【Effective Objective-C】块与大中枢派发
文章目录
- 前言
- 理解“块”这一概念
-
- 块的基础知识
- 块的内部结构
- 全局块、栈块及堆块
- 要点:
- 为常用的块类型创建typedef
-
- 要点:
- 用handler块降低代码分散程度
-
- 要点:
- 用块引用其所属对象时不要出现保留环
-
- 要点:
- 多用派发队列,少用同步锁
-
- 要点
- 多用GCD,少用performSelector系列方法
-
- 要点:
前言
开发应用程序时,最糟糕的事莫过于程序因UI线程阻塞而挂起了,在iOS系统中,阻塞过久可能会使应用程序终止执行,所幸苹果公司以全新的方式设计了多线程,并且当前多线程的核心就是“块”与“大中枢派发”,“块”是一种可在C、C++及OC代码中使用的“词法闭包”,GCD是一种与块有关的技术,它提供了对线程的抽象,而这种抽象则基于“派发队列”。
块与GCD都是当前OC编程的基石,因此,必须理解其工作原理及功能。
理解“块”这一概念
块可以实现闭包,并且其是作为“扩展”而加入GCD编译器中的。
块的基础知识
块与函数类似,只不过是直接定义在另一个函数里的,和定义它的那个函数共享同一个范围内的东西。块用“^”符号来表示,后边跟着一对花括号,括号里面是块的实现代码。例如:
^{
//代码
}
实际定义和使用如:
int (^addBlock)(int a, int b) = ^(int a, int b){
return a + b;
}
int result = addBlock(2,5); //result = 7
那么这个count值就可以在块中改变了,这也是“内联块”的用法。
如果块所捕获的变量是对象类型,那么就会自动保留它。系统在释放这个块的时候,也会将其一并释放。这就引出了一个于块有关的重要问题。块本身可视为对象。并且块本身也和其他对象一样,有引用计数。
如果将块定义在OC类的实例方法中,那么除了可以访问类的所有实例变量之外,还可以使用self变量。块总能修改实例变量,所以在声明时无需加_block。不过,如果通过读取或写入操作捕获了实例变量,那么也会自动把self变量一并捕获了,因为实例变量是与self所指代的实例关联在一起的。也就是说,只要你在块中调用到了属性值,那么这个块就会捕获这个类本身也就是self。
然而一定要记住:self也是个对象,因而块在捕获它时也会将其保留。如果self所指代的那个对象同时也保留了块,那么这种情况通常就会导致**“保留环”**。
块的内部结构
块本身也是对象,在存放块对象的内存区域中,首个变量是指向Class对象的指针,该指针叫做isa。其余内存里含有块对象正常运转所需的各种信息。块对象的内存布局:
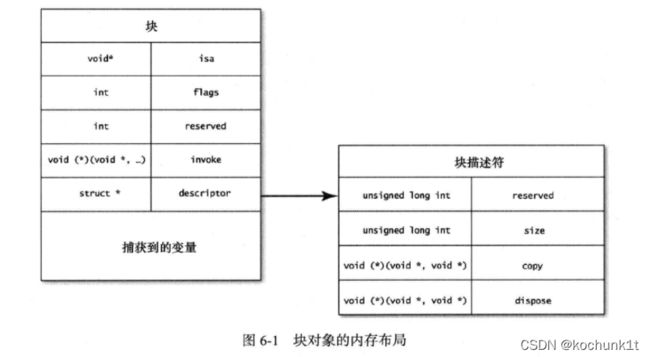
- 在内存布局中,最重要的就是
invoke变量,这是个函数指针,指向块的实现代码。函数原型至少需要接受一个void*型的参数,此参数代表块。 escriptor变量是指向结构体的指针,每个块里都包含此结构体,其中声明里块对象的总体大小,还声明里copy与dispose这两个辅助函数所对应的函数指针。- 块还会把它所捕获的所有变量都拷贝一份。这些拷贝放在
descriptor变量的后面,捕获了多少个变量,就要占据多少内存空间。请注意,拷贝的并不是对象本身,而是指向这些对象的指针变量。invoke函数为何需要把块对象作为参数传进来呢? 原因就在于,执行块时,要从内存中把这些捕获到的变量读出来。
全局块、栈块及堆块
定义块的时候,其所占的内存区域是分配在栈中的。这就是说,块只在定义它的那个范围内有效。像下面这种代码就可能有危险:
void (^block) ();
if (/**/) {
block = ^{
NSLog(@"Block A");
};
} else {
block = ^{
NSLog(@"B;ock B");
};
}
block();
- 定义在if及else语句中的两个块都分配在栈内存中。编译器会给每个块分配好栈内存。然而等离开了相应的范围之后,编译器有可能把分配给块的内存覆写掉。于是,这两个块只能保证在对应的if或else语句范围内有效。这样写出来的代码可以编译,但是运行起来时而正确,时而错误。若编译器未覆写待执行的块,则程序照常运行,若覆写,则程序崩溃。
- 为解决此问题,可给块对象发送copy消息以拷贝之。这样的话,就可以把块从栈复制到堆了。拷贝后的块,可以在定义它的那个范围之外使用。而且,一旦复制到堆上,块就成了带引用计数的对象了。后续的复制操作都不会真的执行复制,只是递增块对象的引用计数。如果不再使用这个块,那就应将其释放,在ARC环境下会自动释放,而手动管理引用计数时则需要自己来调用release方法。当引用计数降为0后,“分配在堆上的块”(heap block)会像其他对象一样,为系统所回收。而“分配在栈上的块”(stackblock)则无须明确释放,因为栈内存本来就会自动回收,刚才那段范例代码之所以有危险,原因也在于此。
明白这一点后,我们只需给代码加上两个copy方法调用,就可令其变得安全了:
void (^block) ();
if (/**/) {
block = [^{
NSLog(@"Block A");
} copy];
} else {
block = [^{
NSLog(@"B;ock B");
} copy];
}
block();
现在代码就安全了。如果手动管理引用计数,那么在用完块后还需将其释放。
除了“栈块”和“堆块”之外,还有一类块叫做“全局块”(globalblock)。这种块不会捕捉任何状态(比如外围的变量等),运行时也无须有状态来参与。块所使用的整个内存区域,在编译期已经完全确定了,因此,全局块可以声明在全局内存里,而不需要在每次用到的时候于栈中创建。另外,全局块的拷贝操作是个空操作,因为全局块决不可能为系统所回收。这种块实际上相当于单例。下面就是个全局块:
void (^block)() = ^{
NSLog(@"This is a block");
};
由于运行该块所需的全部信息都能在编译期确定,所以可以把它做成全局块。这完全是种优化技术:若把如此简单的块当作复杂的块来处理,那就会在复制及丢弃该块时执行一些无谓的操作。
要点:
- 块是C、C++、OC中的词法闭包。
- 块可接受参数,也可返回值。
- 块可以分配在栈上或堆上,也可以是全局的。分配在栈上的块可拷贝到堆里,这样的话,就和标准的OC对象一样,具备引用计数了。
为常用的块类型创建typedef
每个块都具备其“固有类型”(inherent type),因而可将其赋给适当类型的变量。这个类型由块所接受的参数及其返回值组成。例如下面这个块:
^(BOOL flag, int value) {
if (flag) {
return value * 5;
} else {
return value * 10;
}
}
此块接受两个类型分别为BOOL及int的参数,并返回类型为int的值。如果想把它赋给变量,则需注意其类型。变量类型及相关赋值语句如下:
int (^variableName)(BOOL flag, int value) =
^(BOOL flag, int value) {
// Implementation
return someInt;
}
这个类型似乎和普通的类型大不相同,然而如果习惯函数指针的话,那么看上去就会觉得眼熟了。块类型的语法结构如下:
return_type (^block_name)(parameters)
与其他类型的变量不同,在定义块变量时,要把变量名放在类型之中,而不要放在右侧。这种语法非常难记,也非常难读。鉴于此,我们应该为常用的块类型起个别名,尤其是打算把代码发布成API供他人使用时,更应这样做。开发者可可以起个更为易读的名字来表示块的用途,而把块的类型隐藏在其后面。
为了隐藏复杂的块类型,需要用到C语言中名为“类型定定义”(type definition)的特性。typedef关键字用于给类型起个易读的别名。比方说,想定义人新类型,用以表示接受BOOL及int参数并返回int值的块,可通过下列语句来做:
typedef int(^SomeBlock)(BOOL, int value);
声明变量时,要把名称放在类型中间,并在前面加上“^”符号,而定义新类型时也得这么做。上面这条语句向系统中新增了一个名为SomeBlock的类型。此后,不用再以复杂的块类型来创建变量了,直接使用新类型即可:
SomeBlock block = ^(BOOL flag, int value) {
// Implementation
};
这次代码读起来就顺畅多了:与定义其他变量时一样,变量类型在左边,变量名在右边。
通过这项特性,可以把使用块的API做得更为易用些。类里面有些方法可能需要用块来做参数,比如执行异步任务时所用的“completion handler”(任务完成后所执行的处理程序)参数就是块,凡遇到这种情况,都可以通过定义别名使代码变得更为易读。
要点:
- 以typedef重新定义块类型,可令块变量用起来更加简单。
- 定义新类型时应遵从现有的命名习惯,勿使其名称与别的类型相冲突。
- 不妨为同一个块签名定义多个类型别名。如果要重构的代码使用了块类型的某个别名,那么只需要修改相应typedef中的块签名即可,无须改动其他typedef。
用handler块降低代码分散程度
为用户界面编码时,一种常用的范式就是“异步执行任务”(perform task
asynchronously)。这种范式的好处在于:处理用户界面的显示及触摸操作所用的线程,不会因为要执行I/O或网络通信这类耗时的任务而阻塞。这个线程通常常称为主线程(main
thread)。假设把执行异步任务的方法做成同步的,那么在执行任务时,用户界面就变得无法响应用户输入了。某些情况下,如果应用程序在一定时间内无响应,那么就会自动终止。iOS系统上的应用程序就是如此,“系统监控器”(system
watchdog)在发现某个应用程序的主线程已经阻塞了一段时间之后,就会令其终止。
异步方法在执行完任务之后,需要以某种手段通知相关代码。实现此功能有很多办法。常用的技巧是设计一个委托协议,令关注此事件的对象遵从该协议。对象成为delegate之后,就可以在相关事件发生时(例如某个异步任务执行完毕时)得到通知了。
- 比方说,要写一个从 URL 中获取数据的类。使用委托模式设计出来的类会是这个样子:
#import <Foundation/Foundation.h>
@class NetworkFetcher;
@protocol NetworkFetcherDelegate <NSObject>
- (void)networkFetcher:(NetworkFetcher*)networkFetcher didFinishWithData:(NSData*)data;
@end
```objectivec
#import <Foundation/Foundation.h>
typedef void(^EOCNetworkFetcherCompletionHandler)(NSData *data)
@interface NetworkFetcher :NSObject
(id)initWithURL:(NSURL*)url;
-(void)startWithCompletionHandler:(NetworkFetcherCompletionHandler)handler;
@end
@interface NetworkFetcher : NSObject
@property (nonatomic, weak) id<NetworkFetcherDelegate> delegate
- (id)initWithURL:(NSURL*)url;
- (void)start;
@end
而其他类则可像下面这样使用此类所提供的API:
- (void)fetchFooData {
NSURL *url = [[NSURL alloc] initwithstring:@"..."];
NetworkFetcher *fetcher = [[NetworkFetcher alloc] initwithurl:url];
fetcher.delegate = self;[fetcher start];
}
// ...
- (void)networkFetcher:(NetworkFetcher*)networkFetcher didFinishWithData:(NSData*)data {
fetchedFooData = data;
}
这种做法确实可行,而且没有什么错误。然而如果改用块来写的话,代码会更清晰。块可以令这种API变得更紧致,同时也令开发者调用起来更加方便。办法就是:把 completion handler定义为块类型,将其当作参数直接传给start方法:
#import <Foundation/Foundation.h>
typedef void(^EOCNetworkFetcherCompletionHandler)(NSData *data)
@interface NetworkFetcher :NSObject
(id)initWithURL:(NSURL*)url;
-(void)startWithCompletionHandler:(NetworkFetcherCompletionHandler)handler;
@end
与使用委托模式的代码相比,用块写出来的代码显然更为整洁。异步任务执行完毕后所运行的业务逻辑,和启动异步任务所用的代码放在了一起。而且,由于块声明在创建获取据的范围里,所以它可以访问此范围内的全部变量。本例比较简单,体现不出这一点,然而在更为复杂的场景中,会大有裨益。
委托模式有个缺点:如果类要分别使用多个获取器下载不同数据,那么就得在delegate回调方法里根据传人的获取器参数来切换。这种代码的写法如下:
- (void)fetchFooData {
NSURL *url = [[NSURLalloc] initWithString:@"..."];
fooFetcher = [[NetworkFetcher alloc] initWithUrl:url];
fooFetcher.delegate = self;
[_fooFetcher start];
}
- (void)fetchBarData {
NSURL *url = [[NSURLalloc] initwithstring:@"..."];
barFetcher = [[NetworkFetcher alloc] initWithURL:url];
_barFetcher.delegate = self;
[barFetcher start];
}
- (void)networkFetcher:(NetworkFetcher*)networkFetcher didFinishWithData:(NSData*)data {
if (networkFetcher == _fooFetcher) {
fetchedFooData = data;
fooFetcher = nil;
} else if (networkFetcher == _barFetcher) {
fetchedBarData = data;
barFetcher = nil;
}
// etc.
}
这么写代码,不仅会令delegate 回调方法变得很长,而且还要把网络数据获取器对象保存为实例变量,以便在判断语句中使用。这么做可能有其他原因,比如稍后要根据情况解除监听等,然而这种写法有副作用,通常很快就会使类的代码激增。改用块来写的好处是:无须保存获取器,也无须在回调方法里切换。
把成功情况和失败情况放在同一个块中,还有个优点:调用API的代码可能会在处理成功响应的过程中发现错误。比方说,返回的数据可能太短了。这种情况需要和网络数据获取器所认定的失败情况按同一方式处理。此时,如果采用单一块的写法,那么就能把这种情况和获取器所认定的失败情况统一处理了。要是把成功情况和失败情况交给两个不同的处理程序来负责,那么就没办法共享同一份错误处理代码了,除非把这段代码单独放在一个方法里,而这又违背了我们想把全部逻辑代码都放在一处的初衷。
总体来说,建议使用同一个块来处理成功与失败情况,苹果公司似乎也是这样设计其API的。例如,Twitter 框架中的 TWRequest 及 MapKit 框架中的 MKLocalSearch 都只使用一个handler 块。
有时需要在相关时间点执行回调操作,这种情况也可以使用handler块。比方说,调用网络数据获取器的代码,也许想在每次有下载进度时都得到通知。这可以通过委托模式实现。不过也可以使用本节讲的handler块,把处理下载进度的handler定义成块类型,并新增一个此类型的属性:
typedef void(^NetworkFetcherCompletionHandler)(float progress);
@property (nonatomic, copy) NetworkFetcherProgressHandler progressHandler;
这种写法很好,因为它还是能把所有业务逻辑都放在一起:也就是把创建网络数据获取器和定义progress handler所用的代码写在一处。
基于handler来设计API还有个原因,就是某些代码必须运行在特定的线程上。比方说,Cocoa与Cocoa Touch中的UI操作必须在主线程上执行。这就相当于GCD中的“主队列”(main queue)。因此,最好能由调用API的人来决定handler 应该运行在哪个线程上。 NSNotificationCenter就属于这种API,它提供了一个方法,调用者可以经由此方法来注册想要接收的通知,等到相关事件发生时,通知中心就会执行注册好的那个块。调用者可以指定某个块应该安排在哪个执行队列里,然而这不是必需的。若没有指定队列,则按默认方式执行,也就是说,将由投递通知的那个线程来执行。下列方法可用来新增观察者(observer):
- (id)addObserverForName:(NSString*)name object:(id)object queue:(NSOperationQueue*)queue usingBlock:(void(^)(NSNotification*))block
- 此处传人的NSOperationQueue参数就表示触发通知时用来执行块代码的那个队列。这是个“操作队列”(operation queue),而非“底层GCD队列”(low-level GCD queue),不过两者语义相同。
- 也可以照此设计自己的API,根据API所处的细节层次,可选用操作队列甚至GCD队列作为参数。
要点:
- 如果块所捕获的对象直接或间接的保留了块本身,那么就得当心保留环问题。
- 一定要找个适当的时机解除保留环,而不能把责任推给API的调用者。
用块引用其所属对象时不要出现保留环
使用块时,若不仔细思量,则很容易导致“保留环”(retaincycle)。比如,下面这个类就提供了一套接口,调用者可由此从某个URL中下载数据。在启动获取器时,可设置completion handler,这个块会在下载结束之后以回调方式执行。为了能在下载完成后通过p_requestCompleted 方法执行调用者所指定的块,这段代码需要把 completionhandler 保存到实例变量里面。
// NetworkFetcher.h
#import <Foundation/Foundation.h>
typedef void(^NetworkFetcherCompletionHandler)(NSData *data);
@interface NetworkFetcher : NSObject
@property (nonatomic, strong, readonly) NSURL *url;
- (id)initWithURL:(NSURL*)url;
- (void)startWithCompletionHandler:(NetworkFetcherCompletionHandler)completion;
@end
// NetworkFetcher.m
#import"NetworkFetcher.h"
@interface NetworkFetcher ()
@property (nonatomic, strong, readwrite) NSURL *url;
@property (nonatomic,copy) NetworkFetcherCompletionHandler completionHandler;
@property (nonatomic, strong) NSData *downloadedData;
@end
@implementation NetworkFetcher
- (id)initWithURL:(NSURL*)url {
if (self = [super init]) {
_url = url;
}
return self;
}
- (void)startWithCompletionHandler:(NetworkFetcherCompletionHandler)completion {
self.completionHandler = completion;
//Start the request
//Request sets downloadedData property
//When reguest is finished, p_requestCompleted is called
}
- (void)p_requestCompleted {
if(_completionHandler) {
_completionHandler(_downloadedData);
}
}
@end
某个类可能会创建这种网络数据获取器对象,并用其从URL中下载数据:
@implementation MyClass {
NetworkFetcher *_networkFetcher;
NSData *_fetchedData;
}
- (void)downloadData {
NSURL *url = [[NSURL alloc] initWithstring:@"..."];
_networkFetcher = [[NetworkFetcher alloc] initWithUrl:url];
[_networkFetcher startWithCompletionHandler:^(NSData *data) {
NSLog(@"Request URL %@ finished", _networkFetcher.url);
_fetchedData = data;
}];
}
@end
这段代码看上去没什么问题。但你可能没发现其中有个保留环。因为completion handler块要设置fetchedData实例变量,所以它必须捕获self变量。这就是说,handler块保留了创建网络数据获取器的那个MyClass实例。而MyClass实例则通过strong实例变量保留了获取器,最后,获取器对象又保留了handler块。
要打破保留环也很容易:要么令_networkFetcher实例变量不再引用获取器,要么令获取器的completionHandler属性不再持有handler块。在网络数据获取器这个例子中,应该等completion handler块执行完毕后,再去打破保留环,以便使获取器对象在handler块执行期间保持存活状态。比方说,completion handler块的代码可以这么修改:
[_networkFetcher startWithCompletionHandler:^(NSData *data) {
NSLog(@"Request for URL &@ finished", _networkFetcher.url);
fetchedData = data;
networkFetcher = nil;
}];
大部分网络通信库都采用这种办法,因为假如令调用者自己来将获取器对象保持存话的话,他们会觉得麻烦。Twitter框架的TWRequest对象也用这个办法。然而,就NetworkFetcher的现有代码来看,此做法会引入保留环。而这次比刚才那个例子更难于发觉,completion handler块其实要通过获取器对象来引用其中的URL。于是,块就要保留获取器,而获取器反过来又经由其completionHandler属性保留了这个块。所幸要修复这个问题也难。回想一下,获取器对象之所以要把completion handler块保存在属性里面,其唯一目的是想稍后使用这个块。可是,获取器一旦运行过 completion handler之后,就没有必要再保留它了。所以,只需将 p_requestCompleted方法按如下方式修改即可:
- (void)p_requestCompleted {
if (_completionHandler) {
_completionHandler(_downloadedData);
}
self.completionHandler = nil;
}
这样一来,只要下载请求执行完毕,保留环就解除了,而获取器对象也将会在必要时为系统所回收。请注意,之所以要在start方法中把 completion handler作为参数传进去,这也是一条重要原因。假如把completion handler暴露为获取器对象的公共属性,那么就不便在执行完下载请求之后直接将其清理掉了,因为既然已经把 handler作为属性公布了,那就意味着调用者可以自由使用它,若是此时又在内部将其清理掉的话,则会破坏“封装语义”(encapsulation semantic)。在这种情况下要想打破保留环,只有一个办法可用,那就是强迫调用者在handler代码里自己把completionHandler属性清理干净。可这并不是十分合理,因为你无法假定调用者一定会这么做,他们反过来会抱怨你没把内存泄漏问题处理好。
这两种保留环都很容易发生。使用块来编程时,一不小心就会出现这种bug,反过来说,只要小心谨慎,这种问题也很容易解决。关键在于,要想清楚块可能会捕获并保留哪些对象。如果这些对象又直接或间接保留了块,那么就要考虑怎样在适当的时机解除保留环。
要点:
- 派发队列可用来表述同步语义,这种做法要比使用@synchronized块或NSLock对象更简单。
- 将同步与异步派发结合起来,可以实现与普通加锁机制一样的同步行为,而这么做却不会阻塞执行异步派发的线程。
- 使用同步队列及栅栏块,可以令同步行为更加高效。
多用派发队列,少用同步锁
在OC 中,如果有多个线程要执行同一份代码,那么有时可能会出问题。这种情况下,通常要使用锁来实现某种同步机制。在GCD出现之前,有两种办法,第一种是采用内置的“同步块”(synchronization block):
- (void)synchronizedMethod {
@synchronized(self) {
// Safe
}
}
也可以使用NSRccursiveLock这种“递归锁”(重入锁,recursive lock),线程能够多次持有该锁而不会出现死锁(deadlock)现象。
这两种方法都很好,不过也有其缺陷。比方说,在极端情况下,同步块会导致死锁,另外,其效率也不见得很高,而如果直接使用锁对象的话,一旦遇到死锁,就会非常麻烦。
替代方案就是使用GCD,它能以更简单、更高效的形式为代码加锁。比方说,属性就是开发者经常需要同步的地方,这种属性需要做成“原子的”。用atomic特质来修饰属性,即可实现这一点。而开发者如果想自己来编写访问方法的话,那么通常会这样写
- (NSString*)someString {
@synchronized(self) {
return _someString;
}
}
- (void)setSomeString:(NSString*)someString {
@synchronized(self) {
_someString = someString;
}
}
刚才说过,滥用@synchronized(self)会很危险,因为所有同步块都会彼此抢夺同一个锁。要是有很多个属性都这么写的话,那么每个属性的同步块都要等其他所有同步块执行完毕才能执行,这也许并不是开发者想要的效果。我们只是想令每个属性各自独立地同步。
顺便说一下,这么做虽然能提供某种程度的“线程安全”(thread safety),但却无法保证访问该对象时绝对是线程安全的。当然,访问属性的操作确实是“原子的”。使用属性时必定能从中获取到有效值,然而在同一个线程上多次调用获取方法(getter),每次获取到的结果却未必相同。在两次访问操作之间,其他线程可能会写人新的属性值。
有种简单而高效的办法可以代替同步块或锁对象,那就是使用“串行同步队列”(serial synchronization queue)。将读取操作及写人操作都安排在同一个队列里,即可保证数据同步。其用法如下:
_syncQueue =
dispatch_queue_create("com.mine.syncQueue", NULL);
- (NSString*)someString {
__block NSString *localSomeString;
dispatch_sync(_syncQueue, ^{
localSomeString = _someString;
});
return localsomeString;
}
- (void)setSomeString:(NSString*)someString {
dispatch_sync(_syncQueue, ^{
_someString = someString;
});
}
此模式的思路是:把设置操作与获取操作都安排在序列化的队列里执行,这样的话,所有针对属性的访问操作就都同步了。为了使块代码能够设置局部变量,获取方法中用到了__block 语法,若是抛开这一点,那么这种写法要比前面那些更为整洁。全部加锁任务都在 GCD 中处理,而 GCD 是在相当深的底层来实现的,于是能够做许多优化。因此,开发者无须担心那些事,只要专心把访问方法写好就行。
- 然而还可以进一步优化。设置方法并不一定非得是同步的。设置实例变量所用的块,并不需要向设置方法返回什么值。也就是说,设置方法的代码可以改成下面这样:
- (void)setSomeString:(NSString*)someString {
dispatch_async(_syncQueue, ^{
someString=someString;
});
}
这次只是把同步派发改成了异步派发,从调用者的角度来看,这个小改动可以提升设置方法的执行速度,而读取操作与写入操作依然会按顺序执行。但这么改有个坏处:如果测一下程序性能,那么可能会发现这种写法比原来慢,因为执行异步派发时,需要拷贝块。若拷贝块所用的时间明显超过执行块所花的时间,则这种做法将比原来更慢。由于本书所举的这个例子很简单,所以改完之后很可能会变慢。然而,若是派发给队列的块要执行更为繁重的任务,那么仍然可以考虑这种备选方案。
多个获取方法可以并发执行,而获取方法与设置方法之间不能并发执行,利用这个特点,还能写出更快一些的代码来。此时正可以体现出GCD写法的好处。用同步块或锁对象,是无法轻易实现出下面这种方案的。这次不用串行队列,而改用并发队列(concurrent queue):
_syncQueue =
dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, O);
- (NSString*)someString {
__block NSString *localSomeString;
dispatch_sync(_syncQueue, ^{
localSomeString=_someString;
});
return localSomeString;
}
- (void)setSomeString:(NSString*)someString {
dispatch_async(_syncQueue, ^{
_someString = someString;
});
}
像现在这样写代码,还无法正确实现同步。所有读取操作与写入操作都会在同一个队列上执行,不过由于是并发队列,所以读取与写入操作可以随时执行。而我们恰恰不想让这些操作随意执行。此问题用一个简单的GCD 功能即可解决,它就是栅栏(barrier)。下列函数可以向队列中派发块,将其作为栅栏使用:
void dispatch_barrier_async(dispatch_queue_t queue,
dispatch_block_t_block);
void dispatch_barrier_sync(dispatch_queue_t queue,
dispatch_block_t_block);
- 在队列中,栅栏块必须单独执行,不能与其他块并行。这只对并发队列有意义,因为串行队列中的块总是按顺序逐个来执行的。并发队列如果发现接下来要处理的块是个栅栏块(barrier block),那么就一直要等当前所有并发块都执行完毕,才会单独执行这个栅栏块。待栅栏块执行过后,再按正常方式继续向下处理。
要点
- 派发队列可用来表述同步语义(synchronization semantic),这种做法要比使用@synchronized 块或 NSLock 对象更简单。
- 将同步与异步派发结合起来,可以实现与普通加锁机制一样的同步行为,而这么做却不会阻塞执行异步派发的线程。
- 使用同步队列及栅栏块,可以令同步行为更加高效。
多用GCD,少用performSelector系列方法
OC本质上是一门非常动态的语言,NSObject定义了几个方法,令开发者可以随意调用任何方法。这几个方法可以推迟执行方法调用,也可以指定运行方法所用的线程。这些功能原来很有用,但是在出现了大中枢派发及块这样的新技术之后,就显得不那么必要了。虽说有些代码还是会经常用到它们,但还是避开为妙。
这其中最简单的是“performSelector:”。该方法的签名如下,它接受一个参数,就是要执行的那个选择子:
- (id)performSelector:(SEL)selector
该方法与直接调用选择子等效。所以下面两行代码的执行效果相同:
[object performSelector:@selector(selectorName)];
[object selectorName];
这种方式看上去似乎多余。如果某个方法只是这么来调用的话,那么此方式确实多余。然而,如果选择子是在运行期决定的,那么就能体现出此方式的强大之处了。这就等于在动态绑定之上再次使用动态绑定,因而可以实现出下面这种功能:
SEL selector;
if ( /* some condition */ ) {
selector = @selector(foo);
} else if ( /* some other condition */ ) {
selector = @selector(bar);
} else {
selector = @selector(baz);
}
[obiect performSelector:selector];
种编程方式极为灵活,经常可用来简化复杂的代码。还有一种用法,就是先把选择子存起来,等某个事件发生之后再调用。不管哪种用法,编译器都不知道要执行的选择子是什么,这必须到了运行期才能确定。然而,使用此特性的代价是,如果在ARC下编译代码。那么编译器会发出如下警示信息:
warning: performSelector may cause a leak because its selector is unknown [-Warc-performSelector-leaks]
你可能没料到会出现这种警告。要是早就料到了,那么你也许已经知道使用这些方法时为何要小心了。这条消息看上去可能比较奇怪,而且令人纳闷:为什么其中会提到内存泄漏问题呢?只不过是用“performSelector:”调用了一个方法。原因在于,编译器并不知道将要调用的选择子是什么,因此,也就不了解其方法签名及返回值,甚至连是否有返回值都不清楚。而且,由于编译器不知道方法名,所以就没办法运用ARC 的内存管理规则来判定返回值是不是应该释放。鉴于此,ARC 采用了比较谨慎的做法,就是不添加释放操作。然而这么做可能导致内存泄漏,因为方法在返回对象时可能已经将其保留了。
performSelector 还有如下几个版本,可以在发消息时顺便传递参数:
- (id)performSelector:(SEL)selector withObject:(id)object
-(id)performSelector:(SEL)selector withobject:(id)objectA withobject:(id)objectB
比方说,可以用下面这个版本来设置对象中名为 value 的属性值:
id object = /* an object with a property called value */;
id newvalue = /* new value for the property */;
[object performSelector:@selector(setValue:) withobject:newValue];
这些方法貌似有用,但其实局限颇多。由于参数类型是id,所以传入的参数必须是对象才行。如果选择子所接受的参数是整数或浮点数,那就不能采用这些方法了。此外,选择子最多只能接受两个参数,也就是调用“performSelector:withObject:withObject:”这个版本。而在参数不止两个的情况下,则没有对应的performSelector方法能够执行此种选择子。
要点:
- 在解决多线程与任务管理问题时,派发队列并非唯一方案。
- 操作队列提供了一套高层的OC API,能实现纯GCD所具备的绝大部份功能,而且还能完成一些更为复杂的操作,那些操作若改用GCD来实现,则需另外编写代码。