rapidminer decision tree(决策树)手册

目录
概要
描述
分化
输入
输出
参数
教程流程
训练决策树模型
训练决策树模型并应用它来预测结果
回归
概要
此运算符生成可用于分类和回归的决策树模型。
描述
决策树是类似于节点集合的树,旨在创建有关与类的值隶属关系或数字目标值估计值的决策。每个节点表示一个特定属性的拆分规则。对于分类,此规则将属于不同类的值分开,对于回归,它将它们分开,以便以最佳方式减少所选参数条件的误差。
重复构建新节点,直到满足停止条件。类标签属性的预测是根据在生成过程中到达此叶子的大多数示例来确定的,而数值的估计值是通过对叶子中的值求平均值来获得的。
此运算符可以处理包含名义属性和数字属性的示例集。标签属性对于分类必须是名义的,对于回归,标签属性必须是数字。
生成后,可以使用“应用模型”运算符将决策树模型应用于新示例。每个示例都按照拆分规则跟踪树的分支,直到到达叶子。
要配置诊断树,请阅读有关参数的文档,如下所述。
分化
![]()
CHAID 运算符提供了一个修剪的决策树,该决策树使用基于卡方的标准,而不是信息增益或增益比标准。此运算符不能应用于具有数字属性的示例集,而只能应用于名义属性。
![]()
ID3 运算符提供了未运行决策树的基本实现。它仅适用于具有名义属性的示例集。
![]()
随机森林运算符在不同的示例子集上创建多个随机树。生成的模型基于所有这些树的投票。由于这种差异,它不容易过度训练。
![]()
Bootstrap聚合(bagging)是一种机器学习集成元算法,用于在稳定性和分类准确性方面改进分类和回归模型。它还减少了方差,并有助于避免“过拟合”。尽管它通常应用于决策树模型,但它可以与任何类型的模型一起使用。
输入
-
训练集(数据表)
用于生成决策树模型的输入数据。
输出
-
模型(决策树)
决策树模型从此输出端口提供。
- 示例集(数据表)
作为输入给出的示例集将传递,而不会通过此端口更改为输出。
-
权重(属性权重)
包含属性和权重值的示例集,其中每个权重表示给定属性的特征重要性。权重由在节点上提供的给定属性的选择的改进总和给出。改进程度取决于所选的标准。
参数
- 标准
选择将在其上选择属性进行拆分的条件。对于这些条件中的每一个,都会根据所选条件优化拆分值。它可以具有以下值之一:
- information_gain:计算所有属性的熵,并选择熵最小的属性进行拆分。此方法偏向于选择具有大量值的属性。
- gain_ratio:信息增益的变体,可调整每个属性的信息增益,以允许属性值的广度和一致性。
- gini_index:标签特征分布之间不相等的度量。对所选属性进行拆分会导致生成的子集的平均基尼指数降低。
- 精度:选择属性进行分割,从而最大限度地提高整个树的精度。
- least_square:选择一个属性进行拆分,该属性可最大程度地减少节点中值的平均值与真实值之间的平方距离。
- maximal_depth
树的深度因示例集的大小和特征而异。此参数用于限制决策树的深度。如果其值设置为“-1”,则最大深度参数对树的深度没有限制。在这种情况下,将构建树,直到满足其他停止条件。如果其值设置为“1”,则会生成具有单个节点的树。
范围: - apply_pruning
决策树模型可以在生成后修剪。如果选中,某些分支将根据置信度参数替换为叶子。
范围: - 信心
此参数指定用于修剪的悲观误差计算的置信水平。
范围: - apply_prepruning
此参数指定在生成决策树模型期间是否应使用比最大深度更多的停止条件。如果选中,则参数最小增益、最小叶片尺寸、最小拆分尺寸和预运行备选方案的数量将用作停止标准。
范围: - minimal_gain
节点的增益是在拆分节点之前计算的。如果节点的增益大于最小增益,则节点被分割。最小的增益值越高,分裂就越少,树就越小。值太高将完全阻止拆分,并生成具有单个节点的树。
范围: - minimal_leaf_size
叶子的大小是其子集中的示例数。树的生成方式是,每个叶子至少具有示例的最小叶子大小数。
范围: - minimal_size_for_split
节点的大小是其子集中的示例数。仅拆分其大小大于或等于拆分参数的最小大小的节点。
范围: - number_of_prepruning_alternatives
当通过在某个节点上预运行来阻止拆分时,此参数将调整测试用于拆分的备用节点的数量。在预运行与树生成过程并行运行时发生。这可以防止在某些节点上进行拆分,而在该节点上进行拆分不会增加整个树的判别力。在这种情况下,将尝试拆分备用节点。
范围:
教程流程
训练决策树模型
目标:RapidMiner Studio附带了一个名为“Golf”的示例数据集。这包含有关天气的属性,即“展望”,“温度”,“湿度”和“风”。这些是决定游戏是否可以玩的重要功能。我们的目标是训练一个决策树来预测“播放”属性。
使用检索运算符检索“高尔夫”数据集。通过将 Retrieve 的输出端口连接到决策树运算符的输入端口,可以将此数据馈送到决策树运算符。单击“运行”按钮。这将训练决策树模型并转到结果视图,您可以在其中以图形方式和文本描述对其进行检查。
树显示,每当属性“Outlook”具有“overcast”值时,属性“播放”将具有值“yes”。如果属性“Outlook”具有值“雨”,则可能有两种结果:
a) 如果属性“风”的值为“false”,则“播放”属性的值为“yes”
b) 如果“风”属性的值为“true”,则属性“Play”为“no”。
最后,如果属性“Outlook”具有“sunny”值,则还有两种可能性。
如果属性“湿度”的值小于或等于 77.5,则属性“播放”为“是”;如果“湿度”大于 77.5,则属性“播放”为“否”。
在此示例中,叶节点仅指向标签 Attribute 的两个可能值之一。“播放”属性为“是”或“否”,这表明树模型与数据非常拟合。

训练决策树模型并应用它来预测结果
目标:在本教程中,显示了使用决策树的预测分析过程。它比第一个教程略高级。它还引入了基本但重要的概念,例如将数据集拆分为两个分区。较大的一半用于训练决策树模型,较小的一半用于测试它。我们的目标是看看树模型在测试数据集中预测乘客命运的能力有多好。
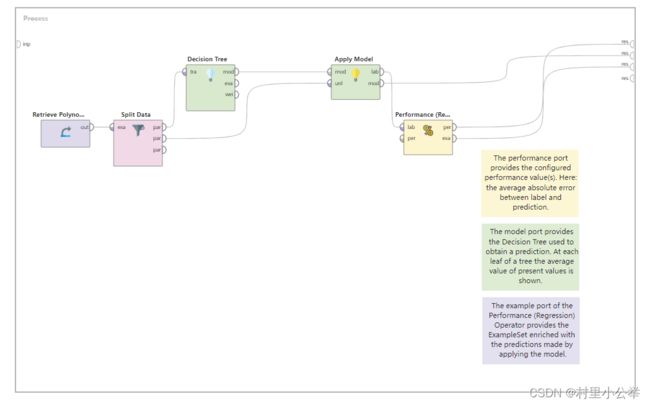
回归
在本教程中,决策树用于回归。具有数字目标属性的“Polynominal”数据集用作标签。在训练模型之前,数据集被拆分为训练集和测试集。然后,将回归值与标签值进行比较,以使用性能(回归)运算符获得性能度量值。