RPN 模型简要介绍
概述
本文介绍了 Faster R-CNN 目标检测模型中提出的图像候选框提取模型—— RPN 模型,这是一种区域生成网络,结构简单嵌入方便,极大加快了目标检测模型的运行速度,使目标检测模型真正融合到同一个神经网络内,对之后影响深远。分别从国内外研究现状,模型具体原理,它的应用环境和对后续研究的影响多角 度的论述此模型,并展望了整个深度学习目标检测领域之后的发展趋势。
研究现状
RPN 在 Faster R-CNN 目标检测算法中首次被提出,用于替代了之前 R-CNN 算法中所使用的 selective search 算法。Faster R-CNN 总共由以下两个模块组成,第一个子模块用来产生区域推荐的 RPN,第二个子模块则是使用 ROI 推荐区 域的 Fast R-CNN 检测器。
之前生成检测框的方式有 opencv 级联分类器所用的 特征金字塔方式,以及 RCNN 所用的 selective search 方式。这些方式生成检测 框非常耗时,而且需要借助电脑的 cpu 完成相应的功能。
Faster R-CNN 直接的使用 RPN 生成检测候选框,很大限度的提升了检测框的生成速度。可以用于图像预处理,真正的把物体检测流程嵌入到一个神经网络 中,因此被广泛应用于之后的各种网络模型,并被进行一次又一次的改造。之后 的二阶段目标检测网络模型基本都包括了这种区域生成网络,诸如 yolo 此类的单阶段检测模型也将这种网络模型改造和嵌入到了自己不断更新的网络中。
RPN 原理
RPN 模型总述
RPN 的英文全称是 Region Proposal Network,是一个全卷积网络,可以同时预测目标的目标检测框和分数,端到端的训练生成高质量的 region proposals, 同时使 RPN与检测网络共用同一个卷积特征。其本质是基于滑窗的无类别物体检测器,输入任意尺度的图像,可输出一系列的矩形候选区域。以下是 RPN的网络结构图:

RPN 模型具体原理
RPN 需要先确定锚点(Anchors),生成多个锚框后,判断每个锚框是包含物体还是背景,进行物体二分类。在具体生成时,当发现锚框内包含识别物体时, 我们进行调整,令每个锚框与底值更加接近。每个滑动窗口位置预测了多个 region proposals,每个位置最大可能性的 proposal 数量定义为 k 个,回归层针对 k 个 boxes 的位置输出 4k 个值,分类层输出 2k 个 scores,用于评估每个 proposal 是否为目标物体的概率。其中 k 个 proposals 类似于 k 个 reference boxes,称之为 anchors;默认情况下,对于每个滑动位置,RPN 使用 3 个尺度 和 3 个长宽比,生成 9 (k=9) 个 anchors。假设一个卷积特征图的大小为 w * h, 那么这张卷积特征图上总共有 w * h * k 个 anchors。
Anchors 是具有平移不变和多尺度特性的。例如如果对图片中的物体进行平移,选取区域也应该进行平移。同时基于 anchor 的方法构建在 anchors 金字塔结构上,根据多尺度和多长宽比的锚框,可以对边界框进行分类和回归。
RPN 模型可以计算它的损失函数,更好的对模型进行训练:

其中, 是一个锚点在一个迷你批处理中的索引,
是一个锚点在一个迷你批处理中的索引, 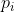 是锚点成为一个对象的预测概率。如果锚点为正,真实框标签为1,如果锚点为负,真实框标签为0。
是锚点成为一个对象的预测概率。如果锚点为正,真实框标签为1,如果锚点为负,真实框标签为0。 是表示预测边界框的 4 个参数化坐标的向量,与正锚点相关。
是表示预测边界框的 4 个参数化坐标的向量,与正锚点相关。
分类损失是两个类的日志损失,对于回归损失,我们使用

其中 是鲁棒损失函数,
是鲁棒损失函数, ![]() 表示回归损失仅在正锚点
表示回归损失仅在正锚点 ![]() 时被激活,否则则被禁用。
时被激活,否则则被禁用。
总体概括而言,RPN 包括以下部分:
• 生成anchor boxes;
• 判断每个anchor box为foreground(包含物体)或者background(背景),进行二分类;
• 边界框回归(bounding box regression) 对anchor box进行微调,使得positive anchor和真实框(Ground Truth Box)更加接近;
• 使每个锚点都有一个或两个值的向量(通常称为预测值),代表前景和背景。如果我们将预测值送入 softmax 或是 logistic 回归激活函数,它将预测标签;
• 计算 RPN 的损失函数,更好的对模型进行训练。
RPN 应用及影响
RPN 一开始由 Faster R-CNN 提出,这是一个对后续研究影响深远的深度学习目标检测网络。
除了 RPN 网络之外,Faster R-CNN 还融合了 VGG-16 这种卷积 神经网络模型作为图像的 backbone 层,提取出图片的 feature maps。并设置 Roi Pooling 层收集输入的 feature maps 和 proposals,综合这些信息后提取 proposal feature maps,送入后续全连接层判定目标类别。最后进行分类,利用 proposal feature maps 计算 proposal 的类别,对边界框(bounding box)进行二次回归,使目标检测准确率和速度都得到很大提升。
从此之后,深度学习可以不借助cpu进行图像预处理,将所有过程嵌入到同 一个神经网络中,实现了一站式的目标检测。虽然于现在而言这个模型的速度和 精度已经算不上最优,但在2016年刚问世之时它的影响是巨大的,之后的 CNN 网络普遍加入了 RPN 这一网络结构,用于加快运行速度。
RPN 结构原理简单,使用和结合到整个 Faster R-CNN 网络中也较为方便,起到了对图像预选框进行二分类并提取候选框的作用,设计巧妙而又优秀。 对于整个深度学习目标检测领域来说,虽然 RPN 模型只是目标检测模型中的 沧海一粟,但也推动了之后目标检测领域的发展。模型速度越来越快,精度也越来越高。发展至今,之前精度较低的 yolo 单阶段检测模型已经更新到了 yolov7, 官方给出的测试集 AP 达到了 51.4%,不仅结果比较准确,而且可以在 GPU 上训练出相应的权重后,将权重放入一些边缘计算平台中进行图片和视频,摄像头画面的推理,这是之前所不敢设想的。一次次的突破使目标检测领域落地更加便捷迅速,也更加具有工程上的可实践性。相信总有一天,深度学习目标检测领域的技术可以更加广泛的应用在我们生活中的方方面面,不经意间改变着我们的生活。