某农商行用户画像项目——数据预处理部分
文章目录
- 一、项目背景及目的
-
- 1.1 项目背景
- 1.2 项目目的
- 1.3 数据说明
- 二、业务与数据理解
-
- 2.1 贷款、逾期数据
-
- 2.1.1 贷款数据
- 2.1.2 逾期数据
- 2.1.3 循环贷数据
- 2.2 征信数据
-
- 2.1.1 征信数据
- 2.1.2 征信查询数据
- 2.3 百融数据
-
- 2.1.1 征信数据
- 二、数据预处理
-
- 2.1 逾期数据处理
-
- 2.1.1 字段过滤
- 2.1.2 特征构建
- 2.1.3 数据去重
-
- 2.1.3.1 基于客户识别码去重
- 2.1.3.2 基于借据编号去重
- 2.1.4 缺失值填充
- 2.2 贷款数据处理
-
- 2.2.1 特征构建
- 2.2.2 数据过滤
-
- 2.2.2.1 基于逾期时间窗口过滤数据
- 2.2.2.2 基于业务实际过滤字段
- 2.2.2.3 过滤数据信息相似的字段
- 2.2.3 数据去重
-
- 2.2.3.1 整体去重
- 2.2.3.2 基于客户标识码去重
- 2.2.3.3 拼接去重数据
- 2.2.4 缺失值填充
-
- 2.2.4.1 基于征信数据填充缺失值
- 2.2.4.2 去重数据缺失值填充
- 2.3 征信数据处理
-
- 2.3.1 数据过滤
-
- 2.3.1.1 基于字段缺失率过滤
- 2.3.1.2 基于业务实际过滤字段
- 2.3.2 数据去重
-
- 2.3.2.1 整体去重
- 2.3.2.2 基于客户标识码去重
- 2.3.3 数据整合
- 2.4 百融数据处理
-
- 2.4.1 合并消费贷、房贷、循环贷数据
- 2.4.2 数据去重
- 2.4.3 数据过滤
- 2.4.4 特征构建
- 2.4.5 数据整合
一、项目背景及目的
1.1 项目背景
随着我国经济飞速发展,信用贷款业务逐渐发展,信贷客户的信用风险管理问题逐渐受到人们的广泛关注,传统的信用征信虽然能在一定程度上减少风险隐患,但在信息获取的及时性、全面性上明显存在短板。随着互联网迅猛发展,大数据、用户画像等新技术应用,为银行等财富管理机构识别优质客户和融通资金、降低信贷风险,开拓了新的思路和方法。
1.2 项目目的
本项目基于用户的贷款逾期数据、征信数据、消费金融数据,通过对数据的多维度、精细化、关联性的挖掘,来构建用户画像,并对用户分群,识别优质客户与高风险用户,为银行提供贷后本息催收过程的风险识别与控制。
1.3 数据说明
数据包含征信数据、百度金融数据以及用户在商行一段时间内的贷款逾期数据:
- 征信数据共63个字段约65000条记录
- 贷款数据共60个字段约61500条记录,逾期数据共13个字段约10000条记录,循环贷共66个字段约1700条记录。客户贷款信息表和逾期信息表都是借据层的原始数据,需要一定逻辑的计算汇总之后才是客户级的数据;循环贷为客户级数据,数据量较小,里面已经标注了好坏客户标签,无需再匹配。
- 百融数据包括房贷、消费贷以及循环贷数据,涉及领域丰富,内容多样化,但部分字段缺失严重。
项目分析中以贷款和逾期数据为主,其余数据为辅。
其中各类数据如图:
二、业务与数据理解
主要结合业务理解数据,并观察各字段数据的特征。
针对不同类型数据采取不同方法:
- 数值型:分布特征分析
- 类别型:占比分析
- 时间数据:时序分析(变化特征)
2.1 贷款、逾期数据
2.1.1 贷款数据
# 载入数据
loan_data = pd.read_excel('昆山农商行数据/贷款、逾期数据/1客户贷款信息宽表_20170510.xlsx',na_values=['(null)','无','未知'])
loan_data.head() # 查看前5行数据
loan_data.info() # 查看数据质量
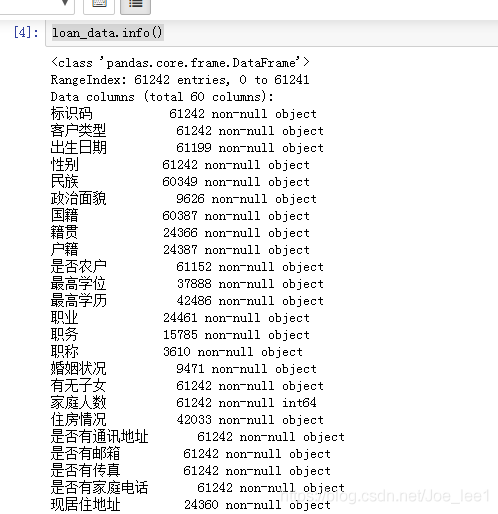
总共60个字段,籍贯、户籍等一些字段值缺失严重。
类别型数据分析(占比分析)示例:
# 绘制饼图
loan_data.groupby(loan_data['客户类型']).count().标识码.plot(kind='pie',figsize=(8,8),autopct='%1.1f%%')
时间型数据分析(时序分析)示例:
# 绘制折线图
loan_data.groupby(loan_data['申请时间']).count()['借据编号——唯一标识'].plot(figsize =(12,8))
# 贷款时间大部分是2015-2016年
数值型数据分析(分布分析)示例:
# 涉及金额的数据(二八定律——帕累托分布)取对数再看分布
sns.distplot(np.log(loan_data[loan_data['职业收入(元)']>0]['职业收入(元)'].dropna()), kde=False,color='blue',bins=200)
贷款数据唯一标志识别:
# 查看唯一标志
len(loan_data),len(loan_data['借据编号——唯一标识'].unique())
存在问题:'借据编号——唯一标识’字段存在重复值,即数据说明中提到的客户贷款信息表是借据层的原始数据,需要一定逻辑的计算汇总之后才是客户级的数据。通过统计同一借据编号下出现多个值的字段来分析具体原因。
# 分析"借据编号——唯一标识"不唯一的原因
from collections import defaultdict
from tqdm import tqdm
d_result_dict = defaultdict(int)
for d_id in tqdm(loads_duplicated_data['借据编号——唯一标识'].unique()):
d_data = loan_data[loan_data['借据编号——唯一标识'] == d_id]
for d_data_col in d_data.columns:
if len(d_data[d_data_col].unique())>1:
d_result_dict[d_data_col] += 1
d_result_dict
![]()
结论: 根据分析结果,借据编号不唯一的原因是同一个借据编号,由于抵押物认定价值的变化,银行更新数据导致的。
2.1.2 逾期数据
overdue_data = pd.read_excel('昆山农商行数据/贷款、逾期数据/2客户逾期信息宽表.xlsx', na_values=['(null)','无','未知'])
overdue_data.head()
overdue_data.info()

# 查看有多少个借据存在逾期现象
len(overdue_data),len(overdue_data['借据编号'].unique())
![]()
逾期数据量较少,其中应还本金、应还利息等几个字段缺失值较多。在总共6万余个借据中,有3745个借据出现过逾期现象。
时间型数据分析(时序分析):
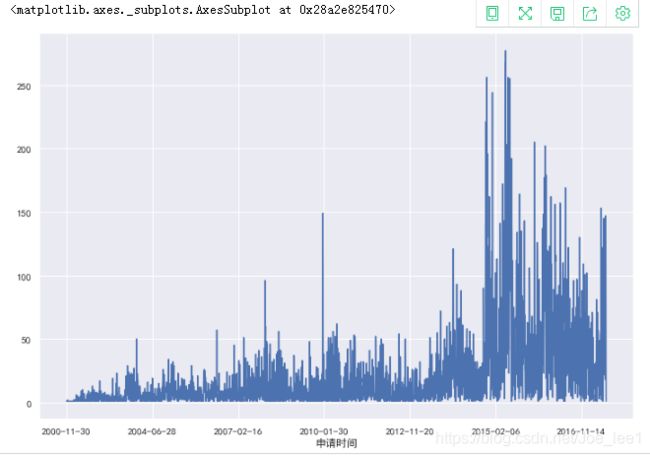
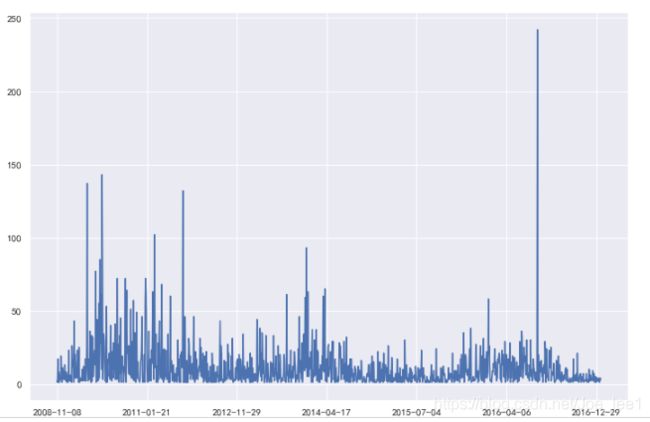
可以发现,与贷款数据中时序分析结果差异较大,贷款数据中借据申请时间大多集中在2015-2016年(近期),而逾期数据中借据大多为申请时间较早,2008-2011年期间多。这个现象很容易从业务场景去理解,假设某个人每年的逾期概率相同,时间周期越长,其发生逾期的概率越高:1-(1-p)^n
# 看一下逾期时间的分布
overdue_data.groupby(overdue_data['逾期时间']).count().借据编号.plot(figsize =(12,8))
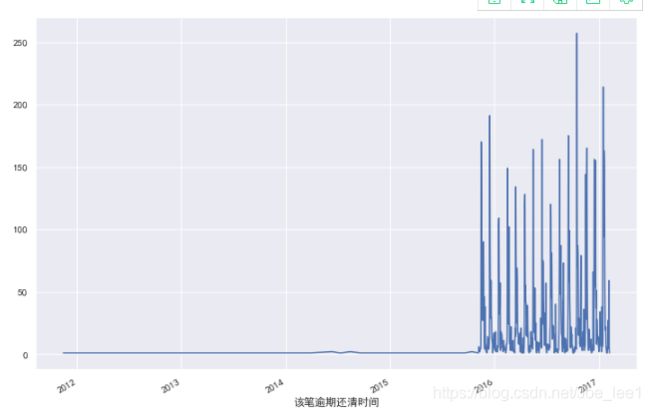
结果表明,逾期时间大多集中在2016-2017年,结合业务可以发现,早期的逾期事件都已经由平台处理掉了。
贷款数据唯一标志识别:
# 查看唯一标志
len(overdue_data),len(overdue_data['借据编号'].unique())
存在问题:'借据编号——唯一标识’字段存在重复值,与贷款数据一致,通过统计同一借据编号下出现多个值的字段来分析具体原因。

结论: 根据分析结果,借据编号不唯一的原因是同一个借据编号,可能因为多次还款或反复逾期产生多条数据,导致不唯一。
2.1.3 循环贷数据
查看循环贷数据与贷款数据关联性:
# 查看循环贷数据与贷款数据关联性
re_loan_data = pd.read_excel('昆山农商行数据/贷款、逾期数据/3循环贷宽表.xlsx', na_values=['(null)','无','未知'])
loan_data_merge = pd.merge(loan_data,re_loan_data, left_on=['标识码'], right_on=['CUS_ID'], how='inner')
len(loan_data['标识码'].unique()), len(re_loan_data['CUS_ID'].unique()), len(loan_data_merge['标识码'].unique())
![]()
结论: 循环贷对应的1692个客户均能匹配到贷款数据中,也就是说贷款数据已经包含了循环贷数据信息,因此舍弃该数据。
2.2 征信数据
2.1.1 征信数据
# 载入数据
credit_data = pd.read_excel('昆山农商行数据/昆山农商行征信数据/征信数据201704前.xlsx', na_values=['(null)','缺失','--'])
credit_data.head() # 查看前5行数据
credit_data.info() # 查看数据质量

# 查看唯一标志
len(credit_data),len(credit_data['客户标识码'].unique())
![]()
征信数据存在的问题:
- 征信数据以记录客户违约记录为主,所以大量字段为空值
- 数据缺乏时间戳,且信息冗余度较高(一个客户具有多条征信数据)
因此数据预处理时考虑针对同一个客户直接通过取median的方式对数值型字段去重、取众数对类别型变量去重。
2.1.2 征信查询数据
# 数据读取
credit_query_data = pd.read_excel('昆山农商行数据/昆山农商行征信数据/征信查询201704前.xlsx', na_values=['(null)','缺失','--'])
credit_query_data.head()
credit_query_data.info()

# 查看数据时间跨度
credit_query_data['id'] = credit_query_data.index
credit_query_data.groupby(pd.to_datetime(credit_query_data['查询日期']).dt.date).count().id.plot(figsize =(12,8))
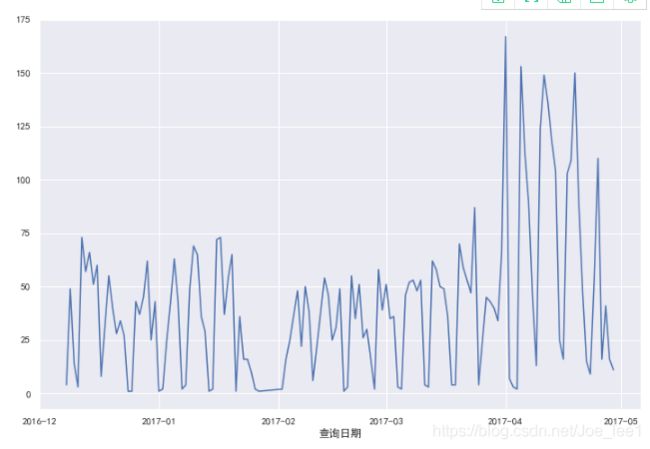
数据存在的问题: 1、缺少单次查询的唯一标识,无法与其余数据匹配;2、时间跨度为2016.12-2017.05,和贷款逾期时间重合较少。综合以上原因,舍弃此数据。
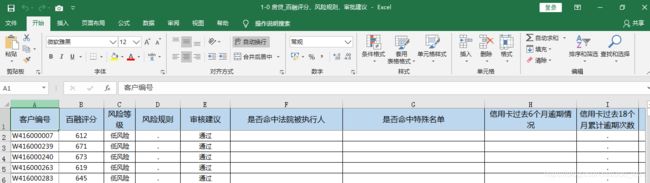
2.3 百融数据
2.1.1 征信数据
# 数据读取
bairong_data10 = pd.read_excel('昆山农商行数据/百融数据/1-0 房贷_百融评分、风险规则、审批建议.xlsx', na_values=['.'])
# 数据读取
bairong_data20 = pd.read_excel('昆山农商行数据/百融数据/2-0 消费贷_百融评分、风险规则、审批建议.xlsx', na_values=['.'])
# 数据读取
bairong_data30 = pd.read_excel('昆山农商行数据/百融数据/3-0 循环贷_百融评分、风险规则、审批建议.xlsx', na_values=['.'])
分别与贷款数据进行连接,查看有多少数据能够匹配到贷款数据:
# 数据连接示例:
loan_data_merge = pd.merge(loan_data,bairong_data10, left_on=['标识码'], right_on=['客户编号'], how='inner')
len(loan_data['标识码'].unique()), len(bairong_data10['客户编号'].unique()), len(loan_data_merge['标识码'].unique())
结论: 房贷数据有896个客户均能匹配到贷款数据中;消费贷数据有947个客户均能匹配到贷款数据中;循环贷数据有1200个客户均能匹配到贷款数据中。
数据关联性分析:
bairong_data_merge1020 = pd.merge(bairong_data10,bairong_data20, left_on=['客户编号'], right_on=['客户编号'], how='inner')
bairong_data_merge1030 = pd.merge(bairong_data10,bairong_data30, left_on=['客户编号'], right_on=['客户编号'], how='inner')
bairong_data_merge2030 = pd.merge(bairong_data20,bairong_data30, left_on=['客户编号'], right_on=['客户编号'], how='inner')
len(bairong_data_merge1020['客户编号'].unique()), len(bairong_data_merge1030['客户编号'].unique()), len(bairong_data_merge2030['客户编号'].unique())
![]()
结果显示:三份数据对应客户编号完全独立。
百融数据存在的问题: 数据涉及领域丰富,内容多样化,但命中率偏低,且部分字段缺失严重。因此在应用时选择命中率高、并且字段完整的部分用于数据维度补齐。
二、数据预处理
包括过滤、新建、去重、补缺几个步骤。
过滤:初步过滤掉缺失率大约90%的字段以及从业务角度上与是否逾期无关的字段
新建:基于原始数据构建一些能够用于预测是否逾期的新字段/特征
去重:数据整体去重以及基于客户识别码(唯一标识)去重
补缺:根据业务实际来对缺失值进行填充
2.1 逾期数据处理
2.1.1 字段过滤
调用missingno模块的matrix函数来对数据缺失概览:
import missingno
missingno.matrix(overdue_data)

# 按缺失率排序:从高到低
check_null = overdue_data.isnull().sum(axis = 0).sort_values(ascending = False)/float(len(overdue_data))
check_null[check_null > 0][:20]

逾期数据不含缺失率高于90%的字段,且数据包含的字段都可被使用,因此不采取过滤操作。
2.1.2 特征构建
基于原始字段构造新特征:逾期时长、本金未还清、利息未还清、本金利息都未还清、逾期金额、逾期次数。
overdue_data['逾期时长'] = (overdue_data['该笔逾期还清时间']-overdue_data['逾期时间']).dt.days
overdue_data['本金未还清'] = overdue_data['应还本金'] != overdue_data['已还逾期本金金额']
overdue_data['利息未还清'] = overdue_data['应还利息'] != overdue_data['已还逾期利息金额']
overdue_data['本金利息都未还清'] = (overdue_data['应还利息'] != overdue_data['已还逾期利息金额']) & (overdue_data['应还本金'] != overdue_data['已还逾期本金金额'])
overdue_data['逾期金额'] = overdue_data['应还本金'] - overdue_data['已还逾期本金金额'] + overdue_data['应还利息'] - overdue_data['已还逾期利息金额']
overdue_data_clean['逾期次数'] = overdue_data[['借据编号','标识码']].groupby('借据编号').count().reset_index()['标识码']
overdue_data[['借据编号', '逾期时长', '本金未还清', '利息未还清', '本金利息都未还清', '逾期金额']].head()

2.1.3 数据去重
2.1.3.1 基于客户识别码去重
# 整体去重
overdue_data_clean = overdue_data.drop_duplicates()
2.1.3.2 基于借据编号去重
# 按照借据编号去重
overdue_data_clean = overdue_data_clean[['借据编号', '逾期时长', '本金未还清', '利息未还清', '本金利息都未还清', '逾期金额', '逾期次数']].groupby('借据编号').agg({'逾期时长':'sum','本金未还清':'sum','利息未还清':'sum','本金利息都未还清':'sum','逾期金额':'sum','逾期时长':np.max}).reset_index()

data_large = pd.merge(loan_data, overdue_data_clean, left_on=['借据编号——唯一标识'], right_on=['借据编号'], how='left')
len(loan_data), len(overdue_data_clean), len(data_large)
![]()
去重的逾期数据中有3745个借据编号能连接到贷款数据中。
2.1.4 缺失值填充
# 缺失值填补,根据业务实际都填充0值
data_large['逾期时长'].fillna(0, inplace = True)
data_large['本金未还清'].fillna(0, inplace = True)
data_large['利息未还清'].fillna(0, inplace = True)
data_large['本金利息都未还清'].fillna(0, inplace = True)
data_large['逾期金额'].fillna(0, inplace = True)
data_large['逾期次数'].fillna(0, inplace = True)
2.2 贷款数据处理
2.2.1 特征构建
贷款数据的特征构建包括:
- 去重前,基于原始字段构造理论贷款结束时间、抵押物溢出价值、抵押物溢出比例;
- 在去重过程中,基于原始字段构造_sum、_std等字段(见去重过程);
- 去重后,基于去重数据构造信息透明度字段
去重前,构造理论贷款结束时间、抵押物溢出价值、抵押物溢出比例:
# 理论贷款结束时间
data_large['理论贷款结束时间'] = pd.to_datetime(data_large['放款时间']) + pd.to_timedelta(data_large['贷款期限'], unit='D')
# 抵押物溢出价值
data_large['抵押物溢出价值'] = data_large['抵押物认定价值'] - data_large['合同额度(元)']
# 抵押物溢出比例
data_large['抵押物溢出比例'] = data_large['抵押物认定价值'] / data_large['合同额度(元)'] - 1

数据去重后构造信息透明度字段:
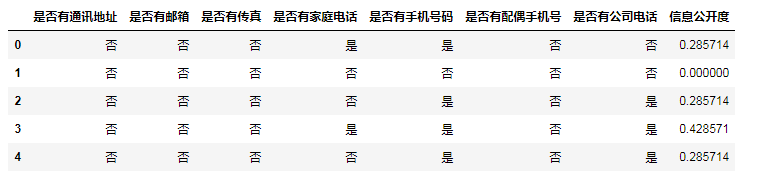
# 信息透明度——基于是否有通讯地址、电话号码等数据构建
Infoclear_cols = [col for col in data_clean.columns if '是否有' in col]
data_clean['信息公开度'] = data_clean[Infoclear_cols].replace('是', 1).replace('否', 0).sum(axis=1)/len(Infoclear_cols)
2.2.2 数据过滤
包括:
- 基于逾期时间窗口过滤时间窗口之外的数据
- 基于业务实际过滤不重要的字段
- 过滤数据信息相似的字段
2.2.2.1 基于逾期时间窗口过滤数据
逾期数据时间窗口为2015.11-2017.1,因此筛选在2016年存在完整还款周期的贷款数据,即申请时间在2016年1月1日之前,理论贷款结束时间在2016年12月31日之后。
data_large_clean = data_large[(data_large['申请时间'] < '2016-01-01') & (data_large['理论贷款结束时间'] > '2016-12-31')]
2.2.2.2 基于业务实际过滤字段
data_large_clean.drop(['公司性质', '公司地址', '本单位入职时间', '借据编号', '现居住地址', '是否我行职工','户籍', '是否我行股东', '职业', ], axis=1, inplace = True)
2.2.2.3 过滤数据信息相似的字段
# 最高学历信息量完全被最高学位覆盖,可考虑删除
data_large_clean.drop(['最高学历'], axis=1, inplace = True)
2.2.3 数据去重
2.2.3.1 整体去重
# 整体去重
data_large_clean = data_large_clean.drop_duplicates()
2.2.3.2 基于客户标识码去重
首先将字段分类,分为去重取众数(类别型变量)、取均值、取中位数、求和、求标准差以及求最大值的字段列表,再分别进行相应去重操作。
mode_cols = ['客户类型', '出生日期', '性别', '民族', '政治面貌', '国籍', '籍贯', '是否农户', '最高学位', '最高学历', '职务', '婚姻状况', '有无子女', '家庭人数', '住房情况', '是否有通讯地址', '是否有邮箱', '是否有传真', '是否有家庭电话', '是否有手机号码', '是否有配偶手机号', '行业类别', '是否有公司电话', '还款来源', '计息周期', '还款方式','担保方式', '贷款形式','产品名称']
median_cols = ['贷款期限', '抵质押率', '逾期时长', '逾期金额', '逾期次数']
mean_cols = ['职业收入(元)', '抵押物溢出价值', '抵押物溢出比例', '合同额度(元)','贷款剩余本金(元)', '正常执行利率(年)']
sum_cols = ['贷款期限', '逾期时长', '本金未还清', '利息未还清', '本金利息都未还清', '逾期金额']
std_cols = ['职业收入(元)', '贷款期限', '抵押物溢出价值', '合同额度(元)','贷款剩余本金(元)', '正常执行利率(年)', '逾期时长', '逾期金额']
max_cols = ['贷款五级分类状态']
取众数字段:
在Python中,使用scipy.stats.mode函数寻找数组或者矩阵每行/每列中最常出现成员[0][0]以及出现的次数 [1][0]。
from scipy import stats
data_clean_mode = data_large_clean[mode_cols+['借据编号——唯一标识','标识码']].drop_duplicates()
data_clean_mode = data_clean_mode.groupby('标识码').agg(lambda x: stats.mode(x)[0][0])#.rename(columns={i:i+'_mode' for i in mode_cols})
data_clean_mode.head()

取均值字段:
data_clean_mean = data_large_clean[mean_cols+['借据编号——唯一标识','标识码']].drop_duplicates()
data_clean_mean = data_clean_mean.groupby('标识码').mean().rename(columns={i:i+'_mean' for i in mean_cols})
data_clean_mean.head()
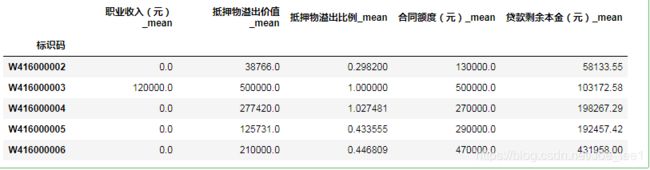
取中位数字段:
data_clean_median = data_large_clean[median_cols+['借据编号——唯一标识','标识码']].drop_duplicates()
data_clean_median = data_clean_median.groupby('标识码').median().rename(columns={i:i+'_median' for i in median_cols})
data_clean_median.head()
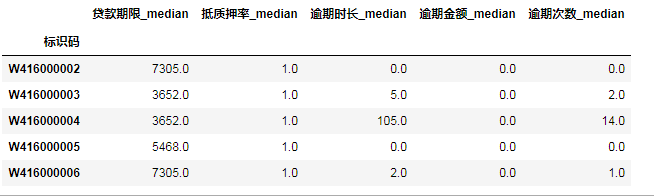
求和字段:
data_clean_sum = data_large_clean[sum_cols+['借据编号——唯一标识','标识码']].drop_duplicates()
data_clean_sum = data_clean_sum.groupby('标识码').sum().rename(columns={i:i+'_sum' for i in sum_cols})
data_clean_sum.head()
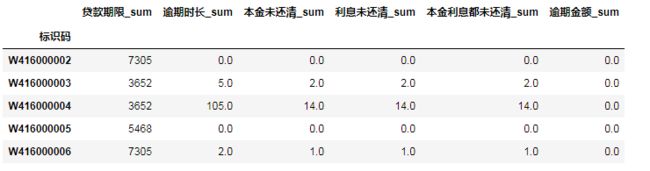
求标准差字段:
data_clean_std = data_large_clean[std_cols+['借据编号——唯一标识','标识码']].drop_duplicates()
data_clean_std = data_clean_std.groupby('标识码').std().rename(columns={i:i+'_std' for i in std_cols})
data_clean_std.head()
取最大值字段:
level5_mapping = {"正常": 1, "可疑": 2, "关注": 3, "次级": 4, "损失": 5}
data_large_clean['贷款五级分类'] = data_large_clean['贷款五级分类状态'].map(level5_mapping)
data_clean_max = data_large_clean[['标识码', '贷款五级分类']].groupby('标识码').max()
data_clean_max.head()

计数字段:构造贷款次数
data_clean_count = data_large_clean[['标识码', '借据编号——唯一标识']].groupby('标识码').count()
data_clean_count = data_clean_count.rename(columns={'借据编号——唯一标识':'贷款次数'})
data_clean_count.head()

2.2.3.3 拼接去重数据
data_clean = pd.concat([data_clean_mode, data_clean_mean, data_clean_median, data_clean_sum, data_clean_std, data_clean_max, data_clean_count], axis=1).reset_index()
data_clean.head()
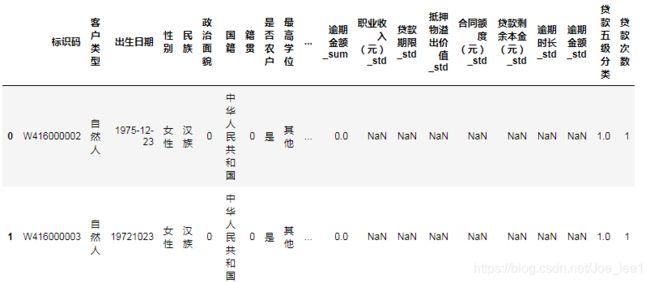
2.2.4 缺失值填充
2.2.4.1 基于征信数据填充缺失值
在数据去重前进行该操作,利用征信数据相同的字段来填充贷款数据,可是标识码作为连接键。
# 通过数据B的相似字段填补数据A的缺失
def fillna_by_replace(DataA, DataB, colA, colB, indexA, indexB):
fillna_times = 0
fillna_before = DataA[colA].isnull().sum()
for index in tqdm(DataB[~DataB[colB].isnull()][indexB]):
if DataA[DataA[indexA] == index][colA].isnull().sum() > 0:
DataA.loc[DataA[indexA] == index, colA] = DataB[DataB[indexB] == index][colB].values[0]
fillna_times += 1
fillna_after = DataA[colA].isnull().sum()
print('字段 '+str(colA)+' 填补次数:'+ str(fillna_times) + ' 缺失补齐数:'+ str(fillna_before-fillna_after))
fillna_by_replace(data_large_clean, credit_data_obj, '行业类别', '行业', '标识码', '客户标识码')
fillna_by_replace(data_large_clean, credit_data_obj, '职务', '职务', '标识码', '客户标识码')

结论:实现了少量缺失数据填充。
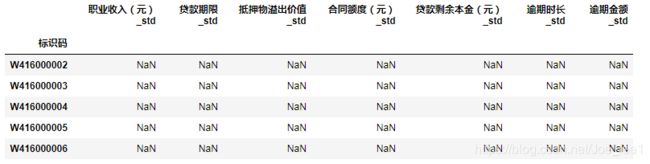
2.2.4.2 去重数据缺失值填充
data_clean["抵押物溢出价值_std"].fillna(0, inplace=True)
data_clean["逾期金额_std"].fillna(0, inplace=True)
data_clean["逾期时长_std"].fillna(0, inplace=True)
data_clean["贷款剩余本金(元)_std"].fillna(0, inplace=True)
data_clean["合同额度(元)_std"].fillna(0, inplace=True)
data_clean["贷款期限_std"].fillna(0, inplace=True)
data_clean["职业收入(元)_std"].fillna(0, inplace=True)
data_clean["抵押物溢出比例_mean"].fillna(data_clean["抵押物溢出比例_mean"].mean(), inplace=True)
data_clean["抵押物溢出价值_mean"].fillna(data_clean["抵押物溢出价值_mean"].mean(), inplace=True)
data_clean["抵质押率_median"].fillna(data_clean["抵质押率_median"].median(), inplace=True)
missingno.matrix(data_clean)

# 将处理好的贷款逾期数据存储
data_clean.to_excel('input/data_clean.xlsx')
2.3 征信数据处理
2.3.1 数据过滤
2.3.1.1 基于字段缺失率过滤
missingno.matrix(credit_data)

# 过滤掉缺失率大于90%的字段
credit_data_clean = credit_data.dropna(thresh = len(credit_data)*0.1, axis =1)
2.3.1.2 基于业务实际过滤字段
credit_data_clean.drop(['证件类型','职业', '行业', '职务', '职称', '进入本单位年份'], axis = 1, inplace = True)
# 按缺失率排序:从高到低
check_null = credit_data_clean.isnull().sum(axis = 0).sort_values(ascending = False)/float(len(credit_data_clean))
check_null[check_null > 0][:20]

2.3.2 数据去重
2.3.2.1 整体去重
credit_data_clean = credit_data_clean.drop_duplicates()
2.3.2.2 基于客户标识码去重
# 类别型变量取众数
object_cols = [c for c in credit_data_clean.columns if credit_data_clean[c].dtypes == object]
credit_data_clean_obj = credit_data_clean[object_cols].groupby('客户标识码').agg(lambda x: stats.mode(x)[0][0]).reset_index()
# 数值型变量取中位数
credit_data_clean_num = credit_data_clean.groupby('客户标识码').median().reset_index()
# 将数据拼接
data_clean = pd.concat([credit_data_clean_obj, credit_data_clean_num], axis=1).reset_index()
# 将处理好的征信数据存储
data_clean.to_excel('input/credit_data.xlsx')
2.3.3 数据整合
目的:查看处理好的征信数据与贷款逾期数据按照客户标识码的重叠数量
data_merge_credit = pd.merge(data_clean,credit_data_clean_median, left_on=['标识码'], right_on=['客户标识码'], how='inner')
len(data_merge_credit),len(data_merge_credit['标识码'].unique())
![]()
结果显示:征信数据与贷款数据仅有446条数据重叠。
2.4 百融数据处理
2.4.1 合并消费贷、房贷、循环贷数据
file_type_dict = {1:'房贷', 2:'消费贷', 3:'循环贷'}
names_dict = {0:'百融评分、风险规则、审批建议.xlsx', 1:'用户信用评估产品.xlsx', 2:'反欺诈产品.xlsx',
3:'支付消费.xlsx', 4:'手机在网时长.xlsx', 5:'手机在网状态.xlsx', # 6:'身份证二要素.xlsx', 7:'银行卡四要素.xlsx',
8:'手机三要素.xlsx', 9:'个人对外投资.xlsx', # 10:'个人不良信息.xlsx',
11:'法院执行人.xlsx', 12:'移动消费档次.xlsx'}
def concat_df_in_dict(dicts_df):
# 拼接dict中的df
return pd.concat([v for v in dicts_df.values()])
def data_cooked_for_bairong(names_dict, file_type_dict):
result = pd.DataFrame()
for k_n, v_n in tqdm(names_dict.items()):
tmp_df_dict = {}
for k_f, v_f in file_type_dict.items():
try:
file_name = '昆山农商行数据/百融数据/'+str(k_f)+'-'+str(k_n)+' '+v_f+'_'+v_n
tmp_df = pd.read_excel(file_name, na_values=['.','#N/A','缺失']).rename(columns={'客户标识码':'客户编号'})\
.rename(columns={'cus_num':'客户编号'}).rename(columns={'number':'客户编号'}) # 统一唯一编号
except Exception as e:
print(e)
tmp_df_clean = tmp_df.dropna(thresh = len(tmp_df)*0.1, axis =1) # 先过滤掉缺失大于90%的列
if len(tmp_df_clean) != 0:
tmp_df_clean = tmp_df_clean.groupby('客户编号').first().reset_index()
tmp_df_dict[k_f] = tmp_df_clean
if len(result) == 0:
result = concat_df_in_dict(tmp_df_dict)
else:
result = pd.merge(result, concat_df_in_dict(tmp_df_dict), on='客户编号', how='left', suffixes=('_保留值','_删除值'))
return result
bairong_data = data_cooked_for_bairong(names_dict, file_type_dict)
bairong_data.head()
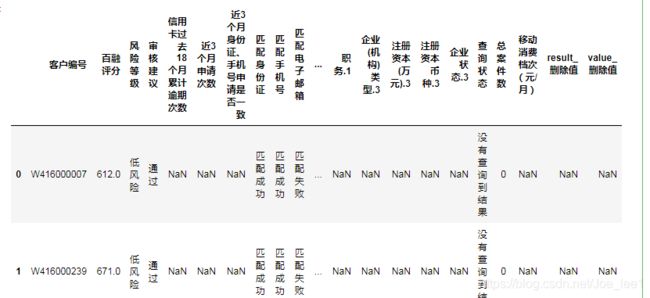
2.4.2 数据去重
# 去除重复行
bairong_data_clean = bairong_data_clean.drop_duplicates()
# 去除重复列
bairong_data_clean = bairong_data_clean.loc[:,~bairong_data_clean.columns.duplicated()]
2.4.3 数据过滤
过滤缺失率大于90%的列:
bairong_data_clean = bairong_data.dropna(thresh = len(bairong_data)*0.1, axis =1)
用户储蓄卡、信用卡消费数据、收入数据等颗粒度太细,需要删除一部分列:
del_months = ['第1', '第2', '第3', '第4', '第5', '第6', '7-9', '10-12','13-15']
del_cols = []
for month_str in del_months:
del_cols.append('储蓄卡过去'+month_str+'个月末可用余额')
del_cols.append('储蓄卡过去'+month_str+'个月支出金额')
del_cols.append('储蓄卡过去'+month_str+'个月支出笔数')
del_cols.append('储蓄卡过去'+month_str+'个月投资金额')
del_cols.append('储蓄卡过去'+month_str+'个月还贷金额')
del_cols.append('储蓄卡过去'+month_str+'个月收入金额')
del_cols.append('储蓄卡过去'+month_str+'个月收入笔数')
del_cols.append('信用卡过去'+month_str+'个月支出金额')
del_cols.append('信用卡过去'+month_str+'个月支出笔数')
del_cols.append('信用卡过去'+month_str+'个月取现金额')
del_cols.append('信用卡过去'+month_str+'个月收入金额')
del_cols.append('信用卡过去'+month_str+'个月收入笔数')
del_cols.append('过去'+month_str+'个月是否按时还贷')
del_cols.append('过去'+month_str+'个月贷款金额')
del_cols.append('过去'+month_str+'个月个人消费金额')
del_cols.append('过去'+month_str+'个月单笔最大入账金额')
bairong_data_clean.drop(del_cols, axis = 1, inplace = True)
在合并数据时,产生了一部分多余的字段,需要将其删除:
reserve_cols = []
delete_cols = []
for col in list(bairong_data_clean.columns):
if '保留值' in col:
reserve_cols.append(col)
elif '删除值' in col or '.1' in col or '.2' in col:
delete_cols.append(col)
# 初步删除重复列
for reserve_col in reserve_cols:
if '删除值' in reserve_col:
bairong_data_clean[reserve_col.replace('保留值', '删除值')].fillna(bairong_data_clean[reserve_col])
elif '.1' in reserve_col:
bairong_data_clean[reserve_col.replace('.1', '')].fillna(bairong_data_clean[reserve_col])
elif '.2' in reserve_col:
bairong_data_clean[reserve_col.replace('.2', '')].fillna(bairong_data_clean[reserve_col])
bairong_data_clean.drop(delete_cols, axis = 1, inplace = True)
rename_dict = {'运营商类型 _保留值':'运营商类型',
'空:无结果\n1:[0,6)\n2:[6,12)\n3:[12,24)\n4:[24,+)\n单位:月_保留值':'手机在网时长',
'value_保留值':'移动消费档次'}
bairong_data_clean = bairong_data_clean.rename(columns=rename_dict)
基于业务实际过滤字段:
delete_cols2 = [ '匹配身份证', '匹配手机号', '匹配电子邮箱', '匹配关健值', '匹配家庭座机','匹配公司座机', '匹配姓名', 'operation_保留值', '电信;联通;移动;其他运营商,如电信70', '运营商类型','result_保留值','运营商代码', '查询结果代码', '状态编号', '手机三要素查询产品输出标识', '返回三要素验证结果', 'flag_telCheck', '是否查询到结果', '运营商编号', '查询结果', '状态码描述','查询状态','货币单位', '注册资本币种']
bairong_data_clean.drop(delete_cols2, axis = 1, inplace = True)
2.4.4 特征构建
# 构建关联度(次数)
connected_cols = ['关联身份证个数', '关联手机号个数','关联电子邮箱数', '关联姓名数', '关联座机数', '关联地址数']
bairong_data_clean['关联度'] = bairong_data_clean[connected_cols].sum(axis=1)/len(Infoclear_cols)
bairong_data_clean.drop(connected_cols, axis = 1, inplace = True)
# 将处理好的百融数据存储
bairong_data_clean.to_excel('input/bairong_data.xlsx')
2.4.5 数据整合
目的:查看处理好的百融数据与贷款逾期数据按照客户标识码的重叠数量
data_merge_bairong = pd.merge(data_clean,bairong_data_clean, left_on=['标识码'], right_on=['客户编号'], how='inner')
len(data_merge_bairong),len(data_merge_bairong['标识码'].unique())
结果显示:百融数据与贷款数据仅有927条数据重叠。
- 征信数据、百融数据的缺失值填充放在模型构建部分处理。