,字典中的键对应 Model 的字段名。可以给 values 方法传递参数,用于限制 select 查询范围,如果指定,则查询结果包含 Model 的所有字段。
>>> Info.objects.values("id","user")
<QuerySet [{'id': 4, 'user': 'python3'}, {'id': 5, 'user': 'python4'}, {'id': 6, 'user': 'python5'}, {'id': 7, 'user': 'python4'}, {'id': 8, 'user': 'python5'}]>
values_list方法获取元组结果
values_list和 values 方法用法相似,但是它的返回结果是列表,其中每一个元素都是一个元组,而非字典。
>>> Info.objects.values_list("id","user")
<QuerySet [(4, 'python3'), (5, 'python4'), (6, 'python5'), (7, 'python4'), (8, 'python5')]>
QuerySet切片使用
QuerySet 是一个可迭代的对象,同时支持索引和切片,并且执行切片后会返回一个新的 QuerySet。我们可以使用切片来限制返回的数据结果,但是这里需要注意的是,QuerySet 不支持末尾切片,即索引值不允许为负数。
Book.objects.all()[:3] # 返回新的QuerySet对象
注意:切片后得到的 QuerySet 不能再执行其他操作,比如字段排序、过滤等。
更新Model实例
# update方法对查询到的数据做更新
Info.objects.filter(user__exact="python").update(user="django")
# 返回一个整数,标识被改动的数据记录数量
delete方法删除数据记录
# 删除符合条件的数据
Info.objects.filter(user__exact="Tornado").delete()
# delete 方法返回一个元组:第一个元素为删除实例的总个数,第二个元素是字典类型
原生数据库操作方法
# 语法
# Model.objects.raw('sql语句')
def InfoView(request):
infos = Info.objects.raw("select * from info")
print(infos)
防止sql注入
在很多场景下,我们需要使用参数化查询,这个时候我们不能手动填充 SQL 字符串,这会带来 SQL 注入的风险,raw方法充分考虑到这一点,提供了params参数来解决这个问题。
infos = Info.objects.raw("select id, user from info where user= %s",['ichpan'])
...: for info in infos:
...: print('%s:%s'%(info.id,info.user))
游标cursor执行SQL语句
# 使用示例
from django.db import connection
with connection.cursor() as cur:
cur.execute('执行SQL语句')
聚合查询
对数据表计算统计值,需要使用 aggregate 方法,提供的参数可以是一个或者多个聚合函数,aggregate 是 QuerySet 的一个子句,它的返回值是一个字典类型,键是聚合的关键字,值是聚合后的统计结果。语法格式如下所示,它的返回值是一个字典.
Model.objects.aggregate(统计结果变量名=聚合函数('列名'))
>>> Info.objects.aggregate(number=Count('user'))
{'number': 5}
聚合分组查询
分组聚合是指通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合。简单的理解就是对 QuerySet中的每一个 Model 对象都生成一个统计值。分组聚合使用 annotate 方法完成。它的语法格式和聚合查询一样如下所示:
QuerySet.annotate(结果变量名=聚合函数('列名'))
F对象查询
F对象主要用于模型类的 A 字段属性与 B 字段属性两者的比较,即操作数据库中某一列的值。通常是对数据库中的字段值在不获取的情况下进行操作。
from django.db.models import F
from index.models import info
# 给Info所有实例钱包增加20元
Info.objects.all().update(wallet=F('wallet')+20) # 获取该列所有值并加20
Q对象查询
Q 对象相比 F 对象更加复杂一点,它主要应用于包含逻辑运算的复杂查询。Q 对象把关键字参数封装在一起,并传递给filter、exclude、get 等查询的方法。多个 Q 对象之间可以使用&或者|运算符组合(符号分别表示与和或的关系),从而产生一个新的 Q 对象。当然也可以使用~(非)运算符来取反,从而实现NOT查询。
# Q(条件1) | Q(条件2) # 条件1成立或条件2成立
# Q(条件1) & Q(条件2) # 条件1和条件2同时成立
# Q(条件1) &~ Q(条件2) # 条件1成立且条件2不成立
# ...等
from django.db.models import Q
Info.objects.filter(Q(wallet__lte=100),user__icontains="p") # 组合使用
# 返回]>
一对多关系类型
这种类型在数据库中体现是外键关联关系,它在和其他的 Model 建立关联同时也和自己建立关联,用来描述一对多的关系,例如一个作者可以写很多不同的书,但是这些书又只能对应这一个作者,再比如一本图书只能属于一个出版社,一个出版社可以出版很多不同种类的图书,这就是一对多的关系。Django 会自动将字段的名称添加“_id”作为列名,ForgienKey 的定义如下:
class django.db,model.ForeignKey(to,on_delete,**options)
必填参数
- to: 指定所关联的 Model,它的取值可以是直接引用其他的 Model,也可以是 Model 所对应的字符串名称
- on_delete:当删除关联表的数据时,Django 将根据这个参数设定的值确定应该执行什么样的 SQL 约束
- CASCADE,级联删除,它是大部分 ForeignKey 的定义时选择的约束。它的表现是删除了“主”,则“子”也会被自动删除。
- PROTECT,删除被引用对象时,将会抛出 ProtectedError 异常。当主表被一个或多个子表关联时,主表被删除则会抛出异常。
- SET_NULL,设置删除对象所关联的外键字段为 null,但前提是设置了选项 null 为True,否则会抛出异常。
- SET_DEFAULT:将外键字段设置为默认值,但前提是设置了 default 选项,且指向的对象是存在的。
- SET(value):删除被引用对象时,设置外键字段为 value。value 如果是一个可调用对象,那么就会被设置为调用后的结果。
- DO_NOTHING:不做任何处理。但是,由于数据表之间存在引用关系,删除关联数据,会造成数据库抛出异常。
可选参数
- to_field:关联对象的字段名称。默认情况下,Django 使用关联对象的主键(大部分情况下是 id),如果需要修改成其他字段,可以设置这个参数。需要注意,能够关联的字段必须有 unique=True 的约束。
- db_constraint:默认值是 True,它会在数据库中创建外键约束,维护数据完整性。通常情况下,这符合大部分场景的需求。如果数据库中存在一些历史遗留的无效数据,则可以将其设置为 False,这时就需要自己去维护关联关系的正确性了。
- related_name:这个字段设置的值用于反向查询,默认不需要设置,Django 会设置其为“小写模型名 _set”。
- related_query_name:这个名称用于反向过滤。如果设置了 related_name,那么将用它作为默认值,否则 Django会把模型的名称作为默认值。
# 创建模型时指定
models.ForeignKey(to=PubName, on_delete=models.CASCADE, null=True)
一对一关系类型
OneToOneFiled 继承自 ForeignKey,在概念上,它类似 unique=Ture 的 ForeignKey,它与 ForeignKey 最显著的区别在于反向查询上,ForeignKey 反向查询返回的是一个对象实例列表,而 OneToOneFiled 反向查询返回的是一个对象实例。
models.OneToOneField(to=UserInfo, on_delete=models.CASCADE)
多对多关系类型
多对多关系也是比较常见的,比如一个作者可以写很多本书,一本书也可以由很多作者一起完成,那么这时候 Author 和 Book 之间就是多对多的关系。 Django 通过中间表的方式来实现 Model 之间的多对多的关系,这和 MySQL 中实现方式是一致的。这个中间表我们可以自己提供,也可以使用 Django 默认生成的中间表。
ManyToManyFiled定义
class django.db.models.ManyToManyFiled(to,**options)
它只有一个必填的参数即 to,与其他两个关联词在一样,用来指定与当前的 Model 关联的 Model。
可选参数
- relate_name 与 ForeignKey 中的相同都用于反向查询。
- db_table 用于指定中间表的名称
- through 用于指定中间表
models.ManyToManyField(to="Book") # 创建多对多映射关系
Django视图函数
在Django 中,视图函数是一个Python类,开发者主要通过编写视图函数来实现业务逻辑。视图函数首先接受来自浏览器或者客户端的请求,并最终返回响应,视图函数返回的响应可以是 HTML 文件,也可以是 HTTP 协议中的 303 重定向。
from django.http import HttpResponse
from django.views import View
# 方法视图
def say_hello(request):
return HttpResponse('hello')
# 类视图
class InfoListView(View):
def get(self, request):
return HttpResponse('get接口')
Django URL Path配置
为了提高代码可读性,采用路由分发。
1、配置跟路由
"""mydjango URL Configuration
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/3.2/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
Including another URLconf
1. Import the include() function: from django.urls import include, path
2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
"""
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('api/v1/', include('app01.urls')),
]
2、配置子路由
- 方法视图
# 在APP同级目录下新建urls.py
"""app01 URL Configuration
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/3.2/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
"""
from django.conf.urls import url
from app01 import views
# api/v1/
urlpatterns = [
url('say_hello/', views.say_hello),
]
- 类视图
"""app01 URL Configuration
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/3.2/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
"""
from django.conf.urls import url
from app01 import views
urlpatterns = [
url('info/', views.InfoListView.as_view()),
]
Django中使用cookie
HTTP 是一种无状态的传输协议,对于事务处理没有记忆能力。对于客户端浏览器发出的请求,Web 服务器无法区分是不是源自于同一个浏览器。所以,这时就需要额外的数据用于维持会话。我们通常用来它来记录浏览器端的信息和当前连接的确认信息。Cookie 保存在客户端浏览器存储空间中并以键值对的形式进行存储。
# 设置cookies
# key、value分别表示 COOKIES 的键与值
# max_age代表COOKIES的存活时间,以秒为单位;
# expires表示具体过期时间,当不指定max_age和expires时,关闭浏览器时此数据失效。
HttpResponse.set_cookie(key="", value='', max_age=None, expires=None) # 设置cookie
Django使用session
Session 又名会话控制,它的根本作用是在服务器上开辟一段空间用于保留浏览器和服务器交互时的会话信息。它代表服务器与浏览器的一次会话过程,这个过程是连续的,也可以是时断时续的。Session 是一种服务器端的机制,Session 对象用来存储特定用户会话所需的信息。Session 由服务端生成,并且保存在服务器端的内存或者缓存中,也可以是硬盘或数据库中。
1、配置session
在settings中可以指定session的属性
# 在settings中可以指定session的生命周期 默认是2周
SESSION_COOKIE_AGE = 60 * 60 * 24 * 7 * 2
#开启关掉浏览器立即失效模式
SESSION_EXPIRE_AT_BROWSER_CLOSE = True
2、session基本操作
Session可以用类似于字典的方式进行操作,并且 Session 只能够存储能够序列化的数据,例如字典或者列表等。
# 保存session的值到服务器
request.session['KEY'] = VALUE
# 获取session的值
VALUE = request.session['KEY']
VALUE = request.session.get('KEY', None)
# 删除session的值
del request.session['KEY']
# 删除所有session
request.session.flush()
3. Cookie和Session的区别
-
存储位置与存取方式不同
-
安全性能两者有所不同
-
对于服务器压力不同
Django自定义中间件
1、中间件的应用场景
中间件简单地理解为对视图中业务处理逻辑的封装。如果想对请求和响应对象做出修改,就可以考虑使用 Django 的中间件。
2、Django钩子方法
| MIDDLEWARE | 描述 |
|---|---|
| process_request | 请求之前做的事情 |
| process_view | 处理视图 |
| process_response | 处理响应 |
| process_template_response | 模板响应之前做的事情 |
| process_exception | 处理异常 |
3、中间件执行顺序
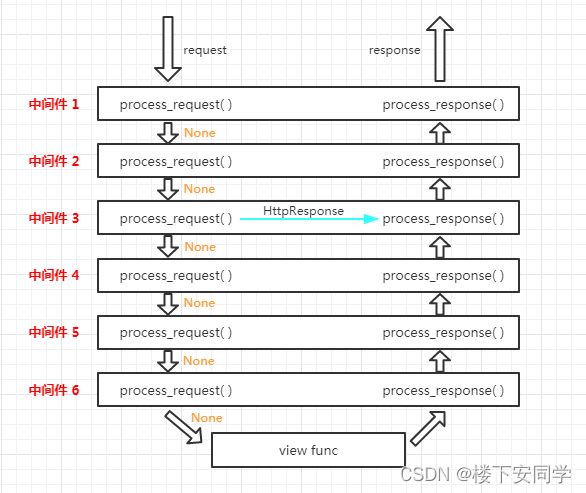
4、自定义中间件
from django.http import HttpResponse
from django.utils.deprecation import MiddlewareMixin
class TestMiddleWare(MiddlewareMixin):
def process_request(self, request):
print("中间件方法 process_request 被调用")
def process_view(self, request, callback, callback_args, callback_kwargs):
print("中间件方法 process_view 被调用")
def process_response(self, request, response):
print("中间件方法 process_response 被调用")
return response
def process_exception(self, request, exception):
print("中间件方法 process_exception 被调用")
5、注册中间件
中间件定义完成后,需要在 settings.py中的MIDDLEWARE列表完成注册,如下所示:
'middleware.TestMiddleWare'
注册完成之后会在项目启动的时候加载中间件。
6、中间件使用时注意事项
- 明确钩子函数的实现
- 中间件的定义顺序。不可以随意更改中间件的定义顺序,因为它们之间可能存在着依赖关系。
Django缓存框架
Django 带有一个强大的缓存系统,可以让您保存动态页面,因此不必为每个请求计算它们。为方便起见,Django 提供了不同级别的缓存粒度:您可以缓存特定视图的输出,您可以只缓存难以生成的部分,或者您可以缓存整个站点,其中缓存机制有内存缓存、数据库缓存、文件系统缓存、本地内存缓存等。
1、按视图缓存
在普通方法中使用缓存:
# example
from django.views.decorators.cache import cache_page
# 装饰器参数是以秒为单位的,下面为15min。
# 还可以设置key标识 key_prefix默认为空
@cache_page(60 * 15, key_prefix="myprefix")
def my_view(request):
...
在类方法使用缓存:
from rest_framework.response import Response
from rest_framework.viewsets import ViewSet
from rest_framework.decorators import action
from django.utils.decorators import method_decorator
from django.views.decorators.cache import cache_page
from datetime import datetime as dt
class TestViewSet(ViewSet):
"""
测试视图集
"""
@method_decorator(cache_page(15, key_prefix='test'))
@action(methods=["get"], detail=False)
def myfunction(self, request):
now = dt.now().strftime("%Y-%m-%d %H:%M:%S")
data = {"_time": now, "msg": "ok"}
return Response(data, status=200)
2、删除缓存
from django.core.cache import cache
def del_cache():
key = '*views.decorators.cache.*'
cache.delete_pattern(key)
print("删除成功")
3、底层原理剖析
核心思想:先缓存request的header,然后对url进行
hash
# 缓存key构造过程
def _generate_cache_key(request, method, headerlist, key_prefix):
"""Return a cache key from the headers given in the header list."""
ctx = hashlib.md5()
for header in headerlist:
value = request.META.get(header)
if value is not None:
ctx.update(value.encode())
url = hashlib.md5(request.build_absolute_uri().encode('ascii'))
cache_key = 'views.decorators.cache.cache_page.%s.%s.%s.%s' % (
key_prefix, method, url.hexdigest(), ctx.hexdigest())
return _i18n_cache_key_suffix(request, cache_key)
4、缓存时长设置建议
- 若接口返回的数据是一直变化的,可以将缓存时长设置短一点,甚至不使用缓存。建议使用在30min左右。
- 若接口查的是历史数据,且数据一直是不变的,我们就可以将缓存设置长一点,四五个小时都是可以的。
Django REST framework
Django REST framework官网
Django REST framework是用于构建Web API的强大而灵活的工具包。
1、序列化器
serializer是独立于数据库之外的存在。
常用字段类型
https://www.django-rest-framework.org/api-guide/fields/
| 字段 | 说明 | 备注 |
|---|---|---|
| BooleanField | 布尔类型 | |
| CharField | 字符类型 | |
| EmailField | 邮箱类型 校验邮箱 | |
| RegexField | 用于验证给定值是否与某个正则表达式匹配 | |
| SlugField | 根据模式验证输入[a-zA-Z0-9_-]+ | |
| URLField | URL 匹配模式验证输入 | |
| UUIDField | 确保输入是有效 UUID 字符串的字段 | |
| IPAddressField | 确保输入是有效的 IPv4 或 IPv6 字符串的字段 | |
| IntegerField | 整数表示 | |
| FloatField | 浮点表示 | |
| DecimalField | 十进制表示,在 Python 中由Decimal实例表示 | |
| DateTimeField | 日期和时间表示 | |
| DateField | 日期表示 | |
| TimeField | 时间表示 | |
| DurationField | 持续时间表示 | |
| ChoiceField | 选择字段 | |
| MultipleChoiceField | 多选字段 | |
| FileField | 上传文件字段 | |
| ImageField | 图片字段 | |
| ListField | 验证对象列表的字段类 | |
| DictField | 验证对象字典的字段类 |
选项参数
| 参数名称 | 作用 |
|---|---|
| max_length | 最大长度 |
| min_lenght | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 最小值 |
| min_value | 最大值 |
通用参数
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
Serializer序列化器使用
定义序列化器
from rest_framework import serializers
from rest_framework.exceptions import ValidationError
class BookSerializer(serializers.Serializer):
id = serializers.IntegerField(read_only=True)
name = serializers.CharField(max_length=64, required=False)
author = serializers.CharField(max_length=32, allow_null=True, required=False)
price = serializers.DecimalField(max_digits=12, decimal_places=2, required=False)
desc = serializers.CharField(allow_null=True, required=False)
created = serializers.DateTimeField(allow_null=True, required=False)
updated = serializers.DateTimeField(allow_null=True, required=False)
def validate(self, validate_date):
return validate_date
def create(self, validated_data):
return Books.objects.create(**validated_data)
def update(self, instance, validated_data):
instance.name = validated_data.get('name', instance.name)
instance.author = validated_data.get('author', instance.author)
instance.price = validated_data.get('price', instance.price)
instance.desc = validated_data.get('desc', instance.desc)
instance.save()
return instance
def validate_price(self, data):
if float(data) > 500:
raise ValidationError("价格输入异常")
return data
序列化器使用
from rest_framework.views import APIView
from rest_framework.response import Response
from app01.models import Books
from app01.serializer import BookSerializer
# 使用序列化器创建一条数据 从body中获取数据
class TestView(APIView):
def post(self, request):
request_data = request.data
serializer = BookSerializer(data=request_data)
serializer.is_valid(raise_exception=True)
serializer.save()
return Response({"code": "2001", "msg": "创建成功"}, status=200)
局部钩子方法
from rest_framework.exceptions import ValidationError
# 校验price字段
def validate_price(self, data):
if float(data) > 10:
return data
else:
raise ValidationError('价格太低')
全局钩子函数
# 从validate_date获取字段的值,校验失败抛出异常即可
# 示例:ValidationError("价格输入异常")
def validate(self, validate_date):
return validate_date
使用validators校验
# 代码示例
def check_author(data):
if data.startswith('sb'):
raise ValidationError('作者名字不能以sb开头')
else:
return data
class BookSerializer(serializers.Serializer):
# 需要序列化哪些字段,就写哪些字段
# validators后面可以放函数的内存地址,把author对应的数据传进去做校验
author = serializers.CharField(validators=[check_author])
重写create方法
若序列化类继承了Serializer,客户端请求方式为post的时候,父类BaseSerializer是create方法是直接抛出了异常(NotImplementedError),所以,必须重写create方法,视图类中调用序列化类,通过save方法保存数据。
def create(self, validated_data):
return Books.objects.create(**validated_data)
在视图中使用:
request_data = request.data
serializer = BookSerializer(data=request_data)
serializer.is_valid(raise_exception=True)
serializer.save()
重写update方法
def update(self, instance, validated_data):
instance.name = validated_data.get('name', instance.name)
instance.author = validated_data.get('author', instance.author)
instance.price = validated_data.get('price', instance.price)
instance.desc = validated_data.get('desc', instance.desc)
instance.save()
return instance
注意事项
如果创建序列化器对象的时候,没有传递instance实例,则调用save()方法的时候,create()被调用,相反,如果传递了instance实例,则调用save()方法的时候,update()被调用。
2、请求和响应
请求对象
REST引入了一个Request扩展常规的对象HttpRequest,并提供更灵活的请求解析。对象的核心功能Request是request.data属性。
响应对象
REST框架引入了一个Response对象,它是一种TemplateResponse接受未渲染内容并使用内容协商来确定返回给客户端的正确内容类型的类型。
包装 API 视图
-
@api_view用于处理基于函数的视图的装饰器
@api_view(['GET', 'POST']) def snippet_list(request): -
APIView用于处理基于类的视图的类class TestView(APIView): def get(): pass def post(): pass
3、视图
视图基类
1、APIView
APIView是REST framework提供的所有视图的基类,继承自Django的View父类。
DRF的APIView在继承djangoView的基础上,新增了以下内容:
- 传入到视图方法中的是REST framework的
Request对象,而不是Django的HttpRequeset对象 - 视图方法可以返回REST framework的
Response对象,视图会为响应数据设置(render)符合前端格式 - 任何
APIException异常都会被捕获到,并且处理成合适的响应信息 - 重写了as_view(),在进行dispatch()路由分发前,会对http请求进行身份认证、权限检查、访问流量控制
支持定义的类属性
- authentication_classes 列表或元组,身份认证类
- permissoin_classes 列表或元组,权限检查类
- throttle_classes 列表或元祖,流量控制类
在APIView中仍以常规的类视图定义方法来实现get() 、post() 或者其他请求方式的方法。
from rest_framework.views import APIView
from rest_framework.response import Response
class TestModelView(APIView):
def post(self, request):
request_data = request.data
serializer = BookModelSerializer(data=request_data)
serializer.is_valid(raise_exception=True)
serializer.save()
return Response({"code": "2001", "msg": "创建成功"}, status=200)
2、GenericAPIView
通用视图类主要作用就是把视图中的独特的代码抽取出来,让视图方法中的代码更加通用,方便把通用代码进行简写。继承自APIView,主要增加了操作序列化器和数据库查询的方法,作用是为下面Mixin扩展类的执行提供方法支持。通常在使用时,可搭配一个或多个Mixin扩展类。
属性:
| 属性 | 描述 | |
|---|---|---|
| queryset | 指明使用的数据查询集 | |
| serializer_class | 指明视图使用的序列化器 | |
| pagination_class | 指明分页控制类 | |
| filter_backends | 指明过滤控制后端 |
方法:
| 方法 | 描述 |
|---|---|
| get_serializer | 返回序列化器对象,在视图中想要获取序列化器对象,可以直接调用此方法。 |
| get_serializer_class | 当出现一个视图类中调用多个序列化器时,那么可以通过条件判断在get_serializer_class方法中通过返回不同的序列化器类。 |
| get_queryset | 返回视图使用的查询集,主要用来提供给Mixin扩展类使用,是列表视图与详情视图获取数据的基础,默认返回queryset属性 |
| get_object | 返回单个视图模型类对象,主要用来提供给Mixin扩展类使用 |
使用示例:
from rest_framework.generics import GenericAPIView
from students.models import Student
from .serializers import StudentModelSerializer, StudentModel2Serializer
from rest_framework.response import Response
class StudentsGenericAPIView(GenericAPIView):
# 本次视图类中要操作的数据
queryset = Student.objects.all()
# 本次视图类中要调用的默认序列化器[选填]
serializer_class = StudentModelSerializer
def get(self, request):
"""获取所有学生信息"""
serializer = self.get_serializer(instance=self.get_queryset(), many=True)
return Response(serializer.data)
视图扩展类
五个扩展类需要搭配GenericAPIView父类,因为五个扩展类的实现需要调用GenericAPIView提供的序列化器与数据库查询的方法。
| 视图子类 | 提供方法 | 继承源 |
|---|---|---|
| CreateAPIView | post | GenericAPIView、CreateModelMixin |
| ListAPIView | get | GenericAPIView、ListModelMixin |
| RetrieveAPIView | get | GenericAPIView、RetrieveModelMixin |
| DestoryAPIView | delete | GenericAPIView、DestoryModelMixin |
| UpdateAPIView | put/patch | GenericAPIView、UpdateModelMixin |
| RetrieveUpdateAPIView | get/put/patch | GenericAPIView、RetrieveModelMixin、UpdateModelMixin |
| RetrieveUpdateDestoryAPIView | get/put/patch/delete | GenericAPIView、RetrieveModelMixin、UpdateModelMixin、DestoryModelMixin |
视图集
使用视图集ViewSet,可以将一系列逻辑相关的动作放到一个类中:
- list() 提供一组数据
- retrieve() 提供单个数据
- create() 创建数据
- update() 保存数据
- destory() 删除数据
ViewSet视图集类不再实现get()、post()等方法,而是实现动作 action 如 list() 、create() 等。
视图集只在使用as_view()方法的时候,才会将action动作与具体请求方式对应上。如:
class BookInfoViewSet(viewsets.ViewSet):
def list(self, request):
books = BookInfo.objects.all()
serializer = BookInfoSerializer(books, many=True)
return Response(serializer.data)
def retrieve(self, request, pk=None):
try:
books = BookInfo.objects.get(id=pk)
except BookInfo.DoesNotExist:
return Response(status=status.HTTP_404_NOT_FOUND)
serializer = BookInfoSerializer(books)
return Response(serializer.data)
常用视图集父类
1、ViewSet
继承自APIView与ViewSetMixin,作用也与APIView基本类似,提供了身份认证、权限校验、流量管理等。ViewSet主要通过继承ViewSetMixin来实现在调用as_view()时传入字典(如{‘get’:‘list’})的映射处理工作。在ViewSet中,没有提供任何动作action方法,需要我们自己实现action方法。
2、GenericViewSet
使用ViewSet通常并不方便,因为list、retrieve、create、update、destory等方法都需要自己编写,而这些方法与前面讲过的Mixin扩展类提供的方法同名,所以我们可以通过继承Mixin扩展类来复用这些方法而无需自己编写。但是Mixin扩展类依赖与GenericAPIView,所以还需要继承GenericAPIView。
3、ModelViewSet
继承自GenericViewSet,同时包括了ListModelMixin、RetrieveModelMixin、CreateModelMixin、UpdateModelMixin、DestoryModelMixin。
4、ReadOnlyModelViewSet
继承自GenericViewSet,同时包括了ListModelMixin、RetrieveModelMixin。
视图集中定义附加动作
在视图集中,如果想要让Router自动帮助我们为自定义的动作生成路由信息,需要使用装饰器。以action装饰器装饰的方法名会作为action动作名,与list、retrieve等同。
action装饰器可以接收两个参数:
- methods: 声明该action对应的请求方式,列表传递
- detail: 声明该action的路径是否与单一资源对应
from rest_framework.viewsets import ModelViewSet
from rest_framework.decorators import action
class TestModelViewSet(ModelViewSet):
queryset = Books.objects.all()
serializer_class = BookModelSerializer
# methods 设置当前方法允许哪些http请求访问当前视图方法
# detail 设置当前视图方法是否是操作一个数据
# detail为True表示路径名格式应该为 router_stu/test/
@action(methods=['get'], detail=False)
def test(self, request):
...
视图集路由
原生方法注册
# django中
from django.conf.urls import url
urlpatterns = [
url(r'^books/$', BookInfoViewSet.as_view({'get':'list'}),
url(r'^books/(?P\d+)/$' , BookInfoViewSet.as_view({'get': 'retrieve'})
]
使用drf注册路由
from rest_framework.routers import DefaultRouter
from . import views
router = DefaultRouter()
router.register(r'', views.TestViewSet, basename='test') # 测试视图
urlpatterns = router.urls
4、DRF分页功能
PageNumberPagination
- page_size 每页数目
- page_query_param 前端发送的页数关键字名,默认为"page"
- page_size_query_param 前端发送的每页数目关键字名,默认为None
- max_page_size 前端最多能设置的每页数量
# 声明分页的配置类
from rest_framework.pagination import PageNumberPagination
class StandardPageNumberPagination(PageNumberPagination):
# 默认每一页显示的数据量
page_size = 2
# 允许客户端通过get参数来控制每一页的数据量
page_size_query_param = "size"
max_page_size = 10
# 自定义页码的参数名
page_query_param = "p"
class StudentAPIView(ListAPIView):
queryset = Student.objects.all()
serializer_class = StudentModelSerializer
pagination_class = StandardPageNumberPagination
LimitOffsetPagination
- default_limit 默认限制,默认值与
PAGE_SIZE设置一直 - limit_query_param limit参数名,默认’limit’
- offset_query_param offset参数名,默认’offset’
- max_limit 最大limit限制,默认None
from rest_framework.pagination import LimitOffsetPagination
class StandardLimitOffsetPagination(LimitOffsetPagination):
default_limit = 2
limit_query_param = "size"
offset_query_param = "start"
class StudentAPIView(ListAPIView):
queryset = Student.objects.all()
serializer_class = StudentModelSerializer
# 调用页码分页类
# pagination_class = StandardPageNumberPagination
# 调用查询偏移分页类
pagination_class = StandardLimitOffsetPagination
5、鉴权
权限控制可以限制用户对于视图的访问和对于具体数据模型对象的访问。
1、在执行视图的as_view()方法的dispatch()方法前,会先进行视图访问权限的判断
2、在通过get_object()获取具体模型对象时,会进行模型对象访问权限的判断
提供的权限:
- AllowAny 允许所有用户
- IsAuthenticated 仅通过登录认证的用户
- IsAdminUser 仅管理员用户
- IsAuthenticatedOrReadOnly 已经登陆认证的用户可以对数据进行增删改操作,没有登陆认证的只能查看数据。
配置使用:
可以在配置文件settings.py中全局设置默认的权限管理类
# drf的配置信息,需要卸载django的配置文件,而且必须写在REST_FRAMEWORK的字典中,才能被drf识别
REST_FRAMEWORK = {
....
# 权限[全局配置,所有的视图都会被影响到]
'DEFAULT_PERMISSION_CLASSES': (
'rest_framework.permissions.IsAuthenticated', # 已经登录认证的用户才能访问
)
}
也可以在具体的视图中通过permission_classes属性来设置,如
from rest_framework.permissions import IsAuthenticated
from rest_framework.views import APIView
class ExampleView(APIView):
permission_classes = (IsAuthenticated,)
...
6、限流
可以对接口访问的频次进行限制,以减轻服务器压力,或者实现特定的业务。
可选限流类
- AnonRateThrottle:限制所有匿名未认证用户,使用IP区分用户。使用anon来设置频次
- UserRateThrottle:限制认证用户,使用User id 来区分。使用user来设置频次
- ScopedRateThrottle:限制用户对于每个视图的访问频次,使用ip或user id
使用
可以在配置文件中,使用DEFAULT_THROTTLE_CLASSES 和 DEFAULT_THROTTLE_RATES进行全局配置,
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': ( # 启用的限制类
'rest_framework.throttling.AnonRateThrottle',
'rest_framework.throttling.UserRateThrottle'
),
'DEFAULT_THROTTLE_RATES': { # 限制频率
'anon': '100/day',
'user': '1000/day'
}
}
DEFAULT_THROTTLE_RATES 可以使用 second, minute, hour 或day来指明周期。
在具体视图中通过throttle_classess属性来配置
from rest_framework.throttling import UserRateThrottle
from rest_framework.views import APIView
class ExampleView(APIView):
throttle_classes = (UserRateThrottle,)
...
7、过滤
对于列表数据可能需要根据字段进行过滤,我们可以通过添加django-fitlter扩展来增强支持。
pip install django-filter
在配置文件settings.py中增加过滤组件的设置:
INSTALLED_APPS = [
...
'django_filters', # 需要注册应用,
]
REST_FRAMEWORK = {
...
# 全局配置,也可以使用局部配置
'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend',)
}
在视图类中添加类属性filter_fields,指定可以过滤的字段
class StudentListView(ListAPIView):
queryset = Student.objects.all()
serializer_class = StudentSerializer
filter_fields = ('age', 'sex')
8、排序
对于列表数据,REST framework提供了OrderingFilter过滤器来帮助我们快速指明数据按照指定字段进行排序。在类视图中设置filter_backends,使用rest_framework.filters.OrderingFilter过滤器,REST framework会在请求的查询字符串参数中检查是否包含了ordering参数,如果包含了ordering参数,则按照ordering参数指明的排序字段对数据集进行排序。前端可以传递的ordering参数的可选字段值需要在ordering_fields中指明。
class TestListView(ListAPIView):
queryset = Student.objects.all()
serializer_class = StudentModelSerializer
filter_backends = [OrderingFilter]
ordering_fields = ('id', 'age')
# 127.0.0.1:8000/books/?ordering=-age
# - 表示针对字段进行倒序排序
如果需要在过滤以后再次进行排序,则需要两者同步。要么一起写在全局配置中,要么一起写在视图类中。
from rest_framework.generics import ListAPIView
from students.models import Student
from .serializers import StudentModelSerializer
from django_filters.rest_framework import DjangoFilterBackend
class Student3ListView(ListAPIView):
queryset = Student.objects.all()
serializer_class = StudentModelSerializer
filter_fields = ('age', 'sex')
# 因为排序配置和过滤配置使用同一个类属性,所以当视图中需要使用排序和过滤时,
# 要么大家一起在视图类中局部配置,要么大家一起在全局中配置,否则会出现过滤组件使用无效的情况
# filter_backends = [DjangoFilterBackend,OrderingFilter]
ordering_fields = ('id', 'age')
配置文件:
# 过滤组件[全局引入]
# 'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend','rest_framework.filters.OrderingFilter')
Django Rest Framwork JWT
在用户注册或登录后,我们想记录用户的登录状态,或者为用户创建身份认证的凭证。我们不再使用Session认证机制,而使用Json Web Token认证机制。
安装
pip install djangorestframework-jwt
配置
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'rest_framework_jwt.authentication.JSONWebTokenAuthentication',
'rest_framework.authentication.SessionAuthentication',
'rest_framework.authentication.BasicAuthentication',
),
}
# JWT_EXPIRATION_DELTA 指明token的有效期
JWT_AUTH = {
'JWT_EXPIRATION_DELTA': datetime.timedelta(days=1),
}
在settings配置文件中直接就生成了一个serect_key,我们直接可以使用它作为我们jwt的serect_key,其实drf-jwt默认配置中就使用的它。
手动生成jwt
Django REST framework JWT 扩展的说明文档中提供了手动签发JWT的方法
from rest_framework_jwt.settings import api_settings
jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER
jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER
payload = jwt_payload_handler(user)
token = jwt_encode_handler(payload)
在用户注册或登录成功后,在序列化器中返回用户信息以后同时返回token即可。
后端实现登陆认证接口
Django REST framework JWT提供了登录获取token的视图,可以直接使用
在子应用路由urls.py中
from rest_framework_jwt.views import obtain_jwt_token
urlpatterns = [
path(r'login/', obtain_jwt_token),
]
注意:
jwt是通过username和password来进行登录认证处理的,所以我们要给真实数据,jwt会去我们配置的user表中去查询用户数据的。所以jwt的框架还是比较重的。