随机森林进阶 以python_sklearn为工具
随机森林进阶 以python_sklearn为工具
文章目录
- 1. 获取数据
- 2. 数据可视化
- 3. 提取新特征 + 可视化
- 4. 构建虚拟变量
- 5. 分割数据
- 6. 训练模型并逐步优化
-
- 6.1 选择部分特征
- 6.2 选择全部特征
- 6.3 筛选重要特征
- 7.时间效率比较
- 8. 进一步优化参数
python 随机森林进阶案例,从获取数据开始,讲一个完整的故事。
(博主使用的开发工具是jupyter notebook,如果您使用的是其他开发工具,个别地方可能需要略有改动。)
1. 获取数据
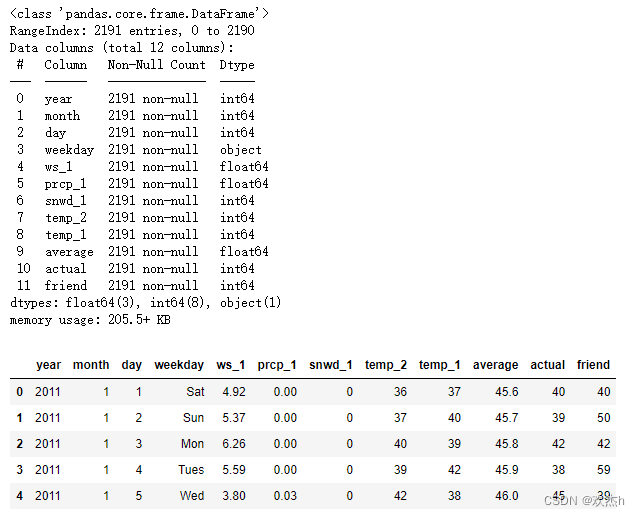
首先导包,获取数据,并查看数据详情。
import pandas as pd
# 读取数据
df = pd.read_csv("data.csv")
df.info()
df.head()
2. 数据可视化
# 构造x轴:日期
dates = pd.PeriodIndex(year=df["year"],month=df["month"],day=df["day"],freq="D") # 注意:PeriodIndex类型不能直接画图
dates = dates.to_timestamp() # 所以,需转为DatetimeIndex
dates
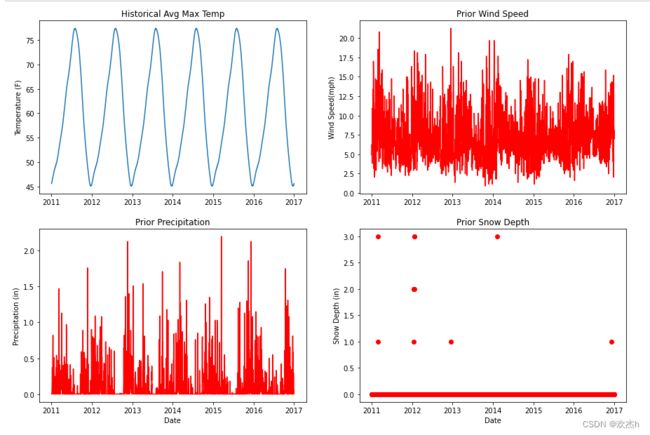
# 可视化
from matplotlib import pyplot as plt
fig,ax = plt.subplots(2,2,figsize=(15,10))
# 平均最高气温
ax[0,0].plot(dates,df["average"])
ax[0,0].set_xlabel("")
ax[0,0].set_ylabel("Temperature (F)")
ax[0,0].set_title("Historical Avg Max Temp")
# 风速
ax[0,1].plot(dates,df["ws_1"],"r-")
ax[0,1].set_xlabel("")
ax[0,1].set_ylabel("Wind Speed(mph)")
ax[0,1].set_title("Prior Wind Speed")
# 降水
ax[1,0].plot(dates,df["prcp_1"],"r-")
ax[1,0].set_xlabel("Date")
ax[1,0].set_ylabel("Precipitation (in)")
ax[1,0].set_title("Prior Precipitation")
ax[1,1].plot(dates,df["snwd_1"],"ro")
ax[1,1].set_xlabel("Date")
ax[1,1].set_ylabel("Show Depth (in)")
ax[1,1].set_title("Prior Snow Depth")
plt.show()
输出图像如下图所示:
3. 提取新特征 + 可视化
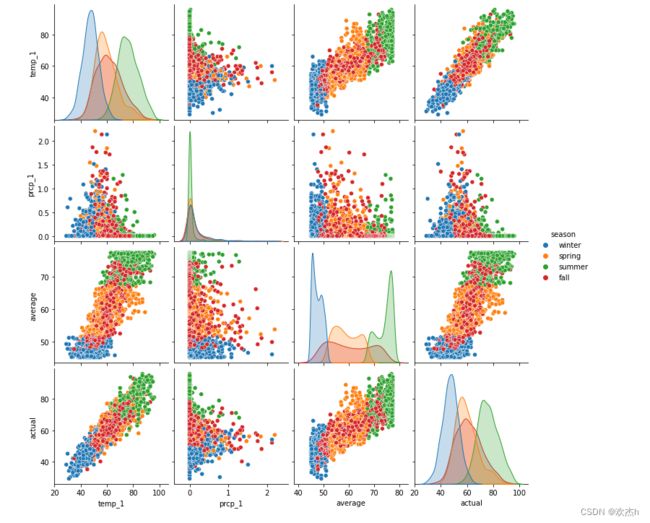
从现有数据中,提取出新特征:季度。并进一步进行可视化展示其他四个特征两两之间的关系,以其其他四个特征与季度的关系。
# 构建季度特征
seasons = []
# 输出所有月份
for month in df["month"]:
# print(month)
# 判断month在哪个区间
if month in [12,1,2]:
seasons.append('winter')
elif month in [3,4,5]:
seasons.append('spring')
elif month in [6,7,8]:
seasons.append('summer')
elif month in [9,10,11]:
seasons.append('fall')
# 构建特征
reduced_features = df.loc[:,['temp_1','prcp_1','average','actual']]
reduced_features['season'] = seasons
reduced_features

__
import seaborn as sns
sns.pairplot(reduced_features,hue='season',diag_kind='kde')
plt.show()
4. 构建虚拟变量
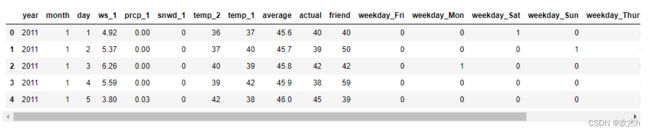
然后,将特征中的字符串类型的数据,构建成为虚拟变量。
more_df_2 = pd.get_dummies(df)
more_df_2.head(5)
5. 分割数据
在正式开始训练之前,还需要先对数据进行分割。
import numpy as np
# 标签-->ndarray
labels = np.array(more_df_2["actual"])
# 在特征中去掉标签列
df_features = more_df_2.drop("actual",axis=1)
# 获取特征名称列表
feature_name_list = list(df_features.columns)
from sklearn.model_selection import train_test_split
# 训练特征值 测试特征值 训练目标值 测试目标值
train_features,test_features,train_labels,test_labels = train_test_split(df_features,labels,test_size=0.25,random_state=42)
print("训练集特征:",train_features.shape)
print("训练集目标:",train_labels.shape)
print("测试集特征:",test_features.shape)
print("测试集目标:",test_labels.shape)

6. 训练模型并逐步优化
6.1 选择部分特征
只选择temp1和average特征,训练模型代码如下:
# 导入算法
from sklearn.ensemble import RandomForestRegressor
# 训练随机森林模型,为1000棵树
rf_most_important = RandomForestRegressor(n_estimators=1000,random_state=42)
# 拿到 temp_1 与 average 特征
important_train_features = train_features.loc[:,["temp_1","average"]]
important_test_features = test_features.loc[:,["temp_1","average"]]
# 重新训练模型:训练集的特征,训练集的目标
rf_most_important.fit(important_train_features,train_labels)
# 预测结果:测试集特征
predictions = rf_most_important.predict(important_test_features)
# 使用mape评估结果
errors = abs(predictions - test_labels)
mape = np.mean(100 * (errors / test_labels))
print('mape:', mape)
错误率输出如下:
mape: 6.923808151443066
6.2 选择全部特征
若选择全部特征:
from sklearn.ensemble import RandomForestRegressor
# 建立模型
rf_exp = RandomForestRegressor(n_estimators=1000,random_state=42)
# 训练模型
rf_exp.fit(train_features,train_labels)
# 进行预测
predictions = rf_exp.predict(test_features)
# 评估
# 预测值-真实值
errors = abs(predictions - test_labels)
# 使用mape评估结果
mape = np.mean(100 * errors / test_labels)
print('mape:', mape)
可以看到训练出模型的错误率有所下降:
mape: 6.256602487487005
6.3 筛选重要特征
# 提取特征的重要性,返回一个数组
importances = rf_exp.feature_importances_.tolist()
# 但是需要保留两位小数,则需使用列表推导式
feature_importances = [(feature,round(importance,2)) for feature,importance in zip(feature_name_list,importances)]
# 特征重要性降序排列,参数1:需进行排序的列表,参数2:指定排序键(按照谁来排序)
feature_importances = sorted(feature_importances,key=lambda x:x[1],reverse=True)
feature_importances
# 打印输出
print(["特征:{:20} 特征重要性:{}".format(feature_importance[0],feature_importance[1]) for feature_importance in feature_importances])

# 获取特征值
sorted_importances = [importance[1] for importance in feature_importances]
# 获取重要性
sorted_features = [importance[0] for importance in feature_importances]
# 累计重要性
cumulative_importances = np.cumsum(sorted_importances)
# 绘制折线图
plt.plot(sorted_features,cumulative_importances,"g-")
# 绘制红色水平虚线: y=0.95
plt.hlines(y=0.95,xmin=0,xmax=len(sorted_importances),color="r",linestyles="dashed")
plt.xticks(rotation=90)
# Y轴和名字
plt.xlabel("features")
plt.xlabel("cumulative importance")
plt.title("cumulative importance")
plt.grid()
plt.show()
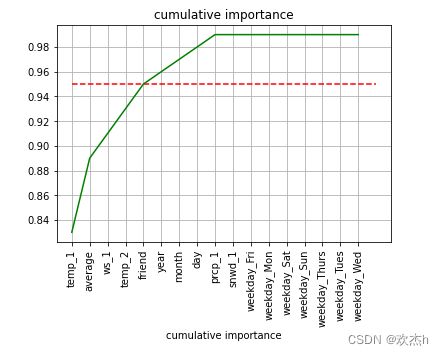
使用重要性排前五的特征进行训练,
# 训练随机森林模型,为1000棵树
rf_most_important = RandomForestRegressor(n_estimators=1000,random_state=42)
# 获取该5个特征的训练数据集
names = ["temp_1","average","ws_1","temp_2","friend"]
important_train_features = train_features.loc[:,names]
important_test_features = test_features.loc[:,names]
# 输出数据形状
print("重要特征训练集形状:",important_train_features.shape)
print("重要特征测试集形状:",important_test_features.shape)
# 重新训练模型:训练集的特征,训练集的目标
rf_most_important.fit(important_train_features,train_labels)
# 预测结果:测试集特征
predictions = rf_most_important.predict(important_test_features)
# 使用mape评估结果
errors = abs(predictions - test_labels)
mape = np.mean(100 * (errors / test_labels))
print('mape:', mape)
输出结果如下:
重要特征训练集形状: (1643, 5)
重要特征测试集形状: (548, 5)
mape: 6.548844579568184
错误率又有所上升,看来还不是最优的。
7.时间效率比较
开发算法的过程中,时间效率往往也是需要纳入考虑的。通过以下代码可以实现对时间效率比较。
在使用所有特征的情况下:
import time
all_features_time = []
# 计算一次可能不太准确,所以计算10次取平均
for i in range(10):
# 记录初始时间
start_time = time.time()
# 训练模型
rf_exp.fit(train_features,train_labels)
# 进行预测
predictions = rf_exp.predict(test_features)
# 记录结束时间
end_time = time.time()
all_features_time.append(end_time - start_time)
all_features_time = np.mean(all_features_time)
print("使用所有特征时建模与测试的平均时间消耗:",round(all_features_time),'秒')
使用所有特征时建模与测试的平均时间消耗: 7 秒
使用部分特征,以只使用重要特征为例:
import time
all_features_time = []
# 计算一次可能不太准确,所以计算10次取平均
for i in range(10):
# 记录初始时间
start_time = time.time()
# 只使用重要特征
rf_most_important.fit(important_train_features,train_labels)
# 预测结果:测试集特征
predictions = rf_most_important.predict(important_test_features)
# 记录结束时间
end_time = time.time()
all_features_time.append(end_time - start_time)
all_features_time = np.mean(all_features_time)
print("使用部分特征时建模与测试的平均时间消耗:",round(all_features_time),'秒')
使用部分特征时建模与测试的平均时间消耗: 5 秒
8. 进一步优化参数
为了进一步选出最佳参数,可以以列表或一维数组的形式将每个参数准备多个,匹配为字典后传入RandomizedSearchCV接口。以选出最佳参数。
from sklearn.model_selection import RandomizedSearchCV
# 决策树的个数可以是 [100,200,300, ...,1000]
n_estimator = np.arange(100,1100,100).tolist()
# 决策树的深度可以是 [1,2,...,10]
max_depth = np.arange(1,11).tolist()
# 每个叶子节点的最小的样本数可以是[2,4,8]
min_samples_leaf = [2,4,8]
# 以key:value键值对的形式存储为字典
random_grid = {
"n_estimators":n_estimator,
"max_depth":max_depth,
"min_samples_leaf":min_samples_leaf
}
# 创建决策树回归模型
rf = RandomForestRegressor()
# 指定随机参数
rf_Random = RandomizedSearchCV(estimator=rf,param_distributions=random_grid,n_iter=10)
# 训练模型
rf_Random.fit(train_features,train_labels)
print(rf_Random.best_params_)
# 预测结果:测试集特征
predictions = rf_Random.predict(test_features)
# 使用mape评估结果
errors = abs(predictions - test_labels)
mape = np.mean(100 * (errors / test_labels))
print('mape:', mape)
输出结果如下:
mape: 6.156625778253245
模型的错误率再一次降低了。
当然,这并不意味着这就是最好的,如果继续测试其他随机参数,错误率还可能会更低。