【OUC_SE_2022】第三周作业:卷积神经网络基础
本博客为OUC2022秋软件工程第三次作业
文章目录
-
- 本博客为OUC2022秋软件工程第三次作业
- 第三周作业:卷积神经网络基础
-
- 第18小组
- Part 1 视频学习
-
- 一、CNN的基本结构
-
- 1. 卷积 (CNN Layer)
- 2. 池化 (Pooling)
- 3. 全连接 (FC layer)
- 二、典型的网络结构
-
- 1. AlexNet
- 2. ZFNet
- 3. VGG
- 4. GoogleNet
- 5. ResNet
- Part 2 代码练习
-
- 一、MNIST 数据集分类
-
- 1. 加载数据 (MNIST)
- 2. 创建网络
- 3. 在小型全连接网络上训练(Fully-connected network)
- 4. 在卷积神经网络上训练
- 5. 打乱像素顺序再次在两个网络上训练与测试
- 二、CIFAR10 数据集分类
-
- 使用 CNN 对 CIFAR10 数据集进行分类
- 三、使用 VGG16 对 CIFAR10 分类
- Part 3 问题思考
第三周作业:卷积神经网络基础
第18小组
组长:罗浩宇
成员:罗浩宇
Part 1 视频学习
一、CNN的基本结构
1. 卷积 (CNN Layer)
一维卷积:常用于信号处理计算信号的延迟累计
二维卷积:常用于图像处理

2. 池化 (Pooling)
作用:
保留了主要特征的同时,减少参数和计算量,防止过拟合,提高模型的泛化能力。
一般处于卷积层与卷积层之间,全连接层和全连接层之间。
类型:最大值池化(Max pooling)、平均池化(Average pooling)。

3. 全连接 (FC layer)
两层之间所有神经元都有权重链接;
通常全连接层在卷积神经网络的尾部;
全连接层的参数量通常最大。
二、典型的网络结构
1. AlexNet
优化方法:
ReLU激活函数、DropOut(随机失活)、数据增强
优点:
解决了梯度消失的问题(正区间)
计算速度快
收敛速度远快于sigmoid
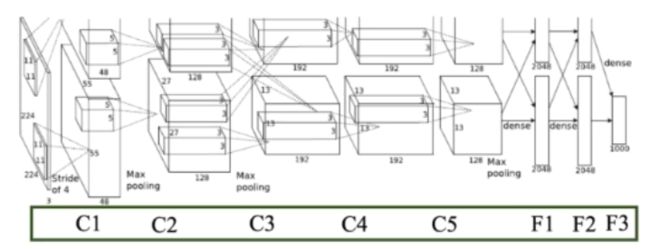
2. ZFNet
网络结构与AlexNet相同,将卷积层1中感受野大小由 11x11 改为 7x7, 步长由4改为2.
卷积层3,4,5的滤波器个数改为512,512,1024。
3. VGG
对网络深度进行了加深。
4. GoogleNet
Inception v2 对一些模型结构进行了改进。没有全连接层。参数量为Alexnet的 1/12 。
而 Inception v3 进一步对 v2d的参数量进行了降低。增加了非线性激活函数,使网络产生更多独立特,表征能力更强,训练更快。

5. ResNet
深度大大加深,有152层,结构是一个基本的VGG结构.
引入了残差学习网络(deep residual learning network),可以被用来训练非常深的网络,并解决了梯度消失的问题。

Part 2 代码练习
一、MNIST 数据集分类
colab_demo/05_01_ConvNet.ipynb at master · OUCTheoryGroup/colab_demo (github.com)
1. 加载数据 (MNIST)
PyTorch里包含了 MNIST, CIFAR10 等常用数据集,调用 torchvision.datasets 即可把这些数据由远程下载到本地。
显示数据集中的部分图像:

2. 创建网络
定义网络时,需要继承nn.Module,并实现它的forward方法,把网络中具有可学习参数的层放在构造函数 init 中。
利用autograd,在nn.Module的子类中定义forward函数,backward函数就会自动被实现。
然后,定义训练和测试函数。完成网络的创建。
(代码略)
3. 在小型全连接网络上训练(Fully-connected network)
在小型全连接网络上训练模型,输出训练过程和结果如下:
可以看到,平均loss在0.3796,从训练了70%左右开始趋于稳定,loss接近于在0.3000左右浮动,其准确度大约为89%。

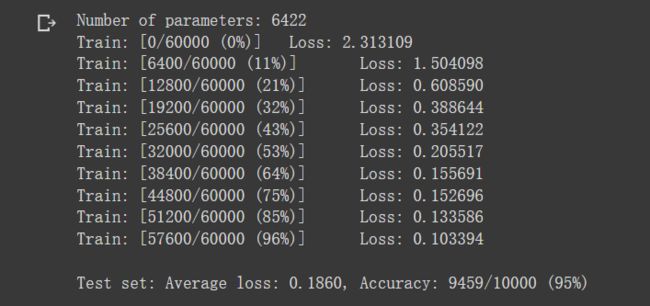
4. 在卷积神经网络上训练
使用相同数量的模型参数,在CNN上进行训练,输出训练过程和结果如下:
可以看到,平均loss在0.1860,从训练了65%左右开始趋于稳定,loss接近于在0.15~0.1左右浮动,其准确度大约为95%
训练结果表明,含有相同参数的 CNN 效果要明显优于 简单的全连接网络,CNN 能够使用卷积和池化来更好地挖掘图像中的信息。
- 卷积:Locality and stationarity in images
- 池化:Builds in some translation invariance
5. 打乱像素顺序再次在两个网络上训练与测试
由于 CNN 在卷积与池化上的优良特性,如果把图像中的像素打乱顺序,卷积和池化就难以发挥作用,所以尝试把图像中的像素打乱顺序,再进行训练测试。
首先随机打乱像素顺序,以下为打乱后的图像的形态:

对 data 加入打乱顺序操作,重新定义训练与测试函数, train_perm 和 test_perm,分别对应着加入像素打乱顺序的训练函数与测试函数。
然后分别在全连接网络、卷积神经网络上训练与测试。
全连接网络测试结果:
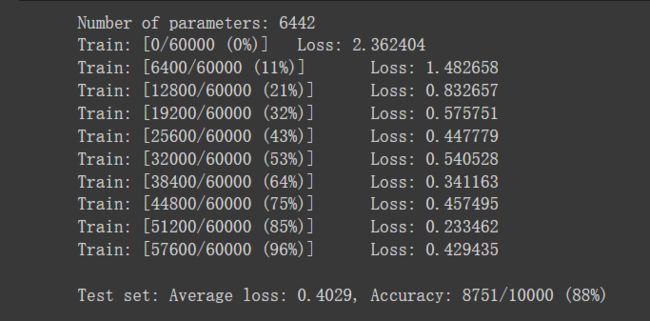
卷积神经网络测试结果:

从打乱像素顺序的实验结果来看,全连接网络的性能基本上没有发生变化,但是CNN的性能明显下降。
这是因为对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
二、CIFAR10 数据集分类
colab_demo/05_02_CNN_CIFAR10.ipynb at master · OUCTheoryGroup/colab_demo (github.com)
使用 CNN 对 CIFAR10 数据集进行分类
对于视觉数据,PyTorch 创建了一个叫做 totchvision 的包,该包含有支持加载类似Imagenet,CIFAR10,MNIST 等公共数据集的数据加载模块 torchvision.datasets 和支持加载图像数据数据转换模块 torch.utils.data.DataLoader。
下面将使用CIFAR10数据集,它包含十个类别:‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’。CIFAR-10 中的图像尺寸为3x32x32,也就是RGB的3层颜色通道,每层通道内的尺寸为32*32。
首先,加载并归一化 CIFAR10 使用 torchvision 。由于
input[channel] = (input[channel] - mean[channel]) / std[channel]
所以代码中transforms.Normalize中,0.5转换成了归一化范围为[-1,1]之间的张量Tensor。
下面展示 CIFAR10 里面的一些图片:

其第一行为:frog bird dog horse ship dog ship plane
接下来定义网络,损失函数和优化器,然后对网络进行训练,训练过程及结果如下:
可以看出,重复了10轮训练后,其loss逐渐降低。最后在0.790左右。
Epoch: 1 Minibatch: 1 loss: 2.308
Epoch: 1 Minibatch: 101 loss: 1.969
Epoch: 1 Minibatch: 201 loss: 1.678
Epoch: 1 Minibatch: 301 loss: 1.497
Epoch: 1 Minibatch: 401 loss: 1.662
Epoch: 1 Minibatch: 501 loss: 1.500
Epoch: 1 Minibatch: 601 loss: 1.600
Epoch: 1 Minibatch: 701 loss: 1.456
Epoch: 2 Minibatch: 1 loss: 1.689
Epoch: 2 Minibatch: 101 loss: 1.337
Epoch: 2 Minibatch: 201 loss: 1.331
Epoch: 2 Minibatch: 301 loss: 1.401
Epoch: 2 Minibatch: 401 loss: 1.255
Epoch: 2 Minibatch: 501 loss: 1.323
Epoch: 2 Minibatch: 601 loss: 1.206
Epoch: 2 Minibatch: 701 loss: 1.392
Epoch: 3 Minibatch: 1 loss: 1.275
Epoch: 3 Minibatch: 101 loss: 1.241
Epoch: 3 Minibatch: 201 loss: 1.234
Epoch: 3 Minibatch: 301 loss: 1.307
Epoch: 3 Minibatch: 401 loss: 1.343
Epoch: 3 Minibatch: 501 loss: 1.186
Epoch: 3 Minibatch: 601 loss: 1.403
Epoch: 3 Minibatch: 701 loss: 1.278
Epoch: 4 Minibatch: 1 loss: 1.392
Epoch: 4 Minibatch: 101 loss: 1.119
Epoch: 4 Minibatch: 201 loss: 1.273
Epoch: 4 Minibatch: 301 loss: 1.095
Epoch: 4 Minibatch: 401 loss: 1.416
Epoch: 4 Minibatch: 501 loss: 1.232
Epoch: 4 Minibatch: 601 loss: 1.178
Epoch: 4 Minibatch: 701 loss: 1.159
Epoch: 5 Minibatch: 1 loss: 1.445
Epoch: 5 Minibatch: 101 loss: 1.024
Epoch: 5 Minibatch: 201 loss: 0.994
Epoch: 5 Minibatch: 301 loss: 1.061
Epoch: 5 Minibatch: 401 loss: 1.196
Epoch: 5 Minibatch: 501 loss: 1.136
Epoch: 5 Minibatch: 601 loss: 1.217
Epoch: 5 Minibatch: 701 loss: 0.904
Epoch: 6 Minibatch: 1 loss: 0.869
Epoch: 6 Minibatch: 101 loss: 0.902
Epoch: 6 Minibatch: 201 loss: 0.755
Epoch: 6 Minibatch: 301 loss: 0.878
Epoch: 6 Minibatch: 401 loss: 1.082
Epoch: 6 Minibatch: 501 loss: 0.986
Epoch: 6 Minibatch: 601 loss: 1.076
Epoch: 6 Minibatch: 701 loss: 0.976
Epoch: 7 Minibatch: 1 loss: 1.054
Epoch: 7 Minibatch: 101 loss: 0.994
Epoch: 7 Minibatch: 201 loss: 1.105
Epoch: 7 Minibatch: 301 loss: 0.964
Epoch: 7 Minibatch: 401 loss: 1.057
Epoch: 7 Minibatch: 501 loss: 0.903
Epoch: 7 Minibatch: 601 loss: 0.905
Epoch: 7 Minibatch: 701 loss: 0.970
Epoch: 8 Minibatch: 1 loss: 1.025
Epoch: 8 Minibatch: 101 loss: 1.107
Epoch: 8 Minibatch: 201 loss: 0.963
Epoch: 8 Minibatch: 301 loss: 0.957
Epoch: 8 Minibatch: 401 loss: 1.172
Epoch: 8 Minibatch: 501 loss: 0.821
Epoch: 8 Minibatch: 601 loss: 1.084
Epoch: 8 Minibatch: 701 loss: 1.001
Epoch: 9 Minibatch: 1 loss: 0.723
Epoch: 9 Minibatch: 101 loss: 0.996
Epoch: 9 Minibatch: 201 loss: 0.968
Epoch: 9 Minibatch: 301 loss: 0.994
Epoch: 9 Minibatch: 401 loss: 1.012
Epoch: 9 Minibatch: 501 loss: 0.967
Epoch: 9 Minibatch: 601 loss: 0.899
Epoch: 9 Minibatch: 701 loss: 0.842
Epoch: 10 Minibatch: 1 loss: 0.852
Epoch: 10 Minibatch: 101 loss: 0.692
Epoch: 10 Minibatch: 201 loss: 0.861
Epoch: 10 Minibatch: 301 loss: 0.803
Epoch: 10 Minibatch: 401 loss: 0.965
Epoch: 10 Minibatch: 501 loss: 0.788
Epoch: 10 Minibatch: 601 loss: 0.748
Epoch: 10 Minibatch: 701 loss: 0.824
Finished Training
然后从测试集中取出8张图片,其分别对应为:
cat ship ship plane frog frog car frog

把图片输入模型,CNN把这些图片分别识别成为:
cat ship ship plane deer frog car frog
可以看到,有一个图片识别错误。
输出网络在整个数据集中的表现,可以看到准确率大约为64%。

三、使用 VGG16 对 CIFAR10 分类
https://github.com/OUCTheoryGroup/colab_demo/blob/master/05_03_VGG_CIFAR10.ipynb
VGG16的网络结构如下图所示:

定义 dataloader 和 VGG 网络,VGG网络结构参数修改为
64 conv, maxpooling,
128 conv, maxpooling,
256 conv, 256 conv, maxpooling,
512 conv, 512 conv, maxpooling,
512 conv, 512 conv, maxpooling,
softmax
由于模型实现的源代码出现bug,将 self.features = self._make_layers(cfg) 中的 cfg 修改为self.cfg,因为cfg是self下的成员。
初始化网络, 修改分类层, 因为 tiny-imagenet 是对200类图像分类,所有把输出修改为200。
然后对网络进行训练:
由于两个矩阵 mat1 和 mat2 分别为 128x512 和 2048x10,不可相乘,所以修改self.classifier的值为self.classifier = nn.Linear(512, 128)。以下为原有报错信息:
修改后再次进行训练,结果如下:
Epoch: 1 Minibatch: 1 loss: 5.237
Epoch: 1 Minibatch: 101 loss: 1.635
Epoch: 1 Minibatch: 201 loss: 1.449
Epoch: 1 Minibatch: 301 loss: 1.302
Epoch: 2 Minibatch: 1 loss: 1.040
Epoch: 2 Minibatch: 101 loss: 0.830
Epoch: 2 Minibatch: 201 loss: 0.965
Epoch: 2 Minibatch: 301 loss: 0.799
Epoch: 3 Minibatch: 1 loss: 0.902
Epoch: 3 Minibatch: 101 loss: 0.807
Epoch: 3 Minibatch: 201 loss: 0.752
Epoch: 3 Minibatch: 301 loss: 0.835
Epoch: 4 Minibatch: 1 loss: 0.727
Epoch: 4 Minibatch: 101 loss: 0.590
Epoch: 4 Minibatch: 201 loss: 0.509
Epoch: 4 Minibatch: 301 loss: 0.621
Epoch: 5 Minibatch: 1 loss: 0.674
Epoch: 5 Minibatch: 101 loss: 0.508
Epoch: 5 Minibatch: 201 loss: 0.684
Epoch: 5 Minibatch: 301 loss: 0.616
Epoch: 6 Minibatch: 1 loss: 0.402
Epoch: 6 Minibatch: 101 loss: 0.569
Epoch: 6 Minibatch: 201 loss: 0.511
Epoch: 6 Minibatch: 301 loss: 0.570
Epoch: 7 Minibatch: 1 loss: 0.598
Epoch: 7 Minibatch: 101 loss: 0.533
Epoch: 7 Minibatch: 201 loss: 0.521
Epoch: 7 Minibatch: 301 loss: 0.734
Epoch: 8 Minibatch: 1 loss: 0.592
Epoch: 8 Minibatch: 101 loss: 0.588
Epoch: 8 Minibatch: 201 loss: 0.483
Epoch: 8 Minibatch: 301 loss: 0.561
Epoch: 9 Minibatch: 1 loss: 0.447
Epoch: 9 Minibatch: 101 loss: 0.318
Epoch: 9 Minibatch: 201 loss: 0.595
Epoch: 9 Minibatch: 301 loss: 0.393
Epoch: 10 Minibatch: 1 loss: 0.288
Epoch: 10 Minibatch: 101 loss: 0.431
Epoch: 10 Minibatch: 201 loss: 0.232
Epoch: 10 Minibatch: 301 loss: 0.439
Finished Training
可以看出,最后训练十次后,loss 在 0.3 左右,接下来测试验证准确率,可以得到在测试图像中,准确率约为 83.94%,可以看出,哪怕是简化版的 VGG 网络,也可以将 CNN 的准确率由 64% 提升到 83.94%。
Part 3 问题思考
1、dataloader 里面 shuffle 取不同值有什么区别?
shuffer = False 时,不打乱数据的顺序,shuffer = Ture 时,在每次迭代训练时会将将数据集打乱,然后再按顺序进行数据的取用。
2、transform 里,取了不同值,这个有什么区别?
transform 定义了一些常用的数据预处理方法,包括数据归一化,随机裁剪、翻转等,用于提高训练模型的泛化能力。
transforms.ToTensor() 作用是将数据转换为张量;transforms.Normalize()可以将像素值进行归一化处理,使得数据服从均值为0,标准差为1的分布;transforms.CenterCrop 和 transforms.RandomCrop 分别为中心裁剪 和 随机裁剪;transforms.RandomHorizontalFlip§ 和 transforms.RandomVerticalFlip§ 分别为依概率p水平翻转 和 依概率p垂直翻转。
3、epoch 和 batch 的区别?
Epoch : 使用训练集的全部数据对模型进行了一次完整的训练,是一次训练数据集的 一代训练。
Batch : 使用训练集的一小部分样本对模型权重进行一次反向传播的参数更新,这一小部分样本被称为 一批数据
4、1x1的卷积和 FC 有什么区别?主要起什么作用?
1*1卷积可以减少或增加特征图的层数,考虑基于输入尺寸,来代替全连接。
全连接的输入是特征图所有元素乘以权重再求和,但是这个权重向量是在设计网络的时候就需要固定的。
他们都是特征图中的元素乘以权重再求和。
5、residual leanring 为什么能够提升准确率?
增加的层能够构建与上一层一样的输出,那么该增加一层的网络训练精度应该大于等于原来的网络的训练精度,让网络学习残差,使用 Residual Network,将x直接连接到下一层,使网络学习到的是F(x),可提升准确率。输入x,当输出 f(x) = 0 时,f(x) + x = x 。有效的避免了梯度消失。
6、代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
代码二中,网络为三通道,使用ReLu激活函数,最大池化;
LeNet,网络为单通道,使用sigmoid激活函数,平均池化。
7、代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
采用1x1的卷积,对大小不同的feature map进行调整。
8、有什么方法可以进一步提升准确率?
①使用Dropout。
②加深网络深度,调整网络结构。
③选择可能更适合的激活函数。
/vc-image-1313154504.cos.ap-shanghai.myqcloud.com/image/202210152020310.jpeg" alt=“img” style=“zoom: 67%;” />
6、代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
代码二中,网络为三通道,使用ReLu激活函数,最大池化;
LeNet,网络为单通道,使用sigmoid激活函数,平均池化。
7、代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
采用1x1的卷积,对大小不同的feature map进行调整。
8、有什么方法可以进一步提升准确率?
①使用Dropout。
②加深网络深度,调整网络结构。
③选择可能更适合的激活函数。
该博客的所有图片依托于腾讯云COS搭建的图床,如出现无法显示的问题,敬请联系本人。