Window编译Opencv CUDA
编译步骤:
本文写的是注意事项,不是完整流程:
dnn cuda编译
OpenCV4.4版本 DNN模块使用CUDA加速教程 VS2017 Window10_猛龙不过江的博客-CSDN博客
opencv mat cuda编译
windows下 编译CUDA版的opencv流程记录_sazass的博客-CSDN博客_opencv编译cuda
https://github.com/opencv/opencv
https://github.com/opencv/opencv_contrib
选择tags,
https://github.com/opencv/opencv_contrib/releases/tag/4.5.4
下载source code.zip
cmake gui对着下载后的根目录,如下图:

第一轮编译报错:
1.python版本报错,因为不用python,忽略掉
2.
CMake Warning at cmake/OpenCVDownload.cmake:202 (message):
IPPICV: Download failed: 35;"SSL connect error"
For details please refer to the download log file:
下载失败解决:
进入opencv-4.5.4\3rdparty\ffmpeg目录
将 ffmpeg.cmake 的https://raw.githubusercontent.com
修改为:https://raw.staticdn.net
把代理关掉,下载再失败,自己去url里下载下来,拷贝到目录.cache\ffmpeg
3.
CMake Warning at cmake/OpenCVDownload.cmake:202 (message):
FFMPEG: Download failed: 6;"Couldn't resolve host name"
For details please refer to the download log file:
CMake Warning at cmake/OpenCVDownload.cmake:202 (message):
ADE: Download failed: 28;"Timeout was reached"
For details please refer to the download log file:
4.3等待第一轮编译完成后,勾选:BUILD_opencv_world
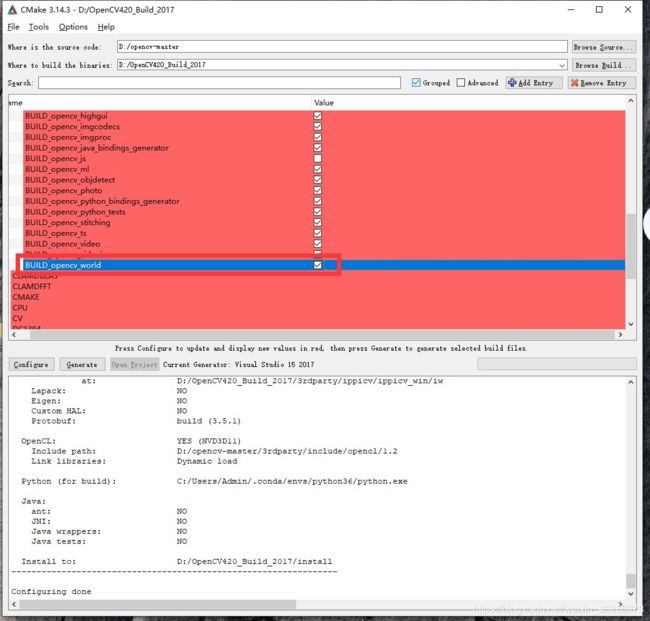
以及,勾选OPENCV_DNN_CUDA,选择解压好的opencv_contrib中modules路径添加进来。

勾选OPENCV_DNN_CUDA,
OPENCV_EXTRA_MODURES_PATH:

勾选 WITH_CUDA:
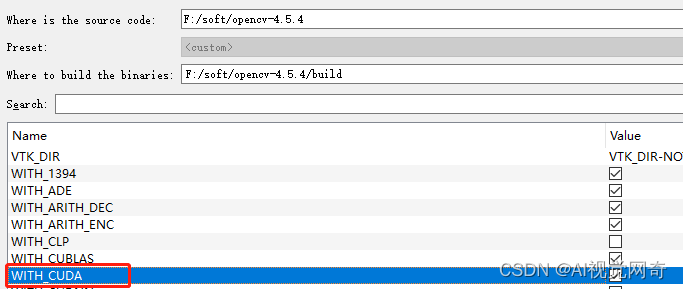
在OPENCV_EXTRA_MODULES_PATH 填入opencv_contrib/modules路径:
需要转化为右斜杠,否则会报错,"\r"
D:/project/opencv/opencv_contrib-4.5.4/modules
vs2017 社区版 generaer报错:
opencv threads:threads but the target was not found
vs2017 专业版编译ok。
https://blog.csdn.net/qq_30623591/article/details/82084113
opencv+CUDA9.1+vs2015环境搭建,编译opencv库,调用GPU加速运算_公子_羽的博客-CSDN博客_opencv 编译cuda
windows上编译自己的opencv(含cuda) - 知乎
使用OpenCV操作CUDA 图像_jacke121的专栏-CSDN博客
cuda11变化:
把cub目录提高到根目录下了。
#include
#include
使用OpenCV操作CUDA送检图像到TensorRT(SSD模型)_ikevin的专栏-CSDN博客
Cuda::GpuMat imageGpu(cv::Size(640,480),CV_32FC4);
Capture>> frame;
cvtColor(frame,imageRGBA,CV_RGB2BGRA);
imageRGBA.convertTo(imageRGBA, CV_32FC4,4);
imageGpu.upload(imageRGBA);
...
// Here is the memory data allocated when getting the GPU corresponding to the above upload
// That is, imageNetMean's first parameter parameter
(float4*)imageGpu.ptr()
cudaError_t cudaPreImageNetMean(float4* input, size_t inputWidth,
Size_t inputHeight,float* output,size_t outputWidth, size_t outputHeight,
Const float3& mean_value );
完整代码:GitHub - wkexinw/tensorSSD: Deep-Learn model SSD_300x300 transplante to TensorRT(Nvidia Jetson Tx2)
for (int i = 0; i < 8; i++) {
std::string file_name = "D:/work/SDKProject/NeuroDetectionV1/fastertest/testimg/1111/4DA9523CCE2B649D39496741D6E3284E1330013_c.jpg";
cv::Mat image = cv::imread(file_name);
//std::cout << "image:" << filelist[i] << std::endl;
if (image.empty()) {
std::cout << "读入图片为空,请检查路径!" << std::endl;
system("pause");
return -1;
}
DWORD start2 = GetTickCount();
//cv::Mat imageRGB;
//image.convertTo(imageRGB, CV_32FC3, 3);
//cv::cuda::GpuMat imageGpu(cv::Size(image.cols, image.rows), CV_32FC3);
//imageGpu.upload(imageRGB);
cv::cuda::GpuMat imageGpu(cv::Size(image.cols, image.rows), CV_8UC3);
cv::cuda::GpuMat imageRGB;
imageGpu.upload(image);
imageGpu.convertTo(imageRGB, CV_32FC3, 3);
DWORD end2 = GetTickCount();
std::cout << "gpu img time:" << end2 - start2 << "ms " << image.cols << " " << image.rows << std::endl;
DWORD start3 = GetTickCount();
std::vector img;
//width and height of input image
int height = image.rows;
int width = image.cols;
img = convertMat2Vector(image);
std::vector data(1 * height * width * 3, 0);
for (int i = 0; i < height * width * 3; i++)
data[0 * height * width * 3 + i] = img[i];
DWORD end3 = GetTickCount();
std::cout << "cpu img time:" << end3 - start3 << "ms " << image.cols << " " << image.rows << std::endl;
} segmentation/trt_sample.cpp at d86c237e1191f159d39e115df13d691ab65752c2 · novaHardware/segmentation · GitHub
// preprocessing stage ------------------------------------------------------------------------------------------------
void preprocessImage(const std::string& image_path, float* gpu_input, const nvinfer1::Dims& dims)
{
// read input image
cv::Mat frame = cv::imread(image_path);
if (frame.empty())
{
std::cerr << "Input image " << image_path << " load failed\n";
return;
}
cv::cuda::GpuMat gpu_frame;
// upload image to GPU
gpu_frame.upload(frame);
auto input_width = dims.d[2];
auto input_height = dims.d[1];
auto channels = dims.d[0];
auto input_size = cv::Size(input_width, input_height);
// resize
cv::cuda::GpuMat resized;
cv::cuda::resize(gpu_frame, resized, input_size, 0, 0, cv::INTER_NEAREST);
// normalize
cv::cuda::GpuMat flt_image;
resized.convertTo(flt_image, CV_32FC3, 1.f / 255.f);
cv::cuda::subtract(flt_image, cv::Scalar(0.485f, 0.456f, 0.406f), flt_image, cv::noArray(), -1);
cv::cuda::divide(flt_image, cv::Scalar(0.229f, 0.224f, 0.225f), flt_image, 1, -1);
// to tensor
std::vector chw;
for (size_t i = 0; i < channels; ++i)
{
chw.emplace_back(cv::cuda::GpuMat(input_size, CV_32FC1, gpu_input + i * input_width * input_height));
}
cv::cuda::split(flt_image, chw);
}