图文融合微博情感分析(小记)
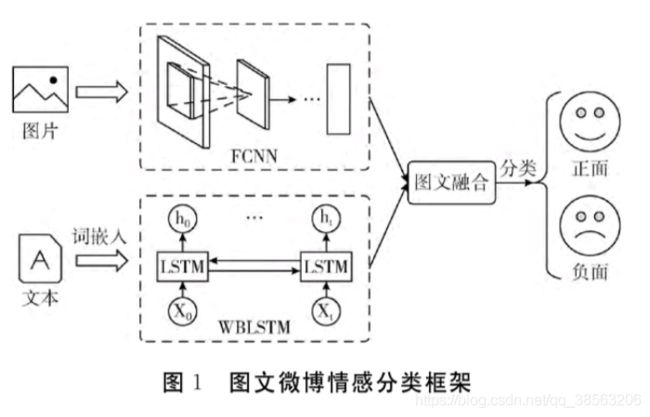
单独基于文本和图片方法,不能充分挖掘微博用户情感问题,提出图文融合的微博情感分析方法。对大规模图片数据集上预训练的CNN模型参数进行迁移,以微调的方式训练图片情感分类模型FCNN;训练词向量输入可提取文本语义单元上下文特征的双向LSTM中,训练文本情感分类模型WBLSTM;根据late fusion的模型融合思想,设计模型融合公式融合FCNN和WBLSTM模型,进行图文融合的微博情感分析。
目前图文融合的微博情感分析存在问题:
图片的低层特征和中层属性并不能高度抽象图片的情感,导致图片情感分类效果不佳。
微博文本简短而不规范,词袋模型等文本表示方法丢失重要的语义信息。传统的机器学习难以捕捉文本的上下文信息。
现有的图文融合方法只是简单的将文本特征与图片特征拼接,未充分考虑文本与图片之间的互补作用。
文章所应用的图文融合微博情感分析方法:该方法首先以参数迁移的方式初始化CNN模型,并对参数迁移后的CNN模型微调训练得到图片情感分类模型FCNN(fine-tuned CNN);然后利用词嵌入技术将文本表示为数值稠密的词向量,输入BILSTM之中训练得到文本情感分类模型WBLSTM(word-embedding bidi-rectional LSTM),最后设计模型融合公式融合FCNN和WBLSTM。
FCNN模型结构:

网络结构函数参数叙述:


LSTM网络结构叙述:

LSTM处理文本序列仅仅对序列进行正向特征提取,未能充分考虑文本序列反向的上下文特征,在权值共享的双向长短期记忆神经网络基础上,提出WBLSTM。
WBLSTM模型结构:



为防止FCNN模型因数据量太少而在训练过程中出现过拟合的现象,提高训练模型的泛化能力和特征表达能力。使用社交图片数据集对参数迁移之后的模型进行微调训练。YOU等人在Flickr和Instagram上用8类情感词(开心、赞叹、满足、激动、生气、厌恶、害怕、悲伤)进行图片搜索,将搜索到的图片用对应的情感关键词作标注,得到弱标注图片数据集。继而通过亚马逊机械土耳其人(AMT)平台对弱标注图片数据集进行人工标注:每张图片5个人投票,至少三个人投了相同的对应的情感关键词,就把它挑选出来,以此构建人工标注的图片数据集。
Flickr:雅虎旗下图片分享网站。为一家提供免费及付费数位照片储存、分享方案之线上服务,也提供网络社群服务的平台。
Instagram:Facebook公司旗下社交应用,Instagram(照片墙)是一款运行在移动端上的社交应用,以一种快速、美妙和有趣的方式将你随时抓拍下的图片彼此分享。
一般认为,图像级的标注是弱标注(例如图像分类的类别标注),像素级的标注是强标注(例如分割标注的mask标注),对于普通的分割任务来说:数据是图像,标注是mask,这属于完全监督问题Supervised;如果标注是annotations或者图像级标注,这属于弱监督问题Weakly-supervised;如果标注只有少部分是mask,剩余是annotations或者图像级标注,这属于半监督问题Semi-supervised。

同样为防止WBLSTM模型因数据量太小而出现过拟合现象,用微博文本数据集进行训练集扩充,该数据集是NLPCC2013和NLP2014提供的微博情感分析数据集,整理得到正面微博文本6908条,负面微博文本5980条。
图文微博数据集为网上爬取的新浪微博图文数据集。爬虫爬取新浪微博数据,进行去广告、新闻的预处理操作。人工标注,3人以上为情感倾向标签。

微博图片情感分类实验:
模型参数设置及训练:batch=64,激活函数:Relu,全连接层采用Dropout防止过拟合,Dropout设为0.5。
FCNN模型包含大量网络参数,需要巨大的图片数据集,人工标注代价昂贵,图片情感分析领域还没有人工标注的大型图片数据集。
解决问题:借鉴迁移学习的思想,通过参数迁移方式将相似领域(图形分类)的知识应用到目标领域(图片情感分类)当中,提高目标领域模型的泛化能力,加快收敛速度,降低过拟合概率。
具体做法:将大型图片数据集ImageNet上训练的CaffeNet图像分类模型全连接层Fc8之前网络层的参数迁移至FCNN模型当中,原来1000个神经元的Fc8层修改为两个神经元,并且以0.01偏差的零均值高斯分布初始化FCNN模型Fc8层的网络参数。
参数迁移方式初始化FCNN模型网络参数之后,进行微调训练。使用社交图片数据集和微博图片数据集对其进行两个阶段的微调训练。
第一阶段社交图片数据集,lr=0.01,动量0.9,随机梯度下降算法更新网络参数。
第二阶段微调训练基于第一阶段,迁移第一阶段已训练模型的网络参数来初始化第二阶段模型的网络参数,lr=0.001,动量0.9,随机梯度下降算法更新网络参数。模型的训练和测试在深度学习框架Caffe上进行。
ImageNet:ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库。超过1400万的图像URL被ImageNet手动注释,以指示图片中的对象;在至少一百万个图像中,还提供了边界框。ImageNet包含2万多个类别;ImageNet就像一个网络一样,拥有多个Node(节点)。每一个node相当于一个item或者subcategory。据官网消息,一个node含有至少500个对应物体的可供训练的图片/图像。它实际上就是一个巨大的可供图像/视觉训练的图片库。ImageNet的结构基本上是金字塔型:目录->子目录->图片集。
Caffe:Caffe,全称Convolutional Architecture for Fast Feature Embedding,是一个兼具表达性、速度和思维模块化的深度学习框架。由伯克利人工智能研究小组和伯克利视觉和学习中心开发。虽然其内核是用C++编写的,但Caffe有Python和Matlab 相关接口。Caffe支持多种类型的深度学习架构,面向图像分类和图像分割,还支持CNN、RCNN、LSTM和全连接神经网络设计。Caffe支持基于GPU和CPU的加速计算内核库,如NVIDIA cuDNN和Intel MKL。
实验对比:

文本情感分类实验:
25万条微博文本,jieba分词,利用word2vec中的CBOW方式训练词向量。取最长微博的词语个数n,词语个数小于n的微博文本用零向量填充,则每条微博文本都表示成n*d的文本矩阵,d为词向量维度。
模型参数设置及训练:batch=128,Adam算法作为优化函数,学习率设置为0.001.
全连接层dropout为0.5。LSTM层数128,BILSTM层数256。
将图文微博数据集中的80%作为训练集,20%作为测试集。利用NLPCC微博文本数据集对训练集进行扩充。模型训练在深度学习框架keras上进行。
实验对比:
词向量最优维度:

模型有效性:

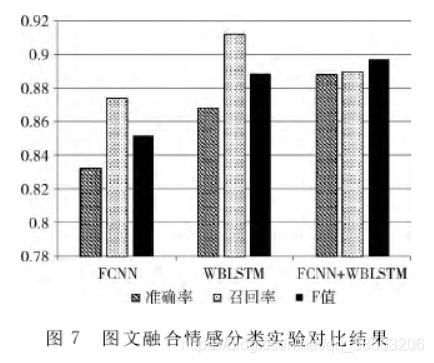
图文融合情感分类实验:

实验结果对比: