机器学习工具篇_sklearn_决策树



课程是全面讲解sklearn包官网的应用
2.决策树
Q:决策树是什么?

非参数的有监督的学习方法。
主要用于解决分类和回归问题
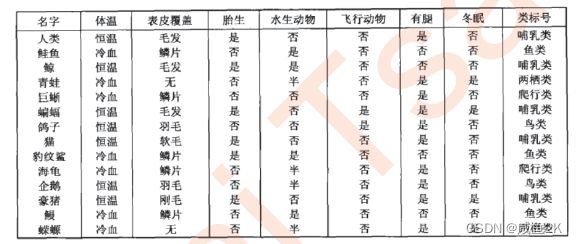
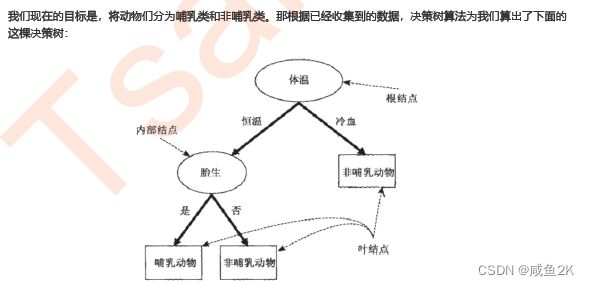
把包含特征的列表,转成树状图的方式
Q:特别概念

进边与出边的区别是,箭头指哪里
叶子节点是最末端,中间节点是中间。
Q:使用决策树需要解决的两个问题

根据数据表画出最好的树,同时控制树的高度
Q:sklearn.tree模块中,有哪些类型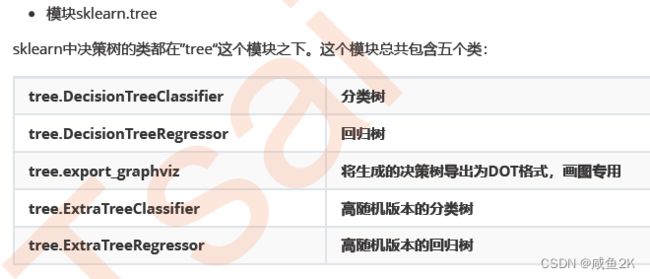
常用的:
分类树:tree.DecisionTreeClassifier
回归树:tree.DecisionTreeRegressor
画图用途:tree.export_graphviz
Q:sklearn的基本建模流程
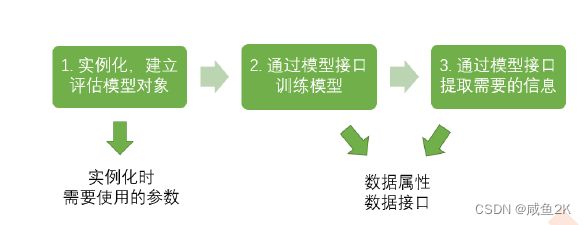
Q:决策树的建模使用具体的语句
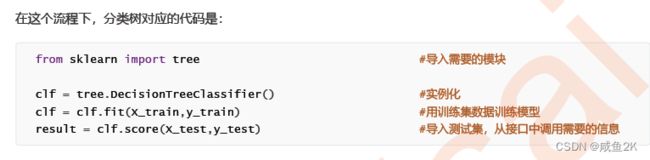
2.1重要参数
2.1.1criterion标准
Q:criterion的类型?

决策树中每一个节点都有不纯度。由上往下,不纯度越低,叶子节点是最低的
criterion参数有两类:entrophy信息熵和gini基尼系数
Q:entropy信息熵和gini基尼系数的两种不同数学算法
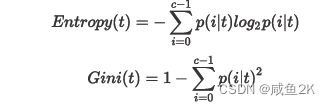
Q:数学公式代表的不同含义
信息熵,来源于信息论的基本概念
信息越是不确定,信息熵越大。信息熵越低,信息越是有序
此处的criterion中的信息熵,是指计算信息熵的增益,也就是父节点到子节点信息熵的减少程度
Q:两种标准的区别

(1) 信息熵对不纯度更敏感,会有更强的惩罚措施,也就是说信息熵标准会分得更细,适用于维度数据不多,噪音低的,需要更精细的情况,适用于拟合程度不足的情况,缺点是容易会过拟合;
而基尼系数相较信息熵,过拟合程度较少。
(2)另外 ,由于信息熵涉及对数,计算时会慢一些
(3)在实际使用中,应当两个都试试
Q:criterion概括总结

Q:决策树的基本流程简单概括
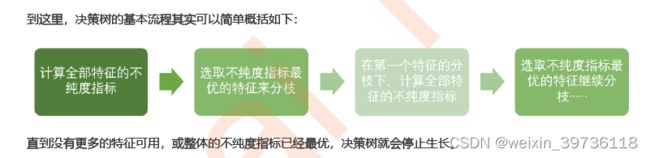
先计算不纯度指标
再选取最优的特征
再再计算最优特征下的不纯度指标
再再选取此情况下的最优特征
2.1.2random_state和splitter
Q:random_state的作用
作为一个参数,可以固定一个值。通过固定这个值,达到结果复现的目的,不用每运行一次,结果都不一样
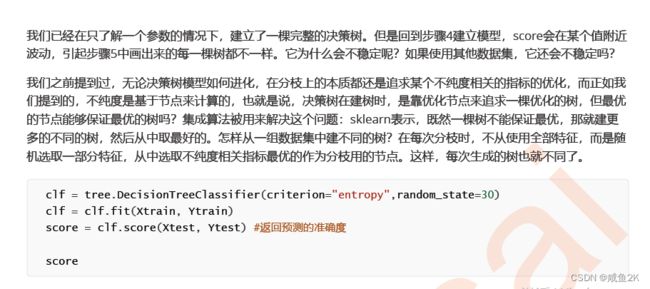
当然,对于固定的值,可以作为超参数进行调参
random_state用来设置分枝中的随机模
Q:splitter的作用?
默认为"best";按更重要的特征进行分枝
当等于"random"时,按随机进行分枝,可以降低过拟合

Q:如何选择模型?
通过超参数的方式,选择准确率最高的模型
2.1.3剪枝参数
Q:为什么会过拟合?
模型训练根据的是训练集。如果对训练集完全拟合,也就是包括噪音也全部拟合在模型中。进而导致真实中一些重要的信息不能通过模型展示出来。
Q:过拟合的表现
用score=clf.score(Xtrain,Ytrain)打分,和score=clf.score(Xtest,Ytest)打分,前者的打分非常好,接近1,而后者才0.8,这种情况就是过拟合
Q:决策树中的核心关键是什么?
为避免决策树的过拟合,剪枝策略是sklearn的核心
Q:max_depth的参数的作用
这个参数用于限制树的最大尝试,如果超过这个深度,则全部剪掉
由于树的尝试多一层,对样本的需求量会增加一倍,这个参数可以有效防止过拟合。
可以用于低样本量而维度较高的情况。
一般从max_depth=3开始。

Q:min_samples_leafs的作用
每一个节点都必须包含至少min_samples_leafs设定的样本(samples)数量。如果小于这个规定的样本数量,则这个分枝不会发生;或者会朝着这个min_samples_leafs能发生的方向去。
Q:min_samples_leaf的使用环境
搭配max_depth使用
如果太小会过拟合,太大就是阻止模型学习数据。
一般从5开始。
如果样本量变化很大,可以录入浮点数作为样本量的百分比使用。
对于类别不多的分类,1是最佳选择。

Q:min_samples_split的用途
min_samples_split设定后,中间节点必须包含设定的训练样本数量,才可以被分票,否则这个分枝就不会发生。

Q :min_samples_leaf与min_samples_split的区别
前者是设定最小的叶子,后者是设定最小样本的中间节点。
Q:max_features的作用
限制特征的个数(比较max_depth限制层数)
Q:min_impurity_decrease
限制信息熵增益的大小,小于设定数值的分枝不会发生。
Q:参数如此之多,怎么选择最优的组合呢?
也不一定是设置了参数才是最好的

Q:什么是属性
属性是各种训练好的模型的性质。
最重要的是feature_importance_,能够查看各个特征对模型的重要性
clf.feature_importances_
Q:什么是接口
能返回一定数值的函数
Q:决策树的重要接口
fit:返回模型
clf.fit(Xtrain,Ytrain)score:返回模型的分数
score=clf.score(Xtest,Ytest)
scoreapply:返回每个测试样本所在的叶子节点索引
clf.apply(Xtest)predict:返回每个测试样本的标签(或者是预测结果)
clf.predict(Xtest)Q:决策树(DecisionTreeClassifier)和(export_graphviz)总结

3.DecisionTreeRegressor
没有class_weight参数,因为回归没有标签均衡的问题
Q:关于回归的衡量指标。回归树的score默认返回的是R平方
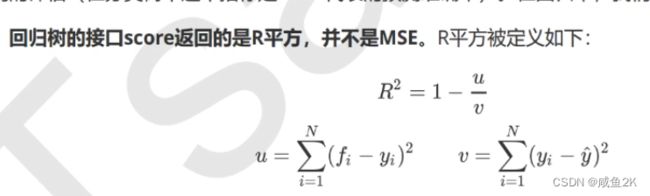
u为残差平方和,v为总平方和。如果残差平方和大于总平方和,则R平方为负数,表示模型很差。但一般来说,R平方这个衡量指标一般不用,而特定指定用MSE

MSE为均方误差
均方差是正数,但在sklearn中作为模型的损失,体现为负数 。
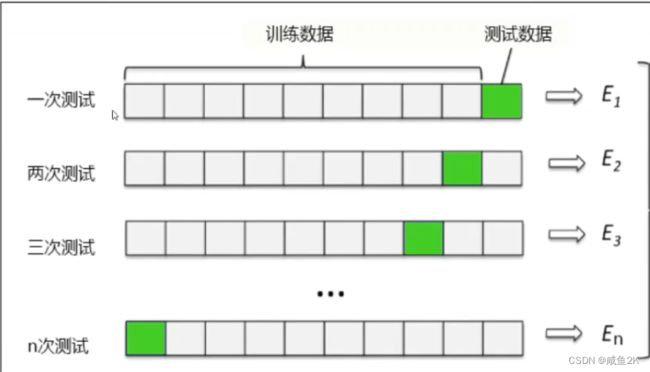
Q:交叉验证
验证模型稳定性的方法
Q:交叉验证的方法
依次将模型分为n份,依次将其中一份作为测试集,其他作为训练集,通过多次计算模型的精确性来评估模型的平均准确程度。
用交叉验证n次的结果求出平均值,对模型效果进行更好的度量

 对n个求平均
对n个求平均
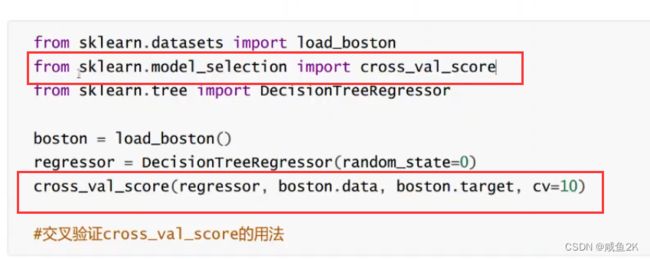
Q:如何评估?
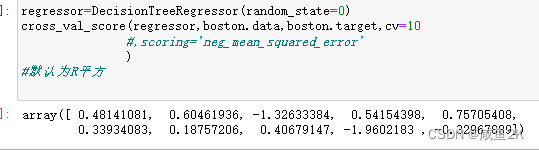

默认为R平方,越接近1越好
负均方差:scoring='neg_mean_squared_error' 越接近于0越好
Q:在正弦曲线中加入噪声的情况下,对决策树的max_depth深度进行分析
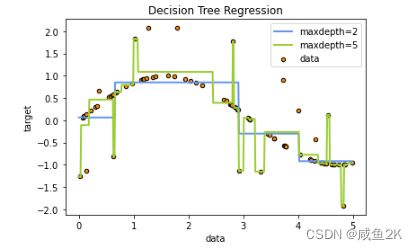
深度越深并不意味着拟合越好,因为把噪音也进行了拟合。出现了过拟合的情况。
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
data=pd.read_csv(r"F:\学习文件\拜师数据分析学习\24630_机器学习-Sklearn(第三版)\【机器学习】菜菜的sklearn课堂(1-12全课)\01 决策树课件数据源码\data.csv")
data.info()
#查看数据集的方法一
#发现有890个记录,Age,Cabin有较多缺失值
#有些字段不是数值形式,需要转化
data.head()
#删除掉缺失太多,或者是关系不大的字段,用drop()属性
#axis=1是指对列进行操作。默认为axis=0是对行操作。
#inplace=False是默认,就是不删除后不替换原数据集,删除后要赋值才行
#data1=data.drop(['Name','Ticket','Cabin'],axis=1,inplace=False)
#inplace=True是直接替换,前面不用再赋值
data.drop(['Name','Ticket','Cabin'],axis=1,inplace=True)
data
data.info()
#对缺失值越多的列进行填充,因为数据量不大,需要对数据进行训练
data['Age']=data['Age'].fillna(data['Age'].mean())
#对于空的值不多的情况,可以删除掉
#对于这种操作,默认也是不替换,要通过赋值的方式
data=data.dropna()
data.info()
labels=data['Embarked'].unique().tolist()#uniqu()作用是取到唯一值,并以一个一维数组的形势展示。
#tolist()作用是将一维数组转化为列表的形式
labels
#把分类型的变量,转化成数值————方法一
#这一步的作用是将某一列的值,换成相应的值 ,这个值以序号的值表示。
#apply()意思是使用括号内的函数,一般里面跟着lambda
#lambda函数的作用是把相应的值进行一定的函数转换,变成新的值
data['Embarked']=data['Embarked'].apply(lambda x:labels.index(x))
int(False)
#将性别类型转化为数值型的另外一种方法————方法二
#判断是否为男性,出来的值是布尔型
data['Sex']=(data['Sex']=='male')
#将布尔型转化成整数型
#使用astype()方法
data['Sex']=data['Sex'].astype('int')
#可以和上一步合并
#上两步出现红框,系统提示用loc,或者iloc
#区别在于可否用序列号来代替
# data.loc[:,'Sex']=(data['Sex']=='male').astype('int')
# data.iloc[:,3]=(data['Sex']=='male').astype('int')
data.head()#查看前五个数据,发现已经按需要都转成 了数值型
#数据预处理结束
#因为模型要区分训练集和测试集,而当前Survied这一列在表中,所以要区分开来
x=data.iloc[:,data.columns!='Survived' ]#用iloc()选取所有的行,用:表示。用布尔判断来选取其他的列
#此处用loc和iloc是一样的
#如果为多个,在np中则要写为!=('Survived' or 'Sex')
#同理,用iloc选择取y
y=data.loc[:,data.columns=='Survived' ]
from sklearn.model_selection import train_test_split#从sklearn.model_selection 中导入训练测试集模块的划分子模块
Xtrain,Xtest,Ytrain,Ytest=train_test_split(x,y,test_size=0.3)
#
Xtrain.shape#用shape属性,可以看到Xtrain的形状,此处为622行,从0-621,8列
Xtrain.shape[0]#选0时,可以得到行数
Xtrain.index#Xtrain的索引是错的,虽然当前不影响,但不知道后续会不会用上顺序的索引,所以有必要把索引按顺利重新填列
range(Xtrain.shape[0])#range()是一个范围的函数,此处可以把循环联系起来
#这四个数据集都需要重新排列,所以此处用循环将这四个数据集一次性的索引重新排列
for i in Xtrain,Ytrain,Xtest,Ytest:
i.index=range(i.shape[0])
Xtest
clf=DecisionTreeClassifier(random_state=25)#ranom_state的数值可以自己随意读
#实例化之后,生成一个空的,但有参数的实例
#通过下面的fit,训练出这个模型
clf=clf.fit(Xtrain,Ytrain)
#给模型打分
score=clf.score(Xtest,Ytest)
score
#发现上述模型的分数比较低,现在来试用交叉验证的方式进行
from sklearn.model_selection import cross_val_score#从模型选择模块中引入交叉验证
clf=DecisionTreeClassifier(random_state=25)#ranom_state的数值可以自己随意读
score=cross_val_score(clf,x,y,cv=10).mean()
score
#结果发现通过交叉验证,这个模型分数还是不高
#所以下一步为进行调参。
#考察不同的层级对模型拟合的影响
tr=[]#建立一个空列表,用来存储不同max_depth的训练集拟合分数
te=[]#建立一个空列表,存储特定不同的max_depth下,交叉验证的平均分数
for i in range(10):#在10个数以内进行循环,从0开始
clf=DecisionTreeClassifier(random_state=25,#实例化clf
max_depth=i+1) #i从0开始,每次循环自加1
clf=clf.fit(Xtrain,Ytrain) #训练clf
score_tr=clf.score(Xtrain,Ytrain)#对clf的模型在不同的max_depth下打分
score_te=cross_val_score(clf,x,y,cv=10).mean()#对clf模型的不同max_depth下,交叉验证取平均数
tr.append(score_tr)#得到结果后,把每个结果加在最后
te.append(score_te)
print(max(te))#print()是函数,取列表中的最大值.
plt.plot(range(1,11),tr,color='red',label='train')
plt.plot(range(1,11),te,color='blue',label='test')
plt.xticks(range(1,11))
plt.show()
#由上图发现,随着max_depth的增加,模型趋近过拟合
#而交叉验证的分数并不高
##这里为什么使用“entropy”?因为我们注意到,在最大深度=3的时候,模型拟合不足,在训练集和测试集上的表现接
#近,但却都不是非常理想,只能够达到83%左右,所以我们要使用entropy。
#说明,应该增加参数
#增加一个参数的影响
tr=[]#建立一个空列表,用来存储不同max_depth的训练集拟合分数
te=[]#建立一个空列表,存储特定不同的max_depth下,交叉验证的平均分数
for i in range(10):#在10个数以内进行循环,从0开始
clf=DecisionTreeClassifier(random_state=25 #实例化clf
,max_depth=i+1
,criterion='entropy'
)
clf=clf.fit(Xtrain,Ytrain) #训练clf
score_tr=clf.score(Xtrain,Ytrain)#对clf的模型在不同的max_depth下打分
score_te=cross_val_score(clf,x,y,cv=10).mean()#对clf模型的不同max_depth下,交叉验证取平均数
tr.append(score_tr)#得到结果后,把每个结果加在最后
te.append(score_te)
print(max(te))#print()是函数,取列表中的最大值.
plt.plot(range(1,11),tr,color='red',label='train')
plt.plot(range(1,11),te,color='blue',label='test')
plt.xticks(range(1,11))
plt.show()
#继续调参
#使用网格搜索的方式
#网格搜索的方式是同时调整多种参数的方式,是一种枚举的方法.
np.linspace(0,0.5,50)#linspace()是numpy的一个函数.作用是从第一个参数,到第二个参数之间,由小到大生成第三个参数数量的数字
#以此对应的是
np.arange(0,0.5,0.01)#作用是从第一个参数,到第二个参数之间,由小到大生成按第三个参数的步长,生成相应数量的数字
gini_threholds=np.linspace(0,0.5,50)#gini系数的范围,从0~0.5,由小到大,生成50个进入网格
#也就是说这个gini系数的边界是一个常用的值
#如果entropy,则是如下
#entropy_threholds=np.linspace(0,1,50)
#参数是一个字典
parameters={'criterion':('gini','entropy')
,'splitter':('best','random')
,'max_depth':[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
,'min_impurity_decrease':[*np.linspace(0,0.5,50)]
}
clf=DecisionTreeClassifier(random_state=25)
GS=GridSearchCV(clf,parameters,cv=10)
GS=GS.fit(Xtrain,Ytrain)
GS.best_params_#风格搜索中表现最好的参数组合
GS.best_score_#表现最好的组合下最高得分
#网格搜索出来的数,不一定有我们自己调出来的参数分值高
#原因是网格搜索会将列出的所有参数都参与计算,而不是其中一两个好了之后就不用考虑其他的参数
#风格搜索需要技巧
#结论:1.如果跑太慢,可以适当减少参数
#2.对于Titanic生存模型,决策树的分数极少会高于85%.
# 决策树模型对这个案例也许适用性不如后面随机森林等高