关于在线评论有用性的论文研读笔记---10篇
目录
1 在线评论的行为影响与价值应用研究综述(中国管理科学)
2 评论有用性相关的论文
2.1 基于知识采纳模型和多层感知机神经网络的评论有用性识别研究(中国管理科学)
2.2 消费者认为怎样的在线评论更有用?— —社会性因素的影响效应(管理世界)
2.3 融合 Word2vec 和WGRA的社会化问答社区答案有用性排序方法研究———以携程问答为例(图书情报工作)
2.4 基于模糊 TOPSIS 分析的在线评论有用性排序过滤模型研究———以亚马逊手机评论为例(图书情报工作)
2.5 表情符号多余吗?———表情符号对在线产品评论感知有用性的影响研究(管理工程学报)
2.6 基于领域情感词典的用户生成内容有用性评价研究———以豆瓣读书为例(情报理论与实践)
2.7 在线评论有用性的深度数据挖掘——基于 TripAdvisor 的酒店评论数据(旅游管理)
2.8 融合信息增益和梯度下降算法的在线评论有用程度预测模型(计算机科学)
2.9 基于在线评论数据的产品需求趋势挖掘(中国管理科学)
3 总结
1 在线评论的行为影响与价值应用研究综述(中国管理科学)
在线评论通常定义为电子商务或者第三方网站上消费者发表的产品评价。主要表现形式为星级打分(1至5颗星)和开放式评论文本。随着社交网络的发展,消费者倾向通过社交媒体分享购物体验,并且在购买之前浏览在线评论。在线评论作为一种新的口碑形式,摆脱传统口碑的社交关系约束。传播 范围广,对消费者行为产生强烈的影响。企业为适应在线评论环境,对市场营销、产品设计等经营决策行为做出调整。
在线评论可以影响消费者的购物决策,进而影响到企业产品的销量,因此也势必会影响企业的经营决策。
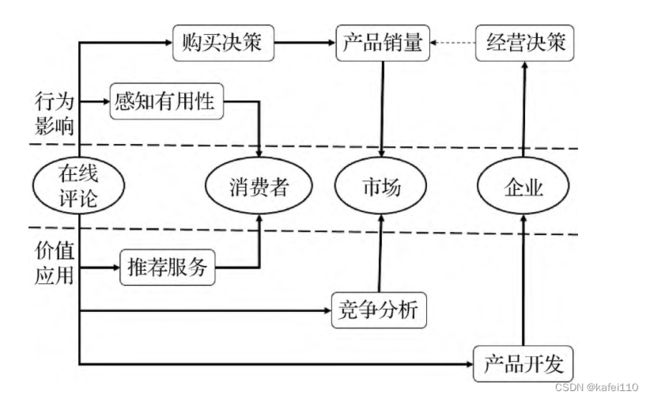
产品在线评论的研究有许多方向,本文将研究分为了行为影响与价值应用两大类的研究。在行为影响层面分三个方面:消费者行为层面上,主要研究消费者对于评论的感知有用性(即消费者认为什么样的在线评论是有价值的);在线评论对于购买意愿的影响,许多研究主要应用计量经济学、统计学的方法来进行定性定量的研究;在线评论对于企业经营决策的影响,企业可以根据在线评论中含有的产品信息来进行产品的调整以及产品价格的调整。
在价值应用层面主要有四个方面的研究:在线评论关键信息的提取,分别是产品属性的提取以及对于消费者情感特征的提取;在线评论的推荐服务,在线平台的评论都是依靠有用性投票或者点赞数来对评论进行推荐,最新发布的评论往往没有足够的投票而无法获得推荐,但是新的评论中可能含有对于消费者而言的有用信息,因此需要根据一定的方法对在线评论进行排序和推荐,降低消费者的信息检索成本和阅读成本;面向市场的竞争分析;面向制造业的产品开发,在线评论可以为制造业提供消费者对于产品的效用感知以及产品中可能存在的质量缺陷等等。

这篇文章较为清晰的展现了在线评论领域的几个研究方向,能够帮助研究者有针对性、有条理性的对在线评论领域进行研究,初次阅读,因此我从评论有用性相关的文献先入手阅读。
2 评论有用性相关的论文
评论有用性识别主要是从评论数据中提取出评论相关的特征,然后构建机器学习模型对参数进行学习;但是机器学习方法需要人工标注数据,比较耗费时间,因此也可以通过排序算法来进行评论的排序,同样可以筛选出有用评论。
2.1 基于知识采纳模型和多层感知机神经网络的评论有用性识别研究(中国管理科学)
这篇文章基于知识采纳模型(KAM)和多层感知机神经网络对评论的有用性进行识别。评论的文本语料主要来源于知乎,总共爬取了9000多条答案文本,题材为中医领域。KAM理论认为感知信息有用性取决于两方面的内容,分别是信息的质量,另一方面是信息来源的可信度。

在文本表示上,采用了词袋法进行表示,表示方式较为简单,不能表示词语之间的相近程度。
在构建机器学习自变量特征时,主要从评论数据中抽取以下特征:评论句子数量、停用词占比、领域词占比、评论回复数量、作者粉丝数量、作者获赞数量。在提取出特征之后对所有变量做了归一化的处理,避免变量量纲的影响。

模型的因变量或者标签就是评论是否有用,1表示评论有用,-1表示评论没用,文章根据评论的点赞量自动划分评论是否有用,选择了100条评论并且进行人工验证,提出了最合适的评论划分阈值,然后对所有评论进行划分。但是这种方法的问题就是日期较近的新评论肯定就没办法。 在模型选择上,主要选择了多层神经网络、SVM、NB,并且尝试了不同特征的学习效果,最终得出多层神经网络的数据拟合能力最好。
总体而言,模型的特征选择比较简单,文本表示方法也较为简单,机器学习方面的理论也比较容易懂,但是我感觉有点过于简单了,没有去考虑评论的情感特征,总感觉还有很多方面的内容可以补充。但是这篇文章依然发表在了中国管理科学上。
2.2 消费者认为怎样的在线评论更有用?— —社会性因素的影响效应(管理世界)
这篇文章是在线评论领域高引用的一篇文章,这篇论文实证分析了各种特征对于评论有用性的影响。文章基于启发—系统式模型(Heuristic-Systematic Model,HSM)为分析框架,基于从众效应、社会网络等视角以及一系列社会因素来说明了在线评论如何影响消费者。
HSM模型揭示了消费者在得到信息时,会从两方面考察信息的可靠性,一是直观信息,另一部分是信息来源相关的信息,文章提出在该文章发表之前,关于评论者社会背景的信息研究较少,因此文章中讨论评论有用性时纳入了评论者社会背景信息。
评论有用性的自变量包括评论长度、评论及时性、评论者的网络中心度、评论者的关系多样性、评论者的经验技能、平均星级差异。评论者的网络中心度分为两个维度,分别为内向和外向网络中心度,内向网络中心度可以用评论者的粉丝数来衡量,外向网络中心度可以用评论者关注的人数来衡量,评论者的关系多样性可以用加入的群组数量来衡量,评论者的经验技能用发表的评论数量来衡量。评论有用性的因变量用有用性投票来衡量。

文章得出:评论长度对评论有用性的影响呈倒U型的关系、除了评论者的经验技能外,其余因素对于评论有用性均有正向的影响。
2.3 融合 Word2vec 和WGRA的社会化问答社区答案有用性排序方法研究———以携程问答为例(图书情报工作)
这篇文章研究了评论有用性的同时还给出了评论排序的方案,该文章的研究框架是基于IAM的,和前面论文的分析框架一致。文章指出很少有文章将有用性和评论排序同时进行的。
文章度量文本有用性的自变量有9个:文本长度、时效性、图片数量、答案评论数量、属性描述词、情感分析、答案获赞、回答者粉丝数、回答者获赞数。

文章引入了熵权法度量了9个自变量的重要性权重,在数据归一化处理后,通过每个变量的熵值来确定每个变量的权重。评论文本的有用性由两个部分构成,分别是加权灰色关联分析确定的关联度,另一部分是基于word2vec生成的词向量均值与答案文本的词向量均值的夹角余弦值。
灰色关联分析法可以用于确定数列与参考数列的关联度,这里算法不具体给出,CSDN上有具体的算例,参考数列是由每一个变量的最优值构成的虚拟的数列,这可以参考TOPSIS算法,与理想点的原理一样。加权体现在最后一步,计算每个评论文本的关联度得分时,权重不是1/n,而是由熵权法确定的产品权重。
最终得分为P = 0.25γ + 0.75S(A, B),γ是加权灰色关联度得分,S(A,B)为word2vec夹角余弦值。
总体来说文章的工作量还是很大的,方法也很多,我觉得问题是WGRA过程中理想点的确定存在问题,对于评论文本的长度、评论文本的数量这些特征你很难确定一个具体的数值,说这个数值是最优的,因人而异。
2.4 基于模糊 TOPSIS 分析的在线评论有用性排序过滤模型研究———以亚马逊手机评论为例(图书情报工作)
这篇文章的研究逻辑与2.3的论文有点类似。
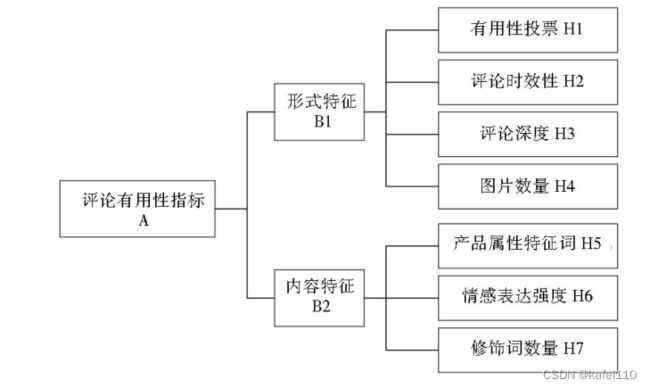
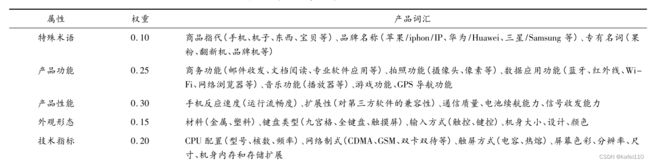
文章度量评论有用性的指标包括文本的形式特征和内容特征,一共7个维度特征,分别是有用性投票、评论时效性、评论深度、图片数量、产品属性特征词、情感表达强度、修饰词数量。对于线性模型而言,模型参数会受到特征分布的影响,因此在进行模型拟合之前,总是需要对数据进行一定的预处理,评论失效性文章提出了一种处理方法。对于评论深度,之前的文章都是单纯的用评论文本的长度来度量的,但是消费者真正阅读评论更多的关注点在于评论中的关键词或者关键语句,文章也提出了一种对于评论文本长度的处理方法。情感表达强度则是用特殊关键词或者特殊句式来量化的,这里应该可以结合word2vec来进行更细致的处理。同时文章给出了手机产品术语的重要性权重。
基于判断矩阵,采用最小二乘法可以得到每个属性的权重,对于评论的排序则可以采取TOPSIS法,通过判断样本与正负理想点的距离来对样本进行排序。
这篇文章我的收获是获得了样本有用性度量特征的处理方法,对特征进行合理的处理能够得到更加合理的排序结果,如果不考虑有用性投票,仅仅考虑每条评论所包含的信息量,评论排序的结果可能会更有意思。
2.5 表情符号多余吗?———表情符号对在线产品评论感知有用性的影响研究(管理工程学报)
该文章指出现有关于在线评论感知有用性的研究主要为以下两个方面。一方面,之前的研究聚焦于评论的结构化特征,如评论有用性投票、评论发表的时间、产品或评论者的特征对有用性的影响。另一方面,现在开始有研究关注评论的文字信息所表达的情感这类非结构化特征,即,评论中的情感线索能否对消费者产生实质性的影响。然而,现有研究关注的情绪化表达聚焦于语言表达方式,即语言线索,却仅有零星的研究关注在线评论中出现表情符号这类非语言线索对在线评论感知有用性产生的效应。为了验证表情符号对于评论有用性是否有影响,文章提出了分析的框架以及对应的实验。
表情符号是一种文字之外的语言( text paralanguage,TPL),可以是键盘符号、图形或动画所构成的人类面部表情或身体姿势的抽象形式,用以表达情感、态度等信息的非语言传播符号,是一种情绪化表达。表情符号通过影响消费者的感知温暖(例如我加一个笑脸,你就觉得暖暖的),进而提高了消费者对于评论的评价。不同的消费者认知风格、不同的产品类型、不同的写作风格都会影响EMOJI对消费者的影响,因此不同学者的研究可能会得出不同的结论。

然后文章给出了研究的框架以及一系列检验,得出了很多结论:
认知风格(言语型与视觉型)的调节效应: 对于视觉型认知风格者,积极表情符号通过提高感知
温暖进而提高感知有用性;对于言语型认知风格者,积极表情符号对感知温暖无显著影响,进而也对感知有用性无显著性影响。
产品类型(实用品与享乐品)的调节效应。 产品类型调节了积极表情符号与感知温暖、评论感知有用性之间的中介关系,即积极表情符号能提高实用型产品的感知温暖,进而提高评论的感知有用性,却对享乐型产品的感知温暖与评论的感知有用性无显著影响。
对于客观事实型评论,产品类型显著调节了中介路径“表情符号→感知温暖→感知有用性”。 对于实用品的客观事实型评论,“表情符号→感知温暖→感知有用性”的中介效应显著;对于享乐品的客观事实型评论,“表情符号→感知温暖→感知有用性”的中介效应不显著。
对于主观评价型评论,产品类型未显著调节中介路径“表情符号→感知温暖→感知有用性”。 对于实用品与享乐品的主观评论,“表情符号→感知温暖→感知有用性”的中介效应均不显著。
因此,在后面有用评论的筛选中,可以加入度量EMOJI的指标!
2.6 基于领域情感词典的用户生成内容有用性评价研究———以豆瓣读书为例(情报理论与实践)
该文章融合了领域情感词典与信息熵的方法来评价评论的有用性。信息熵的方法在目前的文献里面还是比较新颖的方法。文章选取了评论长度、评论规范性、情感倾向、发表时间等来作为自变量。

评价模型共分为四个部分。第一部分,数据获取与预处理中,选取图书领域用户语料内容, 划分测试集与训练集,对数据进行有用性标注,构成实验的因变量数据。第二部分对训练集数据进行处理,包括分词、词性标注、情感得分计算、信息熵计算,构成分类实验的自变量数据。第三部分为特征生成,计算评论的负向情感得分,正向情感得分与信息增益值;负向情感得分为分词后的句子中所有负向词汇得分的总和,正向得分同理;信息增益的计算则建立在信息嫡的基础上得出。第四部分为情感词典效果评价部分,选择合适的机器学习分类方法,利用特征对训练集的数据进行分类模型训练,即通过离线指标测试其在实验集的表现水平,验证情感特征对评论有用性预测是否有影响。 最终只有三个变量进入机器学习模型即情感得分和信息增益值。因变量是人工标注的评论有用性。
情感值的度量是基于情感词典来计算的,情感词典中的情感词语分极性,总得分为极性的加总,基于最长匹配规则从评论文本中去匹配情感词语。信息熵的计算比较新式,关于信息熵的内容可以参考我写的决策树的博客。整个文档分词之后整理之后可以得到一系列不重复的词语,对数据进行标注之后就可以计算整个文档的熵值以及每个词语的信息增益,然后用每个评论的信息增益总和来表示文本的有效信息量。
基于信息熵的度量有用性很高,但是他需要基于标注数据,工作量较大。整篇文章关于熵的概念可能会晦涩一些,同时在度量情感方面可以进一步改进,因为这篇文章只是度量了文章的总体情感,情感是有指向性的,这种指向性没有很好的体现出来,是一个可以改进的方向。
2.7 在线评论有用性的深度数据挖掘——基于 TripAdvisor 的酒店评论数据(旅游管理)
这篇文章基于HSM分析框架,用word2vec和LDA等机器学习的方法来量化评论文本中的变量,用word2vec的方法来计算没有点赞的评论文本与点赞数量多的评论文本的夹角余弦值,来估计零点赞的评论文本的预计点赞数,并且用机器学习的方法来学习评论文本中的情感。
文章指出现有评论语义分析方法相对简单,以关键词、主客观词语为参考或根据词典判断情感为主,未从评论主题角度深度挖掘,存在量化依据不够准确、参照词典相对静态、不能完全涵盖中文表达的丰富含义等问题;基于现有研究存在的不足,本文采用Word2Vec算法,根据有用评论计算零有用票数评论的有用性,可弥补零有用票数评论有用性分数的缺失;在语义分析中,针对酒店行业关键词众多的特点,本文运用具有分类、归纳功能的LDA模型,基于词频与词汇重要性不一致的考虑将TF-IDF方法与LDA模型相结合,深入挖掘评论的语义内涵。
文章选取了历史评论数、评论者类型、评论长度、评论时间、是否有照片、评论语义、评论情感、酒店品牌、所属地域来作为度量评论有用性的自变量。评论的点赞数作为评论有用性的因变量(这里需要提一嘴,以点赞数作为因变量,因为问题是一个二分类问题,所以需要设置一个阈值来将有用评论与无用评论区别开来。)
其中评论语义指的是通过LDA模型提取出的评论文本中的主题,评论情感是通过人工标注的方法对数据集进行正负类标记,然后通过机器学习模型去拟合评论文本的情感,这种方法也是对评论文本整体感情的预测方法,仍然没有对产品的属性情感进行度量,且相对于情感词典的方法而言更加费力。

最终文章通过多元线性回归的方法验证了各种变量与评论有用性之间的相关性。这篇文章给出的建议部分我感觉还不错:第一,若浏览者只想阅读长度为150字以内的评论,则经过筛选后只展示符合条件的评论。第二,在线旅游平台除了提供酒店信息之外,还有很多如餐厅、旅游景点等其他浏览者需要的内容,因此可以针对不同的评论对象提取对应关键字,如酒店的关键字可以是“床”“吃”“交通”“泳池”等,餐厅的关键字可以是“味道”“特色菜”“卫生”“快慢”等,关键字还可以包含评论对象的特征或地方特色,让浏览者能够快速筛选出感兴趣的内容。第三,很多在线旅游平台已经通过提取评论中的所有照片形成照片库,以辅助浏览者快速查看评论照片,同时还可以让浏览者选择优先查看含有照片的评论,图文结合更有利于信息传递。
2.8 融合信息增益和梯度下降算法的在线评论有用程度预测模型(计算机科学)
这篇文章相对来讲还是好懂的,采用的方法在前面的论文中都有应用,论文的研究流程如下:

文章采用了三个变量来衡量评论的有用性:文章词语的数量(做了对数化处理)、词语有用性的熵值总和、产品特征的词语数量(做了对数化处理) 。
评论的有用性则采取了分段函数的方式将评论的有用性按照点赞数量的方式进行分级度量。
剩余的方法和过程与前文的方式类似。
2.9 基于在线评论数据的产品需求趋势挖掘(中国管理科学)
这篇文章更是重量级,这篇文章是我最早看的一篇论文,是被这篇文章带到在线评论领域研究来的,特地来复习了一下这篇文章。该文章结合了前面评论有用性筛选的方法,筛选出有用评论之后然后结合时间序列模型去分析了产品属性感情的变化趋势。在有用性方面,这篇文章更加侧重制造业视角的评论有用性研究。首先给出文章的研究框架:
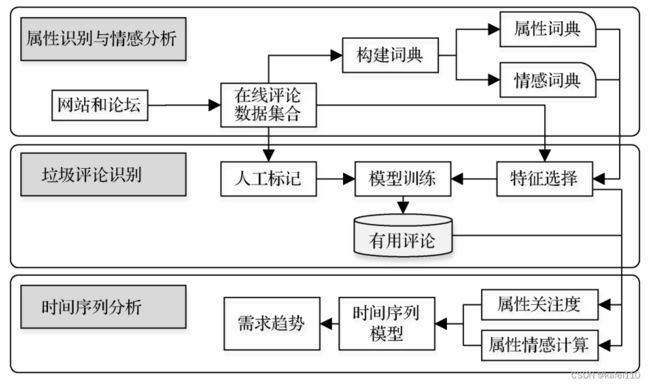
首先从汽车论坛中抓取评论文本,总量有400W条文本,然后提取出频繁出现的名词或者名词短语作为候选的产品属性词典,再从候选词典中筛选出最终的名词和名词短语作为属性词典;情感词典方面则是根据窗口法,在产品属性词语的后面区域搜寻形容词,并根据形容词来判断产品情感的极性,如果后面没有就看前三个词语,同时要注意是否有否定词语,如果找不到情感词语,则用文本的整体情感来代替属性情感。
在垃圾评论的筛选模型中,采用了以下变量:

并且根据前面几篇论文的信息熵的方法,提取了文本的信息熵总和信息来加入到自变量中,因变量则是人工标注的0\1标签。在机器学习模型上,该文章采取了采用核方法的SVM模型来进行参数拟合。选取了1000多条标注数据,然后训练模型。最终从文本中筛选出300W条有用文本。
文章中说的情感词典的训练方法我没有get到他的意思,但是总之他还是训练出来了一个情感词典,对于文本情感的判断依然是基于情感词典的。
在时间趋势的研究上,文章根据每一个产品属性的关注度来刻画时间序列模型,采取了非参数指数平滑模型HOLT--WINTERS模型来进行模型拟合。

文章最终得到的结论也比较漂亮,技术难度来讲比前面的几篇文章要大很多,只不过文章自己提出的文本情感方面没有做情感细粒度的度量,可以是一个改进方向。
3 总结
评论有用性可以用到的特征:
评论句子数量、停用词占比、领域词占比、评论回复数量、作者粉丝数量、作者获赞数量
评论长度、评论及时性、评论者的网络中心度、评论者的关系多样性、评论者的经验技能、平均星级差异
文本长度、时效性、图片数量、答案评论数量、属性描述词、情感分析、答案获赞、回答者粉丝数、回答者获赞数
有用性投票、评论时效性、评论深度、图片数量、产品属性特征词、情感表达强度、修饰词数量
EMOJI的数量
是否存在领域词语
可以留到后面写论文的时候拿出来参考一下。