详解ENet | CPU可以实时的道路分割网络
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达前言
OpenCV DNN模块支持的图像语义分割网络FCN是基于VGG16作为基础网络,运行速度很慢,无法做到实时语义分割。2016年提出的ENet实时语义分割网络基于编码与解码的网络语义分割方式,类似UNet网络,通过构建自定义Block块,在Cityscapes, CamVid, SUN数据集上实现了性能与实时双提高。

ENet网络结构
作者从ResNet网络结构设计中收到启发,定义两个新的Block结构,如下:
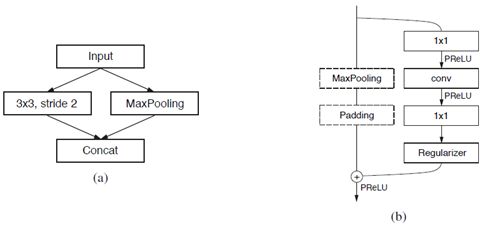
其中a是初始Block,非重叠2x2最大池化,左侧卷积步长为2,然后13个filters之连接合并,该结构注意是收到了Inception改进模型的启发。B是ENet的bottleneck模块,其中卷积可能是正常卷积、空洞卷积、反卷积,使用3x3或者5x5的filters,最终合并在一起是按空间位置相加。两个1x1的卷积分别用来降低维度与扩展,使用BN/Dropout正则化,PReLU非线性激活。最终的ENet网络模型结构如下:

其中stage2跟stage3结构相同,stage4跟stage5属于解码部分。
设计考量
常见的深度学习语义分割模型在下采样操作上的两个缺点:一是降低Feature Map的分辨率会导致图像空间信息损失,特别是图像边缘信息,这个对语义分割精度有明显影响;二是像素级别的语义分割网络要求输入跟输出的分辨率保持一致,这个就要求强的下采样跟强的上采样必须对称,这个增加了模型的计算与参数量。其中第一个问题在FCN与SegNet网络中通过在编码阶段叠加Feature Map与在解码阶段通过稀疏上采样来抑制,但是强的下采样依然对整个语义分割精度有伤害,要在设计时候适当的加以限制。
但是下采样同样可以帮助获得较大的感受野,区分不同的类别,作者发现空洞卷积在这个方面特别有帮助,ENet为了获得实时性能,采用了早期下采样策略来降低计算SegNet跟UNet都是对称的网络结构,ENet采用大的编码网络,小的解码网络实现的不对称结构,编码网络实现分类任务,解码网络主要是优化细节,更好的输出结果。
此外作者在设计过程中还考虑了非线性激活、空洞卷积、正则化方式的影响。
数据对比实验
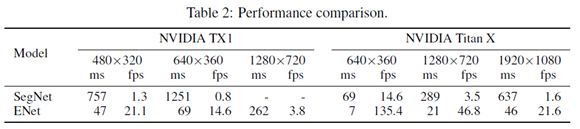
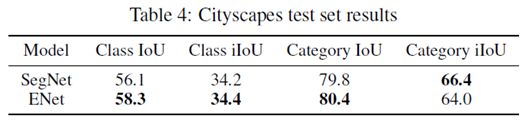
最终模型与SegNet的对比实验结果如下:
速度性能
参数总量与模型大小

精度对比
OpenCV DNN使用ENet道路分割
OpenCV DNN模块从OpenCV4.0版本开始支持ENet网络模型加载与解析,其中的道路分割模型可以从下面的地址下载:
https://github.com/e-lab/ENet-training在OpenCV DNN使用该模型时转换Blob输入相关参数信息如下:
mean: [0, 0, 0]
scale: 0.00392
width: 512
height: 256
rgb: true
classes: "enet-classes.txt"
其中分类文件enet-classes.txt可以从OpenCV的sample/data/dnn中发现。输出的数据格式为:Nx20xHxW,其中N=1表示每次输入的一张图像,20是基于Cityscapes数据集训练的20个类别标签,H跟W是输入时图像分辨率(512x256)。
01
最初版本代码实现
该代码实现是来自C++版本的翻译,完整的演示代码如下:
# load CNN model
bin_model = "D:/projects/models/enet/model-best.net";
net = cv.dnn.readNetFromTorch(bin_model)
# read input data
frame = cv.imread("D:/images/software.jpg");
blob = cv.dnn.blobFromImage(frame, 0.00392, (512, 256), (0, 0, 0), True, False);
cv.imshow("input", frame)
# Run a model
net.setInput(blob)
score = net.forward()
# Put efficiency information.
t, _ = net.getPerfProfile()
label = 'Inference time: %.2f ms' % (t * 1000.0 / cv.getTickFrequency())
print(score.shape)
# generate color table
color_lut = []
n, con, h, w = score.shape
for i in range(con):
b = np.random.randint(0, 256)
g = np.random.randint(0, 256)
r = np.random.randint(0, 256)
color_lut.append((b, g, r))
maxCl = np.zeros((h, w), dtype=np.int32);
maxVal = np.zeros((h, w), dtype=np.float32);
# find max score for 20 channels on pixel-wise
for i in range(con):
for row in range(h):
for col in range(w):
t = maxVal[row, col]
s = score[0, i, row, col]
if s > t:
maxVal[row, col] = s
maxCl[row, col] = i
# colorful the segmentation image
segm = np.zeros((h, w, 3), dtype=np.uint8)
for row in range(h):
for col in range(w):
index = maxCl[row, col]
segm[row, col] = color_lut[index]
h, w = frame.shape[:2]
segm = cv.resize(segm, (w, h), None, 0, 0, cv.INTER_NEAREST)
print(segm.shape, frame.shape)
frame = cv.addWeighted(frame, 0.2, segm, 0.8, 0.0)
cv.putText(frame, label, (0, 15), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0))
cv.imshow("ENet-Demo", frame)
cv.imwrite("D:/result.png", frame)
cv.waitKey(0)
cv.destroyAllWindows()总的来说比较啰嗦!

02
修改后代码熟实现
上面是我在2019年3月份时候在 OpenCV研习社 的代码分享,当时主要是把C++代码直接翻译过来,并没有太多考虑,今天又重新看了一下感觉自己写了点垃圾代码,所以重新整理了一下,把输出解析的部分基于Numpy跟OpenCV-Python函数做了简化,最终得到的代码如下:
1# load CNN model
2bin_model = "D:/projects/models/enet/model-best.net";
3net = cv.dnn.readNetFromTorch(bin_model)
4# read input data
5frame = cv.imread("D:/images/spacecity.png");
6blob = cv.dnn.blobFromImage(frame, 0.00392, (512, 256), (0, 0, 0), True, False);
7cv.imshow("input", frame)
8h, w, c = frame.shape
9
10# Run a model
11net.setInput(blob)
12score = net.forward()
13# Put efficiency information.
14t, _ = net.getPerfProfile()
15label = 'Inference time: %.2f ms' % (t * 1000.0 / cv.getTickFrequency())
16score = np.squeeze(score)
17score = score.transpose((1, 2, 0))
18score = np.argmax(score, 2)
19mask = np.uint8(score)
20mask = cv.cvtColor(mask, cv.COLOR_GRAY2BGR)
21cv.normalize(mask, mask, 0, 255, cv.NORM_MINMAX)
22cmask = cv.applyColorMap(mask, cv.COLORMAP_JET)
23cmask = cv.resize(cmask, (w, h))
24dst = cv.addWeighted(frame, 0.7, cmask, 0.3, 0)
25cv.putText(dst, label, (50, 50), cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 2)
26cv.imshow("dst", dst)
27cv.waitKey(0)运行结果如下:

总的执行时间也大大减少,主要去除了一些无谓的循环解析输出数据部分。CPU上10+FPS 应该没问题!实时get!
好消息!
小白学视觉知识星球
开始面向外开放啦

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~