【ML】欠拟合(underfitting)和 过拟合(overfitting)实践(基于sklearn)
【ML】欠拟合(underfitting)和 过拟合(overfitting)实践(基于sklearn)
- 数据集
- 加载数据
- 可视化数据
- 一阶模型(欠拟合)
-
- 训练
- 预测+评估
- 可视化
- 二级模型(符合要求)
- 五阶模型(过拟合)
数据集
训练集:https://www.kaggle.com/datasets/yuanheqiuye/t-r-train
测试集:https://www.kaggle.com/datasets/yuanheqiuye/t-r-test
加载数据
# 加载数据
import numpy as np
import pandas as pd
data_train = pd.read_csv('/kaggle/input/t-r-train/T-R-train.csv')
data_test = pd.read_csv('/kaggle/input/t-r-test/T-R-test.csv')
可视化数据
# 可视化
X_train = data_train.loc[:,'T']
# 注意这里模型fit方法要求必须是ndarray
X_train = np.array(X_train).reshape(-1,1)
y_train = data_train.loc[:,'rate']
X_test = data_test.loc[:,'T']
# 注意这里模型fit方法要求必须是ndarray
X_test = np.array(X_test).reshape(-1,1)
y_test = data_test.loc[:,'rate']
from matplotlib import pyplot as plt
plt.scatter(X_train,y_train)
plt.show()

一阶模型(欠拟合)
训练
# 训练一阶(欠拟合)
from sklearn.linear_model import LinearRegression
model1 = LinearRegression()
model1.fit(X_train,y_train)
预测+评估
y_train_predict = model1.predict(X_train)
y_test_predict = model1.predict(X_test)
print(y_test_predict.shape)
from sklearn.metrics import r2_score
r2_train = r2_score(y_train, y_train_predict)
r2_test = r2_score(y_test, y_test_predict)
print('r2_train=', r2_train, 'r2_test=', r2_test)
输出:r2_train= 0.016665703886981964 r2_test= -0.758336343735132
r2_score结果远小于1,可知结果很差。
可视化
# 绘图
fig2 = plt.figure()
plt.scatter(X_train,y_train)
plt.scatter(X_test,y_test)
X_range = np.arange(40,90).reshape(-1,1)
y_range_predict = model1.predict(X_range)
plt.plot(X_range,y_range_predict)
plt.show()
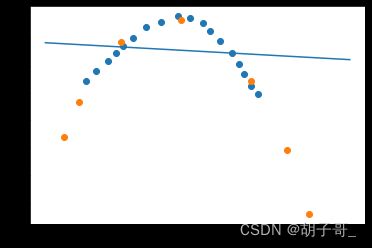
可视化结果跟点的拟合程度非常差。
二级模型(符合要求)
# 训练二阶
# 数据准备
from sklearn.preprocessing import PolynomialFeatures
poly1 = PolynomialFeatures(degree=2)
X_2_train = poly1.fit_transform(X_train)
X_2_test = poly1.transform(X_test)
print(X_2_train.shape, X_2_test.shape)
# 输出:(18, 3) (7, 3)
# 训练
model2 = LinearRegression()
model2.fit(X_2_train, y_train)
# 评分
y_2_train_predict = model2.predict(X_2_train)
y_2_test_predict = model2.predict(X_2_test)
from sklearn.metrics import r2_score
r2_2_train = r2_score(y_train, y_2_train_predict)
r2_2_test = r2_score(y_test, y_2_test_predict)
print('r2_2_train=', r2_2_train, 'r2_2_test=', r2_2_test)
# 输出:r2_2_train= 0.9700515400689422 r2_2_test= 0.9963954556468684
# 可视化
fig3 = plt.figure()
plt.scatter(X_train,y_train)
plt.scatter(X_test,y_test)
X_range = np.arange(40,90).reshape(-1,1)
X_2_range = poly1.transform(X_range)
y_2_range_predict = model2.predict(X_2_range)
plt.plot(X_range,y_2_range_predict)
plt.show()
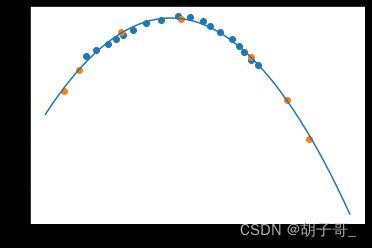
五阶模型(过拟合)
# 数据准备
from sklearn.preprocessing import PolynomialFeatures
poly1 = PolynomialFeatures(degree=5)
X_5_train = poly1.fit_transform(X_train)
X_5_test = poly1.transform(X_test)
print(X_5_train.shape, X_5_test.shape)
# 输出:(18, 3) (7, 3)
# 训练
model5 = LinearRegression()
model5.fit(X_5_train, y_train)
# 评分
y_5_train_predict = model5.predict(X_5_train)
y_5_test_predict = model5.predict(X_5_test)
from sklearn.metrics import r2_score
r2_5_train = r2_score(y_train, y_5_train_predict)
r2_5_test = r2_score(y_test, y_5_test_predict)
print('r2_5_train=', r2_5_train, 'r2_5_test=', r2_5_test)
# 输出:r2_5_train= 0.9978527267187657 r2_5_test= 0.5437837627381455
# 可视化
fig3 = plt.figure()
plt.scatter(X_train,y_train)
plt.scatter(X_test,y_test)
X_range = np.arange(40,90).reshape(-1,1)
X_5_range = poly1.transform(X_range)
y_5_range_predict = model5.predict(X_5_range)
plt.plot(X_range,y_5_range_predict)
plt.show()
输出:r2_5_train= 0.9978527267187657 r2_5_test= 0.5437837627381455

结合r2_score和上图可知,过拟合情况下,模型对训练数据的拟合程度非常好,但在测试数据集上的拟合程度很差。