Pytorch学习笔记---2:张量
Pytorch引入了一种基本的数据结构:张量。在深度学习中,张量可以将向量和矩阵推广到任意维度。张量的另一个名称是多维数组,张量的维度与用来表示张量中标量值的索引数量一致。与Numpy数组相比,Pytorch张量具有一些“超能力”,如在GPU上执行非常快的操作、在多个设备或及其上进行分布式操作以及跟踪创建它们的计算图。在实现现代深度学习库时,这些都是重要的特性。
本文将介绍使用Pytorch张量库来操作张量。张量是一个数组,也就是一种数据结构,它存储了一组数字,这些数字可以用一个索引单独访问,也可以用多个索引访问。
一、构建第一个张量
import torch
a = torch.ones(3) # 生成一个大小为1x3的张量
print(a)
print(a[1]) # 张量索引从0开始
print(float(a[1])) # 张量元素转化为浮点数
# 输出结果如下:
tensor([1., 1., 1.])
tensor(1.)
1.0也可以通过索引修改张量元素的值:
a[2] = 2.0
print(a)tensor([1., 1., 2.])二、张量的本质
Python列表或数字元组实在内存中单独分配的Python对象的集合。Pytorch张量或者Numpy数组通常是连续内存块的视图,这些内存块包含未装箱的C数字类型,而不是Python对象。若每个元素都是32位的浮点数,则存储1000000个浮点数恰好需要4000000个连续字节。
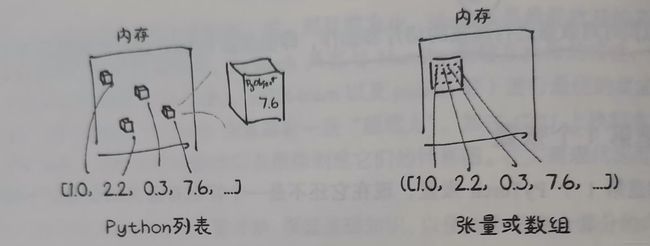
我们可以使用一维张量,将x轴坐标存储在偶数索引中,将y轴坐标存储在奇数索引中,而不是在Python列表中使用数字来表示坐标。
points = torch.zeros(6)
points[0] = 1
points[1] = 1
points[2] = 2
points[3] = 2
points[4] = 3
points[5] = 3
print(points)
print(points.shape)tensor([1., 1., 2., 2., 3., 3.])
torch.Size([6])获得第一个点的坐标:
print(float(points[0]), float(points[1]))1.0 1.0尽管将第一个索引指向单独的二维点而不是点坐标是可行的,但对于这种情况,我们可以用一个二维张量。
points = torch.tensor([[1, 1], [2, 2], [3, 3]])
print(points)
print(points.shape)tensor([[1, 1],
[2, 2],
[3, 3]])
torch.Size([3, 2])可以用两个索引来访问张量中的单个元素,也可以用一个索引来访问一个点
print(points[0, 0]) # 读取第一个元素
print(points[0]) # 读取第一个点tensor(1)
tensor([1, 1])输出是另一个张量tensor([1, 1]),它展示了相同基础数据的不同视图。新的张量是一个大小为2的一维张量,引用了张量points第一行的值,但这并不意味着分配了一个新的内存块,这样子的效率太低了。实际上这只是我们换了一种方式读取一段不变的内存块。
三、索引张量
Pytorch张量使用的表示法和Python列表相同,好处是就像在Numpy和其他Python科学库一样,我们可以为张量的每个维度适用范围索引。
print(points[1:]) # 第1行之后的所有行,隐含所有列
print(points[1:, :]) # 第一行之后的所有行,所有列
print(points[1:, 0]) # 第一行之后的所有行,第1列
print(points[None]) # 增加大小为1的维度,就像unsqueeeze()方法一样tensor([[2, 2],
[3, 3]])
tensor([[2, 2],
[3, 3]])
tensor([2, 3])
tensor([[[1, 1],
[2, 2],
[3, 3]]])四、命名张量
张量的维度或坐标轴通常用来表示诸如像素位置或颜色通道的信息,这意味当我们要把一个张量作为索引时,我们需要记住维度的顺序并按此顺序编写索引。
Pytorch1.3将命名张量作为试验性的特性。张量工厂函数(诸如tensor()和rand()函数)有一个names参数,该参数是一个字符串序列。 · ·· · · a
weight_name = torch.tensor([0.2126, 0.7152, 0.0722], names=['channels'])
print(weight_name)tensor([0.2126, 0.7152, 0.0722], names=('channels',))当我们已经有一个张量并且想要为其添加名称但不改变现有的名称时,可以对其调用refine_names()方法。与索引类似,省略号(...)允许省略任意数量的维度。使用rename()兄弟方法还可以覆盖或删除现有名称:
a = torch.randn(3, 5, 5)
b = a.refine_names(..., 'channels', 'rows', 'columns')
print(b.shape, b.names)torch.Size([3, 5, 5]) ('channels', 'rows', 'columns')如果我们想在对命名的张量进行操作的函数之外使用张量,需要通过将这些张量重命名为None来删除它们的名称。下面让我们回到未命名维度的世界:
c = a.rename(None)
print(c.shape, c.names)torch.Size([3, 5, 5]) (None, None, None)五、张量的元素类型
使用标准Python数字类型可能不是最优的,原因如下:
1.Python中的数字是对象。例如,一个浮点数在计算机上可能只需要32位来表示,而Python会通过引用计数将它转换成一个完整的Python对象,等等。如果我们需要存储少量数值,采用装箱操作并不是什么问题,但如果我们需要存储数百万的数据,采用装箱会非常低效。
2.Python解释器与优化后的已编译的代码相比速度很慢。在大型数字类型的数据集合上执行数学运算,使用用编译过的更低级语言(如C语言)编写的优化代码可以快得多。
张量内的对象必须都是相同类型的数字,Pytorch必须跟踪这个数字类型。
①使用dtype指定数字类型,以下为dtype参数可能的取值:
1.torch.float32或torch.float: 32位浮点数
2.torch.float64或torch.double: 64位双精度浮点数
3.torch.float16或torch.half: 16位半精度浮点数
4.torch.int8 : 8位有符号整数
5.torch.uint8: 8位无符号整数
6.torch.int16或torch.short: 16位有符号整数
7.torch.int32或torch.int: 32位有符号整数
8.torch.int64或torch.long: 64位有符号整数
9.torch.bool: 布尔型
②管理张量的dtype属性
为了给张量分配一个正确的数字类型,我们可以指定适当的dtype作为构造函数的参数:
double_points = torch.ones(10, 2, dtype=torch.double)
short_points = torch.tensor([[1, 2], [3, 4]], dtype=torch.short)我们也可以使用相应的转换方法将张量创建函数的输出转换为正确的类型:
double_points = torch.ones(10, 2).double()
short_points = torch.tensor([[1, 2], [3, 4]]).short()或者用更新的方法:
short_point = double_points.to(torch.short)
double_point = short_point.to(torch.double)六、张量的API
至此,我们知道了什么是Pytorch张量以及它们在底层是如何工作的。现在我们有必要看看Pytorch提供的张量操作方法。
首先,关于张量以及张量之间的绝大多数操作(也可以成为张量对象的方法)都可以在torch模块中找到,如transpose()函数。
a = torch.ones(3, 2)
a_t = torch.transpose(a, 0, 1)
# transpose()函数也可以作为张量的一个方法
# a_t = a.transpose(0, 1)
print(a.shape, a_t.shape)torch.Size([3, 2]) torch.Size([2, 3])关于Pytorch张量API的在线文档见Pytorch官网。该文档内容详尽且结构组织得很好,对张量操作按组进行划分。
1.创建操作---用于构造张量的函数,如ones()和from_numpy()。
2.索引、切片、连接、转换操作---用于改变张量的形状、步长或内容的函数
3.数学操作---通过运算操作张量内容的函数:
1.逐点操作---abs() 、cos()
2.归约操作---mean()、std()、norm()
3.比较操作---equal()、max()
4.频谱操作---在频域中进行变换和操作的函数
5.其他操作---如作用于向量的特定函数cross()
4.随机采样---从概率分布中随机生成值的函数,如randn()和normal()
5.序列化---保存和加载张量的函数,如load()、save()