数据挖掘实验一:关联规则(基于Python)
目录
- 实验要求
- 实验内容
- 实现方法(代码)
- 实验结果
- 结论分析(代码反思)
实验要求
1. 掌握项集和频繁项集的定义。
2. 掌握狭义连接的原理和实现方法,尤其注意狭义连接的严苛条件。
3. 掌握频繁项的候选项如何通过低阶的频繁项做删除操作。
4. 掌握如何利用数据库或其它数据源对频繁项的候选项进行删除操作。
5. 掌握如何利用频繁项生成所有的强关联规则
实验内容
关联规则发现是机器学习和数据挖掘中重要的算法之一,有许多版本变种和应用场景。关联规则发现算法的基础算法之一是Apriori算法
希望你能按照算法的基本原理,编写一个通用算法,对符合格式要求的数据文件和给定的阈值,能够产生所有的强关联规则。数据文件形式如下:
I1,I2,I5
I2,I4
I2,I3
I1,I2,I4
I1,I3
I2,I3
I1,I3
I1,I2,I3,I5
I1,I2,I3
这表示数据库中的若干行,每一行有一个或多个项构成,项之间用英文逗号隔开。
实现方法(代码)
这次实验,我使用简单的python程序先后实现了从文件中读取并存储数据,从数据中归纳频繁项集,从频繁项集中挖掘关联规则这三步。其中,我设置的强关联规则的默认支持度阈值为0.55,支持度频度的默认阈值为2。具体代码如下:
class ItemSet:
# 构造函数,我把前两个类(Itemset和ItemSetCount)直接合并了,方便很多
def __init__(self, info, count=0):
info.sort()
self.items = info
self.count = count
def printInfo(self): # 打印信息(用于测试
print(self.items)
def compareTo(self, anotherItemset):
# 直接字典序比较即可
if self.items < anotherItemset.items:
return -1
elif self.items == anotherItemset.items:
return 0
else:
return 1
def clone(self): # 返回一个复制,要求深拷贝
items = self.items
a = ItemSet(items)
return a
def equals(self, anotherItemset): # 是否完全相同
if self.compareTo(anotherItemset) == 0:
return True
else:
return False
def isMonoIncrease(self):
# 判断是否是从小到大
# 虽然在构造函数里边已经进行了排序,但是最好还是判断一下,以防中间的误操作
for i in range(0, len(self.items) - 1):
if self.items[i] > self.items[i + 1]:
return False
return True
def link(self, anotherItemset):
# 两个项集的狭义连接。只有符合条件的两个项集才能狭义连接。
# 狭义连接后,产生了比当前两个项集更高一阶的项集。
# 如果不满足狭义连接的条件,建议返回null,以便于控制:
# 首先判断是否满足条件
s1 = self.items
s2 = anotherItemset.items
# print(s1, s2, ':')
if len(s1) != len(s2):
return -1 # 错误信息
for i in range(0, len(s1) - 1):
if s1[i] != s2[i]:
return -1
if s1[-1] >= s2[-1]:
# print(False)
return -1
# 合并并返回
ans = s1 + [s2[-1]]
# print(ans)
return ans
def ifSubExist(self):
# 先放在这,感觉用不到,用到了再写
return False
def subStract(self, sub):
# 项集的减法。把当前项集所有项减去一个子集(或任意集合)中的所有元素
i1 = self.items
i2 = sub.items
for i in i2:
if i in i1:
i1.remove(i)
return i1
class Apriori:
def __init__(self, threshold=2):
self.itemSets = []
self.threshold = threshold
def readFile(self): # 读取文件存入对象
self.itemSets = [] # 初始化
print('正在读取p1.py同目录下test.txt中...请留意文件是否存在,数据格式是否正确')
try:
for line in open('test.txt', 'r'):
line = line.replace('\n', '') # 去掉换行符
info = line.split(',')
# print(info)
itemSet = ItemSet(info)
# itemSet.printInfo()
self.itemSets.append(itemSet)
print('读取成功')
except Exception:
print('读取文件失败!请检查源程序同路径下是否有test.txt存在')
def totalNum(self):
# 返回总数
return len(self.itemSets)
def printInfo(self): # 打印信息(用于测试
for i in self.itemSets:
if isinstance(i, ItemSet):
i.printInfo()
def getItemCount(self):
# 一次扫描(对所有的行进行一次遍历)之后能够把所有的项及其对应的数量返回,放到一个Map结构中
list = self.itemSets
map = {}
for line in list:
line = line.items
for i in line:
if i in map:
map[i] += 1
else:
map[i] = 1
return map
def sortItemSetCount(self):
# 把第一次扫描的结果放到结构ItemSetCount中,便于统一使用
# 感觉用不到,用到了再来写
pass
def reduceItemSetCounts(self):
# 根据阈值把不符合阈值条件的项集删除,剩余的是频繁项集族
map = self.getItemCount()
dellist = []
for i in map:
if map[i] < self.threshold:
dellist.append(i)
for i in dellist:
del map[i]
return map
def linkItemSets(self, line):
# 更低一阶的频繁项集族通过狭义连接生成更高一阶的频繁项集候选族
# map = {}
# for i in range(len(line)):
# map[line[i]] = count
itemlist = line
ans = []
for i in itemlist:
if isinstance(i, list):
s1 = ItemSet(i)
else:
s1 = ItemSet([i])
for j in itemlist:
if isinstance(j, list):
s2 = ItemSet(j)
else:
s2 = ItemSet([j])
if isinstance(s1.link(s2), list):
ans.append(s1.link(s2))
return ans
def setLineInfo(self, line):
# 注意!!返回的只有频率没有组合信息
# 取得数据库中的一行之后,这一行的信息会对ItemSetCount数组结构中的频度进行修改
ans = [] # 存储当前这阶的map数值(因为列表不能作key)
for i in line:
ans.append(0)
for item in self.itemSets:
currline = item.items
for index in range(len(ans)):
# print('debug:',line[index])
if set(line[index]).issubset(set(currline)):
ans[index] += 1
return ans
def verifyByDB(self, line):
line_count = self.setLineInfo(line)
ans = []
ans_count = []
for i in range(len(line)):
if line_count[i] >= self.threshold:
ans.append(line[i])
ans_count.append(line_count[i])
return ans, ans_count
def getAllFrequent(self):
# 总的方法,返回所有频繁项集及其频度
ans = []
ans_count = []
self.readFile()
map1 = self.reduceItemSetCounts()
line = []
count = []
for i in map1:
line.append(i)
ans.append([i])
count.append(map1[i])
ans_count.append(map1[i])
# print(ans, ans_count)
frequent = self.linkItemSets(line) # 二阶项集
frequent, count = self.verifyByDB(frequent) # 二阶频繁项集,对应频度
ans += frequent
ans_count += count
# print(frequent, count)
while len(frequent) > 0:
frequent = self.linkItemSets(frequent)
# print('debug:', frequent)
frequent, count = self.verifyByDB(frequent)
ans += frequent
ans_count += count
# print(frequent, count)
return ans, ans_count
class AssociationRule:
def __init__(self, s=0.55):
self.support = s # 支持度阈值
def isSub(self, a, b): # a是b的真子集吗?(ab为列表)
if a == b:
return False
else:
return set(a).issubset(set(b))
def getAssociation(self): # 其实是当主函数用
apriori = Apriori()
fre, fre_count = apriori.getAllFrequent()
print('频繁项集及其对应的频度如下:')
for i in range(len(fre)):
print('<', fre[i], ',', fre_count[i], '>')
print('根据这些频繁项集,我们可以生成的关联规则,以及其可信度,支持度分别为:')
# 接下来要开始算关联规则了
# 首先要知道总数用来算可信度
total_num = apriori.totalNum()
asso = []
asso_beli = []
asso_conf = []
# print(len(fre))
for i in range(len(fre)):
# print('debug:',fre[i])
for j in range(len(fre)):
if self.isSub(fre[i], fre[j]):
curr_supp = fre_count[j] / fre_count[i]
# print('debug:', fre[i], fre[j], curr_supp)
if curr_supp >= self.support: # 满足支持度阈值
head = str(fre[i])
# print('debug1:', fre[j])
tail = str(getMinus(fre[j], fre[i]))
# print('debug2:', fre[j])
curr_asso = head + '-->' + tail
asso.append(curr_asso)
asso_beli.append(fre_count[j] / total_num)
asso_conf.append(curr_supp)
# else:
# print('debug:', fre[i], fre[j], 'fail')
# 输出结果
for i in range(len(asso)):
print('<', asso[i], ',', asso_beli[i], ',', asso_conf[i], '>')
def getMinus(a, b): # 返回a-b(python不支持列表相减)
# 这里必须单独重新构造一次,不然会影响原值,特别麻烦
a0 = []
b0 = []
for i in a:
a0.append(i)
for i in b:
b0.append(i)
for i in b0:
a0.remove(i)
return a0
if __name__ == '__main__': # 主函数
associationRule = AssociationRule()
associationRule.getAssociation()
实验结果
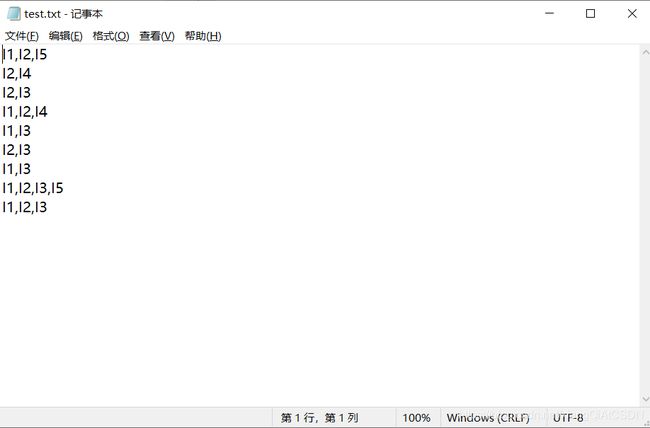
test.txt中的内容如下:
运行代码,控制台输出如下:
正在读取p1.py同目录下test.txt中...请留意文件是否存在,数据格式是否正确
读取成功
频繁项集及其对应的频度如下:
< ['I1'] , 6 >
< ['I2'] , 7 >
< ['I5'] , 2 >
< ['I4'] , 2 >
< ['I3'] , 6 >
< ['I1', 'I2'] , 4 >
< ['I1', 'I5'] , 2 >
< ['I1', 'I3'] , 4 >
< ['I2', 'I5'] , 2 >
< ['I2', 'I4'] , 2 >
< ['I2', 'I3'] , 4 >
< ['I1', 'I2', 'I5'] , 2 >
< ['I1', 'I2', 'I3'] , 2 >
根据这些频繁项集,我们可以生成的关联规则,以及其可信度,支持度分别为:
< ['I1']-->['I2'] , 0.4444444444444444 , 0.6666666666666666 >
< ['I1']-->['I3'] , 0.4444444444444444 , 0.6666666666666666 >
< ['I2']-->['I1'] , 0.4444444444444444 , 0.5714285714285714 >
< ['I2']-->['I3'] , 0.4444444444444444 , 0.5714285714285714 >
< ['I5']-->['I1'] , 0.2222222222222222 , 1.0 >
< ['I5']-->['I2'] , 0.2222222222222222 , 1.0 >
< ['I5']-->['I1', 'I2'] , 0.2222222222222222 , 1.0 >
< ['I4']-->['I2'] , 0.2222222222222222 , 1.0 >
< ['I3']-->['I1'] , 0.4444444444444444 , 0.6666666666666666 >
< ['I3']-->['I2'] , 0.4444444444444444 , 0.6666666666666666 >
< ['I1', 'I5']-->['I2'] , 0.2222222222222222 , 1.0 >
< ['I2', 'I5']-->['I1'] , 0.2222222222222222 , 1.0 >
Process finished with exit code 0
经检查分析,该运行结果是正确的。
结论分析(代码反思)
这是数据挖掘的第一次实验。总的来说,这次实验除了在搭建几个类的时候嵌套的层数比较多以外,并不算特别复杂。这次实验中,我遇到的最大问题是:在挖掘关联规则时,有这样一段代码:
if curr_supp >= self.support: # 满足支持度阈值
head = str(fre[i])
# print('debug1:', fre[j])
tail = str(getMinus(fre[j], fre[i]))
# print('debug2:', fre[j])
curr_asso = head + '-->' + tail
这一段看似逻辑很清晰,但是我在测试的时候发现总会出错。设置断点debug之后,我才发现是函数getMinus()出现了问题。
原getMinus()的定义为:
def getMinus(a, b): # 返回a-b(python不支持列表相减)
for i in b:
a.remove(i)
return a
这段代码会修改a本身的值。每当调用一次,我们之前得到的频繁项集中的内容都会发生改变。因此,我给该函数添加了深拷贝,修改如下:
def getMinus(a, b): # 返回a-b(python不支持列表相减)
# 这里必须单独重新构造一次,不然会影响原值,特别麻烦
a0 = []
b0 = []
for i in a:
a0.append(i)
for i in b:
b0.append(i)
for i in b0:
a0.remove(i)
return a0
除了这里,其他地方并没有出大问题。