CRF详解(理论推导)
目录
- 基本定义
-
- 条件随机场定义
- 线性链条件随机场
- 特征函数的定义
-
- 特征模板
- HMM,MEMM,CRF的比较
- 学习算法
-
- 前向算法
- 后向算法
- 正则化
-
- L1,L2以及Elastic-Net
- 优化算法
- 预测算法
-
- Viterbi与Beam Search
- CRF与NN模型的拼接
本篇是CRF的理论篇,对应的代码解读篇请戳crf++代码解读
基本定义
条件随机场定义
X,Y为随机变量,若Y构成一个由无向图G表示的马尔可夫随机场,即满足: P ( Y v ∣ X , Y w , w ≠ v ) = P { Y v ∣ X , Y w , w ∈ N ( v ) } P(Y_v|X,Y_w,w \not= v)=P\{Y_v|X,Y_w,w\in N(v)\} P(Yv∣X,Yw,w=v)=P{Yv∣X,Yw,w∈N(v)} 其中 N ( v ) N(v) N(v)表示与点 v v v直接相连的点的集合,则称条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)为条件随机场
而马尔可夫随机场满足一条很重要的定理:
Hammersley Clifford定理
一个无向图G是马尔可夫随机场,当且仅当其上的联合概率分布 P ( Y ) P(Y) P(Y)可以写成G上所有最大团上的势函数的因式分解: P ( Y ) = 1 Z ∏ C Ψ C ( Y C ) P(Y)=\frac{1}{Z}\prod_{C}\Psi_C(Y_C) P(Y)=Z1C∏ΨC(YC)
其中规范化因子 Z = ∑ Y ∏ Y Ψ C ( Y C ) Z=\sum_{Y}\prod_{Y}\Psi_C(Y_C) Z=∑Y∏YΨC(YC),势函数 Ψ C ( Y C ) \Psi_C(Y_C) ΨC(YC)是C上定义的严格正函数
定理的严格证明可参考https://en.wikipedia.org/wiki/Hammersley%E2%80%93Clifford_theorem
线性链条件随机场
由于实际应用当中的很多问题都是序列问题,所以我们可以将条件随机场进一步缩小到线性链条件随机场:
设 X = ( X 1 , . . . , X n ) 和 Y = ( Y 1 , . . . , Y n ) X=(X_1,...,X_n)和Y=(Y_1,...,Y_n) X=(X1,...,Xn)和Y=(Y1,...,Yn)均为线性链随机序列,若在给定X的条件下, P ( X ∣ Y ) P(X|Y) P(X∣Y)构成条件随机场,即满足马尔可夫性: P ( Y i ∣ X , Y ) = P ( Y i ∣ X , Y i − 1 , Y i + 1 ) , i = 1 , 2 , . . . , n P(Y_i|X,Y)=P(Y_i|X,Y_{i-1},Y_{i+1}),\quad i=1,2,...,n P(Yi∣X,Y)=P(Yi∣X,Yi−1,Yi+1),i=1,2,...,n则称 P ( Y ∣ X ) P(Y|X) P(Y∣X)为线性链条件随机场
由上述Hammersley Clifford定理,可以给出线性链条件随机场 P ( X ∣ Y ) P(X|Y) P(X∣Y)的因式分解式,由于是X和Y都是线性链,因此由Y构成的无向图G上的所有最大团为: ( Y 1 , Y 2 ) , ( Y 2 , Y 3 ) , . . . , ( Y n − 1 , Y n ) (Y_1,Y_2),(Y_2,Y_3),...,(Y_{n-1},Y_n) (Y1,Y2),(Y2,Y3),...,(Yn−1,Yn)
同时又要求 Ψ C ( Y C ) \Psi_C(Y_C) ΨC(YC)严格正,根据 最大熵原则,我们把 Ψ C i ( Y C i ) \Psi_{C_i}(Y_{C_i}) ΨCi(YCi)定义为指数形式: Ψ C i ( Y C i ) = Ψ i ( Y i − 1 , Y i , X ) = e x p [ ∑ h b h ( Y i − 1 , Y i , X , i ) + ∑ l u l ( Y i , X , i ) ] \Psi_{C_i}(Y_{C_i})= \Psi_i(Y_{i-1},Y_i,X)=exp[\sum_hb_h(Y_{i-1},Y_i,X,i)+\sum_l u_l(Y_i,X,i)] ΨCi(YCi)=Ψi(Yi−1,Yi,X)=exp[∑hbh(Yi−1,Yi,X,i)+∑lul(Yi,X,i)]
⟹ P ( Y ∣ X ) = 1 Z ∏ i Ψ i ( Y i − 1 , Y i , X ) = 1 Z ∏ i e x p [ ∑ h b h ( Y i − 1 , Y i , X , i ) + ∑ l u l ( Y i , X , i ) ] = 1 Z e x p [ ∑ h , i b h ( Y i − 1 , Y i , X , i ) + ∑ l , i u l ( Y i , X , i ) ] (1.1) \begin{aligned} \Longrightarrow \quad P(Y|X)&= \frac{1}{Z}\prod_{i}\Psi_i(Y_{i-1},Y_i,X)\\ &=\frac{1}{Z}\prod_iexp[\sum_hb_h(Y_{i-1},Y_i,X,i)+\sum_l u_l(Y_i,X,i)]\\ &=\frac{1}{Z}exp[\sum_{h,i}b_h(Y_{i-1},Y_i,X,i)+\sum_{l,i} u_l(Y_i,X,i)] \tag{1.1} \end{aligned} ⟹P(Y∣X)=Z1i∏Ψi(Yi−1,Yi,X)=Z1i∏exp[h∑bh(Yi−1,Yi,X,i)+l∑ul(Yi,X,i)]=Z1exp[h,i∑bh(Yi−1,Yi,X,i)+l,i∑ul(Yi,X,i)](1.1)
其中 b k 和 u l b_k和u_l bk和ul称为特征函数, Z Z Z同样是规范化因子。但在实际使用中,为了方便,通常将 b k ( Y i − 1 , Y i , X , i ) b_k(Y_{i-1},Y_i,X,i) bk(Yi−1,Yi,X,i)和 u l ( Y i , X , i ) u_l(Y_i,X,i) ul(Yi,X,i)定义为0-1函数(人工定义是0还是1),而将不同特征的权重单独记为 λ k \lambda_k λk和 μ l \mu_l μl,因此给定特征函数,特征的权重 λ k 和 μ l \lambda_k和\mu_l λk和μl就是线性链CRF的参数。我们可以将上式重新表示为: P ( Y ∣ X ) = 1 Z e x p [ ∑ h , i λ h b h ( Y i − 1 , Y i , X , i ) + ∑ l , i μ l u l ( Y i , X , i ) ] P(Y|X)=\frac{1}{Z}exp[\sum_{h,i}\lambda_hb_h(Y_{i-1},Y_i,X,i)+\sum_{l,i} \mu_lu_l(Y_i,X,i)] P(Y∣X)=Z1exp[h,i∑λhbh(Yi−1,Yi,X,i)+l,i∑μlul(Yi,X,i)]
将符号重新记作:
f k ( Y i − 1 , Y i , X , i ) = { b h ( Y i − 1 , Y i , X , i ) k = 1 , . . , H u l ( Y i , X , i ) k = H + 1 , . . . , H + L (1.2) f_k(Y_{i-1},Y_i,X,i)= \begin{cases} b_h(Y_{i-1},Y_i,X,i)& k=1,..,H\\ u_l(Y_i,X,i)& k=H+1,...,H+L \tag{1.2} \end{cases} fk(Yi−1,Yi,X,i)={bh(Yi−1,Yi,X,i)ul(Yi,X,i)k=1,..,Hk=H+1,...,H+L(1.2)
f k ( X , Y ) = ∑ i = 1 n f k ( Y i − 1 , Y i , X , i ) , f ( X , Y ) = ∑ k = 1 K f k ( X , Y ) (1.3) f_k(X,Y)=\sum_{i=1}^n f_k(Y_{i-1},Y_i,X,i),\quad f(X,Y) = \sum_{k=1}^K f_k(X,Y) \tag{1.3} fk(X,Y)=i=1∑nfk(Yi−1,Yi,X,i),f(X,Y)=k=1∑Kfk(X,Y)(1.3)
w k = { λ h k = 1 , . . , H μ l k = H + 1 , . . . , H + L (1.4) w_k= \begin{cases} \lambda_h& k=1,..,H\\ \mu_l& k=H+1,...,H+L \tag{1.4} \end{cases} wk={λhμlk=1,..,Hk=H+1,...,H+L(1.4)
那么目标函数可以表示为:
P ( Y ∣ X ) = e x p ( ∑ k = 1 K w k f k ( X , Y ) ) ∑ Y ′ e x p ( ∑ k = 1 K w k f k ( X , Y ′ ) ) (1.5) P(Y|X)=\frac{exp(\sum_{k=1}^Kw_k f_k(X,Y))}{\sum_{Y'}exp(\sum_{k=1}^Kw_kf_k(X,Y'))} \tag{1.5} P(Y∣X)=∑Y′exp(∑k=1Kwkfk(X,Y′))exp(∑k=1Kwkfk(X,Y))(1.5)
特征函数的定义
以CRF++为例,它提供了两种特征模版的形式Unigram和Bigram以供使用者定义自己想用的特征函数。
北 N B
京 N E
欢 V B
迎 V M
你 N E
假如这是我们的数据,第一列的观测序列,第二列是与观测序列相关的feature,在这个数据中是词性,而最后一列需要放状态序列,这个数据里是分词的结果。
特征模板
1.Unigram模版
对应unigram特征函数 u l ( Y i , X , i ) u_l(Y_i,X,i) ul(Yi,X,i)。形式:%x[row,col],表示当前位置行数移动row,列数移动col的位置对当前位置output的影响。假设当前位置是"欢 V B",那么%x[-1,1]就表示当前位置上一个位置的第一个feature,也就是"N",对当前位置output的影响。再例如U01:%x[0,0],表示当前位置的观测序列对output的影响,假设状态序列有M种可能的标签,而观测序列的vocabulary数为V,那么U01:%x[0,0],可以生成 M × V M\times V M×V个模版,这个例子中M=3,V=5,所以U01:%x[0,0]可以生成如下15个模版:
func1 = if(output = B & feature=U01:“北”) return 1 else return 0
func2 = if(output = M & feature=U01:“北”) return 1 else return 0
func3 = if(output = E & feature=U01:“北”) return 1 else return 0
func4 = if(output = B & feature=U01:“京”) return 1 else return 0
…
func13 = if(output = B & feature=U01:“你”) return 1 else return 0
func14 = if(output = M & feature=U01:“你”) return 1 else return 0
func15 = if(output = E & feature=U01:“你”) return 1 else return 0
从这里也可以看出线性链CRF中 Y i Y_i Yi对X的依赖是全局的,而不是像HMM一样仅依赖于当前位置。
另:Unigram模版也可以定义为U02:%x[0,0]:%x[1,0],这表示当前位置的output同时依赖当前位置和下一位置的观测值。
2.Bigram模版
对应bigram特征函数 b h ( Y i − 1 , Y i , X , i ) 。 b_h(Y_{i-1},Y_i,X,i)。 bh(Yi−1,Yi,X,i)。B01%x[0,0]表示当前位置观测序列以及上一位置output对当前位置ouput的影响,例如:
func1 = if(prev_output = B & output = B & feature=B01:“北”) return 1 else return 0
func1 = if(prev_output = M & output = B & feature=B01:“北”) return 1 else return 0
func1 = if(prev_output = E & output = B & feature=B01:“北”) return 1 else return 0
func1 = if(prev_output = B & output = M & feature=B01:“北”) return 1 else return 0
…
而这样的模版总共可以生成 M × M × V M\times M\times V M×M×V个bigram特征函数。从这里也可以看出,如果想增加trigram甚至更高阶的特征函数,那么模型的参数也会程指数级上涨(当然更高阶的特征函数已经不符合CRF的定义范围了)
另:如果只定义为"B",则表示只考虑prev_output和output,而不考虑观测序列。
HMM,MEMM,CRF的比较

-
HMM:
a r g m a x w P ( X , Y ; w ) = a r g m a x w ∏ i = 1 n P ( y i ∣ y i − 1 ; w ) P ( x i ∣ y i ; w ) \mathop{argmax}\limits_{w}P(X,Y;w) = \mathop{argmax}\limits_{w}\prod_{i=1}^n P(y_i|y_{i-1};w)P(x_i|y_i;w) wargmaxP(X,Y;w)=wargmax∏i=1nP(yi∣yi−1;w)P(xi∣yi;w) -
MEMM: a r g m a x w P ( Y ∣ X ) = a r g m a x w ∏ i = 1 n P ( y i ∣ y i − 1 , X ; w ) = 最大熵分类器 a r g m a x w ∏ i = 1 n e x p ( ∑ k w k f k ( y i − 1 , y i , X ) ) Z i \begin{aligned} \mathop{argmax}\limits_{w}P(Y|X) =& \mathop{argmax}\limits_{w}\prod_{i=1}^n P(y_i|y_{i-1},X;w) \\ \overset{\text{最大熵分类器}}{=} & \mathop{argmax}\limits_{w}\prod_{i=1}^n\frac{exp(\sum_{k}w_k f_k(y_{i-1},y_i,X))}{Z_i} \end{aligned} wargmaxP(Y∣X)==最大熵分类器wargmaxi=1∏nP(yi∣yi−1,X;w)wargmaxi=1∏nZiexp(∑kwkfk(yi−1,yi,X))
其中 Z i = ∑ y ′ e x p ( ∑ k w k f k ( y i − 1 ′ , y i ′ , X ) ) Z_i = \sum_{y'} exp(\sum_{k}w_k f_k(y'_{i-1},y'_i,X)) Zi=∑y′exp(∑kwkfk(yi−1′,yi′,X)) -
CRF:
a r g m a x w P ( Y ∣ X ) = a r g m a x w ∏ i Ψ i ( Y i − 1 , Y i , X ; w ) Z = a r g m a x w e x p ( ∑ k ∑ i = 1 n w k f k ( y i − 1 , y i , X ) ) ∑ y ′ e x p ( ∑ k ∑ i = 1 n w k f k ( y i − 1 ′ , y i ′ , X ) ) \begin{aligned} \mathop{argmax}\limits_{w}P(Y|X) &= \mathop{argmax}\limits_{w}\frac{\prod_{i}\Psi_i(Y_{i-1},Y_i,X;w)}{Z}\\ &= \mathop{argmax}\limits_{w} \frac{exp(\sum_{k}\sum_{i=1}^n w_k f_k(y_{i-1},y_i,X))}{\sum_{y'}exp(\sum_{k} \sum_{i=1}^n w_kf_k(y'_{i-1},y'_i,X))} \end{aligned} wargmaxP(Y∣X)=wargmaxZ∏iΨi(Yi−1,Yi,X;w)=wargmax∑y′exp(∑k∑i=1nwkfk(yi−1′,yi′,X))exp(∑k∑i=1nwkfk(yi−1,yi,X))
1.HMM和MEMM是有向图,其定义的转移概率是条件概率;CRF是无向图,定义的bigram特征是联合概率。
2.HMM是生成模型,除了用于序列标注,还可以用于数据生成等任务,但缺点是只能利用数据的统计信息,因此需要足够多的数据以保证采样到了数据的全貌;MEMM和CRF是判别模式,旨在找到类别的边界,而且与HMM不同,它们可以直接定义特征,并通过特征捕捉一些仅通过统计数据难以得到的信息,例如字母大小写,词尾信息等。
3.HMM中的观测序列是依赖于状态序列的,而MEMM和CRF中是状态序列依赖于观测序列。前者会导致 P ( Y ∣ X ) P(Y|X) P(Y∣X)是无法直接度量的,必须通过贝叶斯法则 P ( Y ∣ X ) = P ( X , Y ) P ( X ) P(Y|X) = \frac{P(X,Y)}{P(X)} P(Y∣X)=P(X)P(X,Y)来计算,这也解释了为什么HMM是生成模型,而且由于HMM中的未知量是状态向量,刚好契合了EM算法中隐变量的定义,因此还可以使用EM算法做无监督学习(不过无监督的效果会比有监督差很多,所以实践当中大部分还是用有监督方法,并且HMM的有监督方法非常简便,直接通过最大似然估计用频数求解即可);而后两者则可以直接求解 P ( Y ∣ X ) P(Y|X) P(Y∣X)。
4.在HMM中。当前状态 y i y_i yi仅与上一时刻状态 y i − 1 y_{i-1} yi−1和当前观测 x i x_i xi相关,而MEMM和CRF中它是与整个观测序列 X X X相关,可以定义 y i y_i yi和观测序列 X X X任意位置的关系。
5.MEMM是在将条件概率 P ( Y ∣ X ) P(Y|X) P(Y∣X)分解之后再套用的最大熵模型,因此 a r g m a x w ∏ i = 1 n e x p ( ∑ k w k f k ( y i − 1 , y i , X ) ) Z i ⇌ a r g m a x w k e x p ( ∑ k w k f k ( y i − 1 , y i , X ) ) Z i , ∀ k \mathop{argmax}\limits_{w}\prod_{i=1}^n\frac{exp(\sum_{k}w_k f_k(y_{i-1},y_i,X))}{Z_i} \rightleftharpoons \mathop{argmax}\limits_{w_k} \frac{exp(\sum_{k}w_k f_k(y_{i-1},y_i,X))}{Z_i}, \forall k wargmax∏i=1nZiexp(∑kwkfk(yi−1,yi,X))⇌wkargmaxZiexp(∑kwkfk(yi−1,yi,X)),∀k。也就是最大化每一个位置的条件概率,但这会导致局部最优化问题。而CRF中的归一化因子 Z Z Z是针对整个序列的,它的优化目标是全局最优。
6.由于线性链CRF是马尔可夫随机场,由Hammersley Clifford定理可得,它的最大团只能是相邻的状态,因此线性链CRF只能捕捉到相邻状态之间的特征;而MEMM实际上可以不受这个限制,例如三元组MEMM中, P ( Y ∣ X ) = ∏ i P ( y i ∣ y i − 2 , y i − 1 , X ) P(Y|X) = \prod_{i} P(y_i|y_{i-2},y_{i-1},X) P(Y∣X)=∏iP(yi∣yi−2,yi−1,X)(参考http://www.cs.columbia.edu/~mcollins/fall2014-loglineartaggers.pdf)
学习算法
与HMM类似,CRF的loss function也是根据最大似然估计来定义的:
a r g m i n w − L ( w ) = a r g m i n w − l o g P ( X , Y ) = a r g m i n w − l o g P ( Y ∣ X ) P ( X ) = a r g m i n w − l o g ( e x p ( ∑ k = 1 K w k f k ( X , Y ) ) ∑ Y ′ e x p ( ∑ k = 1 K w k f k ( X , Y ′ ) ) ) = a r g m i n w − { ∑ k = 1 K w k f k ( X , Y ) − l o g Z w } (3.1) \begin{aligned} &\mathop{argmin}\limits_{w} -L(w)\\ &= \mathop{argmin}\limits_{w}-logP(X,Y)\\ &= \mathop{argmin}\limits_{w}-logP(Y|X)P(X)\\ &= \mathop{argmin}\limits_{w} -log(\frac{exp(\sum_{k=1}^Kw_k f_k(X,Y))}{\sum_{Y'}exp(\sum_{k=1}^Kw_kf_k(X,Y'))})\\ &= \mathop{argmin}\limits_{w} -\{\sum_{k=1}^Kw_k f_k(X,Y)-logZ_w\} \tag{3.1} \end{aligned} wargmin−L(w)=wargmin−logP(X,Y)=wargmin−logP(Y∣X)P(X)=wargmin−log(∑Y′exp(∑k=1Kwkfk(X,Y′))exp(∑k=1Kwkfk(X,Y)))=wargmin−{k=1∑Kwkfk(X,Y)−logZw}(3.1)
对 w k w_k wk求导:
∂ L ∂ w k = − f k ( Y , X ) + ∑ Y ′ e x p ( ∑ k = 1 K ) f k ( X , Y ′ ) ∗ f k ( X , Y ) ∑ Y ′ e x p ( ∑ k = 1 K ) f k ( X , Y ′ ) = − f k ( Y , X ) + ∑ Y ′ P ( Y ′ ∣ X ) f k ( X , Y ) = − f k ( Y , X ) + ∑ Y ′ P ( Y ′ ∣ X ) ∑ i = 1 n f k ( Y i − 1 , Y i , X , i ) = − f k ( Y , X ) + ∑ i = 1 n ∑ Y ′ P ( Y ′ ∣ X ) f k ( Y i − 1 , Y i , X , i ) = E P ( Y ′ ∣ X ) [ f k ( Y i − 1 , Y i , X , i ) ] − f k ( Y , X ) (3.2) \begin{aligned} \frac{\partial L}{\partial w_k} &= -f_k(Y,X)+\frac{\sum_{Y'}exp(\sum_{k=1}^K)f_k(X,Y')* f_k(X,Y)}{\sum_{Y'}exp(\sum_{k=1}^K)f_k(X,Y')}\\ &= -f_k(Y,X)+ \sum_{Y'}P(Y'|X)f_k(X,Y)\\ &= -f_k(Y,X)+ \sum_{Y'}P(Y'|X)\sum_{i=1}^n f_k(Y_{i-1},Y_i,X,i)\\ &= -f_k(Y,X)+ \sum_{i=1}^n \sum_{Y'}P(Y'|X) f_k(Y_{i-1},Y_i,X,i)\\ &= E_{P(Y'|X)}[f_k(Y_{i-1},Y_i,X,i)]-f_k(Y,X) \tag{3.2} \end{aligned} ∂wk∂L=−fk(Y,X)+∑Y′exp(∑k=1K)fk(X,Y′)∑Y′exp(∑k=1K)fk(X,Y′)∗fk(X,Y)=−fk(Y,X)+Y′∑P(Y′∣X)fk(X,Y)=−fk(Y,X)+Y′∑P(Y′∣X)i=1∑nfk(Yi−1,Yi,X,i)=−fk(Y,X)+i=1∑nY′∑P(Y′∣X)fk(Yi−1,Yi,X,i)=EP(Y′∣X)[fk(Yi−1,Yi,X,i)]−fk(Y,X)(3.2)
而后面这一项如果直接计算的话,由于 ∑ Y ′ P ( Y ′ ∣ X ) = ∑ y 1 , . . y n P ( Y 1 = y 1 , . . . , Y n = y n ∣ X ) \sum_Y'P(Y'|X)=\sum_{y_1,..y_n}P(Y_1=y_1,...,Y_n=y_n|X) ∑Y′P(Y′∣X)=∑y1,..ynP(Y1=y1,...,Yn=yn∣X),计算复杂度高达 O ( M n × n ) O(M^n\times n) O(Mn×n),所以我们可以采用利用了动态规划思想的前向-后向算法来减少计算量。首先将上式化简为:
∂ L ∂ w k = − f k ( Y , X ) + E P ( Y ′ ∣ X ) [ f k ( Y i − 1 , Y i , X , i ) ] = − f k ( Y , X ) + ∑ i = 1 n ∑ Y ′ P ( Y ′ ∣ X ) f k ( Y i − 1 , Y i , X , i ) = − f k ( Y , X ) + ∑ i = 1 n [ ∑ y i , y i − 1 f k ( Y i − 1 = y i − 1 , Y i = y i , X , i ) P ( Y ′ , Y i − 1 = y i − 1 , Y i = y i ∣ X ) + ∑ y i f k ( Y i = y i , X , i ) P ( Y ′ , Y i = y i ∣ X ) ] (3.3) \begin{aligned} \frac{\partial L}{\partial w_k} &= -f_k(Y,X)+ E_{P(Y'|X)}[f_k(Y_{i-1},Y_i,X,i)]\\ &= -f_k(Y,X)+ \sum_{i=1}^n \sum_{Y'}P(Y'|X) f_k(Y_{i-1},Y_i,X,i)\\ &= -f_k(Y,X)+ \sum_{i=1}^n[\sum_{y_i,y_{i-1}}f_k(Y_{i-1}=y_{i-1},Y_i=y_i,X,i)P(Y',Y_{i-1}=y_{i-1},Y_i=y_i|X) + \sum_{y_i}f_k(Y_i=y_i,X,i)P(Y',Y_i=y_i|X)]\tag{3.3} \end{aligned} ∂wk∂L=−fk(Y,X)+EP(Y′∣X)[fk(Yi−1,Yi,X,i)]=−fk(Y,X)+i=1∑nY′∑P(Y′∣X)fk(Yi−1,Yi,X,i)=−fk(Y,X)+i=1∑n[yi,yi−1∑fk(Yi−1=yi−1,Yi=yi,X,i)P(Y′,Yi−1=yi−1,Yi=yi∣X)+yi∑fk(Yi=yi,X,i)P(Y′,Yi=yi∣X)](3.3)
下面我们首先介绍前向-后向算法,再用这个算法来计算 P ( Y ′ , Y i − 1 = y i − 1 , Y i = y i ∣ X ) P(Y',Y_{i-1}=y_{i-1},Y_i=y_i|X) P(Y′,Yi−1=yi−1,Yi=yi∣X)和 P ( Y i = y i ∣ X ) P(Y_i=y_i|X) P(Yi=yi∣X)。
前向算法
定义: α i ( y i ∣ X ) = P ^ ( Y 1 , . . . , Y i − 1 , Y i = y i ∣ X ) \alpha_i(y_i|X)=\hat{P}(Y_1,...,Y_{i-1},Y_i=y_i|X) αi(yi∣X)=P^(Y1,...,Yi−1,Yi=yi∣X),其中 P ^ \hat{P} P^是非规范化概率
初始化: α 0 ( y 0 ∣ X ) = { 1 y 0 = s t a r t 0 y 0 ≠ s t a r t \alpha_0(y_0|X)= \left\{ \begin{array}{c} 1& y_0=start\\ 0& y_0\not= start \end{array}\right. α0(y0∣X)={10y0=starty0=start
递推:
α i ( y i ∣ X ) = P ^ ( Y 1 , . . . , Y i − 1 , Y i = y i ∣ X ) = [ ∑ y i − 1 Ψ i ( y i − 1 , y i , X ) [ ∑ y i − 2 Ψ i − 1 ( y i − 2 , y i − 1 , X ) ⋯ [ ∑ y 1 Ψ 1 ( y 2 , y 1 , X ) Ψ 0 ( y s t a r t , y 1 , X ) ] ] ] = ∑ y i − 1 Ψ i ( y i − 1 , y i , X ) α i − 1 ( y i − 1 ∣ X ) (3.4) \begin{aligned} \alpha_i(y_i|X) &= \hat{P}(Y_1,...,Y_{i-1},Y_i=y_i|X)\\ &= [\sum_{y_{i-1}}\Psi_i(y_{i-1},y_i,X)[\sum_{y_{i-2}}\Psi_{i-1}(y_{i-2},y_{i-1},X)\cdots[\sum_{y_1}\Psi_1(y_2,y_1,X)\Psi_0(y_{start},y_1,X)]]]\\ &= \sum_{y_{i-1}}\Psi_i(y_{i-1},y_i,X)\alpha_{i-1}(y_{i-1}|X) \tag{3.4} \end{aligned} αi(yi∣X)=P^(Y1,...,Yi−1,Yi=yi∣X)=[yi−1∑Ψi(yi−1,yi,X)[yi−2∑Ψi−1(yi−2,yi−1,X)⋯[y1∑Ψ1(y2,y1,X)Ψ0(ystart,y1,X)]]]=yi−1∑Ψi(yi−1,yi,X)αi−1(yi−1∣X)(3.4)
后向算法
定义: β i ( y i ∣ X ) = P ^ ( Y i + 1 , . . . , Y n ∣ Y i = y i , X ) \beta_i(y_i|X)=\hat{P}(Y_{i+1},...,Y_n|Y_i=y_i,X) βi(yi∣X)=P^(Yi+1,...,Yn∣Yi=yi,X),其中 P ^ \hat{P} P^是非规范化概率
初始化: β n + 1 ( y n + 1 ∣ X ) = { 1 y n + 1 = s t o p 0 y n + 1 ≠ s t o p \beta_{n+1}(y_{n+1}|X)= \left\{ \begin{array}{c} 1& y_{n+1}=stop\\ 0& y_{n+1}\not= stop \end{array}\right. βn+1(yn+1∣X)={10yn+1=stopyn+1=stop
递推:
β i ( y i ∣ X ) = P ^ ( Y i + 1 , . . . , Y n ∣ Y i = y i , X ) = [ ∑ y i + 1 Ψ i + 1 ( y i , y i + 1 , X ) [ ∑ y i + 2 Ψ i + 2 ( y i + 1 , y i + 2 , X ) ⋯ [ ∑ y n Ψ n ( y n − 1 , y n , X ) Ψ n + 1 ( y n , y s t o p , X ) ] ] ] \beta_i(y_i|X)=\hat{P}(Y_{i+1},...,Y_n|Y_i=y_i,X) = [\sum_{y_{i+1}}\Psi_{i+1}(y_i,y_{i+1},X)[\sum_{y_{i+2}}\Psi_{i+2}(y_{i+1},y_{i+2},X)\cdots[\sum_{y_n}\Psi_n(y_{n-1},y_n,X)\Psi_{n+1}(y_n,y_{stop},X)]]] βi(yi∣X)=P^(Yi+1,...,Yn∣Yi=yi,X)=[yi+1∑Ψi+1(yi,yi+1,X)[yi+2∑Ψi+2(yi+1,yi+2,X)⋯[yn∑Ψn(yn−1,yn,X)Ψn+1(yn,ystop,X)]]]
⟹ ∑ y i Ψ i ( y i − 1 , y i , X ) β i ( y i ∣ X ) = β i − 1 ( y i − 1 ∣ X ) (3.5) \Longrightarrow \quad \sum_{y_i}\Psi_i(y_{i-1},y_i,X)\beta_i(y_i|X)= \beta_{i-1}(y_{i-1}|X) \tag{3.5} ⟹yi∑Ψi(yi−1,yi,X)βi(yi∣X)=βi−1(yi−1∣X)(3.5)
现在可以计算:
Z w = α n T ( X ) ⋅ 1 = 1 T ⋅ β 1 ( X ) (3.6) Z_w = \alpha_n^T(X)\cdot1 = 1^T\cdot \beta_1(X) \tag{3.6} Zw=αnT(X)⋅1=1T⋅β1(X)(3.6)
P ( Y , Y i = y i ∣ X ) = P ( Y 1 , . . . , Y i − 1 , Y i = y i , Y i + 1 , . . . , Y n ∣ X ) = P ( Y 1 , . . . , Y i − 1 , Y i = y i ∣ X ) P ( Y i + 1 , . . . , Y n ∣ Y i = y i , X ) = α i T ( y i ∣ X ) β i ( y i ∣ X ) Z w (3.7) \begin{aligned} P(Y,Y_i=y_i|X) &= P(Y_1,...,Y_{i-1},Y_i=y_i,Y_{i+1},...,Y_n|X)\\ &= P(Y_1,...,Y_{i-1},Y_i=y_i|X)P(Y_{i+1},...,Y_n|Y_i=y_i,X)\\ &= \frac{\alpha_{i}^T(y_i|X)\beta_i(y_i|X)}{Z_w} \tag{3.7} \end{aligned} P(Y,Yi=yi∣X)=P(Y1,...,Yi−1,Yi=yi,Yi+1,...,Yn∣X)=P(Y1,...,Yi−1,Yi=yi∣X)P(Yi+1,...,Yn∣Yi=yi,X)=ZwαiT(yi∣X)βi(yi∣X)(3.7)
P ( Y , Y i − 1 = y i − 1 , Y i = y i ∣ X ) = P ( Y 1 , . . . , Y i − 2 , Y i − 1 = y i − 1 , Y i = y i , . . . , Y n ∣ X ) = 1 Z w [ ∑ y 1 Ψ 0 ( y s t a r t , y 1 , X ) Ψ 1 ( y 2 , y 1 , X ) ⋯ ∑ y i − 2 Ψ i − 1 ( y i − 2 , y i − 1 , X ) ∗ Ψ ( y i − 1 , y i , X ) ∗ ∑ y i + 1 Ψ i + 1 ( y i , y i + 1 , X ) ⋯ ∑ y n Ψ n ( y n − 1 , y n , X ) Ψ n + 1 ( y n , y s t o p , X ) ] = α i − 1 ( y i − 1 ∣ X ) Ψ ( y i − 1 , y i , X ) β i ( y i ∣ X ) Z w (3.8) \begin{aligned} P(Y,Y_{i-1}=y_{i-1},Y_i=y_i|X) &= P(Y_1,...,Y_{i-2},Y_{i-1}=y_{i-1},Y_i=y_i,...,Y_n|X)\\ &= \frac{1}{Z_w}[\sum_{y_1}\Psi_0(y_{start},y_1,X)\Psi_1(y_2,y_1,X)\cdots\sum_{y_{i-2}}\Psi_{i-1}(y_{i-2},y_{i-1},X)*\Psi(y_{i-1},y_i,X)*\sum_{y_{i+1}}\Psi_{i+1}(y_i,y_{i+1},X)\cdots\sum_{y_n}\Psi_n(y_{n-1},y_n,X)\Psi_{n+1}(y_n,y_{stop},X)]\\ &= \frac{\alpha_{i-1}(y_{i-1}|X)\Psi(y_{i-1},y_i,X)\beta_i(y_i|X)}{Z_w} \tag{3.8} \end{aligned} P(Y,Yi−1=yi−1,Yi=yi∣X)=P(Y1,...,Yi−2,Yi−1=yi−1,Yi=yi,...,Yn∣X)=Zw1[y1∑Ψ0(ystart,y1,X)Ψ1(y2,y1,X)⋯yi−2∑Ψi−1(yi−2,yi−1,X)∗Ψ(yi−1,yi,X)∗yi+1∑Ψi+1(yi,yi+1,X)⋯yn∑Ψn(yn−1,yn,X)Ψn+1(yn,ystop,X)]=Zwαi−1(yi−1∣X)Ψ(yi−1,yi,X)βi(yi∣X)(3.8)
前面说到直接计算 ∑ Y ′ P ( Y ′ ∣ X ) \sum_Y'P(Y'|X) ∑Y′P(Y′∣X)的计算复杂度是 O ( M n × n ) O(M^n\times n) O(Mn×n),而我们前向-后向算法的计算复杂度仅为 O ( M 2 × n ) O(M^2\times n) O(M2×n),所以最终计算 ∑ Y ′ P ( Y ′ ∣ X ) \sum_Y'P(Y'|X) ∑Y′P(Y′∣X)的计算复杂度为 O ( M 3 × n ) O(M^3\times n) O(M3×n)。
正则化
前面有介绍到CRF的参数其实是非常多的,但其中并不是所有的特征函数都对最终的预测结果有重要影响。因此我们需要给目标函数加上正则化项来防止过拟合。常用的正则化项有:
L1正则化: ∑ k = 1 K ∣ w k ∣ \sum_{k=1}^K|w_k| ∑k=1K∣wk∣,和L2正则化: ∑ k = 1 K w k 2 \sum_{k=1}^{K}w_k^2 ∑k=1Kwk2。
L1,L2以及Elastic-Net
L1范数其实是L0范数的最优凸近似,因此它倾向于得到更稀疏的结果,即使得很多参数的值为0,所以也可以认为是一种特征筛选。
L2范数的特性会使得它对于大的数值更敏感,因此模型倾向于得到很多值很小的参数(但是不容易为0,而L1范数会直接使得参数为0);而且由于L2范数是强凸函数,它可以改善目标函数的条件数,增大其凸性,使得求解过程更稳定。
另,参考https://blog.csdn.net/u010725283/article/details/79212762 可知,如果把L2正则项的系数控制在一个合理的范围,那么L2对不同参数的削减由损失函数在这个方向上的凸性强弱决定的:凸性越强,对这个方向上的参数的削减越弱;凸性越弱,则对这个方向上的参数削减越强。
而CRF既可以选择L1正则化,也可以选择L2正则化。为了同时使用两种范数的优点(L1的稀疏性,L2的稳定性)我们可以选择Elastic-Net Penalty:
E ( w ) = L ( w ) + ρ 1 ∑ k = 1 K ∣ w k ∣ + ρ 2 ∑ k = 1 K w k 2 \begin{aligned} E(w) = L(w) + \rho_1 \sum_{k=1}^K|w_k| + \rho_2 \sum_{k=1}^K w_k^2 \end{aligned} E(w)=L(w)+ρ1k=1∑K∣wk∣+ρ2k=1∑Kwk2
尽管 E ( w ) E(w) E(w)是凸函数,但是因为它的解析解无法计算,因此我们需要使用优化方法来求解这个问题。
优化算法
1.梯度下降法(一阶算法)
2.BFGS(二阶算法)
BFGS详见BFGS
(用BFGS优化CRF模型)
- 初始化 w 0 w_0 w0,取 B 0 = I B_0=I B0=I,给定特征函数 { f k ( Y i − 1 , Y i , X , i ) } k = 1 K , ∀ i = 1 , . . . , n \{f_k(Y_{i-1},Y_i,X,i)\}_{k=1}^K, \forall i=1,...,n {fk(Yi−1,Yi,X,i)}k=1K,∀i=1,...,n
- 对第k步迭代, g k 由 公 式 ( 3.3 ) 求 得 g_k 由公式(3.3)求得 gk由公式(3.3)求得。其中 P ( Y ′ , Y i − 1 = y i − 1 , Y i = y i ∣ X ) P(Y',Y_{i-1}=y_{i-1},Y_i=y_i|X) P(Y′,Yi−1=yi−1,Yi=yi∣X)和 P ( Y ′ , Y i = y i ∣ X ) P(Y',Y_i=y_i|X) P(Y′,Yi=yi∣X)由前向-后向算法得到
- 搜索方向 d k = − B k − 1 g k \quad d_k = -B_k^{-1}g_k dk=−Bk−1gk
- 搜索步长 λ k = a r g m i n λ f ( w k + λ k d k ) \quad \lambda_k=argmin_{\lambda}f(w_k+\lambda_kd_k) λk=argminλf(wk+λkdk)
- 记 δ k = λ k d k \delta_k = \lambda_k d_k δk=λkdk, 则有 w k + 1 = w k + λ k d k w_{k+1}=w_k+\lambda_kd_k wk+1=wk+λkdk
- 再利用前向-后向算法计算 g k + 1 g_{k+1} gk+1,如果 ∣ ∣ g k + 1 ∣ ∣ < ϵ ||g_{k+1}||<\epsilon ∣∣gk+1∣∣<ϵ,则停止计算。否则 B k + 1 = B k + y k y k T y k T s k − B k s k s k T B k s k T B k s k B_{k+1} = B_k + \frac{y_ky_k^T}{y_k^Ts_k}-\frac{B_k s_k s_k^T B_k}{s_k^T B_k s_k} Bk+1=Bk+ykTskykykT−skTBkskBkskskTBk
- k = k + 1 k=k+1 k=k+1,转(3)
预测算法
CRF的预测算法与HMM一样,都是采用了利用动态规划思想的Viterbi算法。
由于 y ∗ = a r g m a x y P ( Y = y ∣ X = x ) = a r g m a x y e x p ( w ∗ F ( x , y ) ) Z ( x ) = a r g m a x y ∑ i = 1 n w ∗ F i ( y i − 1 , y i , x ) \begin{aligned} y^*&= argmax_{y}P(Y=y|X=x)\\ &= argmax_{y}\frac{exp(w*F(x,y))}{Z(x)}\\ &= argmax_{y}\sum_{i=1}^nw*F_i(y_{i-1},y_i,x) \end{aligned} y∗=argmaxyP(Y=y∣X=x)=argmaxyZ(x)exp(w∗F(x,y))=argmaxyi=1∑nw∗Fi(yi−1,yi,x)
其中 F ( x , y ) = [ f 1 ( x , y ) , ⋯ , f K ( x , y ) ] T F(x,y)=[f_1(x,y),\cdots,f_K(x,y)]^T F(x,y)=[f1(x,y),⋯,fK(x,y)]T,
F i ( y i − 1 , y i , x ) = [ f 1 ( y i − 1 , y i , x ) , ⋯ , f K ( y i − 1 , y i , x ) ] T F_i(y_{i-1},y_i,x) = [f_1(y_{i-1},y_i,x),\cdots,f_K(y_{i-1},y_i,x)]^T Fi(yi−1,yi,x)=[f1(yi−1,yi,x),⋯,fK(yi−1,yi,x)]T。
因此目标变为寻找使得 ∑ i = 1 n w ∗ F i ( y i − 1 , y i , x ) \sum_{i=1}^nw*F_i(y_{i-1},y_i,x) ∑i=1nw∗Fi(yi−1,yi,x)最大的路径。HMM中使用Viterbi算法的思想参见 https://zhuanlan.zhihu.com/p/148526621。下面我们直接给出CRF中Viterbi算法的公式:
定义: δ i ( l ) = m a x y 1 , . . . , y i − 1 P ( Y i = l , Y 1 , . . . , Y i − 1 ∣ X ) (4.1) \delta_i(l)=max_{y_1,...,y_{i-1}}P(Y_i=l,Y_1,...,Y_{i-1}|X) \tag{4.1} δi(l)=maxy1,...,yi−1P(Yi=l,Y1,...,Yi−1∣X)(4.1)
即 δ i ( l ) \delta_i(l) δi(l)是到节点 ( x i , y i = l ) (x_i,y_i=l) (xi,yi=l)的最佳路径的score
初始化: δ 1 ( l ) = w ∗ F 1 ( y 0 = s t a r t , y 1 = l , x ) \delta_1(l)=w*F_1(y_0=start,y_1=l,x) δ1(l)=w∗F1(y0=start,y1=l,x)
递推式: δ i + 1 ( l ) = m a x j { δ i ( j ) + w ∗ F i + 1 ( Y i = j , Y i + 1 = l , X ) } (4.2) \delta_{i+1}(l) = max_{j}\{\delta_i(j)+w*F_{i+1}(Y_i=j,Y_{i+1}=l,X)\} \tag{4.2} δi+1(l)=maxj{δi(j)+w∗Fi+1(Yi=j,Yi+1=l,X)}(4.2)
另,每一步计算完 δ i + 1 \delta_{i+1} δi+1,要保存 Y 1 → Y i + 1 Y_1 \rightarrow Y_{i+1} Y1→Yi+1且 Y i + 1 = j Y_{i+1}=j Yi+1=j的最优路径里, Y i Y_i Yi的取值: ψ i + 1 ( j ) = a r g m a x j { δ i ( j ) + w ∗ F i + 1 ( Y i = j , Y i + 1 = l , X ) } \psi_{i+1}(j)=argmax_j\{\delta_i(j)+w*F_{i+1}(Y_i=j,Y_{i+1}=l,X)\} ψi+1(j)=argmaxj{δi(j)+w∗Fi+1(Yi=j,Yi+1=l,X)}
Viterbi与Beam Search
Viterbi和Beam Search都是序列标注中,用于求最优序列的解码方法。而对于一个长度为 T T T,可能的标签数为 N N N的序列来说,直接求解最优序列是一个在 N T N^T NT空间上的搜索问题。
- Viterbi: 通过动态规划的方法,去除重复计算,将计算复杂度降到了 O ( N 2 × T ) O(N^2\times T) O(N2×T)
- Beam Search: 由于Beam Search常用于机器翻译,对话生成等任务上。标签数 N N N相当于动辄几万甚至十几万的词典/字典大小,因此即使是 O ( N 2 × T ) O(N^2\times T) O(N2×T)的计算复杂度也是难以接受的。所以它直接放弃了求解全局最优解,通过在每一步都将候选序列限制在概率最高的top k个,找到一个局部最优解,其计算复杂度为 O ( k × N × T ) O(k\times N\times T) O(k×N×T)
CRF与NN模型的拼接
以NER为例,不管是单独的CRF或者是单独的NN模型(例如LSTM,BiLSTM,Bert等)其实都是可以直接用来做NER的,那为什么要将两个拼接起来呢?这样做的好处是什么?
首先说NN模型,尽管LSTM已经可以考虑到不同时刻对某一位置输出的影响了,但output端始终只能看到input的内容,而看不到output端前后的输出,但在NER任务里,这种前后位置的输出对于判断当前位置的输出是很有帮助的。例如,用NN模型做分词可能出现 < E > < B >
然后对于CRF模型,由于CRF模型对于人工特征的依赖性比较强(这一点从前面介绍CRF++中的特征函数就可以发现),没有被人工定义的特征是无论如何也学习不到的;而且如果定义太多的特征,又会导致参数空间太大,降低训练效率。而例如BiLSTM/Bert这样的模型刚好可以弥补这个缺陷,利用NN模型的输出来充当CRF的输入,使得可以免于定义人工特征,让模型自然的去学习数据里的统计特征
下面一个问题是NN模型是如何与CRF拼接的:
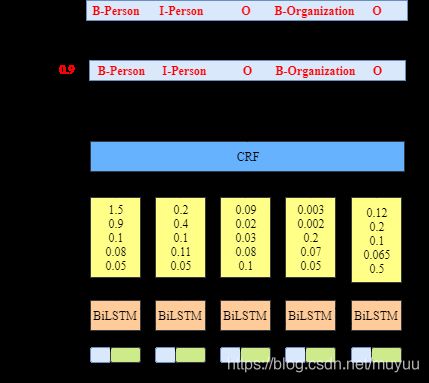
如上图所示BiLSTM会在每个位置都输出一个长度为M的向量,其中M为输出序列tag的数量。而这些向量会作为CRF的unigram特征输入CRF,而这也刚好符合CRF的定义,因为unigram特征定义的就是观测序列X(input)和当前位置状态 Y i Y_i Yi(output)的关系。而bigram的参数的训练过程与原始CRF一致,会随着整个NN-CRF的迭代而更新。
参见NN+CRF代码https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html,可知:1,每一轮迭代是NN和CRF都要训练一遍,即是端到端的训练。2,NN输出的unigram特征进入CRF之后是固定的,CRF训练时只改变bigram的值。3,做inference时,一个query输入进去,也是先经过NN,再经过CRF,因此不同query在进入CRF时的bigram特征是相同的,但unigram的特征会不同(因为不同query用NN做inference的结果不同)