python中的pandas库
文章目录
- 一、基本用法介绍
-
- 1.DataFrame()函数的两种传参方法:
-
- 方法1:
- 方法2:
- 2.Series()函数的传参方法:
- 3.基本用法代码示例
- 二、选择数据
-
- 1.通过标签选择数据(左闭右闭)
- 2.通过下标选择数据(左闭右开)
- 3.大小筛选
- 三、设置值
- 四、处理丢失数据
-
- 1.删除处理
- 2.填充处理
- 3.是否为NaN
- 4.是否为NaN
- 五、导入导出
- 六、concat合并
- 七、merge合并
-
- 1.基于列对应的的元素(可挑是哪个列)的左右合并
- 2.基于行的名字(不可挑)的左右合并
- 3.同名处理
- 八、plot可视化
-
- 1. 线性图
- 2.散点图
一、基本用法介绍
1.DataFrame()函数的两种传参方法:
该函数的作用是构建一个 有行列名字的矩阵(表)
方法1:
第一个参数为矩阵(不能是列表和序列)
第二个参数 index= 为行的名字(为list形式)
第三个参数 columns= 为列的名字(为list形式)
dates = pd.date_range('20200627',periods=6)
df = pd.DataFrame(np.random.randn(6,4),index=dates,columns=['a','b','c','d'])
print(df)
np.random.randn(6,4)函数表示生成正态分布的随机数矩阵。
index表示给每一行命名,columns表示给每一列命名
如果括号里面只有第一个参数,则行列名字默认为从0到n的数。
结果:
a b c d
2020-06-27 -0.527746 0.421249 1.334820 0.513721
2020-06-28 -0.396130 0.666276 0.068600 -1.145693
2020-06-29 -0.297739 1.775346 -0.559711 0.462260
2020-06-30 -1.603373 -0.926307 0.632710 0.492280
2020-07-01 1.436683 -0.488381 0.160079 0.345217
2020-07-02 0.715776 -1.092751 0.116804 -0.827165
方法2:
第一个参数为一个字典:
字典 : 前表示列的名字,为数字或字符串的形式。
字典 : 后表示每一列的元素,为列表的形式。
第二个参数 index= 为行的名字(为list形式)
df2 = pd.DataFrame({'A':1.,
'B':pd.Timestamp('20130102'),
'C':pd.Series(1,index=list(range(4))),
'D':np.array([3]*4),
'E':pd.Categorical(['aa','bb','cc','dd']),
'F':'foo'
},index=[0,1,2,3])
print(df2)
传的第一个参数为字典(定义列),第二个参数为 index(定义行的名字)
结果:
A B C D E F
0 1.0 2013-01-02 1 3 aa foo
1 1.0 2013-01-02 1 3 bb foo
2 1.0 2013-01-02 1 3 cc foo
3 1.0 2013-01-02 1 3 dd foo
2.Series()函数的传参方法:
该函数的作用是构建一个 只有行的名字的 1列
(尽管有1列,但是没有列的名字)
第一个形参为列表或者序列(不能是矩阵)
第二个形参为行的名字,行的名字必须是列表的形式。
import pandas as pd
import numpy as np
s = pd.Series([1,3,6,np.nan,44,1],index=np.arange(6)) #np.nan表示啥都没有NaN
print(s)
结果:
0 1.0
1 3.0
2 6.0
3 NaN
4 44.0
5 1.0
dtype: float64
3.基本用法代码示例
- date_range()函数
dates = pd.date_range('20200627',periods=6)
print(dates)
结果:
DatetimeIndex(['2020-06-27', '2020-06-28', '2020-06-29', '2020-06-30',
'2020-07-01', '2020-07-02'],
dtype='datetime64[ns]', freq='D')
参考:
A B C D E F
0 1.0 2013-01-02 1 3 aa foo
1 1.0 2013-01-02 1 3 bb foo
2 1.0 2013-01-02 1 3 cc foo
3 1.0 2013-01-02 1 3 dd foo
prit(df2.dtypes) 表示输出每一列(A到F)所代表的的数据类型
prit(df2.index) 表示输出行的名字(0到3)
print(df2.columns) 表示输出列的名字(A到F)
print(df2.values) 表示输出每个元素
print(df2.describe()) 表示输出每一列所代表的数字的特征量(和,平均值等)
print(df2.T) 表示输出转置
参考:
A B C D E F
0 1.0 2013-01-02 1 3 aa foo
1 1.0 2013-01-02 1 3 bb foo
2 1.0 2013-01-02 1 3 cc foo
3 1.0 2013-01-02 1 3 dd foo
print(df2.sort_index(axis=1,ascending=False))
第一个参数表示对列的名字排序(行保持不变)
第二个参数表示倒序排序
结果:
F E D C B A
0 foo aa 3 1 2013-01-02 1.0
1 foo bb 3 1 2013-01-02 1.0
2 foo cc 3 1 2013-01-02 1.0
3 foo dd 3 1 2013-01-02 1.0
参考:
A B C D E F
0 1.0 2013-01-02 1 3 aa foo
1 1.0 2013-01-02 1 3 bb foo
2 1.0 2013-01-02 1 3 cc foo
3 1.0 2013-01-02 1 3 dd foo
print(df2.sort_index(axis=0,ascending=False))
第一个参数表示对行的名字排序(列保持不变)
第二个参数表示倒序排序
结果:
A B C D E F
3 1.0 2013-01-02 1 3 dd foo
2 1.0 2013-01-02 1 3 cc foo
1 1.0 2013-01-02 1 3 bb foo
0 1.0 2013-01-02 1 3 aa foo
参考:
A B C D E F
0 1.0 2013-01-02 1 3 aa foo
1 1.0 2013-01-02 1 3 bb foo
2 1.0 2013-01-02 1 3 cc foo
3 1.0 2013-01-02 1 3 dd foo
print(df2.sort_values(by='E'))
对元素进行排序,可以通过by=的形式表示对某一列的元素进行排序
结果:
A B C D E F
0 1.0 2013-01-02 1 3 aa foo
1 1.0 2013-01-02 1 3 bb foo
2 1.0 2013-01-02 1 3 cc foo
3 1.0 2013-01-02 1 3 dd foo
二、选择数据
参考:
dates = pd.date_range('20220514',periods=6)
df=pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['a','b','c','d'])
print(df)
参考的结果:
a b c d
2022-05-14 0 1 2 3
2022-05-15 4 5 6 7
2022-05-16 8 9 10 11
2022-05-17 12 13 14 15
2022-05-18 16 17 18 19
2022-05-19 20 21 22 23
1.通过标签选择数据(左闭右闭)
print(df.loc['20220514',:]) #输出某一行的元素
a 0
b 1
c 2
d 3
print(df.loc[:,'a']) #输出某一列的元素
2022-05-14 0
2022-05-15 4
2022-05-16 8
2022-05-17 12
2022-05-18 16
2022-05-19 20
print(df.loc['20220515':'20220517','a':'c']) #行列区间的元素
a b c
2022-05-15 4 5 6
2022-05-16 8 9 10
2022-05-17 12 13 14
2.通过下标选择数据(左闭右开)
print(df.iloc[3,:]) 输出第4行的元素
print(df.iloc[:,3]) 输出第4列的元素
print(df.iloc[0:3,0:2]) 输出1到3行,1到2列的元素
print(df.iloc[[0,3],[0,2]]) 不连续筛选([]包[]),表示输出第一行第四行和第一列第三列的交集元素
不连续筛选的结果:
a c
2022-05-14 0 2
2022-05-17 12 14
3.大小筛选
print(df[df.a>8]) #或者print(df[df['a']>8]) 表示输出所有元素(要求a这一列大于8)
a b c d
2022-05-17 12 13 14 15
2022-05-18 16 17 18 19
2022-05-19 20 21 22 23
print(df.a[df.a>8]) 表示输出a这一列大于8的元素
2022-05-17 12
2022-05-18 16
2022-05-19 20
三、设置值
参考:
dates = pd.date_range('20220514',periods=6)
df=pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['a','b','c','d'])
print(df)
参考的结果:
a b c d
2022-05-14 0 1 2 3
2022-05-15 4 5 6 7
2022-05-16 8 9 10 11
2022-05-17 12 13 14 15
2022-05-18 16 17 18 19
2022-05-19 20 21 22 23
df.iloc[2,2] = 1111 #通过位置(下标)改动值
df.loc[‘20200514’,’c’] = 2222 #通过名字改动值
df[df.a>4] = 0置零
a b c d
2022-05-14 0 1 2 3
2022-05-15 4 5 6 7
2022-05-16 0 0 0 0
2022-05-17 0 0 0 0
2022-05-18 0 0 0 0
2022-05-19 0 0 0 0
df.a[df.a>4] = 0置零
a b c d
2022-05-14 0 1 2 3
2022-05-15 4 5 6 7
2022-05-16 0 9 10 11
2022-05-17 0 13 14 15
2022-05-18 0 17 18 19
2022-05-19 0 21 22 23
df.b[df.a>4] = 0置零
a b c d
2022-05-14 0 1 2 3
2022-05-15 4 5 6 7
2022-05-16 8 0 10 11
2022-05-17 12 0 14 15
2022-05-18 16 0 18 19
2022-05-19 20 0 22 23
df['e'] = np.nan表示加一列空值df['f'] = pd.Series([1,2,3,4,5,6],index = dates)表示加一列数字
#dates = pd.date_range(‘20200514’,periods=6)
a b c d f
2022-05-14 0 1 2 3 1
2022-05-15 4 5 6 7 2
2022-05-16 8 9 10 11 3
2022-05-17 12 13 14 15 4
2022-05-18 16 17 18 19 5
2022-05-19 20 21 22 23 6
四、处理丢失数据
处理丢失数据即 将含NaN的进行处理
1.删除处理
print(df.dropna(axis=0,how='any')) #或者how = 'all'
axis=0 表示列保留,即删掉行
how='any’表示,只要某一行有一个NaN,那么那一行都会删掉
how = 'all’表示只有所有行都有NaN,那么那一行才会删掉
2.填充处理
print(df.fillna(value=0))
#将NaN的地方填充为0
3.是否为NaN
print(df.isnull())
输出为由true和false组成的表
4.是否为NaN
print(np.any(df.isnull()) == True)
表示是否至少包含一个True
输出结果为True或者False
五、导入导出
导入:
data = pd.read_csv('student.csv')
print(data)
可以将csv表格文件存到data里,然后在python中输出
导出:
data.to_pickle('student.pickle')
将student.pickle保存到了与py文件同一目录的文件夹中
六、concat合并
直接合并,一样的都保留
可左右合并,也可上下合并
参考:
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['b','c','d','e'],index=[2,3,4])
print(df1)
print(df2)
参考的结果:
a b c d
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0
b c d e
2 1.0 1.0 1.0 1.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
pd.concat(ignore_index = True) 表示对行的名字重新排序
- 取列的并集(上下合并)
(axis=1,join='outer’的组合表示取行的并集,左右合并)
print(pd.concat([df1,df2],axis=0,join='outer'))
结果:
a b c d e
1 0.0 0.0 0.0 0.0 NaN
2 0.0 0.0 0.0 0.0 NaN
3 0.0 0.0 0.0 0.0 NaN
2 NaN 1.0 1.0 1.0 1.0
3 NaN 1.0 1.0 1.0 1.0
4 NaN 1.0 1.0 1.0 1.0
- 取列的交集(上下合并)
(axis=1,join='inner’的组合表示取行的交集,左右合并)
print(pd.concat([df1,df2],axis=0,join='inner'))
结果:
b c d
1 0.0 0.0 0.0
2 0.0 0.0 0.0
3 0.0 0.0 0.0
2 1.0 1.0 1.0
3 1.0 1.0 1.0
4 1.0 1.0 1.0
- 按照谁来合并(保留谁)
print(pd.concat([df1,df2],axis=1).reindex(df1.index))
表示按照df1的 行的名字来进行与df2的左右合并(同理可推其他情况)
a b c d b c d e
1 0.0 0.0 0.0 0.0 NaN NaN NaN NaN
2 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
3 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
- 例子(添加某一行)(上下合并)
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
print(df1)
df3=pd.DataFrame(np.array([1,2,3,4]).reshape((1,4)),index=[4],columns=['a','b','c','d'])
print(df3)
res=pd.concat([df1,df3],axis=0)
print(res)
结果:
a b c d
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0
a b c d
4 1 2 3 4
a b c d
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0
4 1.0 2.0 3.0 4.0
- 例子(添加某一列)(左右合并)
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
print(df1)
df3=pd.DataFrame(np.array([1,2,3]).reshape((3,1)),index=[1,2,3],columns=['e'])
print(df3)
res=pd.concat([df1,df3],axis=1)
print(res)
结果:
a b c d
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0
e
1 1
2 2
3 3
a b c d e
1 0.0 0.0 0.0 0.0 1
2 0.0 0.0 0.0 0.0 2
3 0.0 0.0 0.0 0.0 3
七、merge合并
名字一样的会只保留一个,输出时为字典乱序形式
只是左右合并
1.基于列对应的的元素(可挑是哪个列)的左右合并
参考:
import pandas as pd
import numpy as np
l = pd.DataFrame({'k1':[0,0,1,2],
'k2':[0,1,0,1],
'a':[10,11,12,13],
'b':[20,21,22,23]
})
r = pd.DataFrame({'k1':[0,1,1,2],
'k2':[0,0,0,0],
'a':[30,31,32,33],
'b':[40,41,42,43]
})
print(l)
print(r)
参考的结果:
k1 k2 a b
0 0 0 10 20
1 0 1 11 21
2 1 0 12 22
3 2 1 13 23
k1 k2 a b
0 0 0 30 40
1 1 0 31 41
2 1 0 32 42
3 2 0 33 43
res1 = pd.merge(l,r,on=['k1','k2'],how='inner')#
res2 = pd.merge(l,r,on=['k1','k2'],how='outer')
res3 = pd.merge(l,r,on=['k1','k2'],how='left')
res4 = pd.merge(l,r,on=['k1','k2'],how='right')
print(res1)
print(res2)
print(res3)
print(res4)
on=列表 表示基于哪两个相同进行合并
how=字符串 表示哪种方式合并。
’inner‘表示找两者k1,k2元素交集(笛卡尔积)进行对应左右合并。
’outer’为并集,直接合并
‘left’为基于左边l 的进行合并
‘right’表示基于右边r 的进行合并
结果:
k1 k2 a_x b_x a_y b_y
0 0 0 10 20 30 40
1 1 0 12 22 31 41
2 1 0 12 22 32 42
k1 k2 a_x b_x a_y b_y
0 0 0 10.0 20.0 30.0 40.0
1 0 1 11.0 21.0 NaN NaN
2 1 0 12.0 22.0 31.0 41.0
3 1 0 12.0 22.0 32.0 42.0
4 2 1 13.0 23.0 NaN NaN
5 2 0 NaN NaN 33.0 43.0
k1 k2 a_x b_x a_y b_y
0 0 0 10 20 30.0 40.0
1 0 1 11 21 NaN NaN
2 1 0 12 22 31.0 41.0
3 1 0 12 22 32.0 42.0
4 2 1 13 23 NaN NaN
k1 k2 a_x b_x a_y b_y
0 0 0 10.0 20.0 30 40
1 1 0 12.0 22.0 31 41
2 1 0 12.0 22.0 32 42
3 2 0 NaN NaN 33 43
res3 = pd.merge(l,r,on=['k1','k2'],how='left',indicator=True)
indicator=True这个语句表示,在输出结果时,会多一列,把连接方式(怎么imerge的)给打印出来。
2.基于行的名字(不可挑)的左右合并
参考:
import pandas as pd
import numpy as np
l = pd.DataFrame({'a':[1,2,3],
'b':[11,12,13],
},index=[0,1,2])
r = pd.DataFrame({'c':[21,22,23],
'd':[31,32,33],
},index=[0,2,3])
print(l)
print(r)
参考的结果:
a b
0 1 11
1 2 12
2 3 13
c d
0 21 31
2 22 32
3 23 33
res1 = pd.merge(l,r,left_index=True,right_index=True,how='inner')
res2 = pd.merge(l,r,left_index=True,right_index=True,how='outer')
res3 = pd.merge(l,r,left_index=True,right_index=True,how='left')
res4 = pd.merge(l,r,left_index=True,right_index=True,how='right')
print(res1)
print(res2)
print(res3)
print(res4)
结果:
a b c d
0 1 11 21 31
2 3 13 22 32
a b c d
0 1.0 11.0 21.0 31.0
1 2.0 12.0 NaN NaN
2 3.0 13.0 22.0 32.0
3 NaN NaN 23.0 33.0
a b c d
0 1 11 21.0 31.0
1 2 12 NaN NaN
2 3 13 22.0 32.0
a b c d
0 1.0 11.0 21 31
2 3.0 13.0 22 32
3 NaN NaN 23 33
3.同名处理
作用是防止基于某个列的名字合并以后的表中,出现名字相同的列,进而混淆
- 以基于列的名字的左右合并为例:
import pandas as pd
import numpy as np
boys = pd.DataFrame({'id':['k0','k1','k2'],'age':[1,2,3]})
girls = pd.DataFrame({'id':['k0','k0','k3'],'age':[4,5,6]})
print(boys)
print(girls)
res = pd.merge(boys,girls,on='id',suffixes=['_boy','_girl'],how='inner')
print(res)
suffixes=['_boy','_girl']是为了处理两个表合并以后仍然有同名列名字的情况
'_boy’加在左面表(boys)列同名名字的后面
'_girl’加在右面表(girls)列同名名字的后面。
结果:
id age id_boy age_boy
0 k0 1 0 k0 1
1 k1 2 1 k1 2
2 k2 3 相当于 2 k2 3
id age id_girl age_girl
0 k0 4 0 k0 4
1 k0 5 1 k0 5
2 k3 6 相当于 2 k3 6
id age_boy age_girl
0 k0 1 4
1 k0 1 5
//因为是基于id合并的,所以合并之后只有1个id,不涉及到同名,所以不加后缀_boy/_girl
八、plot可视化
1列表示1组数据,4列表示4组数据(ABCD)
1. 线性图
1.Series()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
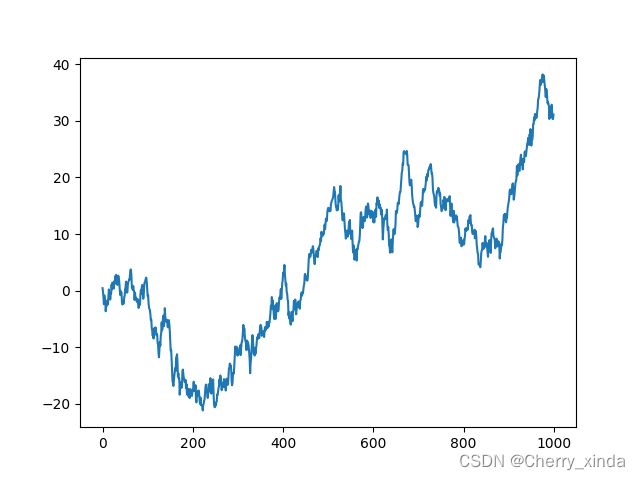
data = pd.Series(np.random.randn(1000),index = np.arange(1000))
data = data.cumsum() #累加
data.plot()
plt.show()
结果:
- DataFrame()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
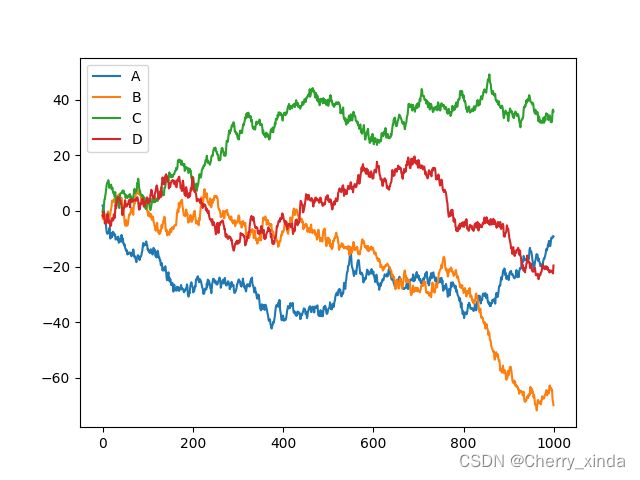
data = pd.DataFrame(np.random.randn(1000,4),index=np.arange(1000),columns=list('ABCD')) #np.random.randn(1000,4)表示1000个数据点,4个属性
data = data.cumsum() #累加
data.plot()
plt.show()
结果:
2.散点图
- DataFrame()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.DataFrame(np.random.randn(1000,4),index=np.arange(1000),columns=list('ABCD')) #表示1000个数据点,4个属性
data = data.cumsum() #累加
ax = data.plot.scatter(x='A',y='B',color='Blue',label='Class 1')
data.plot.scatter(x='A',y='C',color='Green',label='Class 2',ax=ax)
plt.show()
结果:
