李航统计学习方法----感知机章节学习笔记以及python代码
目录
1 感知机模型
2 感知机学习策略
2.1 数据集的线性可分性
2.2 感知机学习策略
3 感知机学习算法
3.1 感知机学习算法的原始形式
3.2 感知机算法的对偶形式
4 感知机算法python代码
感知机(perceptron)是二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1和-1二值.感知机对应于输入空间(特征空间〉中将实例划分为正负两类的分离超平面,属于判别模型.感知机学习旨在求出将训练数据进行线性划分的分离超平面。为此,导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型.感知机学习算法具有简单而易于实现的优点,分为原始形式和对偶形式.感知机预测是用学习得到的感知机模型对新的输入实例进行分类.感知机1957年由Rosenblatt提出,是神经网络与支持向量机的基础.
1 感知机模型
假设输入空间(特征空间)是x是n维列向量,输出空间是y={+1,-1}.输入x表示实例的特征向量,对应于输入空间(特征空间)的点;输出y表示实例的类别.由输入空间到输出空间的如下函数,其中sign是符号函数:
其中![]() 是分离超平面,在几何上表示为下图,正类样本是与分离超平面法向量夹角余弦值为正的点,负类样本则是夹角余弦值为负的点。
是分离超平面,在几何上表示为下图,正类样本是与分离超平面法向量夹角余弦值为正的点,负类样本则是夹角余弦值为负的点。

2 感知机学习策略
2.1 数据集的线性可分性
数据集可以被一个超平面完全正确的分成两个部分,则称数据集是线性可分的。否则是线性不可分的,现实中的数据集往往是线性不可分的。
2.2 感知机学习策略
假设数据集是线性可分的,感知机的目的就是求得一个是正负类样本完全正确分离的超平面。为了找到这个超平面,需要找到感知机模型的参数w和b。同时还要确定一个学习策略,来使损失函数极小化。损失函数一般要可导,这里损失函数的思想是所有误分类的点到超平面的总距离。其中![]() 是超平面的模长。
是超平面的模长。
对于误分类的点来说:
假设所有误分类的样本都属于集合M,并且忽略掉超平面的模长,那么就可以得到所有误分类的点到达超平面的总距离为:
![]()
损失函数连续可导,并且在正确分类时,损失函数值为0。
3 感知机学习算法
由于损失函数连续可导的性质,梯度下降法就相当NICE了。整体函数的优化目标是使得损失函数最小化。
3.1 感知机学习算法的原始形式
给定一个训练数据集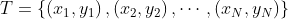 ,要使得损失函数最小,其中M是误分类点的集合:
,要使得损失函数最小,其中M是误分类点的集合:
![]()
损失函数关于两个参数的梯度为:
李航的书中采用了随机梯度下降的策略对数据集进行学习,即每次只选取一个误分类的点对参数进行学习,避免了运算的复杂度:
![]()
其中η为学习率,是超参数,可以自己进行调整。其中在实现这个算法的时候比较关键的一个就确定误分类的点集,只要确定了点集,梯度下降就比较好实现。
同时需要注意算法的收敛性,只有数据集完全线性可分的情况下,才可以在有限次搜索下得到分离超平面,如果数据集不完全线性可分,算法就会震荡。
3.2 感知机算法的对偶形式
对偶问题是将参数w和b表示成关于所有点的增量形式:
![]()
那么感知机模型就变成了:
![]()
继续采用随机梯度下降算法,那么参数的更新规则就变成了下式:
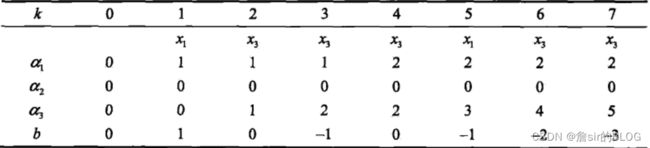
这个更新规则可以这样理解,首先是误分类点集,只有错误分类了才会体现在损失函数中,因此只有错误分类的点才可以进行乘子的更新,其次是随机梯度下降,每次只拿出一个点来进行学习,因此只更新有问题的那个点的乘子,更新规则好像不是根据梯度求导得出的,求导的结果应该不是1,但是更新规则是直接加上个学习率,就方便很多。对偶思想在后面的支持向量机还会再讲,这里就当个引入把。
4 感知机算法python代码
import numpy as np
def data_set(n, p, seed=20220227): # 构造数据集,特征矩阵shape=(n, p)
np.random.seed(seed)
w = np.random.uniform(-3, 3, p)
b = np.random.uniform(-3, 3, 1)
x = np.random.uniform(-10, 10, (n, p))
y = np.apply_along_axis(lambda s: 1 if (s*w).sum()+b >= 0 else -1, axis=1, arr=x)
return x, y, np.concatenate((w, b))
def perception(x, y, lr=0.6): # x为特征矩阵,y为label(一维数组)
n, p = x.shape
w = np.zeros(p)
b = np.zeros(1)
i = 0
while not (np.where(((x*w).sum(axis=1)+b) >= 0, 1, -1) == y).all():
row = np.random.randint(0, n, 1)[0]
if ((x[row]*w).sum()+b)*y[row] <= 0:
w = w+lr*y[row]*x[row]
b = b+lr*y[row]
i += 1
return np.concatenate((w, b)), i
def perception_dual(x, y, lr=3): # x为特征矩阵,y为label(一维数组)
n, p = x.shape
w = np.zeros(p)
b = np.zeros(1)
alpha = np.zeros(n)
i = 0
while not (np.where(((x*w).sum(axis=1)+b) >= 0, 1, -1) == y).all():
row = np.random.randint(0, n, 1)[0]
if ((x[row]*w).sum()+b)*y[row] <= 0:
alpha[row] += lr
b = b+lr*y[row]
w = x.transpose().dot(alpha)
i += 1
return np.concatenate((w, b)), i
if __name__ == '__main__':
feature, label, paras_true = data_set(3000, 2)
paras_pred, iterations = perception(feature, label)
print('paras_true={}\nparas_pred={}\nparas_pred:paras_true={}\n最后一个数为b,迭代次数为{}'.format(paras_true, paras_pred,
paras_pred/paras_true,
iterations))
# paras_true = [-0.5349794 1.22372565 - 1.88170882]
# paras_pred = [-28.20560145 64.38087154 - 99.]
# paras_pred: paras_true = [52.72278042 52.61054357 52.61175305]
# 最后一个数为b, 迭代次数为1691
feature, label, paras_true = data_set(15, 2)
paras_pred, iterations = perception_dual(feature, label)
print('paras_true={}\nparas_pred={}\nparas_pred:paras_true={}\n最后一个数为b,迭代次数为{}'.format(paras_true, paras_pred,
paras_pred/paras_true,
iterations))
# paras_true = [-0.5349794 1.22372565 - 1.88170882]
# paras_pred = [-22.38115122 15.21081373 6.]
# paras_pred: paras_true = [41.83553837 12.42992148 - 3.18859109]
————————————————
版权声明:本文为CSDN博主「故_kj」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_57494293/article/details/123209704