Redis基础总结
目录
Redis简介
Redis 优缺点
优点
缺点
redis与其他数据库
分布式缓存常见的技术选型方案有哪些?
说一下 Redis 和 Memcached 的区别和共同点
Redis和其他数据库的区别
mysql与redis的区别与选型
nosql和关系型数据库比较?
Redis与mysql的qps与tps
Redis 单线程模型详解
多路 I/O 复用模型
Redis 没有使用多线程?为什么不使用多线程?
那么为什么Redis是单线程的
多线程适用场景
多线程的弊端
Redis6.0 之后为何引入了多线程?
注意点
Redes是单线程的,我们现在服务器都是多核的,那不是很浪费?
为什么redis效率高?
pipeline
原生批命令(mset, mget)与Pipeline对比
Lua
Redis常见性能问题和解决方案?
假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如何将它们全部找出来?
Redis版本特性
Redis 4
模块系统
PSYNC 2.0
缓存驱逐策略优化
Lazy Free
交换数据库
混合持久化
内存命令
兼容 NAT 和 Docker
Active Defrag
Redis4其他
Redis 5
Stream类型
新的Redis模块API
集群管理器更改
Lua改进
RDB格式变化
动态HZ
ZPOPMIN&ZPOPMAX命令
CLIENT新增命令
Redis5其他
Redis 6
多线程IO
SSL支持
ACL支持
RESP3
客户端缓存
集群代理
Disque module
Redis6其他
Redis简介
简单来说 Redis 就是一个使用 C 语言开发的数据库,不过与传统数据库不同的是 Redis 的数据是存在内存中的 ,也就是它是内存数据库,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向。
另外,Redis 除了做缓存之外,也经常用来做分布式锁,甚至是消息队列。
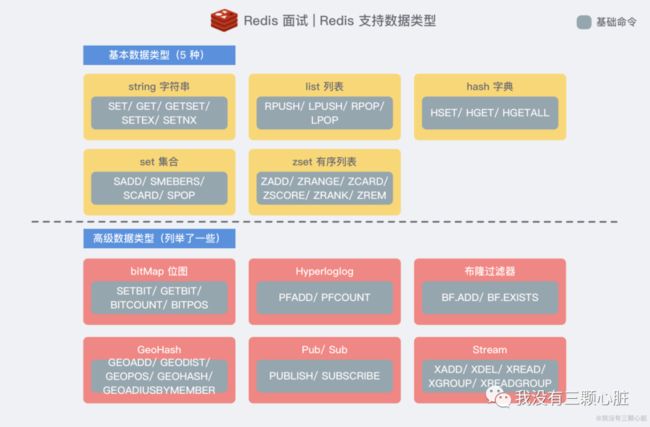
Redis 提供了多种数据类型来支持不同的业务场景。Redis 还支持事务 、持久化、Lua 脚本、多种集群方案。
Redis 优缺点
优点
读写性能优异, Redis能读的速度是 110000 次/s,写的速度是 81000 次/s。
支持数据持久化,支持 AOF 和 RDB 两种持久化方式。
支持事务,Redis 的所有操作都是原子性的,同时 Redis 还支持对几个操作合并后的原子性执行。
数据结构丰富,除了支持 string 类型的 value 外还支持 hash、set、zset、list 等数据结构。
支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
数据库 容量受到物理内存的限制,不能用作海量数据的高性能读写,因此 Redis 适合的场景主要局限在较小数据量的高性能操作和运算上。
Redis 不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的 IP 才能恢复。
主机宕机,宕机前有部分数据未能及时同步到从机,切换 IP 后还会引入数据不一致的问题,降低了系统的可用性。
Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
redis与其他数据库
分布式缓存常见的技术选型方案有哪些?
分布式缓存的话,使用的比较多的主要是 Memcached 和 Redis。不过,现在基本没有看过还有项目使用 Memcached 来做缓存,都是直接用 Redis。
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
分布式缓存主要解决的是单机缓存的容量受服务器限制并且无法保存通用信息的问题。因为,本地缓存只在当前服务里有效,比如如果你部署了两个相同的服务,他们两者之间的缓存数据是无法共同的。
说一下 Redis 和 Memcached 的区别和共同点
现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!不过,了解 Redis 和 Memcached 的区别和共同点,有助于我们在做相应的技术选型的时候,能够做到有理有据!
共同点 :
都是基于内存的数据库,一般都用来当做缓存使用。
都有过期策略。
两者的性能都非常高。
区别 :
1 Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。不过Memcached还可用于缓存其他东西,例如图片、视频等等;
2 Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中。
3 Redis 有灾难恢复机制。 因为可以把缓存中的数据持久化到磁盘上。
4 Redis 在服务器内存使用完之后,可以将不用的数据放到磁盘上。但是,Memcached 在服务器内存使用完之后,就会直接报异常。
5 Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的。
6 Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。 (Redis 6.0 引入了多线程 IO )
由于 Redis 只使用单核,而 Memcached 可以使用多核,所以平均每一个核上 Redis 在存储小数据时比 Memcached 性能更高。而在 100k 以上的数据中,Memcached 性能要高于 Redis,虽然 Redis 最近也在存储大数据的性能上进行优化,但是比起 Remcached,还是稍有逊色。
7 Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
8 Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。
9 过期策略 Memcached在set时就指定,例如:set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如:expire name 10;
10 应用场景不一样:Redis出来作为NoSQL数据库使用外,还能用做消息队列、数据堆栈和数据缓存等;Memcached适合于缓存SQL语句、数据集、用户临时性数据、延迟查询数据和Session等。
Redis和其他数据库的区别
mysql与redis的区别与选型
1 mysql和redis的数据库类型
mysql是关系型数据库,主要用于存放持久化数据,将数据存储在硬盘中,读取速度较慢。
mysql支持sql查询,可以实现一些关联的查询以及统计,而且支持事务;
redis是NOSQL,即非关系型数据库,也是内存数据库,即将数据存储在内存中,内存的读取速度快,能够大大的提高运行效率,但是保存时间有限。
2 mysql和redis的作用
mysql用于持久化的存储数据到硬盘,功能强大,速度较慢,基于磁盘,读写速度没有Redis快,但是不受空间容量限制,性价比高
redis用于存储使用较为频繁的数据到缓存中,读取速度快,基于内存,读写速度快,也可做持久化,但是内存空间有限,当数据量超过内存空间时,需扩充内存,但内存价格贵
3 mysql和redis的需求
mysql和redis因为需求的不同,一般都是配合使用。
需要高性能的地方使用Redis,不需要高性能的地方使用MySQL。存储数据在MySQL和Redis之间做同步。
4 redis和mysql选型
redis适合放一些频繁使用,比较热的数据,因为是放在内存中,读写速度都非常快,一般会应用在下面一些场景
排行榜、计数器、消息队列推送、好友关注、粉丝、缓存
首先要知道mysql存储在磁盘里,redis存储在内存里,redis既可以用来做持久存储,也可以做缓存,而目前大多数公司的存储都是mysql + redis,mysql作为主存储,redis作为辅助存储被用作缓存,加快访问读取的速度,提高性能
那么为什么不直接全部用redis存储呢?
因为redis存储在内存中,如果存储在内存中,存储容量肯定要比磁盘少很多,那么要存储大量数据,只能花更多的钱去购买内存,造成在一些不需要高性能的地方是相对比较浪费的,所以目前基本都是mysql(主) + redis(辅),在需要性能的地方使用redis,在不需要高性能的地方使用mysql,好钢用在刀刃上
nosql和关系型数据库比较?
nosql优点:
1)成本:nosql数据库简单易部署,基本都是开源软件,不需要像使用oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
2)查询速度:nosql数据库将数据存储于缓存之中,关系型数据库将数据存储在硬盘中,自然查询速度远不及nosql数据库。
3)存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
4)扩展性:关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难。
nosql缺点:
1)维护的工具和资料有限,因为nosql是属于新的技术,不能和关系型数据库10几年的技术同日而语。
2)不提供对sql的支持,如果不支持sql这样的工业标准,将产生一定用户的学习和使用成本。
3)不提供关系型数据库对事物的处理。
关系型数据库的优势:
1. 复杂查询可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
2. 事务支持使得对于安全性能很高的数据访问要求得以实现。
对于这两类数据库,对方的优势就是自己的弱势,反之亦然。
Redis与mysql的qps与tps
一般像 MySQL 这类的数据库的 QPS 大概都在 1w 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 10w+,甚至最高能达到 30w+(就单机 redis 的情况,redis 集群的话会更高)。
mysql的tps大概在1000左右,redis还是5万-30万左右
QPS(Query Per Second):服务器每秒可以执行的查询次数;
TPS 即Transactions Per Second的缩写,每秒处理的事务数目。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程**(完整处理,即客户端发起请求到得到响应)**。
客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数,最终利用这些信息作出的评估分。一个事务可能对应多个请求,可以参考下数据库的事务操作。
测试环境配置
Ubuntu Intel(R) Core(TM) i5-5257U CPU @ 2.70GHz 8GB DDR3, 40GB SSD
Redis
进入 Redis[1] 官网,使用如下步骤安装。
$ wget http://download.redis.io/releases/redis-5.0.5.tar.gz
$ tar xzf redis-5.0.5.tar.gz
$ cd redis-5.0.5
$ make
启动服务
$ src/redis-server
运行 Redis 自带的基准测试工具,运行 set,get 1000000 次,1s 后退出并显示数据
$ cd src
$ ./redis-benchmark -n 1000000 -t set,get -q
数据显示如下,结果为 SET 48009,GET 56960。
SET: 48009.98 requests per second
GET: 56960.59 requests per second
当然这数据是没有使用 pipeline 的情况下,那么使用了 pipeline 又是什么场景呢?运行命令如下,运行 set,get 1000000 次,每次发送 200 个请求到服务端,1s 后退出并显示数据
$ cd src
$ ./redis-benchmark -n 1000000 -t set,get -P 200 -q
数据显示如下,结果为 SET 315258,GET 330797。这里你可以自行调整 -P 的数值,上升到 30000 上下保持平稳,所以如下数据是理论上最佳的测试数据。
SET: 315258.53 requests per second
GET: 330797.22 requests per second
好的,到这里我们就知道了,Redis 的大致数据为 50000 - 300000,那么我们赶紧看看 MySQL 呗?
MySQL
参考 Mysql性能指标(QPS、TPS)_武壮-CSDN博客_mysql qps tps
1个tps,4个select,1个update
| 实例规格 | 存储空间 | 数据集 | 客户端数 | 单客户端并发数 | QPS | TPS |
|---|---|---|---|---|---|---|
| 1核1GB | 200GB | 19GB | 1 | 128 | 1757 | 97 |
| 1核2GB | 200GB | 38GB | 1 | 128 | 3016 | 167 |
| 2核4GB | 200GB | 76GB | 1 | 128 | 4082 | 816 |
| 4核8GB | 200GB | 142GB | 1 | 128 | 6551 | 1310 |
| 4核16GB | 400GB | 238GB | 1 | 128 | 11098 | 2219 |
| 8核32GB | 700GB | 238GB | 2 | 128 | 20484 | 3768 |
| 16核64GB | 1TB | 378GB | 2 | 128 | 36395 | 7279 |
| 16核96GB | 1.5TB | 378GB | 3 | 128 | 56464 | 11292 |
| 16核128GB | 2TB | 378GB | 3 | 128 | 81752 | 16350 |
| 24核244GB | 3TB | 567GB | 4 | 128 | 98528 | 19705 |
| 48核488GB | 6TB | 567GB | 6 | 128 | 142246 | 28449 |
| 48核488GB(调优) | 6TB | 140GB | 6 | 128 | 245509 | 46304 |
Redis 单线程模型详解
Redis 基于 Reactor 模式来设计开发了自己的一套高效的事件处理模型 (Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
既然是单线程,那怎么监听大量的客户端连接呢?
Redis 通过IO 多路复用程序 来监听来自客户端的大量连接(或者说是监听多个 socket),它会将感兴趣的事件及类型(读、写)注册到内核中并监听每个事件是否发生。
这样的好处非常明显: I/O 多路复用技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗(和 NIO 中的 Selector 组件很像)。
另外, Redis 服务器是一个事件驱动程序,服务器需要处理两类事件:1. 文件事件; 2. 时间事件。
时间事件不需要多花时间了解,我们接触最多的还是 文件事件(客户端进行读取写入等操作,涉及一系列网络通信)。
《Redis 设计与实现》有一段话是如是介绍文件事件的。
Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler)。文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关 闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件事件处理器以单线程方式运行,但通过使用 I/O 多路复用程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,这保持了 Redis 内部单线程设计的简单性。
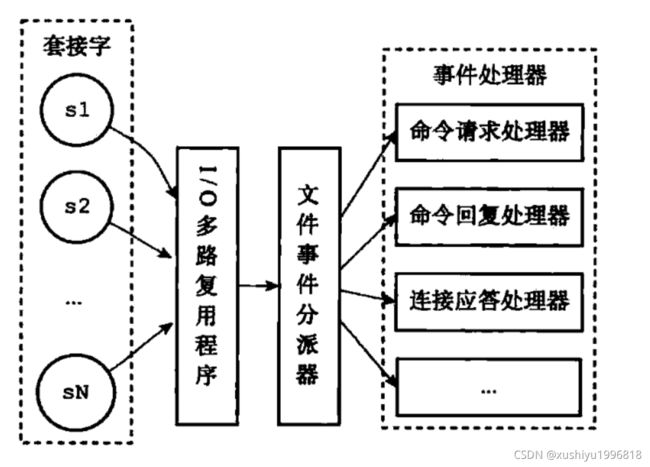
可以看出,文件事件处理器(file event handler)主要是包含 4 个部分:
多个 socket(客户端连接)
IO 多路复用程序(支持多个客户端连接的关键)
文件事件分派器(将 socket 关联到相应的事件处理器)
事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多路 I/O 复用模型
Linux多路复用技术,就是多个进程的IO可以注册到同一个管道上,这个管道会统一和内核进行交互。当管道中的某一个请求需要的数据准备好之后,进程再把对应的数据拷贝到用户空间中。

也就是说,通过一个线程来处理多个IO流。
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,主要由以上几点造就了 Redis 具有很高的吞吐量。
其实,Redis的IO多路复用程序的所有功能都是通过包装操作系统的IO多路复用函数库来实现的。每个IO多路复用函数库在Redis源码中都有对应的一个单独的文件。

在Redis 中,每当一个套接字准备好执行连接应答、写入、读取、关闭等操作时,就会产生一个文件事件。因为一个服务器通常会连接多个套接字,所以多个文件事件有可能会并发地出现。

一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
所以,Redis选择使用多路复用IO技术来提升I/O利用率。
Redis 没有使用多线程?为什么不使用多线程?
虽然说 Redis 是单线程模型,但是,实际上,Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。
不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主处理之外的其他线程来“异步处理”。
大体上来说,Redis 6.0 之前主要还是单线程处理。
那,Redis6.0 之前 为什么不使用多线程?
我觉得主要原因有下面:
1、Redis 操作基于内存,绝大多数操作的性能瓶颈不在 CPU,主要在内存和网络;
2、使用单线程模型,可维护性更高,开发,调试和维护的成本更低
3、单线程模型,避免了线程间切换带来的性能开销
4、在单线程中使用多路复用 I/O技术也能提升Redis的I/O利用率
5、多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能。
那么为什么Redis是单线程的
我们首先要明白,上边的种种分析,都是为了营造一个Redis很快的氛围!官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!)。
我们已经可以很清楚的解释了为什么Redis这么快,并且正是由于在单线程模式的情况下已经很快了,就没有必要在使用多线程了!
但是,我们使用单线程的方式是无法发挥多核CPU 性能,不过我们可以通过在单机开多个Redis 实例来完善!
警告:我们所说的Redis单线程,指的是"其网络IO和键值对读写是由一个线程完成的",也就是说,Redis中只有网络请求模块和数据操作模块是单线程的。而其他的如持久化存储模块、集群支撑模块等是多线程的。例如Redis进行持久化的时候会以子进程或者子线程的方式执行
警告:Redis 4.0版本开始会支持多线程的方式,但是,只是在某一些操作上进行多线程的操作!
多线程适用场景
一个计算机程序在执行的过程中,主要需要进行两种操作分别是读写操作和计算操作。
其中读写操作主要是涉及到的就是I/O操作,其中包括网络I/O和磁盘I/O。计算操作主要涉及到CPU。
而多线程的目的,就是通过并发的方式来提升I/O的利用率和CPU的利用率。
那么,Redis需不需要通过多线程的方式来提升提升I/O的利用率和CPU的利用率呢?
首先,我们可以肯定的说,Redis不需要提升CPU利用率,因为Redis的操作基本都是基于内存的,CPU资源根本就不是Redis的性能瓶颈。
所以,通过多线程技术来提升Redis的CPU利用率这一点是完全没必要的。
那么,使用多线程技术来提升Redis的I/O利用率呢?是不是有必要呢?
Redis确实是一个I/O操作密集的框架,他的数据操作过程中,会有大量的网络I/O和磁盘I/O的发生。要想提升Redis的性能,是一定要提升Redis的I/O利用率的,这一点毋庸置疑。
但是,提升I/O利用率,并不是只有采用多线程技术这一条路可以走!
多线程的弊端
Java中的多线程技术,如内存模型、锁、CAS等,这些都是Java中提供的一些在多线程情况下保证线程安全的技术。
线程安全:是编程中的术语,指某个函数、函数库在并发环境中被调用时,能够正确地处理多个线程之间的共享变量,使程序功能正确完成。
和Java类似,所有支持多线程的编程语言或者框架,都不得不面对的一个问题,那就是如何解决多线程编程模式带来的共享资源的并发控制问题。
虽然,采用多线程可以帮助我们提升CPU和I/O的利用率,但是多线程带来的并发问题也给这些语言和框架带来了更多的复杂性。而且,多线程模型中,多个线程的互相切换也会带来一定的性能开销。
所以,在提升I/O利用率这个方面上,Redis并没有采用多线程技术,而是选择了多路复用 I/O技术。
Redis6.0 之后为何引入了多线程?
主要是因为我们对Redis有着更高的要求。
根据测算,Redis 将所有数据放在内存中,内存的响应时长大约为 100 纳秒,对于小数据包,Redis 服务器可以处理 80,000 到 100,000 QPS,这么高的对于 80% 的公司来说,单线程的 Redis 已经足够使用了。
但随着越来越复杂的业务场景,有些公司动不动就上亿的交易量,因此需要更大的 QPS。
为了提升QPS,很多公司的做法是部署Redis集群,并且尽可能提升Redis机器数。但是这种做法的资源消耗是巨大的。
而经过分析,限制Redis的性能的主要瓶颈出现在网络IO的处理上,虽然之前采用了多路复用技术。但是我们前面也提到过,多路复用的IO模型本质上仍然是同步阻塞型IO模型。
下面是多路复用IO中select函数的处理过程:
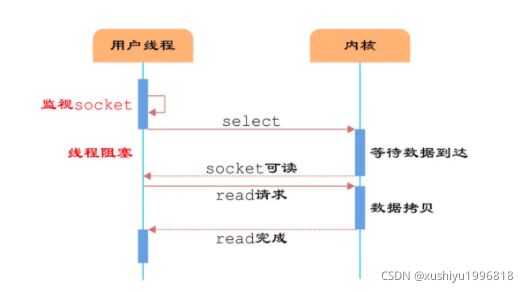
从上图我们可以看到,在多路复用的IO模型中,在处理网络请求时,调用 select (其他函数同理)的过程是阻塞的,也就是说这个过程会阻塞线程,如果并发量很高,此处可能会成为瓶颈。
虽然现在很多服务器都是多个CPU核的,但是对于Redis来说,因为使用了单线程,在一次数据操作的过程中,有大量的CPU时间片是耗费在了网络IO的同步处理上的,并没有充分的发挥出多核的优势。
如果能采用多线程,使得网络处理的请求并发进行,就可以大大的提升性能。多线程除了可以减少由于网络 I/O 等待造成的影响,还可以充分利用 CPU 的多核优势。
所以,Redis 6.0采用多个IO线程来处理网络请求,网络请求的解析可以由其他线程完成,然后把解析后的请求交由主线程进行实际的内存读写。提升网络请求处理的并行度,进而提升整体性能。
但是,Redis 的多 IO 线程只是用来处理网络请求的,对于读写命令,Redis 仍然使用单线程来处理。
那么,在引入多线程之后,如何解决并发带来的线程安全问题呢?
这就是为什么我们前面多次提到的"Redis 6.0的多线程只用来处理网络请求,而数据的读写还是单线程"的原因。
Redis 6.0 只有在网络请求的接收和解析,以及请求后的数据通过网络返回给时,使用了多线程。而数据读写操作还是由单线程来完成的,所以,这样就不会出现并发问题了。
Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要修改 redis 配置文件 redis.conf :
io-threads-do-reads yes
开启多线程后,还需要设置线程数,否则是不生效的。同样需要修改 redis 配置文件 redis.conf :
io-threads 4 #官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
注意点
1、我们知道Redis是用”单线程-多路复用IO模型”来实现高性能的内存数据服务的,这种机制避免了使用锁,但是同时这种机制在进行sunion之类的比较耗时的命令时会使redis的并发下降。因为是单一线程,所以同一时刻只有一个操作在进行,所以,耗时的命令会导致并发的下降,不只是读并发,写并发也会下降。而单一线程也只能用到一个CPU核心,所以可以在同一个多核的服务器中,可以启动多个实例,组成master-master或者master-slave的形式,耗时的读命令可以完全在slave进行。
2、“我们不能任由操作系统负载均衡,因为我们自己更了解自己的程序,所以,我们可以手动地为其分配CPU核,而不会过多地占用CPU,或是让我们关键进程和一堆别的进程挤在一起。”。
CPU 是一个重要的影响因素,由于是单线程模型,Redis 更喜欢大缓存快速 CPU, 而不是多核
在多核 CPU 服务器上面,Redis 的性能还依赖NUMA 配置和处理器绑定位置。最明显的影响是 redis-benchmark 会随机使用CPU内核。为了获得精准的结果,需要使用固定处理器工具(在 Linux 上可以使用 taskset)。最有效的办法是将客户端和服务端分离到两个不同的 CPU 来高校使用三级缓存。
Redes是单线程的,我们现在服务器都是多核的,那不是很浪费?
是的他是单线程的,但是,我们可以通过在单机开多个Redis实例嘛。
既然提到了单机会有瓶颈,那你们是怎么解决这个瓶颈的?
我们用到了集群的部署方式也就是Redis cluster,并且是主从同步读写分离,类似Mysql的主从同步,Redis cluster 支撑 N 个 Redis master node,每个master node都可以挂载多个 slave node。
这样整个 Redis 就可以横向扩容了。如果你要支撑更大数据量的缓存,那就横向扩容更多的 master 节点,每个 master 节点就能存放更多的数据了。
为什么redis效率高?
Redis采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,由C语言编写,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。这个数据不比采用单进程多线程的同样基于内存的 KV 数据库 Memcached 差!
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;(redis的瓶颈在于内存和网络,cpu不是瓶颈)
4、使用多路I/O复用模型,非阻塞IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
6、C 语言实现,一般来说,C 语言实现的程序“距离”操作系统更近,执行速度相对会更快。
pipeline
Redis本身是一个cs模式的tcp server, client可以通过一个socket连续发起多个请求命令。 每个请求命令发出后client通常会阻塞并等待redis服务端处理,redis服务端处理完后将结果返回给client。

可以将多次IO往返的时间缩减为一次,前提是pipeline执行的指令之间没有因果相关性。使用redis-benchmark进行压测的时候可以发现影响redis的QPS峰值的一个重要因素是pipeline批次指令的数目。
redis的pipeline(管道)功能在命令行中没有,但redis是支持pipeline的,而且在各个语言版的client中都有相应的实现。 由于网络开销延迟,即算redis server端有很强的处理能力,也由于收到的client消息少,而造成吞吐量小。当client 使用pipelining 发送命令时,redis server必须部分请求放到队列中(使用内存)执行完毕后一次性发送结果;如果发送的命名很多的话,建议对返回的结果加标签,当然这也会增加使用的内存;
Pipeline在某些场景下非常有用,比如有多个command需要被“及时的”提交,而且他们对相应结果没有互相依赖,而且对结果响应也无需立即获得,那么pipeline就可以充当这种“批处理”的工具;而且在一定程度上,可以较大的提升性能,性能提升的原因主要是TCP链接中较少了“交互往返”的时间。
使用pipeline组装的命令个数不能太多,不然数据量过大,增加客户端的等待时间,还可能造成网络阻塞,可以将大量命令的拆分多个小的pipeline命令完成。
不过在编码时请注意,pipeline期间将“独占”链接,此期间将不能进行非“管道”类型的其他操作,直到pipeline关闭;如果你的pipeline的指令集很庞大,为了不干扰链接中的其他操作,你可以为pipeline操作新建Client链接,让pipeline和其他正常操作分离在2个client中。不过pipeline事实上所能容忍的操作个数,和socket-output缓冲区大小/返回结果的数据尺寸都有很大的关系;同时也意味着每个redis-server同时所能支撑的pipeline链接的个数,也是有限的,这将受限于server的物理内存或网络接口的缓冲能力。
@Test
public void pipeCompare() {
Jedis redis = new Jedis("192.168.1.111", 6379);
redis.auth("12345678");//授权密码 对应redis.conf的requirepass密码
Map data = new HashMap();
redis.select(8);//使用第8个库
redis.flushDB();//清空第8个库所有数据
// hmset
long start = System.currentTimeMillis();
// 直接hmset
for (int i = 0; i < 10000; i++) {
data.clear(); //清空map
data.put("k_" + i, "v_" + i);
redis.hmset("key_" + i, data); //循环执行10000条数据插入redis
}
long end = System.currentTimeMillis();
System.out.println(" 共插入:[" + redis.dbSize() + "]条 .. ");
System.out.println("1,未使用PIPE批量设值耗时" + (end - start) / 1000 + "秒..");
redis.select(8);
redis.flushDB();
// 使用pipeline hmset
Pipeline pipe = redis.pipelined();
start = System.currentTimeMillis();
//
for (int i = 0; i < 10000; i++) {
data.clear();
data.put("k_" + i, "v_" + i);
pipe.hmset("key_" + i, data); //将值封装到PIPE对象,此时并未执行,还停留在客户端
}
pipe.sync(); //将封装后的PIPE一次性发给redis
end = System.currentTimeMillis();
System.out.println(" PIPE共插入:[" + redis.dbSize() + "]条 .. ");
System.out.println("2,使用PIPE批量设值耗时" + (end - start) / 1000 + "秒 ..");
//--------------------------------------------------------------------------------------------------
// hmget
Set keys = redis.keys("key_*"); //将上面设值所有结果键查询出来
// 直接使用Jedis hgetall
start = System.currentTimeMillis();
Map> result = new HashMap>();
for (String key : keys) {
//此处keys根据以上的设值结果,共有10000个,循环10000次
result.put(key, redis.hgetAll(key)); //使用redis对象根据键值去取值,将结果放入result对象
}
end = System.currentTimeMillis();
System.out.println(" 共取值:[" + redis.dbSize() + "]条 .. ");
System.out.println("3,未使用PIPE批量取值耗时 " + (end - start) / 1000 + "秒 ..");
// 使用pipeline hgetall
result.clear();
start = System.currentTimeMillis();
for (String key : keys) {
pipe.hgetAll(key); //使用PIPE封装需要取值的key,此时还停留在客户端,并未真正执行查询请求
}
pipe.sync(); //提交到redis进行查询
end = System.currentTimeMillis();
System.out.println(" PIPE共取值:[" + redis.dbSize() + "]条 .. ");
System.out.println("4,使用PIPE批量取值耗时" + (end - start) / 1000 + "秒 ..");
redis.disconnect();
}
原生批命令(mset, mget)与Pipeline对比
1、原生批命令是原子性,pipeline是非原子性
(原子性概念:一个事务是一个不可分割的最小工作单位,要么都成功要么都失败。原子操作是指你的一个业务逻辑必须是不可拆分的. 处理一件事情要么都成功,要么都失败,原子不可拆分)
2、原生批命令一命令多个key, 但pipeline支持多命令(存在事务),非原子性
3、原生批命令是服务端实现,而pipeline需要服务端与客户端共同完成
Lua
Redis 支持提交 Lua 脚本来执行一系列的功能。
秒杀场景经常使用这个东西,讲道理有点香,利用他的原子性。
Redis常见性能问题和解决方案?
Master 最好不要做任何持久化工作,包括内存快照和 AOF 日志文件,特别是不要启用内存快照做持久化。
如果数据比较关键,某个 Slave 开启 AOF 备份数据,策略为每秒同步一次。
为了主从复制的速度和连接的稳定性,Slave 和 Master 最好在同一个局域网内。
尽量避免在压力较大的主库上增加从库。
Master 调用 BGREWRITEAOF 重写 AOF 文件,AOF 在重写的时候会占大量的 CPU 和内存资源,导致服务 load 过高,出现短暂服务暂停现象。
为了 Master 的稳定性,主从复制不要用图状结构,用单向链表结构更稳定,即主从关系为:Master<–Slave1<–Slave2<–Slave3…,这样的结构也方便解决单点故障问题,实现 Slave 对 Master 的替换,也即,如果 Master 挂了,可以立马启用 Slave1 做 Master,其他不变。
假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如何将它们全部找出来?
使用 keys 指令可以扫出指定模式的 key 列表。但是要注意 keys 指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用 scan 指令,scan 指令可以无阻塞的提取出指定模式的 key 列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用 keys 指令长。
Redis版本特性
Redis 4
模块系统
Redis 4.0 发生的最大变化就是加入了模块系统, 这个系统可以让用户通过自己编写的代码来扩展和实现 Redis 本身并不具备的功能,因为模块系统是通过高层次 API 实现的, 它与 Redis 内核本身完全分离、互不干扰, 所以用户可以在有需要的情况下才启用这个功能。
目前已经有人使用这个功能开发了各种各样的模块, 比如 Redis Labs 开发的一些模块就可以在 http://redismodules.com 看到。模块功能使得用户可以将 Redis 用作基础设施, 并在上面构建更多功能, 这给 Redis 带来了无数新的可能性。
PSYNC 2.0
新版本的PSYNC命令解决了旧版本的 Redis 在复制时的一些不够优化的地方:
在旧版本 Redis 中, 如果一个从服务器在 FAILOVER 之后成为了新的主节点, 那么其他从节点在复制这个新主的时候就必须进行全量复制。 在 Redis 4.0 中, 新主和从服务器在处理这种情况时, 将在条件允许的情况下使用部分复制。
在旧版本 Redis 中, 一个从服务器如果重启了, 那么它就必须与主服务器重新进行全量复制, 在 Redis 4.0 中, 只要条件允许, 主从在处理这种情况时将使用部分复制。
在旧版本中,当复制为链式复制的时候,如 A—>B—>C ,主节点为A。当A出现问题,C节点不能正常复制B节点的数据。当提升B为主节点,C需要全量同步B的数据。在PSYNC2:PSYNC2解决了链式复制之间的关联性。A出现问题不影响C节点,B提升为主C不需要全量同步。
在使用星形复制时,如一主两从。A—>B , A—>C ,主节点为A。当A出现问题,B提升为主节点,C 重新指向主节点B。使用同步机制PSYNC2,C节点只做增量同步即可。在使用sentinel故障转移可以较少数据重新同步的延迟时间,避免大redis同步出现的网络带宽占满。
缓存驱逐策略优化
新添加了Last Frequently Used(LFU)缓存驱逐策略;
LFU:最不经常使用。在一段时间内,使用次数最少的数据,优先被淘汰;
另外 Redis 4.0 还对已有的缓存驱逐策略进行了优化, 使得它们能够更健壮、高效、快速和精确。
Lazy Free
在 Redis 4.0 之前, 用户在使用 DEL命令删除体积较大的键, 又或者在使用 FLUSHDB 和 FLUSHALL删除包含大量键的数据库时, 都可能会造成服务器阻塞。
为了解决以上问题, Redis 4.0 新添加了UNLINK命令, 这个命令是DEL命令的异步版本, 它可以将删除指定键的操作放在后台线程里面执行, 从而尽可能地避免服务器阻塞:
redis> UNLINK fruits
(integer) 1
因为一些历史原因, 执行同步删除操作的DEL命令将会继续保留。此外, Redis 4.0 中的FLUSHDB和FLUSHALL这两个命令都新添加了ASYNC选项, 带有这个选项的数据库删除操作将在后台线程进行:
redis> FLUSHDB ASYNC
OK
redis> FLUSHALL ASYNC
OK
还有,执行rename oldkey newkey时,如果newkey已经存在,Redis会先删除已经存在的newkey,这也会引发上面提到的删除大key问题。如果想让Redis在这种场景下也使用lazyfree的方式来删除,可以按如下配置:
lazyfree-lazy-server-del yes
交换数据库
Redis 4.0 对数据库命令的另外一个修改是新增了SWAPDB命令, 这个命令可以对指定的两个数据库进行互换: 比如说, 通过执行命令 SWAPDB 0 1 , 我们可以将原来的数据库 0 变成数据库 1 , 而原来的数据库 1 则变成数据库 0。
混合持久化
Redis 4.0 新增了 RDB-AOF 混合持久化格式, 这是一个可选的功能, 在开启了这个功能之后, AOF 重写产生的文件将同时包含 RDB 格式的内容和 AOF 格式的内容, 其中 RDB 格式的内容用于记录已有的数据, 而 AOF 格式的内存则用于记录最近发生了变化的数据, 这样 Redis 就可以同时兼有 RDB 持久化和 AOF 持久化的优点 —— 既能够快速地生成重写文件, 也能够在出现问题时, 快速地载入数据。这个功能可以通过配置项:aof-use-rdb-preamble进行开启。
内存命令
新添加了一个MEMORY命令, 这个命令可以用于视察内存使用情况, 并进行相应的内存管理操作:
redis> MEMORY HELP
1) "MEMORY USAGE
2) "MEMORY STATS - Show memory usage details"
3) "MEMORY PURGE - Ask the allocator to release memory"
4) "MEMORY MALLOC-STATS - Show allocator internal stats"
其中, 使用MEMORY USAGE子命令可以估算储存给定键所需的内存:
redis> SET msg "hello world"
OK
redis> SADD fruits apple banana cherry
(integer) 3
redis> MEMORY USAGE msg
(integer) 62
redis> MEMORY USAGE fruits
(integer) 375
使用MEMORY STATS子命令可以查看 Redis 当前的内存使用情况:
redis> MEMORY STATS
1) "peak.allocated"
2) (integer) 1014480
3) "total.allocated"
4) (integer) 1014512
5) "startup.allocated"
6) (integer) 963040
7) "replication.backlog"
8) (integer) 0
9) "clients.slaves"
10) (integer) 0
11) "clients.normal"
12) (integer) 49614
13) "aof.buffer"
14) (integer) 0
15) "db.0"
16) 1) "overhead.hashtable.main"
2) (integer) 264
3) "overhead.hashtable.expires"
4) (integer) 32
17) "overhead.total"
18) (integer) 1012950
19) "keys.count"
20) (integer) 5
21) "keys.bytes-per-key"
22) (integer) 10294
23) "dataset.bytes"
24) (integer) 1562
25) "dataset.percentage"
26) "3.0346596240997314"
27) "peak.percentage"
28) "100.00315093994141"
29) "fragmentation"
30) "2.1193723678588867"
使用MEMORY PURGE子命令可以要求分配器释放内存:
redis> MEMORY PURGE
OK
使用MEMORY MALLOC-STATS子命令可以展示分配器内部状态:
127.0.0.1:6306> MEMORY MALLOC-STATS
___ Begin jemalloc statistics ___
Version: 4.0.3-0-ge9192eacf8935e29fc62fddc2701f7942b1cc02c
Assertions disabled
Run-time option settings:
opt.abort: false
opt.lg_chunk: 21
opt.dss: "secondary"
opt.narenas: 32
opt.lg_dirty_mult: 3 (arenas.lg_dirty_mult: 3)
opt.stats_print: false
opt.junk: "false"
opt.quarantine: 0
opt.redzone: false
opt.zero: false
opt.tcache: true
opt.lg_tcache_max: 15
CPUs: 8
Arenas: 32
Pointer size: 8
Quantum size: 8
Page size: 4096
Min active:dirty page ratio per arena: 8:1
Maximum thread-cached size class: 32768
Chunk size: 2097152 (2^21)
Allocated: 3101248, active: 3371008, metadata: 1590912, resident: 4657152, mapped: 8388608
Current active ceiling: 4194304
arenas[0]:
assigned threads: 1
dss allocation precedence: secondary
min active:dirty page ratio: 8:1
dirty pages: 823:10 active:dirty, 1 sweep, 3 madvises, 1032 purged
allocated nmalloc ndalloc nrequests
small: 586304 25408 13607 170099066
large: 2514944 3967215 3967203 3967223
huge: 0 1 1 1
total: 3101248 3992624 3980811 174066290
active: 3371008
mapped: 6291456
metadata: mapped: 159744, allocated: 346240
...
...
兼容 NAT 和 Docker
在Redis Cluster集群模式下,集群的节点需要告诉用户或者是其他节点连接自己的IP和端口。
默认情况下,Redis会自动检测自己的IP和从配置中获取绑定的PORT,告诉客户端或者是其他节点。而在Docker环境中,如果使用的不是host网络模式,在容器内部的IP和PORT都是隔离的,那么客户端和其他节点无法通过节点公布的IP和PORT建立连接。
4.0中增加了三个配置:
cluster-announce-ip:要宣布的IP地址
cluster-announce-port:要宣布的数据端口
cluster-announce-bus-port:节点通信端口,默认在端口前+1
如果配置了以后,Redis节点会将配置中的这些IP和PORT告知客户端或其他节点。而这些IP和PORT是通过Docker转发到容器内的临时IP和PORT的。
Active Defrag
Redis 4.0 之后支持自动内存碎片整理(Active Defrag),通过以下选项进行配置:
# 开启自动内存碎片整理(总开关)
activedefrag yes
# 当碎片达到 100mb 时,开启内存碎片整理
active-defrag-ignore-bytes 100mb
# 当碎片超过 10% 时,开启内存碎片整理
active-defrag-threshold-lower 10
# 内存碎片超过 100%,则尽最大努力整理
active-defrag-threshold-upper 100
# 内存自动整理占用资源最小百分比
active-defrag-cycle-min 25
# 内存自动整理占用资源最大百分比
active-defrag-cycle-max 75
实现原理可参考:https://zhuanlan.zhihu.com/p/67381368
Redis4其他
Redis Cluster的故障检测方式改变,node之间的通讯减少;
慢日志记录客户端来源IP地址,这个小功能对于故障排查很有用处;
新增zlexcount命令,用于sorted set中,和zrangebylex类似,不同的是zrangebylex返回member,而zlexcount是返回符合条件的member个数;
Redis 5
Stream类型
Stream与Redis现有数据结构比较:
新的Redis模块API
新的Redis模块API:定时器(Timers)、集群(Cluster)和字典API(Dictionary APIs)。
集群管理器更改
redis3.x和redis4.x的集群管理主要依赖基于Ruby的redis-trib.rb脚本,redis5.0彻底抛弃了它,将集群管理功能全部集成到完全用C写的redis-cli中。可以通过命令redis-cli --cluster help查看帮助信息。
Lua改进
将Lua脚本更好地传播到 replicas/AOF;
Lua脚本现在可以超时并在副本中进入BUSY状态。
RDB格式变化
Redis5.0开始,RDB快照文件中增加存储key逐出策略LRU和LFU:
LRU(Least Recently Used):最近最少使用。长期未使用的数据,优先被淘汰。
LFU(Least Frequently Used):最不经常使用。在一段时间内,使用次数最少的数据,优先被淘汰。
Redis5.0的RDB文件格式有变化,向下兼容。因此如果使用快照的方式迁移,可以从Redis低版本迁移到Redis5.0,但不能从Redis5.0迁移到低版本。
动态HZ
以前redis版本的配置项hz都是固定的,redis5.0将hz动态化是为了平衡空闲CPU的使用率和响应能力。当然这个是可配置的,只不过在5.0中默认是动态的,其对应的配置为:dynamic-hz yes
ZPOPMIN&ZPOPMAX命令
ZPOPMIN key [count]
在有序集合ZSET所有key中,删除并返回指定count个数得分最低的成员,如果返回多个成员,也会按照得分高低(value值比较),从低到高排列。
ZPOPMAX key [count]
在有序集合ZSET所有key中,删除并返回指定count个数得分最高的成员,如果返回多个成员,也会按照得分高低(value值比较),从高到低排列。
BZPOPMIN key [key …] timeout
ZPOPMIN的阻塞版本。
BZPOPMAX key [key …] timeout
ZPOPMAX的阻塞版本。
CLIENT新增命令
CLIENT UNBLOCK
**格式:**CLIENT UNBLOCK client-id [TIMEOUT|ERROR]
**用法:**当客户端因为执行具有阻塞功能的命令如BRPOP、XREAD被阻塞时,该命令可以通过其他连接解除客户端的阻塞
CLIENT ID
该命令仅返回当前连接的ID。每个连接ID都有某些保证:
它永远不会重复,可以判断当前链接是否断开过;
ID是单调递增的。可以判断两个链接的接入顺序。
Redis5其他
主动碎片整理V2:增强版主动碎片整理,配合Jemalloc版本更新,更快更智能,延时更低;
HyperLogLog改进:在Redis5.0中,HyperLogLog算法得到改进,优化了计数统计时的内存使用效率;
更好的内存统计报告;
客户经常连接和断开连接时性能更好;
错误修复和改进;
Jemalloc内存分配器升级到5.1版本;
许多拥有子命令的命令,新增了HELP子命令,如:XINFO help、PUBSUB help、XGROUP help…
LOLWUT命令:没什么实际用处,根据不同的版本,显示不同的图案,类似安卓;
如果不为了API向后兼容,我们将不再使用“slave”一词:查看原因
Redis核心在许多方面进行了重构和改进。
Redis 6
多线程IO
Redis的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程顺序执行。所以我们不需要去考虑控制 key、lua、事务,LPUSH/LPOP 等等的并发及线程安全问题。
Redis6.0的多线程默认是禁用的,只使用主线程。如需开启需要修改redis.conf配置文件:io-threads-do-reads yes。开启多线程后,还需要设置线程数,否则是不生效的。修改redis.conf配置文件:io-threads ,关于线程数的设置,官方有一个建议:4核的机器建议设置为2或3个线程,8核的建议设置为6个线程,线程数一定要小于机器核数。还需要注意的是,线程数并不是越大越好,官方认为超过了8个基本就没什么意义了。
更多关于redis 6.0多线程的讲解,请查看:https://www.cnblogs.com/madashu/p/12832766.html
SSL支持
连接支持SSL协议,更加安全。
ACL支持
在之前的版本中,Redis都会有这样的问题:用户执行FLUSHAL,现在整个数据库就空了在以前解决这个问题的办法可能是在Redis配置中将危险命令进行rename,这样将命令更名为随机字符串或者直接屏蔽掉,以满足需要。当有了ACL之后,你就可以控制比如:这个连接只允许使用RPOP,LPUSH这些命令,其他命令都无法调用。
Redis ACL是Access Control List(访问控制列表)的缩写,该功能允许根据可以执行的命令和可以访问的键来限制某些连接。它的工作方式是:在客户端连接之后,需要客户端进行身份验证,以提供用户名和有效密码:如果身份验证阶段成功,则将连接与指定用户关联,并且该用户具有指定的限制。可以对Redis进行配置,使新连接通过“默认”用户进行身份验证(这是默认配置),但是只能提供特定的功能子集。
在默认配置中,Redis 6(第一个具有ACL的版本)的工作方式与Redis的旧版本完全相同,也就是说,每个新连接都能够调用每个可能的命令并访问每个键,因此ACL功能对于客户端和应用程序与旧版本向后兼容。同样,使用requirepass配置指令配置密码的旧方法仍然可以按预期工作,但是现在它的作用只是为默认用户设置密码。
Redis AUTH命令在Redis 6中进行了扩展,因此现在可以在两个参数的形式中使用它:
AUTH
也可按照旧格式使用时,即:
AUTH
Redis提供了一个新的命令ACL来维护Redis的访问控制信息,详情见:https://redis.io/topics/acl
RESP3
RESP(Redis Serialization Protocol)是 Redis 服务端与客户端之间通信的协议。Redis 6之前使用的是 RESP2,而Redis 6开始在兼容RESP2的基础上,开始支持RESP3。在Redis 6中我们可以使用HELLO命令在RESP2和RESP3协议之间进行切换:
#使用RESP2协议
HELLO 2
#使用RESP3协议
HELLO 3
推出RESP3的目的:一是因为希望能为客户端提供更多的语义化响应(semantical replies),降低客户端的复杂性,以开发使用旧协议难以实现的功能;另一个原因是为了实现 Client side caching(客户端缓存)功能。详细见:https://github.com/antirez/RESP3/blob/master/spec.md
127.0.0.1:6380> HSET myhash a 1 b 2 c 3
(integer) 3
127.0.0.1:6380> HGETALL myhash
1) "a"
2) "1"
3) "b"
4) "2"
5) "c"
6) "3"
127.0.0.1:6380> HELLO 3
1# "server" => "redis"
2# "version" => "6.0"
3# "proto" => (integer) 3
4# "id" => (integer) 5
5# "mode" => "standalone"
6# "role" => "master"
7# "modules" => (empty array)
127.0.0.1:6380> HGETALL myhash
1# "a" => "1"
2# "b" => "2"
3# "c" => "3"
客户端缓存
基于 RESP3 协议实现的客户端缓存功能。为了进一步提升缓存的性能,将客户端经常访问的数据cache到客户端。减少TCP网络交互。不过该特性目前合并到了unstable 分支,作者说等6.0 GA版本之前,还要修改很多。
客户端缓存的功能是该版本的全新特性,服务端能够支持让客户端缓存values,Redis作为一个本身作为一个缓存数据库,自身的性能是非常出色的,但是如果可以在Redis客户端再增加一层缓存结果,那么性能会更加的出色。Redis实现的是一个服务端协助的客户端缓存,叫做tracking。客户端缓存的命令是:
CLIENT TRACKING ON|OFF [REDIRECT client-id] [PREFIX prefix] [BCAST] [OPTIN] [OPTOUT] [NOLOOP]
当tracking开启时, Redis会"记住"每个客户端请求的key,当key的值发现变化时会发送失效信息给客户端。失效信息可以通过 RESP3 协议发送给请求的客户端,或者转发给一个不同的连接(支持RESP2+ Pub/Sub)。
更多信息见:http://antirez.com/news/130
集群代理
因为 Redis Cluster 内部使用的是P2P中的Gossip协议,每个节点既可以从其他节点得到服务,也可以向其他节点提供服务,没有中心的概念,通过一个节点可以获取到整个集群的所有信息。所以如果应用连接Redis Cluster可以配置一个节点地址,也可以配置多个节点地址。但需要注意如果集群进行了上下节点的的操作,其应用也需要进行修改,这样会导致需要重启应用,非常的不友好。从Redis 6.0开始支持了Prxoy,可以直接用Proxy来管理各个集群节点。本文来介绍下如何使用官方自带的proxy:redis-cluster-proxy
通过使用 redis-cluster-proxy 可以与组成Redis集群的一组实例进行通讯,就像是单个实例一样。Redis群集代理是多线程的,使用多路复用通信模型,因此每个线程都有自己的与群集的连接,该连接由属于该线程本身的所有客户端共享。
在某些特殊情况下(例如MULTI事务或阻塞命令),多路复用将被禁用;并且客户端将拥有自己的集群连接。这样客户端仅发送诸如GET和SET之类的简单命令就不需要Redis集群的专有连接。
redis-cluster-proxy的主要功能特点:
路由:每个查询都会自动路由到集群的正确节点
多线程
支持多路复用和专用连接模型
在多路复用上下文中,可以确保查询执行和答复顺序
发生ASK | MOVED错误后自动更新集群的配置:当答复中发生此类错误时,代理通过获取集群的更新配置并重新映射所有插槽来自动更新集群。 更新完成后所有查询将重新执行,因此,从客户端的角度来看,一切正常进行(客户端将不会收到ASK | MOVED错误:他们将在收到请求后直接收到预期的回复) 群集配置已更新)。
跨槽/跨节点查询:支持许多命令,这些命令涉及属于不同插槽(甚至不同集群节点)的多个键。这些命令会将查询分为多个查询,这些查询将被路由到不同的插槽/节点。 这些命令的回复处理是特定于命令的。 某些命令(例如MGET)将合并所有答复,就好像它们是单个答复一样。 其他命令(例如MSET或DEL)将汇总所有答复的结果。 由于这些查询实际上破坏了命令的原子性,因此它们的用法是可选的(默认情况下禁用)。
一些没有特定节点/插槽的命令(例如DBSIZE)将传递到所有节点,并且将对映射的回复进行映射缩减,以便得出所有回复中包含的所有值的总和。
可用于执行某些特定于代理的操作的附加PROXY命令
Disque module
这个本来是作者几年前开发的一个基于 Redis 的消息队列工具,但多年来作者发现 Redis 在持续开发时,他也要持续把新的功能合并到这个Disque 项目里面,这里有大量无用的工作。因此这次他在 Redis 的基础上通过 Modules 功能实现 Disque。
如果业务并不需要保持严格消息的顺序,这个 Disque 能提供足够简单和快速的消息队列功能。
Redis6其他
新的Expire算法:用于定期删除过期key的函数activeExpireCycle被重写,以便更快地收回已经过期的key;
提供了许多新的Module API;
从服务器也支持无盘复制:在用户可以配置的特定条件下,从服务器现在可以在第一次同步时直接从套接字加载RDB到内存;
SRANDMEMBER命令和类似的命令优化,使其结果具有更好的分布;
重写了Systemd支持;
官方redis-benchmark工具支持cluster模式;
提升了RDB日志加载速度;