关于在线评论有用性的论文研读笔记---61-70篇
目录
61.Huang, G. H., Chang, C. T., Bilgihan, A., & Okumus, F. (2020). Helpful or harmful? A double-edged sword of emoticons in online review helpfulness. (Tourism Management)
62.Automatically assessing review helpfulness. In Proceedings of the 2006 Conference on empirical methods in natural language processing
63.Effects of user-provided photos on hotel review helpfulness: An analytical approach with deep leaning. (International Journal of Hospitality Management)
64.Predicting the “helpfulness” of online consumer reviews. (Journal of Business Research)
65.Helpfulness of online reviews: Examining review informativeness and classification thresholds by search products and experience products. (Decision Support Systems)
66.Automatically predicting the helpfulness of online reviews. (In Proceedings of the 2014 IEEE 15th International Conference on Information Reuse and Integration)
67.Artificial intelligence for hospitality big data analytics: developing a prediction model of restaurant review helpfulness for customer decision-making. (International Journal of Contemporary Hospitality Management)
68.Drivers of helpfulness of online hotel reviews: A sentiment and emotion mining approach. (International Journal of Hospitality Management)
69.Enhancing the helpfulness of online consumer reviews: the role of latent (content) factors. (Journal of Interactive Marketing)
70.Predicting users’ review helpfulness: the role of significant review and reviewer characteristics. (Soft Computing)
61.Huang, G. H., Chang, C. T., Bilgihan, A., & Okumus, F. (2020). Helpful or harmful? A double-edged sword of emoticons in online review helpfulness. (Tourism Management)
这篇文章也是研究表情符号对评论有用性的影响的,可以回顾一下之前关于表情符号对评论有用性影响的文章,第40篇文章中用了调查问卷的方式研究了单义表情符号和多义表情符号对评论有用性的影响,第5篇文章也研究了表情符号与顾客的认知风格以及评论的写作风格之间的交互作用,研究表情符号作用的文章目前来看采用的多是调查问卷的方式进行研究的。其实不难判断,在线购物网站中很少有人会去使用表情符号进行评论,即使有表情符号的评论可能效果也不会很理想,因此多是采用调查问卷的形式来进行分析。
文章也是从写作风格出发的,将评论写作风格分为了叙述型写作和列表型写作,表情符号的积极程度以及表情符号是否出现与评论写作风格产生交互作用,共同影响评论的有用性。文章基于cognitive tunning theory来进行分析,认为人们在阅读积极消息时采取的是启发式阅读,而在阅读消极信息时采取的是分析式阅读,外部感情线索也会影响评论的阅读方式,因此表情符号可以作为一个外部线索来影响评论的阅读方式,而阅读方式的不同对不同评论的写作风格的有用性影响也不同。

文章指出在叙述性且感情积极的评论中添加积极的表情符号能够提高评论有用性,在列表型写作风格且感情消极的评论中添加消极的表情符号能够提高评论有用性,但是从图中可以看出来消极评论中其实影响并不是很大,积极评论中有一定的影响,并且文章的数字和表格的数字并不统一,但我不知道为什么这篇文章可以发在这种级别的期刊上。
文章还做了一个大数据实验,拿了4000多条评论数据进行分析,但是没有详细说明特征工程是怎么处理的,也没有给出表格。
总结一下,好像有道理,但是我感觉是rubbish,但是行文思路看起来却又是很牛的样子。
62.Automatically assessing review helpfulness. In Proceedings of the 2006 Conference on empirical methods in natural language processing
这是一篇比较早的从机器学习的角度去研究在线评论有用性的文章,是2006年发表的,但是里面提到的许多特征都是后来研究中的重要特征,文章采用了亚马逊的电子产品来进行建模分析。
首先要确定文章的因变量,文章采用了有用性投票率来进行回归分析,这个指标的确定为后来的研究奠定了基础;在自变量上,文章从多个维度进行分析,首先是结构维度(评论长度、句子数、平均句子长度、换行符和加粗字体),词汇维度(基于tf-idf的词袋模型和N-gram模型),句法维度(各种词性的词语的占比),语义维度(与产品特征有关的情感词、通用的情感词语),超文本维度(星级、星级不一致性)。在模型上,文章采用了SVR模型并采取了RBF核函数,然后进行回归分析。
文章在模型的评价上采用了网页上的排名和预测的排名结果进行相关性分析来验证模型的好坏,后面的文章中进行模型评价时多采用的是MSE或者AUC系列的指标。


由于评价指标的不同,对文章的结果很难去进行评价,同时由于机器学习的限制性,对于特征的现实意义也很难去解释,但是这篇文章所发掘的特征却是相当有用的。
63.Effects of user-provided photos on hotel review helpfulness: An analytical approach with deep leaning. (International Journal of Hospitality Management)
大多数文章对于评论数据中的图片数据都没有进行处理,而是直接提取了图片数量来表示图片对评论有用性的影响,这就默认每张图片都是有用的,并且图片中包含了消费者想要知道的产品特点,但这个是不合理的。这篇文章是从多源异构数据视角下去分析在线评论有用性的,之前的文章中也有几篇也进行了类似方向的研究。对于多源异构数据的处理,这类型的文章都是分别通过不同的网络来对异构数据进行处理,然后将异构数据转换成具有相似结构的压缩数据,最终进行合并,并且进行最终模型的学习训练。可以参考第11篇文章(该文章是通过识别评论图片的标签,然后将标签转化为词向量,最终进行训练的),第45篇文章(该文章采用BERT模型和VGG-16模型来进行异构数据的处理,并自创了损失函数来进行最终的模型训练)。
这篇文章对文本数据采用了RNN网络来进行学习,对于图像则采用了ResNet来进行学习,在学习之前文章做了数据的清洗、样本的配对以及一系列描述性统计的工作,当特征全部被学习出来之后就进行特征的融合。作为一个深度学习的小白,我觉得论文在框架这一块写的还是不够清晰。

基线模型上,文章利用TF-IDF提取词语特征,同时用图片向量的平均值来表示图片的质心,并且用特征选择的方法分别选择重要性前1000的特征放在一起,然后用DT/LR/SVM这三个基本的机器学习模型来进行拟合。
文章先选取了没有照片的评论来进行模型训练,deep1表示只有评论文本的评论。准确率有0.67,然后deep2表示训练的模型在有图片的评论上进行拟合,结果准确率只有0.62,文章的解释是当消费者写评论放图片时,就倾向于少打字,如果没放图片就会多打字。总体上来讲,深度学习的模型表现会比传统的机器学习模型要好。(其实这里有一个问题,就是基线模型太随意了,结果肯定不如精耕细作的深度模型要好,只要base烂,我的模型提升就牛逼)

然后文章又跑了整体得模型,即同时放入了图片和文本,结果提升比较大。
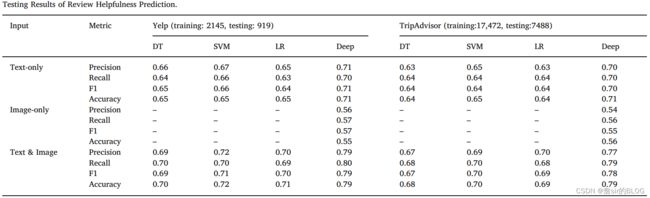
总的来讲,这篇文章做的还是很Nice的,文章结尾还采用了图片夹角余弦值的方式来判断最有用的评论图片和最没用的评论图片,来给管理者和评论者一定的启示。在图片识别和文本识别上可以选择的网络还是比较多的,这也是从这篇文章中得到的启示。
64.Predicting the “helpfulness” of online consumer reviews. (Journal of Business Research)
这篇文章从机器学习的角度去研究了评论有用性,是一篇比较典型的从机器学习类型的文章,不管是行文思路还是变量选取都值得去学习。这篇文章从印度区亚马逊网站中选取了书籍、母婴产品、电子产品来进行在线评论有用性的分析。
在自变量的选取上,文章选取的十分丰富,符合机器学习处理模型时的常规思路,文章提取了情感、主观度、句法、语义、可读性、信息熵、结构化信息等维度的特征来进行模型拟合。在因变量的选取上,我认为文章的选取存在一定的问题,文章采用了评论者总体的有用性投票比例来代表单个评论的有用性投票比例,这会存在一定的问题,因此在这篇文章中,我觉得直接采用有用性投票比例来直接跑回归或许更加合理一些。

在模型上,这篇文章选择了集成模型GBDT来进行训练,指标采取了MSE,然后在三个产品种类中分别训练查看不同参数的效果,并且输出了各个特征的重要性。然后作者结合了模型参数、产品类型、特征重要性展开了结论的论述。然后讨论了这个实验结果对于管理与实践的启示。


总的来讲是一篇机器学习研究评论有用性的好范文。
65.Helpfulness of online reviews: Examining review informativeness and classification thresholds by search products and experience products. (Decision Support Systems)
这篇文章是一篇典型的研究评论有用性的文章,是从计量经济学的角度去研究各个变量对评论有用性的影响机制,与之前的文章不同,大部分的文章都是从tripadvisor或者amazon等国外的网站去寻找在线评论并进行研究的,这篇文章是国人写的,因此选择的是京东在线购物网站。在数据源的获取上,tripadvisor等网站信息披露的工作做的更加完善一些,国内网站的披露信息相对会少一些,只能从文本和图片等角度去进行研究。京东网站的信息整理的会更加全面一些。
首先是自变量上,京东的评论者信息披露做的还是挺完善的,评论的基本信息都总结的挺好的,匿名性、头像、京东会员、评论者经验、图片数量、评论实践、文本等信息都可以查询到。同时文章还提出了几个新颖的变量,首先是统计了一个评论文本中的产品属性的总数,同时也统计了文本中描述产品属性的平均文本长度,这相当于是对评论长度的精细化,照葫芦画瓢,也进一步统计了描述平台属性词语的总数并且统计了文本平均长度。文本涉及属性的平均长度确实是一个比较好的变量。

在因变量上,文章直接选用了有用性投票总数来进行分析。结果还是很漂亮的,属性数量、文本长度都得到了显著的解,但是由于平台披露的信息以及平台之间的差异性,一些在外网上显著的变量在京东平台上没有得到显著的解。可以看出文章是分了体验型商品和搜索型商品进行分析的。

文章还进一步分析了评论有用性阈值划分的研究,结论得出搜索型产品和体验型产品的有用性阈值是不同的,搜索型产品的阈值更高而体验型产品的阈值低,文章采用模型拟合的结果来进行判断阈值的好坏。
总的来讲国人的文章看起来条理性就很舒服,是一篇好文章。
66.Automatically predicting the helpfulness of online reviews. (In Proceedings of the 2014 IEEE 15th International Conference on Information Reuse and Integration)
这篇文章是发表在学术会议上的文章,是用支持向量机的方法去研究评论有用性的,是一篇发表时间比较早的文章,文章总结了三种在线网站评论机制存在的偏差:不平衡投票偏差、赢家通吃偏差、早鸟效应,这在之前的文章里面有总结过这个偏差。
这篇文章提取了文本方面、评论者方面和元数据方面的特征。文本方面分别是长度、句子数、句子长度、各种词性占比、情感强度度量;评论者方面包括排名、过去总的有用性投票比例、过去发表的评论总数;元数据方面包括星级和时间。
因变量上文章直接采用了有用性投票比例来进行度量,在模型上文章采用了SVM,然后分批加入变量来查看模型的表现,然后得出结论。总体来讲文章还是比较简单的,文章得出评论星级、过去有用性投票比例以及评论总数对评论有用性影响最大。
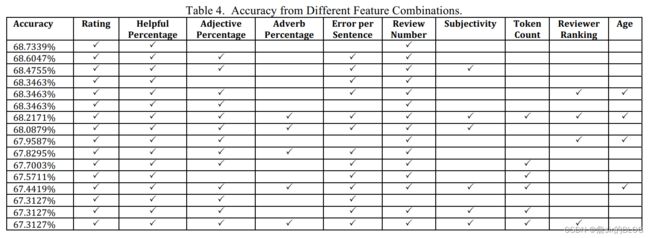
同时在可视化图形中可以看出,在极端有用和极端没用的评论中,原作者给出的星级也都是极端的。而在不是那么极端的评论中,低星级评分是主流。后面的研究中也可以考虑做这种可视化。
67.Artificial intelligence for hospitality big data analytics: developing a prediction model of restaurant review helpfulness for customer decision-making. (International Journal of Contemporary Hospitality Management)
这篇文章是从机器学习的角度去研究在线评论有用性的,不管是特征提取还是模型拟合做的工作都挺饱满的,但是在行文上略显夸张、冗余和错误(比如第一篇从机器学习角度去研究评论有用性的、搞不清楚机器学习、集成学习、神经网络、深度学习这些概念的区别、线性回归的效果和xgb的效果相差无几和经验有所违背),抛开这些问题不谈,这篇文章还是可以读一读的。
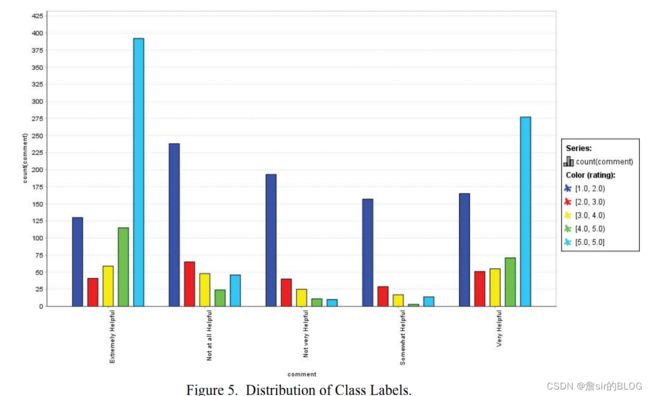
文章首先提出问题,什么模型对有用性评论有较高的预测性能、什么特征能够提高模型的预测性能。文章总结了4个方面的11个特征,这些特征都是以往研究中常见的特征,因变量直接选择了有用性投票总数来进行模型训练,将问题定义为回归问题,因此在模型评价上就很顺理成章的采用了MSE系列的指标。

在模型的选择上,文章选择了SVM/MLR/RF/XGB四个常见的机器学习模型来进行模型训练,XGB在评论有用性的文章中出现的频次是比较低的,但是XGB在结构化数据的预测中往往能表现出较好的性能,从经验上看,mlr的性能最差,xgb性能最优。这篇文章中xgb最优但是mlr的性能与xgb非常接近,我觉得是不是在模型训练的时候或者评价的时候出了点错误。从文章给出的结果来看,xgb和mlr在训练集和测试集上的结果都非常接近,难道这些特征真的就是纯线性关系吗?

然后文章跑了个特征重要性图,并且把线性回归模型的系数都输出出来了,并且分别在不同地区的餐馆分别跑了xgb回顾,测试了不同地区的预测能力。
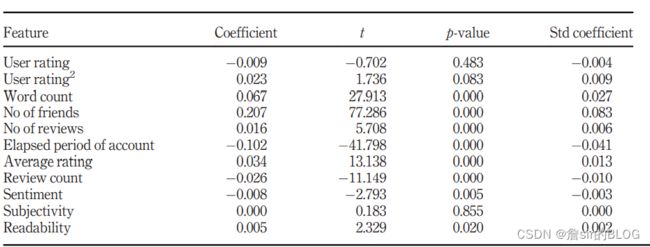
工作量还算可以,但是有点偏向水文了,没看到创新点在哪,只看到用了个新模型,而且可以直接调包。看了这么多论文也有了自己的思考,就是不同模型他的特征重要性是不同的,单纯用一个的特征重要性图直接去解释现实意义可能会存在一定风险,但是我看的论文里基本就是直接解释现实意义了,可能我写的时候也会这样干把。
68.Drivers of helpfulness of online hotel reviews: A sentiment and emotion mining approach. (International Journal of Hospitality Management)
这篇文章是从计量经济学和机器学习的角度去研究在线评论有用性的,有一说一这个印度老哥的论文用了900条评论数据都可以发论文是我没想到的,搞歧视是不是!蚌埠住了,研究评论有用性就一个研究框架,分别是自变量、因变量和模型。
这篇文章在自变量上,选择了情感方面的变量,例如积极情感、消极情感、消极词语的消极程度、情感极性、文本长度、星级、发布时间、过去评论者获得的总投票。因变量上选择了有用性投票总数来进行训练。在模型上,文章采用了两个路径,分别是计量的泊松回归和负二项回归以及机器学习的支持向量机、随机森林、全连接网络来进行训练。
在情感提取方面,文章采用了基于词典的提取方法,不管是情感的极性还是消极词语的消极程度,都是基于词典的打分和评论中词语的个数来确定的。

结果我都不想说啥,900条的数据跑出来的结果怎么能让我荔枝。结果不具有参考性,文章参考参考行文把,结果和实践简直rubbish。
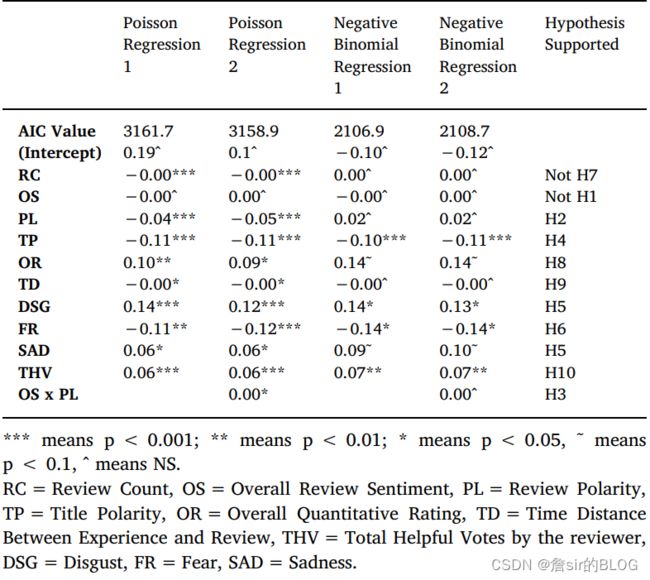
总结,辣眼睛。
69.Enhancing the helpfulness of online consumer reviews: the role of latent (content) factors. (Journal of Interactive Marketing)
这篇文章是基于ELM框架,采用机器学习的方法提取特征并利用计量经济学的方法去分析各个特征对评论有用性的影响。ELM模型是常见的分析框架,评论阅读者从中心路径和外围路径两个路径去分析一条在线评论,外围路径基本上是与评论者相关的信息或者平台提供的元数据,中心路径过去的研究多是采用文本长度、星级等等显性的指标,这篇文章就从文本内部提取了全面性、可读性、清晰性、相关性这四个指标来丰富现有的研究。
全面性是通过LDA提取出来的主题数量,清晰性则是用拼写的正确性来表示的,相关性应该是全面性的一个衍生变量,表示是否提及到了酒店相关的词语,可读性指标之前的文献提及过。这些指标的提取都有相关的程序包可以直接实现。
这篇文章做了俩实践,第一个实践是雇了两个人手动识别各种特征,只有500个样本,然后跑出来一个结论,浪费时间浪费钱。第二个实践就是正宗的机器学习提取特征然后跑回归了,结果如下所示。可以看出清晰性和相关性都能积极影响评论的有用性,而情感方面文章是用情感词典进行提取的,也没有明说情感强度的度量方式,结论就是积极情感强度越高评论有用性就越低,而消极情感的强度没有显著影响有用性,但是从符号方向来看是正向影响的,说明越消极评论越有用。

总的来说文章还是很中规中矩的,该有的都有,但是我发现最近看的论文都喜欢用小样本来做研究,这个我不是很认可,毕竟是在大样本背景下的研究,小样本的结论是难以服众的。
70.Predicting users’ review helpfulness: the role of significant review and reviewer characteristics. (Soft Computing)
这篇文章是一篇比较标准的从机器学习和深度学习的角度去研究评论有用性的文章,文章采用了多种常见的机器学习模型,并且采用了一个公开数据集和自己爬取的数据集来进行联合分析。文章的数据采集于amazon,amazon的评论数据公开还是很全面的,各种方面的数据都可以直接爬取。文章里也有一些创新性的特征。文章要解决的问题是什么模型最有效、产品类型对评论有用性的影响以及什么特征最有效。
阅读框架还是比较固定的,首先是自变量,然后是因变量,然后是采用的模型以及评价指标。自变量方面,文章分了6个方面的特征,首先是评论相关的特征:回复数量、文本标题相似度、文本标题的情感以及极性、评论长度,情感方面的特征是基于情感词典提取的;评论者相关的特征:社区活跃时间、最近发文时间;产品方面的特征:产品总体评论的极性、商品标题长度、问题回答数量、产品潜在得分(这个特征我看的不是很懂,文章也没明说怎么算的);可读性指标;可见指标:星级、时间、情感得分、长度、句子数量。因变量直接采用了有用性投票比例。
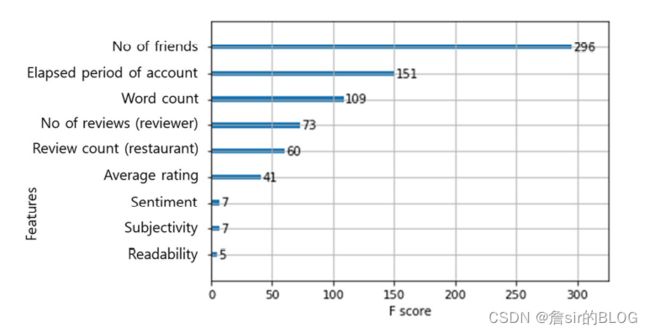
在模型上,文章采用了深度网络,神经网络,随机森林,CART,MAR(这是啥玩意??)来进行训练。数据集方面,前面提到了采用了两个数据集,然后将这些算法应用在这两个数据集上面。从图形可以看出深度神经网络的表现是最好的,模型的选择上,不同的特征不同的处理方式都有可能导致模型的变化,这种结论的可泛化能力是比较弱的。
文章进一步跑了特征重要性图,但我不大清楚用MSE怎么跑的特征重要性图。

同时文章还对两个数据集的搜索型产品和体验型产品再重复跑了一次模型,从表格可以看出搜索型产品的预测能力比体验型产品强,
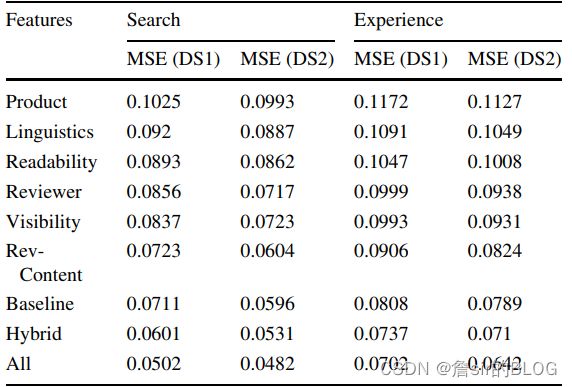
总结一下就是特征方面来讲,一些夹角余弦值什么的都还算少见,其次是采用了双数据集比较的做法,这种做法可以借鉴。最后是模型的训练以及产品分类的做法。整体来讲中规中矩。