python tesseract selenium自动识别验证码登陆
文章目录
- 前言
- 一、下载安装tesserocr
-
- 1. 环境:win7 x64位 +python3.6
- 2. 下载链接
- 3.安装注意事项
- 二、安装pytesseract和Pillow包
-
- 1.使用pycharm导入pytesseract和Pillow包
- 2.pytesseract包路径设置
- 三、验证码图片处理
-
- 1.使用selenium自动批量右击下载验证码
- 2.处理验证码,将其分割为一个个字母
- 3.使用jTessBoxEditor建立训练集
-
- 1).合并图片
- 2).生成mjchar.box文件
- 3). 校正字符集
- 4).训练
- 四、实际应用
-
- 1.定义一个函数,根据输入图片路径,输出识别出的验证码
- 2.将验证码截图传入路径
- 3.结果
- 总结
前言
前期写得爬虫已经逐渐稳定,但是每次都是手动输入验证码,时间久了觉得麻烦,就想着自动识别验证码登陆,于是就开启了各种百度之路,磕磕碰碰,总算成功实现自动登陆,特次复盘此次验证码识别的全过程,以便大家参考。
一、下载安装tesserocr
1. 环境:win7 x64位 +python3.6
tesserocr是Python的一个OCR识别库,但其实是对tesseract做的一层PythonAPI封装,所以它的核心是tesseract。所以需要先安装tesseract。
2. 下载链接
- 下载链接:https://digi.bib.uni-mannheim.de/tesseract/
- 百度云链接:https://pan.baidu.com/s/1LpTBxBitlljUwP0cyqZS-Q 提取码:1d53
我下载的是tesseract-ocr-setup-3.05.01版本,并且将之后需要用到软件以及语言包打包在一起,有需要的读者可以点击百度云链接下载。

3.安装注意事项
-
安装注意事项:在安装到图片这一步时不需要勾选语言包,因为在安装过程中需要额外下载,但总是报错下载不了,可以先安装完再将单独下载语言包放入.\Tesseract-OCR\tessdata文件夹中即可。

-
添加系统变量:我是参考用于图片文本识别的Tesseract-OCR的安装说明(windows10)这篇博文的。
二、安装pytesseract和Pillow包
1.使用pycharm导入pytesseract和Pillow包
2.pytesseract包路径设置
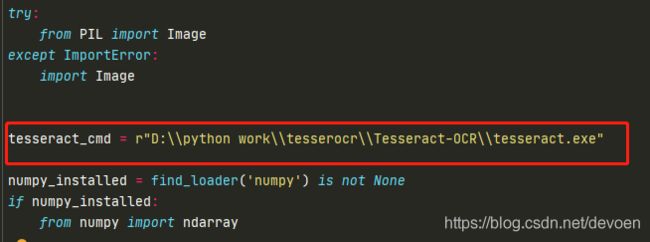
- pytesseract安装完需要打开pytesseract文件,找到tesseract_cmd(一般在前几十行),将其设置为自己的tesseract.exe的安装路径,不然运行时会报错。
tesseract_cmd = r"D:\\python work\\tesserocr\\Tesseract-OCR\\tesseract.exe"
三、验证码图片处理
1.使用selenium自动批量右击下载验证码
这里我采用的是每次点击验证码就会自动刷新一下,然后右击另存为保存验证码,循环100次。
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
import win32api
import win32con
# 键盘键按下
def keyDown(keyName):
win32api.keybd_event(VK_CODE[keyName], 0, 0, 0)
# 键盘键抬起
def keyUp(keyName):
win32api.keybd_event(VK_CODE[keyName], 0, win32con.KEYEVENTF_KEYUP, 0)
if __name__ == '__main__':
url = ''
driver = webdriver.Chrome()
driver.get(url)
VK_CODE = {'enter': 0x0D, 'down_arrow': 0x28}
element = driver.find_element_by_xpath('//*[@id="vercode"]')
for i in range(100):
element.click()
action = ActionChains(driver).move_to_element(element) # 移动到该元素
action.context_click(element).perform() # 右键点击该元素
time.sleep(1)
win32api.keybd_event(86, 0, 0, 0)
win32api.keybd_event(86, 0, win32con.KEYEVENTF_KEYUP, 0)
time.sleep(3)
keyDown("enter")
keyUp("enter")
time.sleep(1)
得到的验证码如下:

2.处理验证码,将其分割为一个个字母
从这里开始之后的每一个步骤都是参考这篇文章:python+tesseract 训练和破解验证码
我将爬取下来的图片放在脚本所在目录的origin_imgs文件夹中,直接粘贴作者所写代码,成功将处理好后的照片放入clean_imgs文件夹中,脚本如下:
import pytesseract
from PIL import Image
import os
if __name__ == '__main__':
path = os.path.dirname(__file__)
origin_path = path + '/origin_imgs/'
new_path = path + '/clean_imgs/' #用来存放处理好的图片
#从100张图片中提取出字符样本
print(os.listdir(origin_path))
for image in os.listdir(origin_path):
im = Image.open(origin_path + image)
width, height = im.size
# 获取图片中的颜色,返回列表[(counts, color)...]
color_info = im.getcolors(width * height)
# 按照计数从大到小排列颜色,那么颜色计数最多的应该是背景,接下来排名2到6的则对应5个字符。
sort_color = sorted(color_info, key=lambda x: x[0], reverse=True)
# 根据颜色,提取出每一个字符,重新放置到一个新建的白色背景image对象上。每个image只放一个字符。
char_dict = {}
for i in range(1, 6):
im2 = Image.new('RGB', im.size, (255, 255, 255))
for x in range(im.size[0]):
for y in range(im.size[1]):
if im.getpixel((x, y)) == sort_color[i][1]:
im2.putpixel((x, y), (0, 0, 0))
else:
im2.putpixel((x, y), (255, 255, 255))
im2.save(new_path + str(i) + '-' + image.replace('jpg', 'tif'))
print('成功处理图片{}'.format(image))

运行后得到的结果是如上图所示的白底黑字的单个字符,接下就是去识别训练这些单个字符。
3.使用jTessBoxEditor建立训练集
参考这篇文章:python+tesseract 训练和破解验证码
1).合并图片
- 这里我在使用jTessBoxEditor合并图片时总是报错,于是百度了一下后使用TiffToy软件成功将图片合并,有需要的朋友可以从文章前面的百度云链接直接下载。
2).生成mjchar.box文件
打开cmd, 切换到char_imgs目录下,执行tesseract命令:
tesseract mjchar.tif mjchar -psm 10 batch.nochop makebox
此时会在char_imgs目录下生成了一个mjchar.box文件。
3). 校正字符集
用 jTessBoxEditor打开生成的图片集 mjchar.tif ,注意 mjchar.tif 与对应的box文件一定要处于同一个文件夹下,然后就可以开始调整了(记得要翻页),调整完之后保存。
- 注1:这个软件容易点开关闭后再打开没反应,关机重启后才可以,原因未找到。
- 注2:在方框内修改完字符后需要先点击下方空白处,才算修改完,之后再点击翻页,修改其他字符,我第一次使用不知道,全部修改完才发现白修改了,又重新修改了一遍。

4).训练
这里完全参考python+tesseract 训练和破解验证码
一步步操作即可。
1.在char_imgs目录下新建一个名字为“font_properties”的文本文件,并且输入文本 normal 0 0 0 0 0,表示非斜体,粗体的一般字体。
2.执行 tesseract mjchar.tif mjchar nobatch box.train 进行测试训练。
3.执行 unicharset_extractor mjchar.box, char_imgs目录下生成一个名为unicharset的文件。
4.执行 shapeclustering -F font_properties.txt -U unicharset mjchar.tr, char_imgs目录下生成一个名为mjchar.tr的文件
5.执行 mftraining -F font_properties.txt -U unicharset -O unicharset mjchar.tr
6.执行 cntraining mjchar.tr
7.重命名生成的文件

8.执行 combine_tessdata normal, 合并五个文件,此时目录下的normal.traineddata 就是训练好的字库文件。
9.把normal.traineddata 复制到Tesseract-OCRt程序目录下的“tessdata”目录
至此本次需要识别的验证码已经训练完毕,接下就是实际验证了。
四、实际应用
1.定义一个函数,根据输入图片路径,输出识别出的验证码
def read_text(text_path):
"""
传入文本(jpg、png)的绝对路径,读取文本
:param text_path:
:return: 文本内容
"""
# 指定路径,路径为安装的OCR对应的目录
im = Image.open(text_path) # 直接读取bytes数据,生成图片对象
width, height = im.size
# 获取图片中的颜色,返回列表[(counts, color)...]
color_info = im.getcolors(width * height)
sort_color = sorted(color_info, key=lambda x: x[0], reverse=True)
# 将背景全部改为白色, 提取出字,每张图片一个字
char_dict = {}
for i in range(1, 6):
start_x = 0
im2 = Image.new('RGB', im.size, (255, 255, 255))
for x in range(im.size[0]):
for y in range(im.size[1]):
if im.getpixel((x, y)) == sort_color[i][1]:
im2.putpixel((x, y), (0, 0, 0))
if not start_x:
start_x = x # 标记每个字符的起始位置,用于最后字符串的排序
else:
im2.putpixel((x, y), (255, 255, 255))
char = pytesseract.image_to_string(im2, lang='gy', config='--psm 10')
char_dict[start_x] = char
code = ''.join([item[1] for item in sorted(char_dict.items(), key=lambda i: i[0])])
return code

注:此处为训练好的字体
2.将验证码截图传入路径
def v_code_input(self): # 识别验证码并输入
img = self.driver.find_element_by_xpath('//*[@id="vercode"]') # 获取验证码
v_code = read_text(BytesIO(img.screenshot_as_png)) # 识别验证码
verCode = self.driver.find_element_by_id('captcha')
verCode.send_keys(v_code)
self.driver.find_element_by_xpath('//*[@id="subButton"]').click()
time.sleep(3)
try:
print("验证码识别错误,重新输入")
self.v_code_input()
except NoSuchElementException:
print("验证码识别通过,等待开始外呼数据查询")
pass
注:这里为了判别验证码是否正确,模拟点击登录,如果识别成功,则页面会跳转,登录按钮会消失,此时再点击会报错,如果报错即可认为识别成功

3.结果
def login_gy(self, url, user, pwd): # 登陆高阳系统
self.driver = webdriver.Chrome()
time.sleep(5)
self.driver.get(url)
time.sleep(3)
username = self.driver.find_element_by_id('agentNumber')
username.send_keys(user) # 输入用户名
time.sleep(1)
password = self.driver.find_element_by_id('agentPwd')
password.send_keys(pwd) # 输入密码
time.sleep(1)
self.v_code_input() # 输入验证码
time.sleep(10)


总结
虽然过程很曲折,但好在坚持了下来,也学到了不少,最后的结果还是挺有成就感的,在此,非常感谢大佬的详细分享,才得以让我少走很多弯路,非常感谢,也希望能给看到我这篇文章的人提供一点点帮助。